Sql api что это
Многие профаммисты обладают опытом работы с различными библиотеками функций, предназначенггых для обработки сфок, выполнения математических вычислений, организации файлового ввода/вывода или отображения информации на экране В современных операционных системах, таких как Unix или Windows подобные библиотеки применяются чрезвычайно широко, так как они расширяют функциональные возможности самой операционной системы. Для знакомых с этой кухней профаммистов SQL API является просто новой библиотекой, которую необходимо освоить.
За последние несколько лет появилось много различных библиотек SQL-функций, которые стали применяться даже более интенсивно, чем встроенный SQL. В настоящей главе приводится общая характеристика таких библиотек, а затем рассматриваются особенности профаммных интерфейсов некоторых ведущих СУБД. Подробно описывается также протокол ODBC компании Microsoft, который де-факто считается стандартом профаммного доступа к реляционным базам данных. Наконец, приводится описание международного стандарта SQL/CLI, сформированного на основе протокола ODBC.
Принципы применения программных интерфейсов для доступа к базам данных
Когда в СУБД имеется собственный профаммный интерфейс, приложение взаимодействует с СУБД только одним способом; вызывая функции, входящие в этот интерфейс. Типичная схема применения SQL API изображена на рис. 19.1:
программа получает доступ к базе данных путем вызова одной или нескольких API-функций, подключающих профамму к СУБД и к конкретной базе данных;
для пересылки инструкции SQL в СУБД профамма формирует инсфукцию в виде текстовой сфоки и затем передает эту сфоку в качестве парамефа при вызове API-функции;
профамма вызывает API-функции для проверки состояния переданной в СУБД инструкции и для обработки ошибок;
если инсфукция SQL представляет собой запрос на выборку, то, вызывая API-функции, программа записывает результаты запроса в свои переменные; обычно за один вызов возвращается одна сфока или один столбец данных;
свое обрашение к базе данных профамма заканчивает вызовом API-функции, отключающей ее от СУБД.
Образовательный блог — всё для учебы
В ряде СУБД при разработке приложений используются библиотеки функций, представляющие собой интерфейс между прикладными программами и СУБД(Application Program Interface — API). В настоящее время существует много новых API для доступа к БД. Это ODBC, JDBC, OLE DB.
1. Алгоритм взаимодействия
1) Получение доступа к БД
Программа получает доступ к БД с помощью вызова одной или нескольких API-функций, подключающих ее к СУБД и конкретной БД.
Пример:
LOGINREC *loginrec; — структура для хранения регистрационных данных.
DBPROCESS *dbproc; — структура данных, описывающая соединение.
loginrec=dblogin(); — создаем регистрационную структуру.
DBSTLUSER(loginrec, “username”); — указываем пользователя.
DBSTLPWD(loginrec, “password”); — указываем пароль.
dbproc=dbopen(loginrec, “server”); — подключаемся к БД.
2) Формирование операторов
SQL-оператор формируется в виде текстовой строки, и затем строка передается в качестве параметра при вызове соответствующей API-функции в СУБД
Пример:
char amount_str[31]; — число, вводимое пользователем.
printf(“Увеличить/уменьшить объем продаж на: ”); — запрос на обновление
gets(amount_str); — вводим значение.
dbcmd(dbproc, “update SalesPeople set Amt=Amt+”); — передаем оператор в DB-Library
dbcmd(dbproc, &amount_str); — передаем значение.
dbsqlexec(dbproc); — выполняем оператор.
3) Контроль состояний операторов и ошибок
Программа вызывает API-функции для проверки состояния переданного в СУБД оператора и для обработки ошибок.
If (dbresult(dbproc)!=SUCCEED) printf(“Ошибка обновления.\n”);
else printf(“Обновление произведено. \n”);
4) Обработка полученных результатов
Если SQL-оператор представляет собой запрос, то, вызывая API-функции, программа считывает результаты запроса в свои переменные. Обычно за один вызов возвращается одна строки или один столбец данных.
5) Отключение от БД
Свое обращение к БД программа заканчивает вызовом API-функции, отключающей ее от СУБД.
dbclose(dbproc); — разрываем соединение.
//dbexit(); — разрываем все соединения.
return(0);
2. Особенности API
• API обеспечивает более эффективную и быструю связь между прикладной программой и СУБД.
• Существенно снижается сетевой трафик.
• Более гибко обрабатываются ошибки
• Не требуется предкомпилятор.
3. СУБД с API
• Oracle (первоначально было около 20 функций, сейчас около 60).
• SQLBase (75 функций).
• MS SQL Server (100 функций).
Использование языка SQL в прикладных программах
13.4. Интерфейсы программирования приложений (API). DB-Library, ODBC, OCI, JDBC
Как замечено выше, программный SQL отличается от обычной, интерактивной формы наличием некоторых специальных инструкций, а также механизмом трансляции и выполнения запросов. Таким образом, для применения программного SQL в тексте своих программ программистам необходимо ознакомиться с некоторым специфическим набором инструкций. Стоит заметить, что в разных СУБД эти наборы инструкций, вообще говоря, могут несколько отличаться друг от друга. В результате возникает некоторая проблема, связанная с непереносимостью программы.
Протокол ODBC
ODBC (Open Database Connectivity – открытый доступ к базам данных) – разработанный компанией Microsoft универсальный интерфейс программирования приложений для доступа к базам данных [ [ 3.1 ] ].
Основной целью разработки протокола ODBC считается стандартизация механизмов взаимодействия с различными СУБД. Основная проблема, связанная с разработкой приложений, взаимодействующих с базами данных на основе специальных SQL API, состояла в том, что каждая СУБД имела собственный программный интерфейс доступа, каждый из них имел свои особенности и функционировал не совсем так, как другие. В связи с этим разработка приложения существенно зависела от используемой СУБД. Компания Microsoft сделала важный шаг для решения этой проблемы. Основная идея заключалась в разработке универсального интерфейса на уровне семейства операционных систем Windows, который мог бы быть поддержан в разных СУБД.
Рассмотрим кратко структуру программного обеспечения ODBC [ [ 3.1 ] ]:
Схема выполнения программы с использованием протокола ODBC для доступа к данным приводится на рис. 13.5.
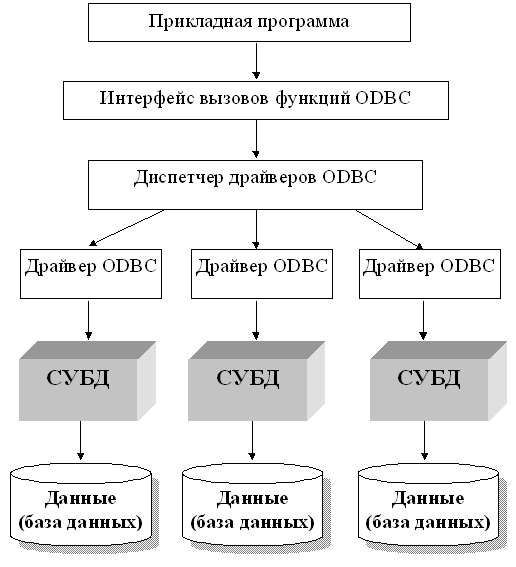
Перечень некоторых базисных функций ODBC API приводится в следующей таблице.
| Назначение | Функция | Описание |
|---|---|---|
| Соединение с источником данных | SQLAlocEnv | Получает указатель окружения. Одно окружение может служить для создания нескольких соединений. |
| SQLAlIoc Connect | Получает указатель соединения. | |
| SQLConnect | Соединяется с указанным драйвером, используя имя источника данных, идентификатор пользователя и пароль. | |
| Подготовка SQL запросов | SQLAllocStmt | Размещает указатель выражения. |
| SQLPrepare | Подготавливает SQL выражение для дальнейшего использования. | |
| SQLGet CursorName | Возвращает имя, связанное c указателем выражения. | |
| SQLSet CursorName | Устанавливает имя курсора. | |
| Выполнение запросов | SQLExecute | Выполняет заранее подготовленный запрос. |
| SQLExec Direct | Выполняет запрос. | |
| Выборка результатов и информации о результатах | SQLRow Count | Возвращает количество записей, задействованных в операциях вставки, удаления, модификации. |
| SQLNum ResultCol | Возвращает количество колонок в выбранном наборе данных. | |
| SQLDescribe Col | Описывает колонку в выбранном наборе данных. | |
| SQLCol Attributes | Описывает атрибуты колонки в выбранном наборе данных. | |
| SQLBindCol | Присваивает место в памяти для колонки в выбранном наборе данных и указывает ее тип данных. | |
| SQLFetch | Возвращает несколько наборов данных. |
Протокол JDBC
JDBC (Java Database Connectivity) представляет собой API для выполнения SQL-запросов к базам данных из программ, написанных на языке Java [ [ 3.1 ] ].
Рассмотрим основные принципы JDBC.
Известно несколько различных версий JDBC. Так, версия 1.0 содержала некоторые средства доступа к данным:
Этот перечень определенным образом напоминает аналогичный функциональный аппарат протокола ODBC.
Версия JDBC 2.0 содержит существенные отличия. Так, вследствие увеличения возможностей интерфейса было проведено его идеологическое разделение на две основные части: Core API (основные возможности) и Extensions API (так называемые расширения).
В [ [ 3.1 ] ] указаны следующие возможности JDBC:
Версия JDBC 3.0 появилась совсем недавно и содержит такие новации, как объектно-реляционные расширения SQL и улучшенные механизмы обработки транзакций. Архитектура JDBC берет свое начало от ODBC и в существенной части повторяет ее, поэтому схема выполнения программы на Java с использованием протокола JDBC для доступа к данным полностью аналогична схеме на рис. 13.5 (слова ODBC заменяются на слова JDBC). В отличие от ODBC, драйверы JDBC подразделяются на четыре типа. Основные отличия между этими типами связаны с местонахождением API СУБД (на клиентской или серверной СУБД) и способом доступа к базе данных (через собственный API СУБД или через ODBC).
Библиотека DB-Library
Библиотека DB-Library реализует интерфейс программирования приложений для совместной работы с широко распространенной СУБД Microsoft SQL Server. Данная библиотека является весьма обширной и содержит более 100 функций. Основными из них являются:
Логика работы прикладной программы, обрабатывающей данные, хранящиеся в базе данных под управлением Microsoft SQL Server, выглядит следующим образом:
SQLite — замечательная встраиваемая БД (часть 2)
В этой части будут затронуты непростые вопросы использования SQLite через работу с его программным интерфейсом (API).
Что такое SQLite API? Это набор функций sqlite3_XXX на языке C.
Заголовки этих функций находятся в sqlite3.h, а описание API в виде одного большого HTML находится тут.
Мы начнем использовать API, а позднее плавно перейдем к вопросам оборачивания его в уютный фреймворк.
Попробуем создать небольшой проект на C++ (я делал в MS Visual Studio), который что-то делает с SQLite базой.
Использовать SQLite в своем проекте можно двумя способами.
«Вкомпилировать» код (если это C или C++). Или загружать и использовать sqlite3.dll (позволяет легко обновлять SQLite и не привязан к языку).
В любом случае, надо создать новый проект (консольного) приложения (я использовал MS Visual Studio) и добавить в него вот такой main.cpp:
const char * SQL = «CREATE TABLE IF NOT EXISTS foo(a,b,c); INSERT INTO FOO VALUES(1,2,3); INSERT INTO FOO SELECT * FROM FOO;» ;
sqlite3 * db = 0 ; // хэндл объекта соединение к БД
char * err = 0 ;
Далее, если мы желаем собрать проект вместе с кодом SQLite, то надо:
— скачать исходный код в виде amalgamation;
— извлечь из него sqlite3.h и sqlite3.c и добавить их в проект.
Если же мы хотим использовать sqlite3.dll, необходимо:
— скачать SQLite DLL и распаковать;
— выполнить «LIB.EXE /DEF:sqlite3.def» в папке куда распаковали для получения sqlite3.lib (убедитесь, что пути к lib.exe прописаны через вызов vcvars32.bat);
— включить в проект sqlite3.lib;
— скачать amalgamation и извлечь из него sqlite3.h;
— включить в проект sqlite3.h;
Компилируем, выполняем (во втором случае, DLL должна быть доступна для исполняемого файла).
При первом запуске будет создан файл «my_cosy_database.dblite» с БД, в нем — одна таблица и две записи в ней.
При последующих запусках — программа будет присоединяться к уже существующей БД и удваивать число записей в таблице.
Давайте разбираться с кодом проекта.
Использование SQLite предполагает, что мы хотим выполнять команды на языке SQL в какой-то БД (Ваш К.О.!).
Можно представить работу с SQLite базой как работу с файлами в ОС Windows. Мы открываем файл и получаем _хэндл_ файла, к которому «привязан» некий системный объект (файл). Передавая этот хэндл в различные функции мы просим систему что-то сделать с файлом. Затем — закрываем файл. Также и в SQLite. Мы открываем файл с БД и получаем хэндл объекта «соединение к БД». Затем мы исполняем некие SQL команды через вызовы функций, получающих этот хэндл, и, в конце, закрываем соединение.
Ничего оригинального, особенного или хитрого, как видим, тут нет.
Расширение файла с БД SQLite не стандартизовано. Некоторые делают его «.sqlite3», но можно поставить любое.
создает или открывает БД в указанном файле (UTF-8!) и заносит хендл соединения в db. Она возвращает 0 (успех) или код ошибки. Закрывающий вызов sqlite3_close нужен в любом случае (даже при ошибке sqlite3_open).
выполняет команду SQL (состояющую из одного или нескольких операторов SQL в UTF-8, разделенных «;») в контексте указанного (открытого) соединения к БД.
Функция обратного вызова (callback) и custom аргумент к ней нужны, если делается SELECT (для извлечения данных). Об этом позже, пока не используем.
В параметре errmsg можно получить текст ошибки и позднее очистить его через sqlite3_free. Если передать здесь NULL, то текста ошибки не получим.
Как и sqlite3_open возвращается 0 или код ошибки.
Команда «CREATE TABLE» содержит уточнение «IF NOT EXISTS». Это означает, что таблица создается, если ее — нет. Если есть, то ничего не происходит (и нет ошибки).
Собственно, вот и все. Несмотря на то, что в реальных проектах не используются ни sqlite3_open (есть более мощный вызов sqlite3_open_v2), ни sqlite3_exec (обычно используется связка вызовов, компилирующих SQL, привязывающих параметры и пр.) это вполне рабочий проект.
Он несет и еще одну важную миссию. Как уже было сказано при каждом запуске он удваивает кол-во строк в таблице foo. После 20 запусков в таблице будет
Т.е. 21-й запуск вставляет
На моей машине (Windows 7 x64, i5 2.8 Ghz, HDD, не SSD ) это заняло
15 секунд. Пускай это убогий и синтетический тест, но он все-таки дает определенное представление о производительности SQLite.
Руководство по Выполнение запросов в Azure Cosmos DB с использованием API SQL
ПРИМЕНИМО К:  API SQL
API SQL
API SQL базы данных Azure Cosmos DB позволяет выполнять запросы к документам с помощью SQL. В этой статье содержится пример документа и два примера SQL-запросов и результатов.
В этой статье рассматриваются следующие задачи:
Пример документа
Запросы SQL в этой статье используют следующий пример документа.
Где могут выполняться SQL-запросы
Запросы можно выполнять с помощью обозревателя данных на портале Azure и с помощью REST API и пакетов SDK.
Дополнительные сведения об SQL-запросах см. в статье:
Предварительные требования
В этом руководстве предполагается, что у вас есть учетная запись и коллекция базы данных Azure Cosmos DB. Если у вас их нет, выполните указанные ниже действия. Выполните задачи 5-минутного краткого руководства.
Пример запроса 1
Запрос
Результаты
Пример запроса 2
Запрос
Результаты
Дальнейшие действия
В этом учебнике были выполнены следующие задачи:
Теперь вы можете приступать к следующему руководству, чтобы узнать, как глобально распределять данные.
Пытаетесь выполнить планирование ресурсов для миграции в Azure Cosmos DB? Можете использовать для этого сведения о существующем кластере базы данных.