Введение
Что такое Объектная Модель Документа (DOM)?
Объектная Модель Документа (DOM) – это программный интерфейс (API) для HTML и XML документов. DOM предоставляет структурированное представление документа и определяет то, как эта структура может быть доступна из программ, которые могут изменять содержимое, стиль и структуру документа. Представление DOM состоит из структурированной группы узлов и объектов, которые имеют свойства и методы. По существу, DOM соединяет веб-страницу с языками описания сценариев либо языками программирования.
Веб-страница – это документ. Документ может быть представлен как в окне браузера, так и в самом HTML-коде. В любом случае, это один и тот же документ. DOM предоставляет другой способ представления, хранения и управления этого документа. DOM полностью поддерживает объектно-ориентированное представление веб-страницы, делая возможным её изменение при помощи языка описания сценариев наподобие JavaScript.
Стандарты W3C DOM и WHATWG DOM формируют основы DOM, реализованные в большинстве современных браузеров. Многие браузеры предлагают расширения за пределами данного стандарта, поэтому необходимо проверять работоспособность тех или иных возможностей DOM для каждого конкретного браузера.
Например: стандарт DOM описывает, что метод getElementsByTagName в коде, указанном ниже, должен возвращать список всех элементов
DOM и JavaScript
Вначале JavaScript и DOM были тесно связаны, но впоследствии они развились в различные сущности. Содержимое страницы хранится в DOM и может быть доступно и изменяться с использованием JavaScript, поэтому мы можем записать это в виде приблизительного равенства:
API (веб либо XML страница) = DOM + JS (язык описания скриптов)
DOM спроектирован таким образом, чтобы быть независимым от любого конкретного языка программирования, обеспечивая структурное представление документа согласно единому и последовательному API. Хотя мы всецело сфокусированы на JavaScript в этой справочной документации, реализация DOM может быть построена для любого языка, как в следующем примере на Python:
Для подробной информации о том, какие технологии участвуют в написании JavaScript для веб, смотрите обзорную статью JavaScript technologies overview.
Каким образом доступен DOM?
Вы не должны делать ничего особенного для работы с DOM. Различные браузеры имеют различную реализацию DOM, эти реализации показывают различную степень соответствия с действительным стандартом DOM (это тема, которую мы пытались не затрагивать в данной документации), но каждый браузер использует свой DOM, чтобы сделать веб страницы доступными для взаимодействия с языками сценариев.
При создании сценария с использованием элемента
XML DOM Учебное пособие
DOM определяет стандарт для доступа и работы с документами.
XML DOM представляет документ XML в виде древовидной структуры.
HTML DOM представляет HTML-документ в виде древовидной структуры.
Понимание DOM является обязательным для тех, кто работает с HTML или XML.
XML DOM Пример дерева
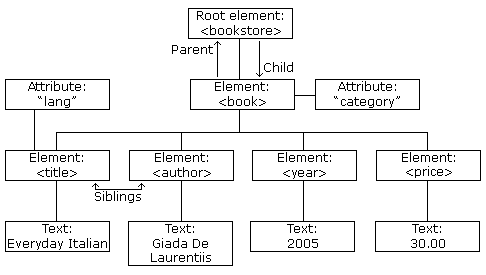
Что такое DOM?
DOM определяет стандарт для доступа к документам, как XML и HTML:
«The W3C Document Object Model (DOM) is a platform and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure, and style of a document.»
DOM разделяется на 3 части / уровней:
DOM определяет objects and properties всех элементов документа, а также methods (interface) для доступа к ним.
HTML DOM
HTML DOM определяет стандартный способ для доступа и управления HTML-документов.
Все HTML-элементы могут быть доступны через HTML DOM.
Измените значение HTML-элемента
Этот пример изменяет значение HTML-элемента с :
пример
This is a Heading
Этот пример изменяет значение первого
пример
This is a Heading
This is a Heading
Примечание: Даже если containes документ HTML только ОДИН
элемента вам все равно придется указать индекс массива [0], потому что getElementsByTagName() метод всегда возвращает массив.
XML DOM
XML DOM определяет стандартный способ для доступа и манипулирования XML-документами.
Все элементы XML могут быть доступны через XML DOM.
XML DOM определяет objects, properties and methods всех элементов XML.
Получить значение элемента XML
Этот код извлекает текстовое значение первого элемента в документе XML:
Использование XML Document Object Model
Язык XML все чаще используется для хранения информации, обмена ею между приложениями и Web-узлами. Во многих приложениях этот язык применяется в качестве базового для хранения данных, в других — для экспортирования и импортирования XML-данных. Из этого следует, что разработчикам пора задуматься над тем, как можно использовать XML-данные в собственных приложениях.
В этой статье мы рассмотрим XML Document Object Model (DOM) и ее реализацию фирмой Microsoft — Microsoft XML DOM.
XML DOM — это объектная модель, предоставляющая в распоряжение разработчика объекты для загрузки и обработки XML-файлов. Объектная модель состоит из следующих основных объектов: XMLDOMDocument, XMLDOMNodeList, XMLDOMNode, XMLDOMNamedNodeMap и XMLDOMParseError. Каждый из этих объектов (кроме XMLDOMParseError) содержит свойства и методы, позволяющие получать информацию об объекте, манипулировать значениями и структурой объекта, а также перемещаться по структуре XML-документа.
Рассмотрим основные объекты XML DOM и приведем несколько примеров их использования в Borland Delphi.
Использование XML DOM в Borland Delphi 
Для того чтобы использовать Microsoft XML DOM в Delphi-приложениях, необходимо подключить к проекту соответствующую библиотеку типов. Для этого мы выполняем команду Project | Import Type Library и в диалоговой панели Import Type Library выбираем библиотеку Microsoft XML version 2.0 (Version 2.0), которая обычно находится в файле Windows\System\MSXML.DLL
После нажатия кнопки Create Unit будет создан интерфейсный модуль MSXML_TLB, который позволит нам воспользоваться объектами XML DOM: DOMDocument, XMLDocument, XMLHTTPRequest и рядом других, реализованных в библиотеке MSXML.DLL. Ссылка на модуль MSXML_TLB должна быть указана в списке Uses.
Устройство XML DOM
Document Object Model представляет XML-документ в виде древовидной структуры, состоящей из ветвей. Программные интерфейсы XML DOM позволяют приложениям перемещаться по дереву документа и манипулировать его ветвями. Каждая ветвь может иметь специфический тип (DOMNodeType), согласно которому определяются родительская и дочерние ветви. В большинстве XML-документов можно встретить ветви типа element, attribute и text. Атрибуты (attribute) представляют собой особый вид ветви и не являются дочерними ветвями. Для управления атрибутами используются специальные методы, предоставляемые объектами XML DOM.
Помимо реализации рекомендованных World Wide Web Consortium (W3C) интерфейсов, Microsoft XML DOM содержит методы, поддерживающие XSL, XSL Patterns, Namespaces и типы данных. Например, метод SelectNodes позволяет использовать синтаксис шаблонов XSL (XSL Pattern Syntax) для поиска ветвей по определенному контексту, а метод TransformNode поддерживает использование XSL для выполнения трансформаций.
Тестовый XML-документ
В качестве примера XML-документа возьмем каталог музыкальных CD-ROM, который имеет следующую структуру:
Теперь мы готовы приступить к рассмотрению объектной модели XML DOM, знакомство с которой начнем с объекта XMLDOMDocument.
XML-документ — объект XMLDOMDocument
Работа с XML-документом начинается с его загрузки. Для этого мы используем метод Load, который имеет всего один параметр, указывающий URL загружаемого документа. При загрузке файлов с локального диска указывается только полное имя файла (протокол file:/// в данном случае можно опустить). Если XML-документ хранится в виде строки, для загрузки такого документа следует использовать метод LoadXML.
Для управления способом загрузки документа (синхронный или асинхронный) используется свойство Async. По умолчанию это свойство имеет значение True, указывающее на то, что документ загружается асинхронно и управление возвращается приложению еще до полной загрузки документа. В противном случае документ загружается синхронно, и тогда приходится проверять значение свойства ReadyState, чтобы узнать, загрузился документ или нет. Также можно создать обработчик события OnReadyStateChange, который получит управление при изменении значения свойства ReadyState.
Ниже показано, как загрузить XML-документ, используя метод Load:
После того как документ загружен, мы можем обратиться к его свойствам. Так, свойство NodeName будет содержать значение #document, свойство NodeTypeString — значение document, свойство URL — значение file:///C:/DATA/DATA.xml.
Обработка ошибoк
Особый интерес представляют свойства, связанные с обработкой документа при его загрузке. Так, свойство ParseError возвращает объект XMLDOMParseError, содержащий информацию об ошибке, возникшей в процессе обработки документа.
Чтобы написать обработчик ошибки, можно добавить следующий код:
Чтобы узнать, какая информация возвращается в случае ошибки, изменим следующий элемент каталога:
убрав закрывающий элемент во второй строке:
Теперь напишем код, возвращающий значения свойств объекта XMLDOMParseError:
и выполним наше приложение. В результате получаем следующую информацию об ошибке 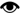 .
.
Как видно из приведенного примера, возвращаемой объектом XMLDOMParseError информации вполне достаточно для того, чтобы локализовать ошибку и понять причину ее возникновения.
Теперь восстановим закрывающий элемент в нашем документе и продолжим обсуждение XML DOM.
Доступ к дереву документа
Для доступа к дереву документа можно либо получить корневой элемент и затем перебрать его дочерние ветви, либо найти какую-то специфическую ветвь. В первом случае мы получаем корневой элемент через свойство DocumentElement, которое возвращает объект типа XMLDOMNode. Ниже показано, как воспользоваться свойством DocumentElement для того, чтобы получить содержимое каждого дочернего элемента:
Для нашего XML-документа мы получим следующий текст .
Если нас интересует какая-то специфическая ветвь или ветвь уровнем ниже первой дочерней ветви, мы можем воспользоваться либо методом NodeFromID, либо методом GetElementByTagName объекта XMLDOMDocument.
Метод NodeFromID требует указания уникального идентификатора, определенного в XML Schema или Document Type Definition (DTD), и возвращает ветвь с этим идентификатором.
Метод GetElementByTagName требует указания строки со специфическим элементом (тэгом) и возвращает все ветви с данным элементом. Ниже показано, как использовать данный метод для нахождения всех исполнителей в нашем каталоге CD-ROM:
Для нашего XML-документа мы получим следующий текст
Отметим, что метод SelectNodes объекта XMLDOMNode обеспечивает более гибкий способ для доступа к ветвям документа. Но об этом чуть ниже.
Ветвь документа — объект XMLDOMNode
Объект XMLDOMNode представляет собой ветвь документа. Мы уже сталкивались с этим объектом, когда получали корневой элемент документа:
Для получения информации о ветви XML-документа можно использовать свойства объекта XMLDOMNode (табл. 1).
Для доступа к данным, хранимым в ветви, обычно используют либо свойство NodeValue (доступно для атрибутов, текстовых ветвей, комментариев, инструкций по обработке и секций CDATA), либо свойство Text, возвращающее текстовое содержимое ветви, либо свойство NodeTypedValue. Последнее, однако, может использоваться только для ветвей с типизованными элементами.
Перемещение по дереву документа
Объект XMLDOMNode предоставляет множество способов для перемещения по дереву документа. Например, для доступа к родительской ветви используется свойство ParentNode (тип XMLDOMNode), доступ к дочерним ветвям осуществляется через свойства ChildNodes (тип XMLDOMNodeList), FirstChild и LastChild (тип XMLDOMNode) и т.д. Свойство OwnerDocument возвращает объект типа XMLDOMDocument, идентифицирующий сам XML-документ. Перечисленные выше свойства позволяют легко перемещаться по дереву документа.
Теперь переберем все ветви XML-документа:
Как уже отмечалось выше, SelectNodes объекта XMLDOMNode обеспечивает более гибкий способ доступа к ветвям документа. Кроме того, существует метод SelectSingleNode, возвращающий только первую ветвь документа. Оба эти метода позволяют задавать XSL-шаблоны для поиска ветвей.
Рассмотрим процесс использования метода SelectNodes для извлечения всех ветвей, у которых есть ветвь CD и подветвь PRICE:
В коллекцию Nodes будут помещены все подветви PRICE ветви CD. К обсуждению XSL-шаблонов вернемся чуть позже.
Манипуляция дочерними ветвями
Для манипуляции дочерними ветвями мы можем воспользоваться методами объекта XMLDOMNode (табл. 2).
Для того чтобы полностью удалить запись о первом диске, необходимо выполнить следующий код :
Обратите внимание на то, что в данном примере мы удаляем первую дочернюю ветвь. Как удалить первый элемент первой дочерней ветви, показано ниже :
Теперь добавим новую ветвь. Ниже приведен код, показывающий, как добавить новую запись о музыкальном CD-ROM :
Приведенный выше код показывает следующую последовательность действий по добавлению новой ветви:
Напомним, что метод AppendChild добавляет ветвь в конец дерева. Для того чтобы добавить ветвь в конкретное место дерева, необходимо использовать метод InsertBefore.
Трансформации
Два метода объекта XMLDOMNode — TransformNode и TransformNodeToObject — могут использоваться для трансформации ветви в строку или объект. Эти методы базируются на XSL-синтаксисе.
Набор ветвей — объект XMLDOMNodeList
Объект XMLNodeList содержит список ветвей, который может быть построен с помощью методов SelectNodes или GetElementsByTagName, а также получен из свойства ChildNodes.
Мы уже рассматривали использование этого объекта в примере, приведенном в разделе «Перемещение по дереву документа». Здесь же мы приведем некоторые теоретические замечания.
Число ветвей в списке может быть получено как значение свойства Length. Ветви имеют индексы от 0 до Length-1, и каждая отдельная ветвь доступна через элемент массива Item с соответствующим индексом.
Перемещение по списку ветвей также может осуществляться с помощью метода NextNode, возвращающего следующую ветвь в списке, или Nil, если текущая ветвь — последняя. Чтобы вернуться к началу списка, следует вызвать метод Reset.
Создание и сохранение документов
Итак, мы рассмотрели, как можно добавлять ветви и элементы в существующие XML-документы. Теперь создадим XML-документ «на лету». Прежде всего напомним, что документ может быть загружен не только из URL, но и из обычной строки. Ниже показано, как создать корневой элемент, который затем может использоваться для динамического построения остальных элементов (что мы уже рассмотрели в разделе «Манипуляция дочерними ветвями»):
После построения XML-документа сохраним его в файле с помощью метода Save. Например:
Помимо сохранения в файле метод Save позволяет сохранять XML-документ в новом объекте XMLDOMDocument. В этом случае происходит полная обработка документа и, как следствие, проверка его структуры и синтаксиса. Ниже показано, как сохранить документ в другом объекте:
В заключение отметим, что метод Save также позволяет сохранять XML-документ в другие COM-объекты, поддерживающие интерфейсы IStream, IPersistStream или IPersistStreamInit.
Использование XSL-шаблонов
Обсуждая метод SelectNodes объекта XMLDOMNode, мы упомянули о том, что он обеспечивает более гибкий способ доступа к ветвям документа. Гибкость заключается в том, что в качестве критерия для выбора ветвей можно указать XSL-шаблон. Такие шаблоны предоставляют мощный механизм для поиска информации в XML-документах. Например, для того, чтобы получить список всех названий музыкальных CD-ROM в нашем каталоге, можно выполнить следующий запрос:
Чтобы узнать, диски каких исполнителей выпущены в США, запрос формируется следующим образом:
Ниже показано, как найти первый диск в каталоге:
Чтобы найти диски Боба Дилана, можно выполнить следующий запрос:
а чтобы получить список дисков, выпущенных после 1985 года, мы выполняем следующий запрос:
Используя XSL, мы просто создаем шаблон (или таблицу стилей), в котором указываем, что и как надо преобразовать. Затем накладываем этот шаблон на наш каталог — и готово: перед нами текст XSL-шаблона, преобразующего каталог в таблицу (листинг 2).
Код для наложения XSL-шаблона на наш каталог выглядит так:
Завершая наше обсуждение XSL, следует сказать, что в настоящее время этот язык активно используется для трансформации между различными XML-документами, а также для форматирования документов.
Заключение
По вполне понятным причинам в одной статье невозможно рассмотреть все объекты Microsoft XML DOM и привести примеры их использования. Здесь мы лишь коснулись основных вопросов использования XML DOM в приложениях. В табл. 3 показаны все объекты, реализованные в Microsoft XML DOM.
Учебник XML DOM
Что такое DOM?
HTML DOM определяет стандартный способ доступа к HTML-документам и управления ими. Он представляет HTML-документ в виде древовидной структуры.
XML DOM определяет стандартный способ доступа к XML-документам и управления ими. Он представляет XML-документ в виде древовидной структуры.
Понимание DOM является обязательным для всех, кто работает с HTML или XML.
HTML DOM
Доступ ко всем элементам HTML можно получить через HTML DOM.
В следующем примере изменяется значение элемента HTML с id=»demo»:
В следующем примере изменяется значение первого элемента
в документе HTML:
Примечание: Даже если документ HTML содержит только ОДИН элемент
, вам все равно необходимо указать индекс массива [0], потому что метод getElementsByTagName() всегда возвращает массив.
Подробнее о HTML DOM вы можете узнать в нашем учебнике по JavaScript.
XML DOM
Доступ ко всем элементам XML можно получить через XML DOM.
Как получить значение XML элемента
Следующий код извлекает текстовое значение первого элемента в XML-документе:
Загрузка XML файла
В приведенных ниже примерах используется XML-файл books.xml.
В следующем примере загружается файл «books.xml» в объект xmlDoc и извлекается текстовое значение первого элемента в books.xml:
Загрузка строки XML
В следующем примере загружается текстовая строка в объект XML DOM и затем при помощи JavaScript извлекаются из него нужные данные:
Интерфейс программирования
DOM моделирует XML как набор узловых объектов. Доступ к узлам можно получить с помощью JavaScript или других языков программирования. В этом учебнике используется JavaScript.
Программный интерфейс DOM определяется набором стандартных свойств и методов.
Свойства XML DOM
Существует ряд типичных свойств DOM:
Примечание: В приведенном выше списке «x» — узловой объект.
Методы XML DOM
Примечание: В приведенном выше списке «x» — узловой объект.
Модель объектов XML-документов (DOM)
Входные данные
Далее показано, какая структура будет создана в памяти, когда эти XML-данные считываются в модель структуры DOM.
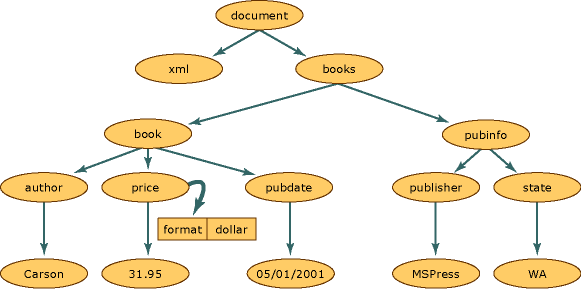 Структура XML-документа
Структура XML-документа
Каждый круг на этой иллюстрации представляет собой узел в структуре XML-документа, называемый объектом XmlNode. Объект XmlNode является базовым объектом дерева DOM. Класс XmlDocument, расширяющий класс XmlNode, поддерживает методы для операций над документом в целом (например, для загрузки его в память или сохранения XML в файл). Кроме того, XmlDocument предоставляет возможности для просмотра узлов всего XML-документа и выполнения операций над ними. И XmlNode, и XmlDocument обладают улучшенной производительностью, расширенной функциональностью и содержат методы и свойства, которые позволяют следующее.
Получать доступ к DOM-специфичным узлам, например к узлам элементов, узлам ссылок на сущности и т. п., и изменять эти узлы.
Получать целые узлы помимо содержащейся в них информации, например текста в узле элемента.
Для приложений, которым не требуется структуризация или изменение, предоставляемые моделью DOM, классы XmlReader и XmlWriter обеспечат последовательный потоковый доступ к XML без поддержки кэширования. Дополнительные сведения см. в разделах XmlReader и XmlWriter.
Объекты Node обладают набором методов и свойств, а также хорошо определенных базовых характеристик. Вот некоторые из этих характеристик:
У большинства узлов может быть несколько дочерних узлов, то есть узлов, расположенных непосредственно под ними. Далее следует список типов узлов, которые могут иметь дочерние узлы:
Document
DocumentFragment
EntityReference
Элемент
Attribute (XElement Dynamic Property) (Attribute (динамическое свойство XElement))
Узлы XmlDeclaration, Notation, Entity, CDATASection, Text, Comment, ProcessingInstruction и DocumentType не могут иметь дочерних узлов.
Узлы, находящиеся на одном уровне наследования, например узлы book и pubinfo на нашей схеме, называются одноуровневыми.
По мере считывания XML-документа в память создаются узлы. Узлы бывают разных типов. Правила и синтаксис XML-элемента отличаются от правил и синтаксиса инструкции по обработке. Поэтому по мере считывания разнообразных данных каждому узлу присваивается тип. Тип узла определяет его характеристики и функциональность.
Дополнительные сведения о типах узлов, создаваемых в памяти, см. в статье Типы XML-узлов. Дополнительные сведения об объектах, создаваемых в дереве узлов, см. в статье Сопоставление объектной иерархии с XML-данными.
Корпорация Майкрософт расширила API-интерфейсы, доступные в DOM уровней 1 и 2 W3C, чтобы облегчить работу с XML-документами. Дополнительные классы, методы и свойства полностью совместимы со стандартами W3C и добавляют дополнительную функциональность по сравнению с возможностями W3C XML DOM. Новые классы позволяют получить доступ к реляционным данным, предоставляют методы синхронизации с данными ADO.NET, одновременно делая эти данные доступными в виде XML. Дополнительные сведения см. в статье о синхронизации DataSet с XmlDataDocument.
Модель DOM чрезвычайно полезна для считывания XML-данных в память, изменения их структуры, добавления и удаления узлов, изменения данных, принадлежащих узлу (например, текста, содержащегося в документе). Однако существуют и другие классы, которые в некоторых ситуациях работают быстрее модели DOM. Классы XmlReader и XmlWriter предоставляют быстрый последовательный потоковый доступ к XML без поддержки кэширования. Если вам нужен произвольный доступ с моделью курсора и XPath, используйте класс XPathNavigator.