Xml Declaration Класс
Определение
Некоторые сведения относятся к предварительной версии продукта, в которую до выпуска могут быть внесены существенные изменения. Майкрософт не предоставляет никаких гарантий, явных или подразумеваемых, относительно приведенных здесь сведений.
Комментарии
Этот класс является расширением Майкрософт для модель DOM (DOM).
Конструкторы
Инициализирует новый экземпляр класса XmlDeclaration.
Свойства
Возвращает класс XmlAttributeCollection, содержащий атрибуты данного узла.
Возвращает базовый URI текущего узла.
Возвращает все дочерние узлы данного узла.
Получает или задает уровень кодировки XML-документа.
Возвращает первый дочерний узел данного узла.
Возвращает значение, свидетельствующее о наличии дочерних узлов у текущего узла.
Возвращает или задает разметку, отражающую только дочерние узлы данного узла.
Возвращает значение, определяющее, доступен ли узел только для чтения.
Возвращает первый дочерний элемент с помощью указанного свойства LocalName и NamespaceURI.
Возвращает первый дочерний элемент с помощью указанного свойства Name.
Возвращает последний дочерний узел данного узла.
Возвращает локальное имя узла.
Возвращает полное имя узла.
Возвращает URI пространства имен данного узла.
Возвращает узел, следующий сразу за данным узелом.
Возвращает тип текущего узла.
Возвращает разметку, содержащую данный узел и все его дочерние узлы.
Возвращает класс XmlDocument, которому принадлежит данный узел.
Возвращает родительский узел для данного узла (только для тех узлов, которые могут иметь родительские узлы).
Возвращает или задает префикс пространства имен данного узла.
Возвращает узел, непосредственно предшествующий данному узлу.
Возвращает текстовый узел, непосредственно предшествующий данному.
Возвращает информационный набор после проверки схемы (назначенный этому узлу в результате проверки схемы).
Получает или задает значение отдельного атрибута.
Получает XML-версию документа.
Методы
Добавляет указанный узел в конец списка дочерних узлов данного узла.
Создает дубликат этого узла.
Создает дубликат этого узла.
Создает класс XPathNavigator для перемещения данного объекта.
Определяет, равен ли указанный объект текущему объекту.
Возвращает перечислитель, выполняющий итерацию дочерних узлов текущего узла.
Служит хэш-функцией по умолчанию.
Ищет наиболее точное объявление xmlns для заданного префикса, принадлежащее области действия текущего узла, и возвращает универсальный код ресурса (URI) пространства имен в объявлении.
Ищет наиболее точное объявление xmlns для универсального кода ресурса (URI) пространства имен, принадлежащее области действия текущего узла, и возвращает префикс, определенный в этом объявлении.
Возвращает объект Type для текущего экземпляра.
Вставляет заданный узел сразу после указанного узла ссылки.
Вставляет заданный узел сразу перед указанным узлом ссылки.
Создает неполную копию текущего объекта Object.
Помещает все узлы XmlText на максимальную глубину поддерева, расположенного под данным узлом XmlNode, в обычную форму, где узлы XmlText разделяются только разметкой (теги, примечания, комментарии, инструкции по обработке, разделы CDATA и ссылки на сущности). Смежные узлы XmlText отсутствуют.
Добавляет указанный узел в начало списка дочерних узлов данного узла.
Удаляет все дочерние узлы и (или) атрибуты текущего узла.
Удаляет указанный дочерний узел.
Выбирает список узлов в соответствии с выражением XPath.
Выбирает список узлов в соответствии с выражением XPath. Префиксы, найденные в выражении XPath, разрешаются с помощью предоставленного XmlNamespaceManager.
Проверяет, присутствует ли указанное средство в реализации DOM.
Возвращает строку, представляющую текущий объект.
Сохраняет дочерний узел этого узела в заданном классе XmlWriter. Поскольку у узлов XmlDeclaration отсутствуют дочерние узлы, этот метод не работает.
Сохраняет узел в заданном XmlWriter.
Явные реализации интерфейса
Описание этого члена см. в разделе Clone().
Описание этого члена см. в разделе GetEnumerator().
Методы расширения
Приводит элементы объекта IEnumerable к заданному типу.
Выполняет фильтрацию элементов объекта IEnumerable по заданному типу.
Позволяет осуществлять параллельный запрос.
Преобразовывает коллекцию IEnumerable в объект IQueryable.
Создает навигатор XPath для навигации по указанному узлу.
Выбирает список узлов, которые соответствуют указанному выражению XPath.
Выбирает список узлов, которые соответствуют указанному выражению XPath. Префиксы, найденные в выражении XPath, разрешаются с помощью предоставленного диспетчера пространств имен.
Выделяет первый узел, соответствующий выражению XPath.
Выделяет первый узел, соответствующий выражению XPath. Префиксы, найденные в выражении XPath, разрешаются с помощью предоставленного диспетчера пространств имен.
Создает экземпляр IXPathNavigable, используемый для создания навигаторов.
Как я разбирал docx с помощью XSLT
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
А логически — 3 вида элементов:
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
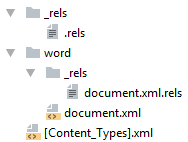
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
word/_rels/document.xml.rels
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
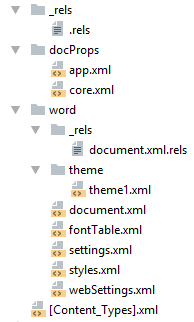
Вот что в них содержится:
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
Инструменты
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
Использование
Поиск изменений происходит следующим образом:
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
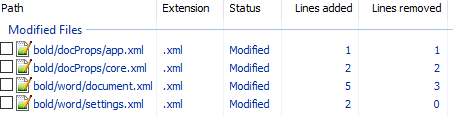
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
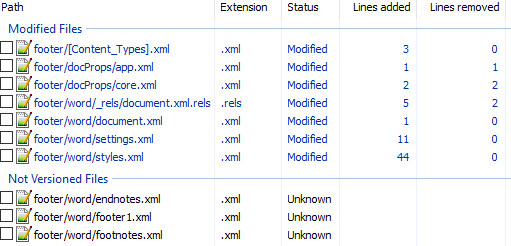
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
Распаковка
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег добавить тег или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега может быть 3 тега — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
This chapter covers XML declaration in detail. XML declaration contains details that prepare an XML processor to parse the XML document. It is optional, but when used, it must appear in the first line of the XML document.
Syntax
Following syntax shows XML declaration −
Each parameter consists of a parameter name, an equals sign (=), and parameter value inside a quote. Following table shows the above syntax in detail −
| Parameter | Parameter_value | Parameter_description |
|---|---|---|
| Version | 1.0 | Specifies the version of the XML standard used. |
| Encoding | UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, ISO-8859-1 to ISO-8859-9, ISO-2022-JP, Shift_JIS, EUC-JP | It defines the character encoding used in the document. UTF-8 is the default encoding used. |
| Standalone | yes or no | It informs the parser whether the document relies on the information from an external source, such as external document type definition (DTD), for its content. The default value is set to no. Setting it to yes tells the processor there are no external declarations required for parsing the document. |
Rules
An XML declaration should abide with the following rules −
If the XML declaration is present in the XML, it must be placed as the first line in the XML document.
If the XML declaration is included, it must contain version number attribute.
The Parameter names and values are case-sensitive.
The names are always in lower case.
The order of placing the parameters is important. The correct order is: version, encoding and standalone.
Either single or double quotes may be used.
The XML declaration has no closing tag i.e.
XML Declaration Examples
Following are few examples of XML declarations −
XML declaration with no parameters −
XML declaration with version definition −
XML declaration with all parameters defined −
XML declaration with all parameters defined in single quotes −
Xml declaration should precede all document content что это
This forum has migrated to Microsoft Q&A. Visit Microsoft Q&A to post new questions.
Asked by:
![]()
Question
![]()
![]()
public static MemoryStream CriteriaStream = new MemoryStream(60000);
static bool withDeclaration = false;
public static void WriteMyDoc(object entity, string formName, string templateName)
<
#region Get Node «FormName» and remove all children ifexisted; else create a new one.
XmlDocument doc = new XmlDocument();
XmlNode e;
XmlNode template;
XMLConvert.CriteriaStream.Position = 0;
try
<
doc.PreserveWhitespace = false;
doc.Load(CriteriaStream);
>
catch (Exception ex)
<
// Unexpected XML declaration. The XML declaration must be the first node in the document, and no white space characters are allowed to appear before it.
>
e = doc.SelectSingleNode(formName);
if (e == null)
<
e = doc.CreateElement(formName);
doc.AppendChild(e);
if (!withDeclaration)
<
XmlDeclaration xmldcl =
doc.CreateXmlDeclaration(«1.0», «UTF-8», null);
doc.InsertBefore(xmldcl, e);
withDeclaration = true;
>
#region Set Attribute «Entity »
XmlElement c = null;
Type type = entity.GetType();
if (!withDeclaration)
<
((XmlElement)e).SetAttribute(«EntityName», type.FullName);
doc.AppendChild(e);
>
#endregion
#region Get Node «Template»
template = ((XmlElement)e).SelectSingleNode(templateName);
if (template == null)
<
template = doc.CreateElement(templateName);
e.AppendChild(template);
>
((XmlElement)template).RemoveAll();
#endregion
#region Add children
PropertyInfo[] properties = type.GetProperties();
foreach (PropertyInfo propertyInfo in properties)
<
bool isNullDateTime =
(propertyInfo.GetGetMethod().ReturnType.Name.Equals(«DateTime»)) &&
(DateTime)(propertyInfo.GetValue(entity, null)) ==
new DateTime(1, 1, 1);
They say that when we save xml document into memory stream, white space will be added in front of the document automatically, then the xml became illegal. But how to write the memory steam back into xml document?
error: XML declaration allowed only at the start of the document [64] #181
Comments
RobertMyles commented Jun 6, 2017
I’m trying to parse this xml http://blog.physicsworld.com/feed/ and I get the error in the title above. What I’m trying is:
This gives the error:
The xml document doesn’t have more than one declaration. Any idea what’s happening?
The text was updated successfully, but these errors were encountered:
dan87134 commented Aug 1, 2017
The document is not well-formed XML, i.e. is doesn’t conform to the format specified in the XML Recommendation. There is a bunch of whitespace preceding the xml declaration. this is not allowed. You can either delete the preceding whitespace or delete the xml declaration before processing the XML. This requirement is actually important because an XML parser does not have to be told the encoding of an xml document if it is encoded as UTF-8 or has an xml declaration. to do that is needs to know exactly what is at the very beginning of the document.
jimhester commented Jan 4, 2018
As mentioned this document does not conform to the XML specification. However, you can parse it as HTML, which is a looser parser, then fix it up after the fact.
Created on 2018-01-04 by the reprex package (v0.1.1.9000).
You can’t perform that action at this time.
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.