FPGA. Создаем хардверный счетчик в Xilinx Vivado, чтобы освоить инструменты разработки ПЛИС
Содержание статьи
О том, что такое FPGA, как они устроены и почему во многих случаях они предпочтительнее, чем CPU, GPU и ASIC, читай в предыдущей статье: «FPGA. Разбираемся, как устроены программируемые логические схемы и чем они хороши».
Для примера я возьму простую и доступную Zybo board, но все будет работать на любой современной плате Xilinx, которая поддерживает Vivado. Если понадобится поменять файл ограничений, напиши мне, я смогу помочь.
Стоит сказать о требованиях к операционной системе. Я работаю в Ubuntu 16.04, но подойдут и Windows 7 или 10, CentOS 6 и 7 или SUSE последних версий.
Устанавливаем Vivado
Первым делом скачивай Vivado Design Suite — HLx Editions — 2018.2 Full Product Installation для своей ОС отсюда (на выбор варианты для Linux и для Windows).
Перед установкой следует зарегистрироваться на сайте.
Для ознакомительных целей я рекомендую установить бесплатную версию Vivado — WEB Pack, она по набору функций ничем не отличается от платной версии, но имеет ограничение на размер дизайна. Это значит, что счетчик в ней можно спроектировать, а что-то посложнее, что можно было бы продать, — вряд ли.
Программа установки Vivado 2018.2
Xakep #236. FPGA
В конце установки откроется Vivado License Manager, также его можно открыть и из Vivado — через вкладку Help в главном меню. Сюда нам нужно подсунуть файл лицензии. Давай создадим ее.
Теперь Vivado установлена, и нам нужно убедиться, что она корректно запускается.
Открываем терминал в Linux и пишем:
Также надо установить драйверы кабеля USB для загрузки прошивки. В Windows для этого просто ставим галочку Install Cable Drivers во время установки. В Linux следует вернуться в терминал и набрать следующее:
Теперь ставим драйверы для платы Zybo:
Запускаем пример и моделируем схему
Мы спроектируем четырехбитный бинарный счетчик с задаваемым направлением счета и выводом значения на светодиоды. Счетчик будет синхронным: работать он будет на одной тактовой частоте. При работе в железе счетчик станет изменять свое значение не каждый период тактовой частоты, а один раз в секунду, иначе мы не увидим моргание (при частоте 125 МГц оно для глаза сольется в ровный свет).
После загрузки проекта в FPGA он будет работать так: каждую секунду четыре светодиода переключаются в соответствии с бинарным представлением значения счетчика. Помимо светодиодов, на плате есть еще кнопки и тумблеры. При нажатии на одну кнопку счетчик сбрасывается в ноль. Один из тумблеров разрешает счет, второй тумблер — задает направление счета.
Чтобы получить исходный код и запустить проект в Linux, нам нужно ввести такие команды:
Вейвформы сигналов при моделировании
Самое время посмотреть на исходные файлы! Закрываем симуляцию и смотрим в окно Sources.
Исходные файлы проекта
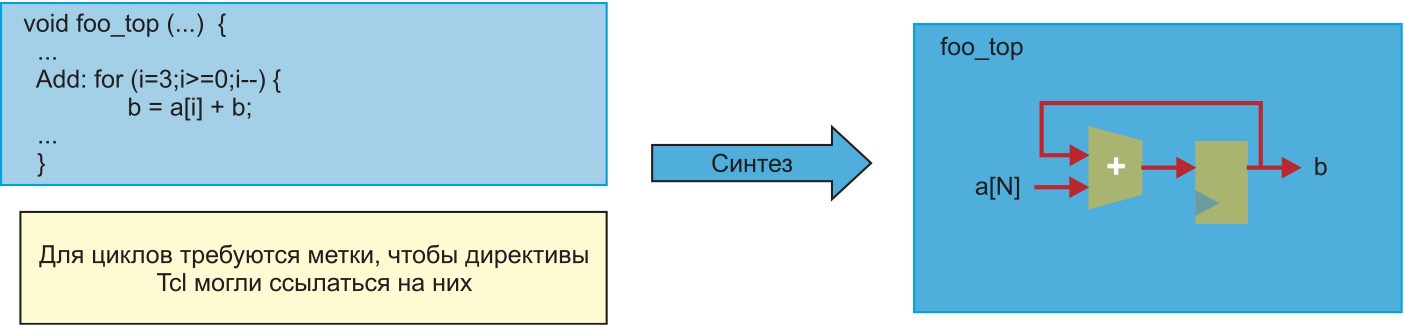
В разделе Constraints находятся файлы ограничений XDC (Xilinx Design Constraints). Как уже упоминалось, в них определяются ножки микросхемы, к которым должны подключаться порты ввода-вывода верхнего уровня RTL (top level) и период тактового сигнала.
Описание модуля counter начинается с определения его параметров и портов ввода-вывода. Параметр WIDTH определяет ширину слова регистра счетчика. По умолчанию оно равно 4, следовательно, счетчик может принимать значения без знака от 0 до 15.
Тут в начале файла точно так же идет определение параметров и портов ввода-вывода. Параметр WIDTH мы уже знаем, параметр DIV рассмотрим чуть позже. Интерфейсные сигналы модуля counter_top подсоединяются к внешним компонентам FPGA. На вход clk подается сигнал 125 МГц от внешнего кварцевого генератора, вход reset подключен к кнопке сброса, входы enable и dir — к тумблерам. Выход leds[3:0] подключен к четырем светодиодам.
Один и тот же модуль может быть вставлен в дизайне несколько раз. Логика и аппаратные ресурсы при этом дублируются, поэтому название экземпляра каждый раз должно быть уникальным.
Дальше идет блок подключения локальных сигналов модуля, где происходит вставка с указанием портов ввода-вывода того модуля, который вставляется. Синтаксис тут такой: после точки идет имя порта, затем в скобках указывается локальный сигнал для соединения с этим портом.
Получается, что cnt_en будет равен единице тогда и только тогда, когда оба сигнала div_clr и enable равны единице. Enable — это сигнал с тумблера, он либо есть, либо отсутствует, использовать его для управления частотой счета не получится.
Получается следующее: div_cnt считает по кругу от 0 до 124 999 999, div_clr на один такт системной частоты становится равен 1, и происходит это ровно один раз в секунду. Тогда и для модуля counter сигнал cnt_en будет выставляться ровно на один такт каждую секунду, и счетчик будет изменять свое значение на единицу, что мы и увидим в железе.
Синтезируем код и анализируем результат
Как ты помнишь, следующим шагом после моделирования кода RTL и выявления логических ошибок идет синтез схемы. На этом шаге абстрактные конструкции RTL реализуются в виде связанного набора компонентов аппаратных ресурсов, доступных для конкретно микросхемы FPGA.
Но прежде чем нажимать Synthesis → Run Synthesis в окне Flow Navigator, давай посмотрим на другой подход к проектированию цифровых устройств, а именно на схемотехническое описание. Раньше оно было довольно распространено в качестве основного инструмента для ввода информации о схеме, но с развитием языков VHDL и Verilog отошло на второй план. Тем не менее очень полезно взглянуть на графическое представление того, что ты написал на Verilog. Для этого во Flow Navigator жмем RTL Analysis → Open Elaborated Design → Schematic.
RTL Analysis Counter
Тут мы видим красивую и понятную схему четырехбитного счетчика, представленного регистром и комбинационной схемой, которая меняет его значение. В зависимости от значения dir через мультиплексор на вход регистра поступает либо выход схемы сумматора (инкремент текущего значения), либо выход схемы разности (декремент текущего значения).
Давай сравним эти красивые схемы с тем, что получится после синтеза. Закрываем Elaborated Design и жмем Synthesis → Run Synthesis, после окончания процесса жмем Synthesis → Open Synthesised Design → Schematic. Если ты работаешь в Vivado, то увидишь огромную схему из десятков компонентов. Найди на схеме блок counter_rtl и открой его.
Counter after Synthesis
Видно, что абстрактные комбинационные схемы типа сумматора и мультиплексора исчезли, вместо них появилось много LUT. Это уже LUT, который относится к твоему кристаллу FPGA. Разобраться в этой схеме сложнее, чем прочитать бинарный машинный код. Но это и не требуется, программы-синтезаторы, как и компиляторы кода для ЦП, сейчас достаточно развиты и надежны.
Перейдем к следующему шагу — размещению компонентов на кристалле (Place) и конфигурации связей между ними (Route). Для этого в окне Flow Navigator жмем Implementation → Run Implementation. Процесс займет пару минут.
После его завершения жмем на Implementation → Open Implemented Design, что откроет окно Device. В нем отображаются аппаратные ресурсы FPGA. Занятые ресурсы подсвечены сине-зеленым цветом. Выдели мышкой прямоугольник вокруг таких ресурсов, чтобы увеличить масштаб в этой области и увидеть отдельные CLB и занятые в них ресурсы.
Placed hardware resources
На рисунке видно, что в выбранном CLB заняты все четыре LUT и четыре из восьми триггеров, а также используется специальная цепь переноса, нужная для операции сложения. Каждый ресурс можно выделить мышкой, узнать его номер, статус и какой логической цепи он соответствует. Оставляю тебя исследовать это окно самостоятельно.
Получаем прошивку и загружаем ее в FPGA
Осталось сгенерировать файл прошивки и загрузить его в FPGA.
Жмем на Program and Debug → Generate Bitstream. После окончания процесса подключаем к плате кабель microUSB в порт PROG/UART и включаем питание тумблером на плате. Далее в Vivado жмем на Program and Debug → Open Hardware Target → Open Target → Auto Connect.
В открывшемся окне Hardware Manager правой кнопкой мыши кликаем по названию кристалла xc7z010_1 и выбираем Program Device.
Выводы
В этой и предыдущей статьях я хотел познакомить тебя с технологией FPGA: дать первое представление об использовании, архитектуре и методах проектирования.
Хотя я говорил, что существуют высокоуровневые средства проектирования на языке C/C++, все равно для успешного использования FPGA необходимо иметь твердое понимание, каким образом код C++ будет переведен в «железо» и какая цифровая схема будет синтезирована. Для этого нужно уметь проектировать на уровне RTL на языках VHDL или Verilog.
Должен сказать, что пока высокоуровневые средства не могут полностью заменить RTL и большинство команд, которые отвечают за FPGA в серьезных компаниях, продолжают использовать именно этот способ.
Для изучения RTL я хочу порекомендовать книгу «Цифровая схемотехника и архитектура компьютера» за авторством Дэвида и Сары Харрис. Все, что там написано, я считаю обязательным для понимания инженером-программистом FPGA. Еще одна книга для изучения истории и архитектуры FPGA — «Проектирование на ПЛИС. Архитектура, средства и методы. Курс молодого бойца» Клайва Максфилда. Отличное неутомительное чтение!
На рынке специалисты FPGA традиционно ценятся и у нас, и на Западе. Дело в том, что хотя задач для таких специалистов меньше, чем для других программистов, и обычно на компанию требуется не больше одной команды до пяти человек, но мест, где готовят FPGA-шников, еще меньше, а знания RTL специфичны.
Поэтому хороших спецов мало и все они нарасхват. При этом, конечно, очень важно иметь сильные навыки в других языках программирования, а также математическую подготовку для понимания вычислительных алгоритмов, которые ты реализуешь.
Главное — критично относиться к необходимости использования FPGA для решения той или иной задачи: при всех своих плюсах разработка на FPGA занимает намного больше времени, чем на CPU или GPU. Используй свои знания с умом и продолжай совершенствоваться!
Проектирование для ПЛИС Xilinx с применением языков высокого уровня в среде Vivado HLS
Введение
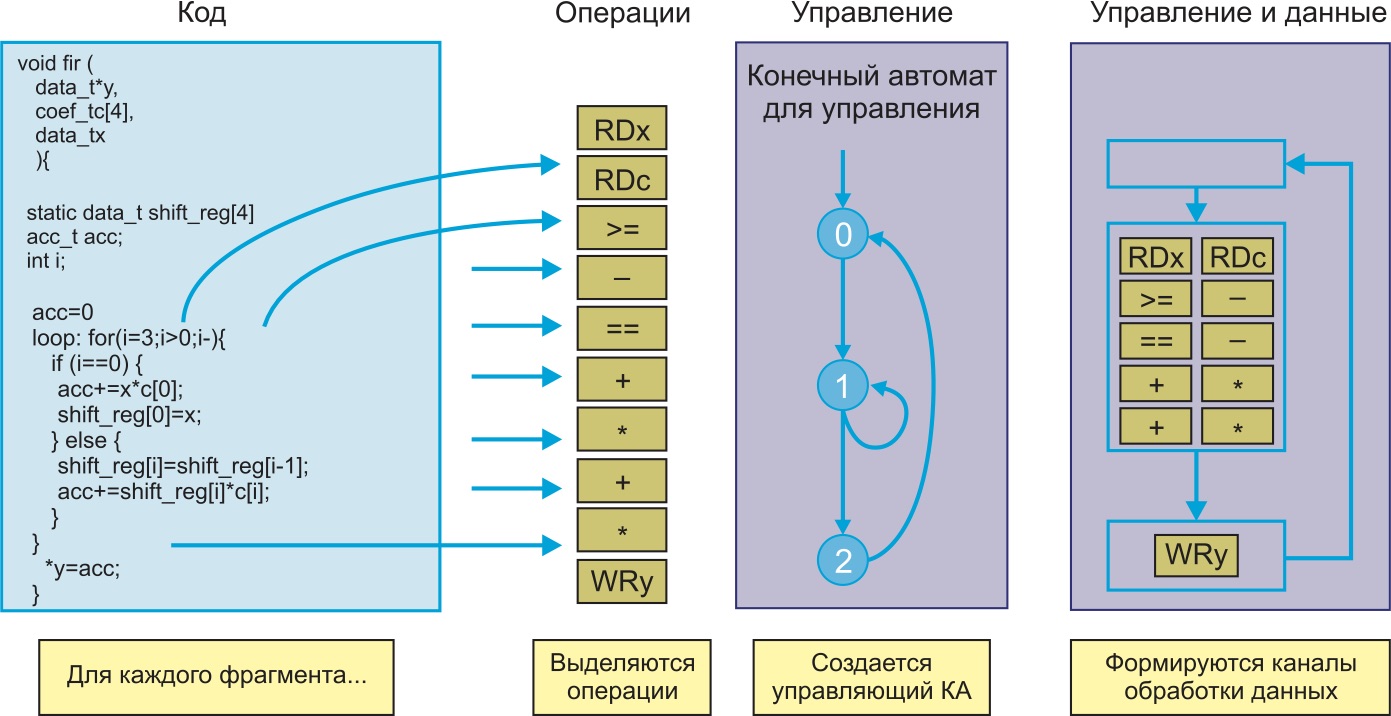
Практическое использование ПЛИС часто вызывает трудности для «чистых» программистов, которые сталкиваются с целым рядом непривычных задач: необходимостью помнить о правильном формировании тактовых сигналов, учитывать латентность, а также вообще понимать, что операторы языков описания аппаратуры не вполне эквивалентны операторам языков программирования. Например, оператор сложения, естественный для программиста, в распространенных языках описания аппаратуры ( HDL ) требует соответствующего обрамления. Разные схемотехнические решения будут получены для случая, когда сложение выполняется в виде оператора непрерывного присваивания ( continuous assignment ) и внутри синхронного процесса. В то же время, цифровая схемотехника по мере уменьшения норм технологического процесса все больше тяготеет к синхронным схемам. В итоге оказывается, что много усилий при проектировании на базе ПЛИС тратится на разработку управляющего автомата, активирующего устройства в нужные моменты времени.
Рис. 1. Упрощенный маршрут проектирования в Vivado HLS
Основные сведения об HLS
Для анализа этой схемы необходим о определить два важных понятия:
На рис. 2 эти понятия проиллюстрированы на примере простейшей конвейерной схемы. На показанной временной диаграмме видно, что каждым тактом входные данные сдвигаются на один регистр, освобождая при этом вход для приема новых данных. Таким образом, пропускная способность такой схемы составляет один такт, поскольку новые данные можно подавать каждым новым тактом. Латентность равна количеству триггеров в цепочке (в показанном случае это два такта).
Рис. 2. Понятия «латентность» и «пропускная способность»
Эти понятия играют важную роль при разработке высокопроизводительных цифровых схем. При построении сложных комбинаторных схем период тактового сигнала определяется самой длинной цепью, соединяющей синхронные компоненты. Поэтому очевидным способом повышения тактовой частоты (т о есть уменьшения периода тактового сигнала) является разделение длинных цепей триггерами. При этом, очевидно, увеличивается латентность схемы, однако это является побочным эффектом на пути к достижению более приоритетной цели — увеличению тактовой частоты при сохранении пропускной способности, равной одному такту между новыми входными отсчетами.
Рис. 3. Основы Vivado HLS — управление синтезом с помощью директив
По аналогии с разворачиванием цикла в компиляторах языков программирования такой цикл также можно развернуть (этот прием называется loop unrolling ). При этом каждая итерация цикла рассчитывается индивидуальным элементом. За счет одновременного выполнения всех итераций латентность становится существенно меньше, однако количество ресурсов, требуемое для реализации такой схемы, возрастает практически пропорционально.
Рис. 4. Принципы автоматического создания управляющих автоматов в Vivado HLS
Рис. 5. Влияние характеристик аппаратной платформы на формирование управляющего автомата
Таким образом, при генерации схемы Vivado HLS действует следующим образом:
Рис. 6. Формирование аппаратных интерфейсов для блоков
Циклы в Vivado HLS
Рис. 7. Реализация циклов в HLS
Листинг 1. Пример «идеального цикла» ( perfect loop ) в Vivado HLS
Таблица. Результат ы синтеза проекта из листинга 1
Период, нс (требуемый период — 25 нс)
Логических генераторов (LUT)
Без дополнительных директив
HLS _ UNROLL для внутреннего цикла
HLS _ UNROLL для внешнего цикла
HLS _ UNROLL для внутреннего и внешнего циклов
Результаты синтеза без дополнительных директив предсказуемы. Цикл имеет в общей сложности 400 итераций (2 0 0 на внешнем и 20 0 на вложенном уровне). Добавляя латентность на вспомогательные пересылки, можно объяснить появление значения 403 в таблице. Это решение имеет минимальный размер.
Следующий шаг эксперимент а — установка директивы UNROLL только для внешнего цикла. Однако результаты оказываются, на первый взгляд, неожиданными : при резком увеличении ресурсов латентность не только не уменьшилась, но и несколько увеличилась. Внешний цикл действительно оказался развернут, и каждая итерация получила собственный экземпляр устройства умножения. Однако в этом случае каждая итерация внешнего цикла ожидает зав ершения работы вложенного цикла, поэтому для работы требуется целых 460 тактов.
Массивы и работа с памятью
Использованию памяти в HLS следует уделять особое внимание. Обычно программист для PC не рассматривает память в качестве отдельного ресурса, поскольку все используемые данные автоматически помещаются в основную память компьютера. При оптимизации программ речь может идти о временном размещении каких-то значений в регистрах, учете особенностей кэширования и т. п. Однако для ПЛИС возможности размещения данных существенно шире.
Во-первых, память может быть физически реализована в виде следующих аппаратных ресурсов:
Из-за этих факторов необходимо тщательно продумывать распределение данных, чтобы обеспечить их размещение в ресурсе такого типа, который позволит максимально эффективно использовать особенности ПЛИС. При программировании также необходимо следить, чтобы выбранные синтаксические конструкции не сделали невозможн ым размещение данных в памяти, которую имеет в виду разработчик. Можно констатировать, что в настоящее время результаты работы компилятора HLS сильно зависят как от особенностей исходного текста, так и от использованных директив. У программиста, знакомого с С, может сложиться впечатление, что результаты работы HLS в ряде случаев весьма далеки от совершенства.
Разработчик, работающий с памятью в языках программирования высокого уровня, не нуждается в решении такой задачи, поскольку независимо от вида массивов и порядка обращения к ним пропускная способность памяти компьютера или микроконтроллера ограничена, причем чаще всего единственным интерфейсом. Вопросы распределения данных по областям памяти могут оказаться актуальными для редких случаев многоядерных систем, имеющих сложную структуру доступа к памяти по физически раздельным шинам.
Директива RESHAPE выполняет обратное действие — объединяет несколько независимых областей данных в один массив. В сочетании с предыдущей директивой она позволяет управлять размещением данных в физических блоках, увеличивая или уменьшая количество независимых шин, с помощью которых выполняется доступ к данным.
Поддержка языков высокого уровня
Важным отличием от языков программирования является поддержка так называемых arbitrary — precision типов, т о есть типов данных с явно указываемой разрядностью. Это отличие считается таким важным потому, что при программировании разработчик имеет дело с процессором, обрабатывающим данные фиксированной разрядности, определяемой конструкцией этого процессора. Изменение разрядности с точки зрения программы возможно, однако редко целесообразно. В противоположность этому при проектировании цифровых систем разработчик имеет возможность явно указать разрядность обрабатываемых данных, которая наилучшим образом соответствует решаемой задаче. Для разных языков типы отличаются:
При использовании указателей необходимо обращать дополнительное внимание на получаемые результаты. Вообще при работе с HLS необходимо помнить, что FPGA имеют гибкую архитектуру, позволяющую реализовать требуемое поведение множеством способов, в отличие от выполнения программы на процессоре или микроконтроллере. Стиль программного кода, используемые синтаксические конструкции и директивы компилятора способны оказать существенное влияние на получаемые результаты.
Работа с HLS
Рис. 10. Стартовый экран Vivado HLS
Основные шаги по созданию проекта удобно рассмотреть на практическом примере, содержащем простейшую схему. На рис. 11 показан о стартовое диалоговое окно « мастера » создания нового проекта.
Рис. 11. Стартовое диалоговое окно «мастера» создания нового проекта
Рис. 12. Диалоговое окно настройки синтезируемой части проекта
Рис. 13. Настройка решения (solution)
Рис. 14. Окно САПР Vivado HLS после завершения работы «мастера» создания проекта
Рис. 15. Окно САПР после завершения синтеза схемы и формирования отчета
Далее в проект можно добавить тестовый модуль, с помощью которого можно будет проверить работу синтезированного проекта. Тестовый модуль является элементом более в ысокого уровня по отношению к синтезируемому, но он также может обращаться и к другим файлам, содержащим несинтезируемый код. Пример простейшего теста показан в листинге 4.
Листинг 4. Тестовый файл для моделирования поведения синтезированного модуля
Рис. 16. Консоль Vivado HLS после завершения работы теста
Листинг 5. Исходный текст модуля верхнего уровн я быстрого преобразования Фурье
Сгенерированный проект обладает следующими характеристиками:
Также можно обратить внимание на то, что латентность указана в виде интервала значений. Такое поведение HLS весьма важно для последующего анализа его применения.
Vivado HLS в сравнении с другими средствами проектирования Xilinx
Почему при этом делается упор на разработку систем цифровой обработки сигналов? Прежде всего потому, что применение HLS само по себе не гарантирует качественного роста производительности. Далеко не каждая программа, написанная на С, может быть эффективно реализована в ПЛИС. Функциональности компилятора HLS недостаточно, чтобы для произвольного программного продукта определить именно те участки кода, аппаратное ускорение которых даст существенное увеличение эффективности программно-аппаратного комплекса в целом. Из известных сфер применений именно цифровая обработка сигналов с ее потенциальной возможностью задействовать параллельные вычислительные структуры может получить существенный выигрыш при реализации в FPGA по сравнению с другими аппаратными платформами. Это не исключает применения HLS и в других задачах, но для алгоритмов ЦОС, по крайней мере, хорошо известны типичные решения на основе параллельных вычислительных структур.
Таким образом, для систем цифровой обработки сигналов в настоящее время существует три подхода:
В то же время результаты работы HLS имеют две особенности, которые могут затруднить применение разработанных модулей:
Заключение
Разработка процессорной системы на базе софт-процессора MicroBlaze в среде Xilinx Vivado IDE/HLx. Часть 1.
Дата: 15.04.2017 23:04
В этой статье описаны основные этапы разработки процессорной системы на базе софт-процессора MicroBlaze [1, 2] в среде Xilinx Vivado [3]. Будут рассмотрены только основные моменты и шаги, которые позволят Вам быстро собрать процессорную систему из ресурсов ПЛИС/FPGA, а также получить общее представление о ходе её построения и подключения периферии.
Разработка систем на FPGA давно перестала ограничиваться простым написанием кода на языках описания аппаратуры (HDL); и по мере возрастания количества логических ресурсов и сложности проектов, подходы к проектированию систем на FPGA многократно пересматривались. Одним из витков развития стало внедрение в проекты софт-процессоров – по сути обычных микропроцессоров, но собранных на ресурсах FPGA. Такой подход даёт разработчикам гибкость системы и ещё больше объединяет области сотрудничества HW (hardware – аппаратных) и SW (software – программных) инженеров. К сожалению, несмотря на относительную несложность разработки софт-процессорных систем, многие пытаясь «поднять» эту тему, сталкиваются с трудностями освоения, потому что не знают где найти нужную информацию, а если и находят, то не знают с чего начать.
Цель статьи – дать общее представление об этапах сборки процессорной системы на базе софт-процессора Microblaze, используя среду Xilinx Vivado.
К сожалению, в рамках одной статьи сложно описать все многообразие процесса построения софт-процессорных систем на FPGA и детально изложить все сопровождающие его «тонкие» моменты, но с чего-то начать необходимо. В последующих статьях мы рассмотрим подключение Ethernet, различных контроллеров памяти, внешних интерфейсов, разберём работу компонентов, связывающих MicroBlaze с периферией и многое другое. Но это будет чуточку позже, а для начала…
Примечание: надо сказать, что при создании софт-процессорной системы, точнее для её отладки Вам всё же придётся иметь какую-нибудь макетную плату с FPGA Xilinx 7-го семейства [4] или же уметь пользоваться QEMU эмулятором. Простое моделирование через симулятор XSIM здесь не есть решение проблемы. Моделирование запустится, но сколько понадобится времени чтобы посмотреть, что светодиод моргает – я сказать не могу; возможно – дни и недели машинного времени. Поэтому крайне рекомендую обзавестись недорогой макетной платой. экспериментировал на Arty Board от компании Digilent [5], именно на ней и будет проходить текущее и дальнейшее «обучение». Рекомендую читателям обзавестись ею, поскольку кристалл, установленный на ней, поддерживается бесплатной (Web) версией Vivado, но при этом с платой поставляется полноценная лицензия. В России плата обошлась мне в 153 доллара, заказывал через компанию Регион Вирта [6], поскольку они могут работать с физическими лицами. В интернет магазинах (включая AliExpress) в то время плата стоила гораздо дороже. Возможно, сейчас ситуация изменилась – проверьте.
Разработка любой процессорной системы, построенной на ресурсах FPGA, состоит из двух фундаментальных частей: сборки аппаратной платформы HW – hardware, и разработки исполняемой программы SW – software. HW-часть разрабатывается в среде Xilinx Vivado в модуле IP Integrator [7] (Vivado IPI) и представляет собой создание собственно экземпляра (или нескольких – для многопроцессорной системы) ядра MicroBlaze, соединение его c необходимой периферией и распределение адресного пространства. Разработка кода для MicroBlaze выполняется в Xilinx SDK [8] на ассемблере или C/C++. Процесс сборки HW-части в Vivado IPI во многом похож, на аналогичный в предшествующих средах Xilinx – ISE и PlanAhead (где для этого использовалась утилита XPS – Xilinx Platform Studio), но имеет ряд отличий от него. Сохранились общие принципы, различия же встречаются, по большей части, в представлении системы. В одной из последующих статей мы разберём процесс разработки в XPS. Со стороны же программной (SW-части) никаких отличий нет: для работы с программной частью также используется Xilinx SDK. Разработка аппаратной платформы начинается с запуска Vivado и создания проекта.
Воспользуемся одним из способов открытия стартового окна Vivado, используя TCL Shell (Пуск – Xilinx Design Tools – Vivado 201x.x – Vivado 201x.x Tcl Shell (см. рис. 1)).
Рисунок 1. Расположение Tcl Shell в меню Пуск
В этом проекте я использую Vivado 2015.4, потому что в ней нет некоторых ошибок, присутствующих в последующих версиях. Для себя считаю её оптимальным вариантом по занимаемому на жёстком диске объёму, стабильности, функциональности и быстродействию. В более новых версиях этапы разработки HW-части либо полностью, либо почти полностью аналогичны или точь в точь повторяют описанную здесь последовательность действий. В открывшемся окне пишем команду start_gui (рис. 2). Нажимаем Enter и ждём окончания выполнения команды.
Рисунок 2. Tcl Shell и запуск Vivado с помощью команды start_gui
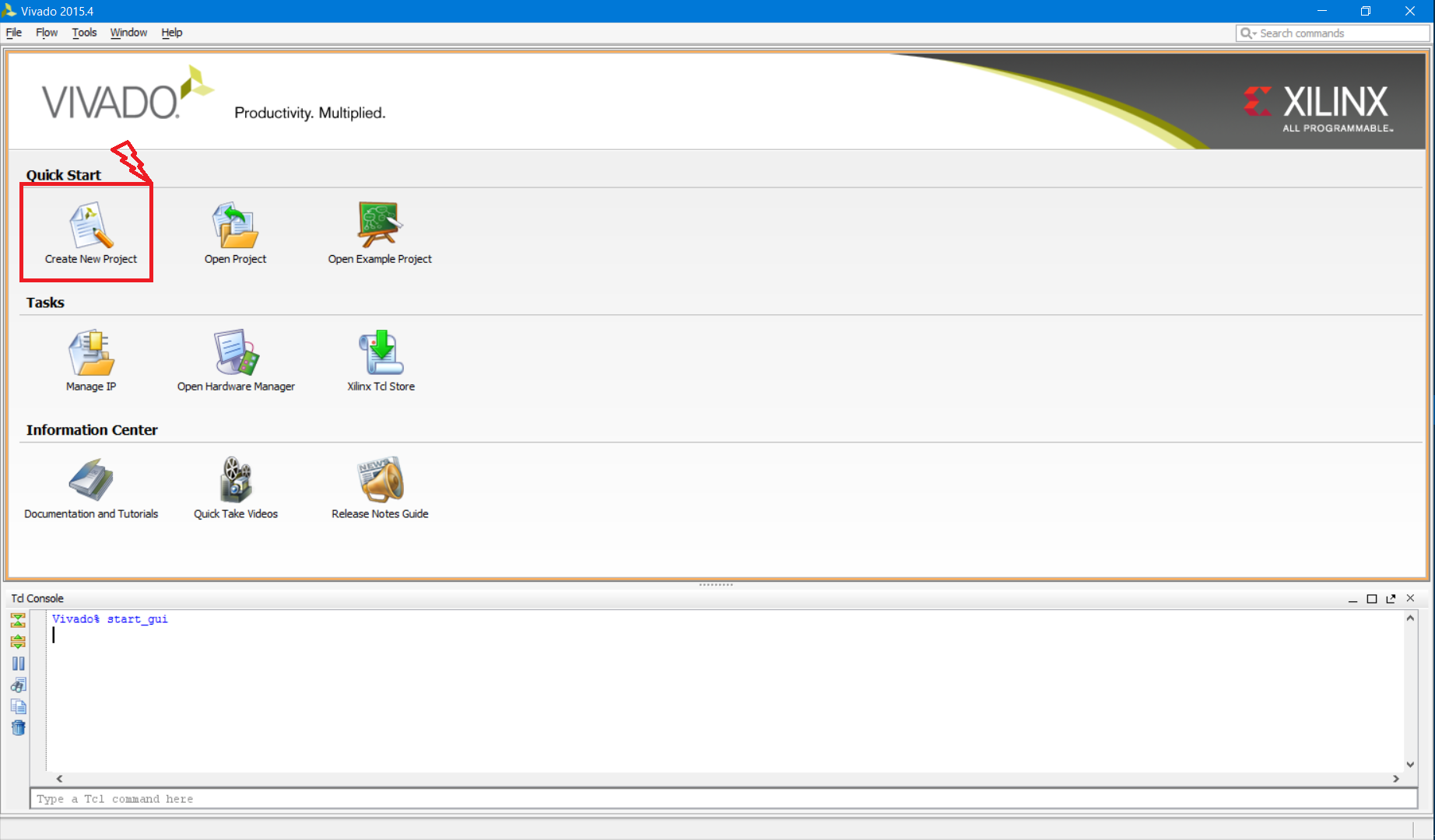
После завершения выполнения команды появится стандартное окно Vivado (рис. 3). В зависимости от версии интерфейс может несколько отличаться; описание и скриншоты в статье будут соответствовать версии 2015.4. Приступаем к созданию нового проекта. Нажимаем Create New project (рис. 3)
Рисунок 3. Окно Vivado 2015.4, красным выделена кнопка создания нового проекта
После нажатия кнопки появится мастер создания нового проекта, в котором нажимаем кнопку Next (рис. 4).
Рисунок 4. Окно мастера создания нового проекта
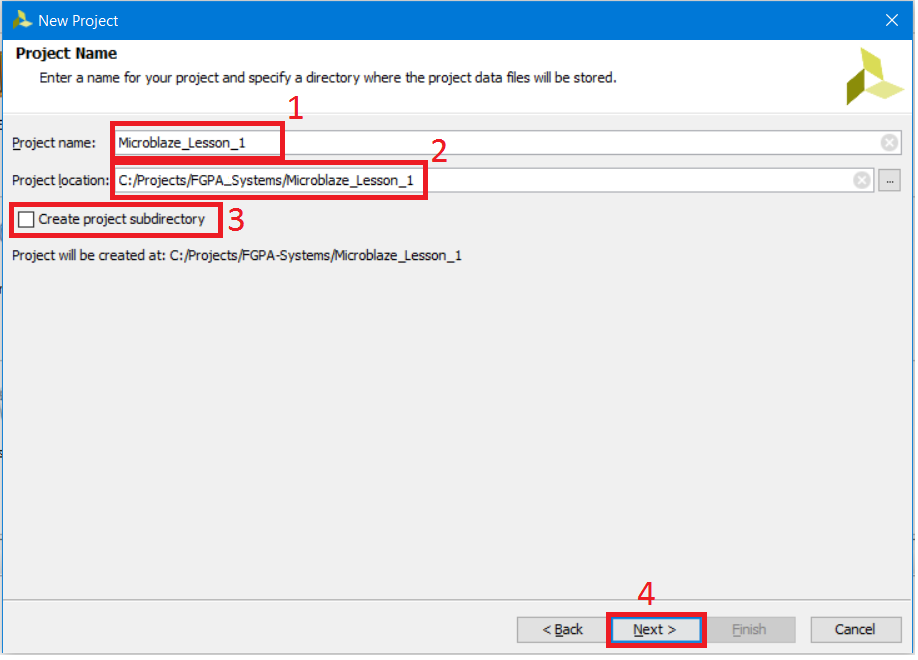
На странице Project Name (рис. 5) указываем: 1. Название проекта – в поле Project name пишем Microblaze_Lesson_1 2. Место расположения проекта – в поле Project location указываем ту папку, которую Вам будет удобно использовать. Не используйте в названии пути русские буквы, пробелы, тире и специальные символы:
3. Снимаем галочку Create project subdirectory – иначе по указанному нами пути среда создаст подпапку с введённым нами именем проекта и поместит его файлы уже туда. 4. Нажимаем кнопку Next
Рисунок 5. Окно мастера создания нового проекта: название проекта, путь к проекту
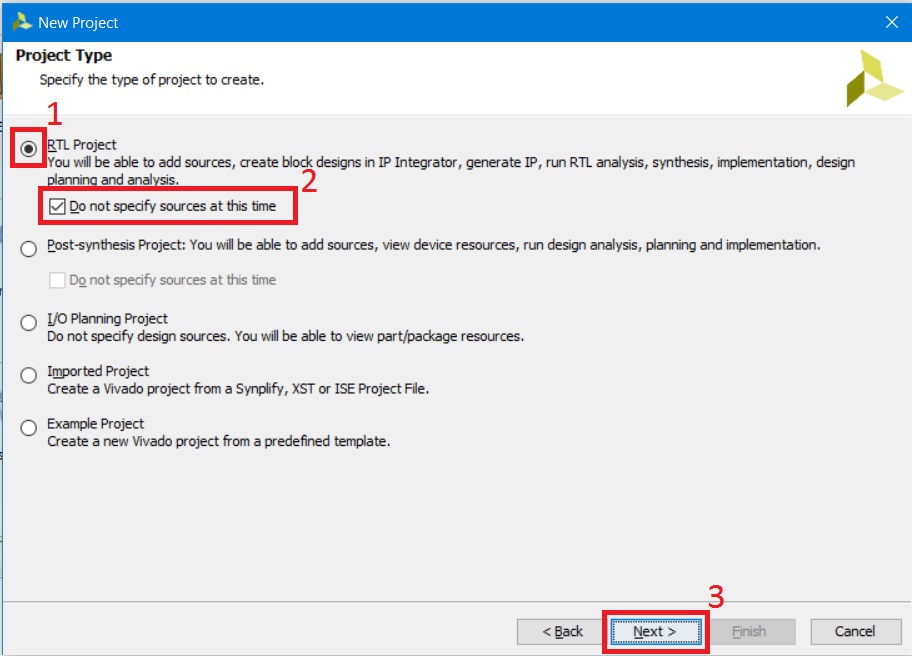
На странице Project Type (рис. 6): 1. Выбираем тип проекта RTL Project, потому что мы будем создавать с нуля обыкновенный проект с добавлением IP-ядер и последующей имплементацией. 2. Ставим галочку Do not specify…, потому что при создании этого проекта никакие файлы мы в него добавлять не будем 3. Нажимаем кнопку Next
Рисунок 6 Окно мастера создания нового проекта: выбор типа создаваемого проекта
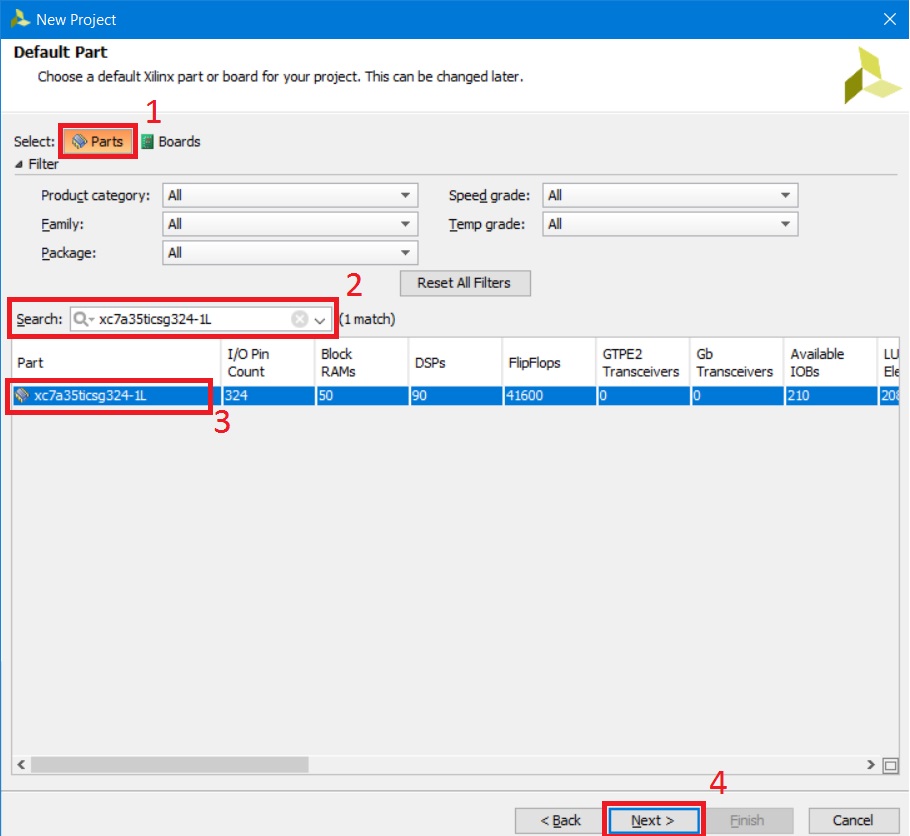
На странице Default Part выбираем (рис. 7): 1. Вкладку Parts с перечнем FPGA, доступных для текущей версии Vivado. 2. В поле поиска Search пишем название кристалла, стоящего на плате. На Arty Board установлена FPGA xc7a35ticsg324-1L 3. В списке выбираем нашу FPGA 4. Нажимаем кнопку Next
Рисунок 7. Окно мастера создания нового проекта: выбор FPGA
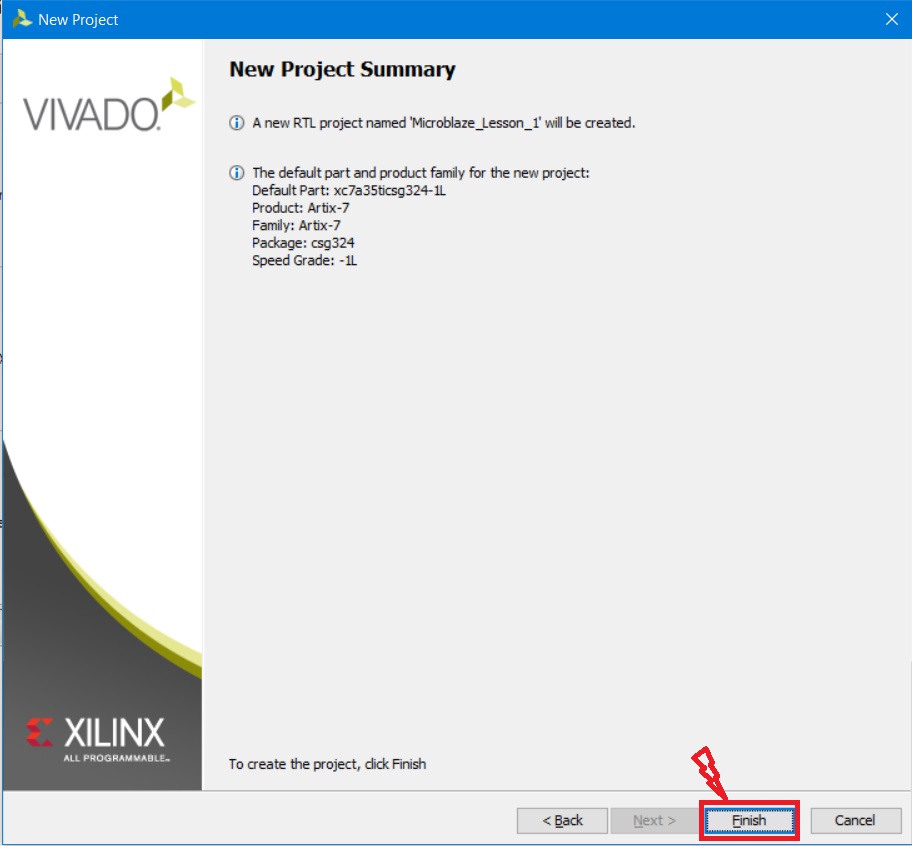
На этом создание нового проекта закончено. В окне New Project Summary (рис. 8) отображается суммарная информация о созданном проекте. Нажимаем кнопку Finish.
Рисунок 8. Окно мастера создания нового проекта: суммарные сведения о создаваемом проекте
Если Вы что-то захотите поменять в проекте, это можно сделать в любой момент во вкладке Tools – Project settings (рис. 9)
Рисунок 9. Кнопка для изменения настроек проекта
Для разработки HW-части софт-процессорной системы в Vivado используется IP Integrator [7], а сам процесс построения основан на добавлении и соединении готовых IP-ядер, которые могут быть как от Xilinx, так и от других фирм, а также разработанными Вами самостоятельно. Для запуска IP Integrator нужно нажать кнопку создания нового блочного проекта Create Block Design, которая находится в панели Flow Navigator – группа IP Integrator, пункт Create Block Design (рис. 10).
Рисунок 10. Кнопка создания нового блочного проекта
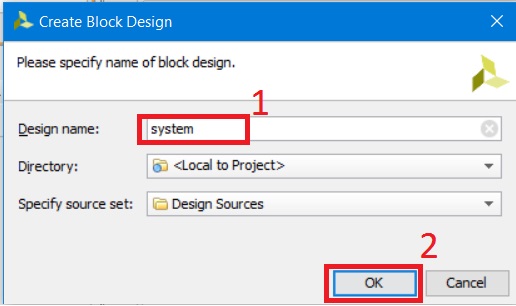
После нажатия на кнопку создания нового блочного проекта появится окно (рис. 11), которое позволяет задать его имя, определить папку для его размещения, если предлагаемая по умолчанию Вас не устраивает, и определить к какой подгруппе основной панели (дизайн или моделирование) будет относиться этот блок. Изменим: 1. Имя проекта на system 2. Нажимаем кнопку OK
Рисунок 11. Окно настроек создаваемого блочного проекта
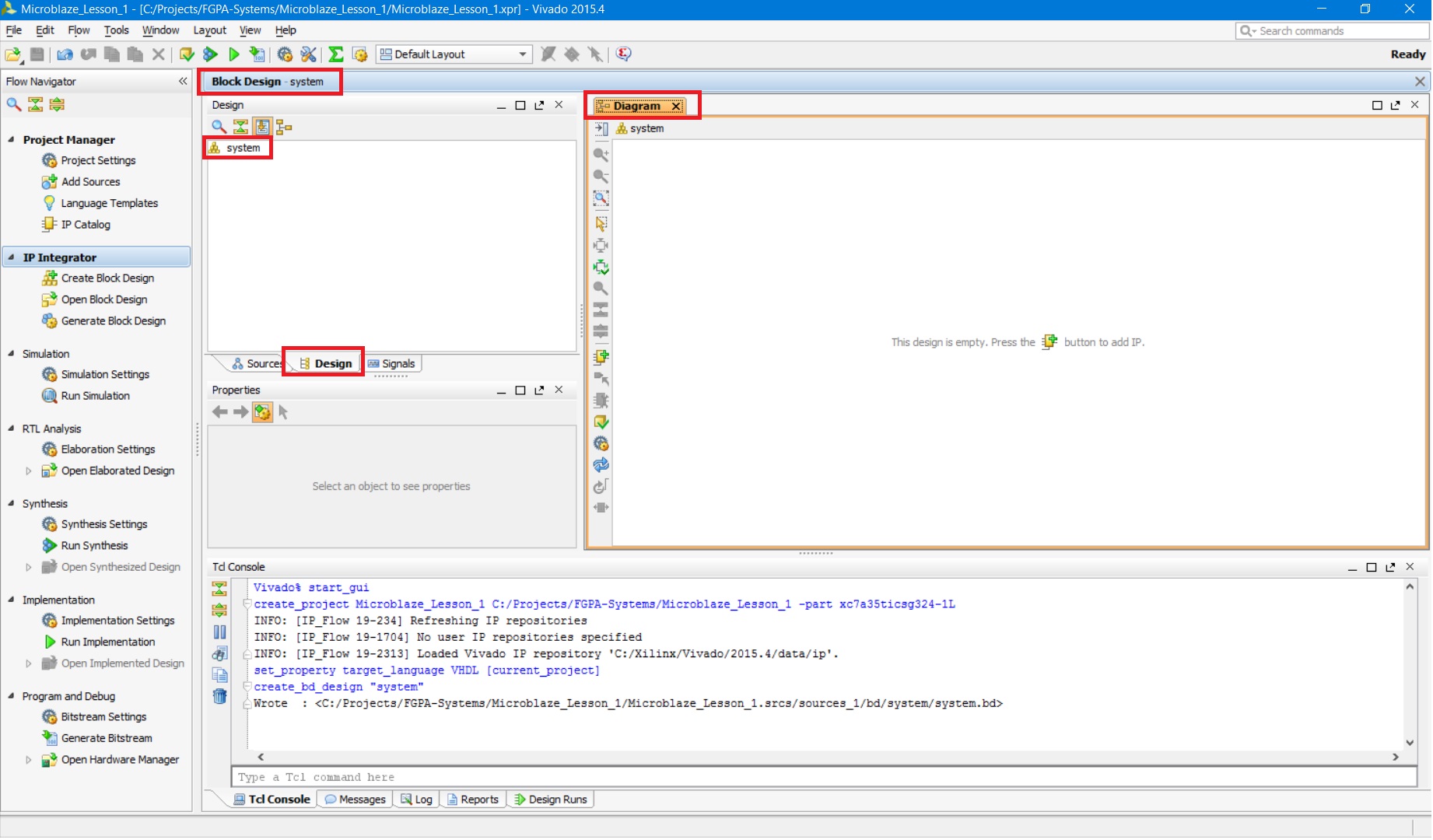
После нажатия на кнопку OK Vivado перейдёт в режим IP Integrator: (рис. 12).
Рисунок 12. Окно Block Design с различными доступными вкладками
Теперь мы можем начать собирать процессорную систему. Процесс этот во многом автоматизирован, и мы этим воспользуемся. Первое, что нам необходимо добавить в софт-процессорную систему – это сам софт-процессор MicroBlaze. Есть несколько вариантов его исполнения и добавления, но для проектирования таких простых систем, как наша, обычно используется мастер настройки. Для добавления IP-блоков на схему проекта (вкладка Diagram) можно воспользоваться кнопкой Add IP , расположенной в панели инструментов слева во вкладке Diagram или нажать Ctrl+I. После нажатия на кнопку откроется каталог блоков, которые можно добавить на поле Diagram (рис. 13).
Рисунок 13. Окно со списком доступных IP блоков, после нажатия на кнопку Add IP
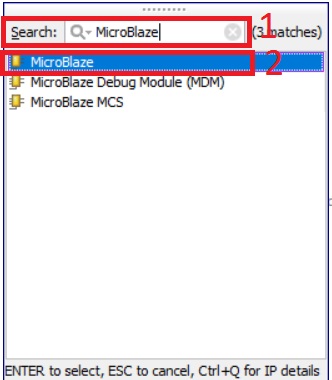
В появившемся окне со списком доступных IP блоков (рис. 14) в поле поиска Search пишем MicroBlaze и выбираем из найденных позиций MicroBlaze. Остальные два это MicroBlaze Debug Module (MDM) – отладчик для MicroBlaze, который будет позже добавлен автоматически, и микроконтроллерная система на базе MicroBlaze – фактически, ещё один вариант кастомизации процессорной системы.
Рисунок 14. Окно со списком доступных IP блоков, с отфильтрованным списком MicroBlaze
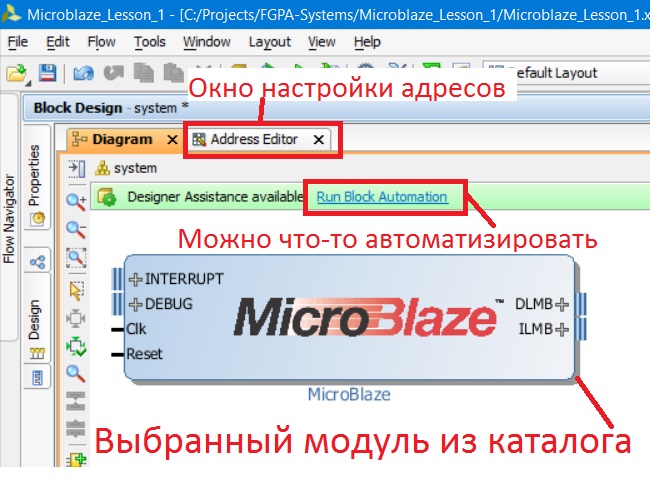
Дважды кликаем по MicroBlaze, после чего IP блок появляется на поле (рис. 15). Обратите внимание, что также появилось окно настройки адресов (об этом позже), и «свесилась» зелёная строка помощи, которая появляется, если Vivado может как-то автоматизировать процесс (в нашем случае появилась надпись-ссылка Run Block Automation) и сам модуль MicroBlaze возник на поле Diagram.
Рисунок 15. Появление дополнительных вкладок, опций автоматизации и IP блока после его добавления
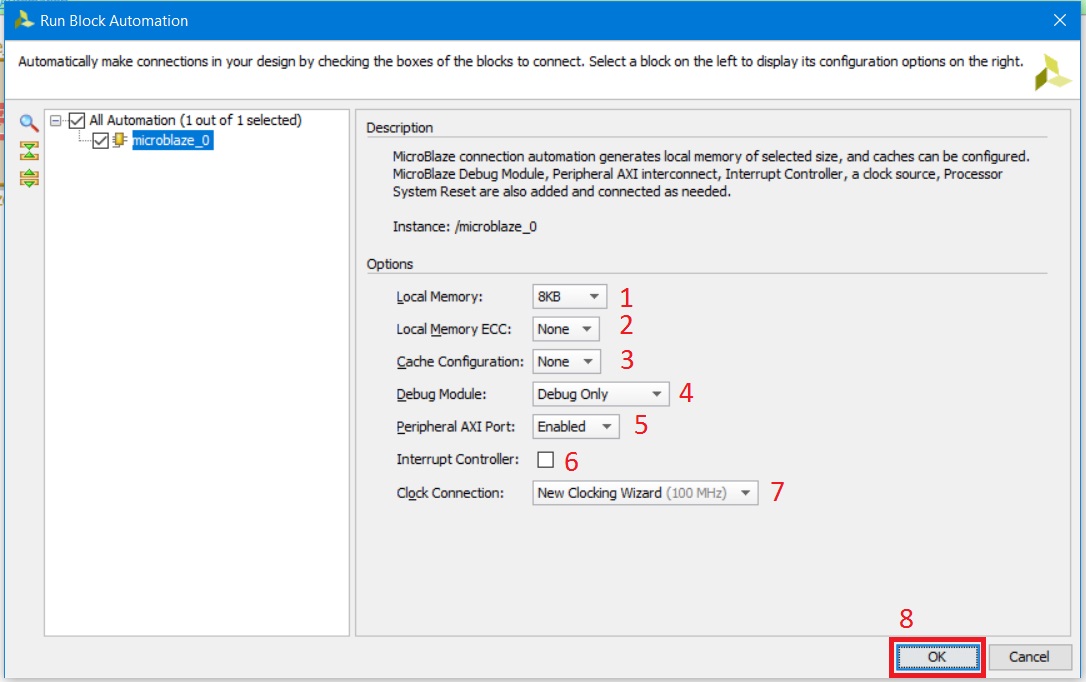
Воспользуемся предлагаемой автоматизацией, нажав на ссылку Run Block Automation, после чего появится окно с мастера экспресс настроек процессорной системы (рис. 16). После вызова мастера доступны именно экспресс-настройки, то есть те, которые используются наиболее часто. Расширенные настройки доступны по двойному щелчку на IP-блоке MicroBlaze, но это выходит за рамки текущей статьи.
Рисунок 16. Мастер экспресс настроек процессорной системы
Из предлагаемых настроек доступны: 1. Количество памяти для программы и данных 2. Управление механизмом коррекции ошибок 3. Конфигурация кэша 4. Конфигурация отладчика (тот самый MDM из списка) 5. Задействование/отключение порта сопряжения с периферией (AXI-порта) 6. Включение/выключение контроллера прерываний 7. Выбор сигнала тактирования Оставим все настройки в значениях по умолчанию и нажмём кнопку OK, т. к. для нас этих параметров достаточно. После окончания работы мастера на поле появится множество новых блоков, которые мы разберём ниже. Для оптимизации рабочего поля нажмите кнопку перестроить в панели инструментов (рис. 17).
Рисунок 17. Результат работы мастера экспресс-настроек после оптимизации рабочего поля
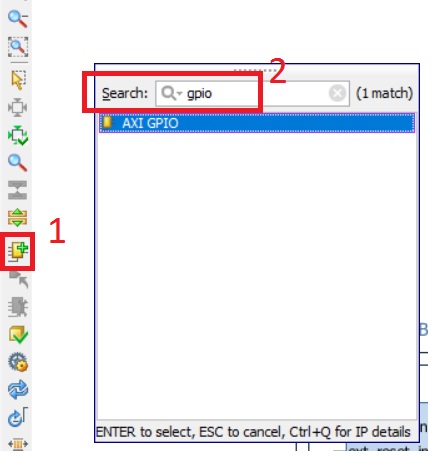
Рисунок 18. Поиск GPIO в каталоге доступных IP блоков
На схему должен добавиться блок, изображённый на рис. 19.
Рисунок 19. Блок AXI GPIO
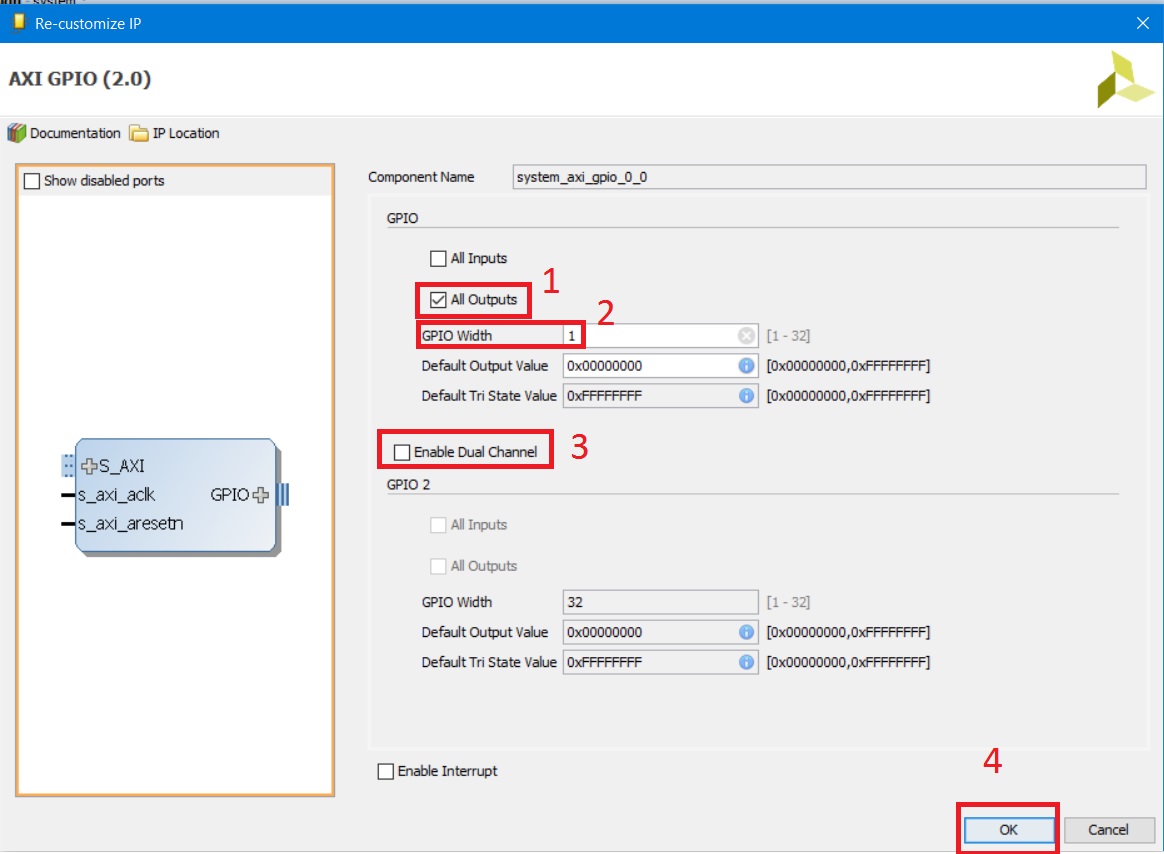
После добавления блока AXI GPIO необходимо его настроить, задать разрядность портов, определить направление и количество каналов. Настройка производится двойным щелчком по блоку либо выбором Customize Block из контекстного меню, открывающегося по щелчку правой кнопкой мыши. Модуль axi_gpio_0 будет управлять светодиодом, периодически включая и выключая его. Значит axi_gpio_0 должен быть сконфигурирован следующим образом (рис. 20)
Рисунок 20. Настройка блока AXI GPIO
1. Задаём направление портов блока AXI GPIO – выбираем, что все выводы являются выходами, т. к. мы управляем светодиодом, а не он нами. 2. Ставим разрядность порта 1 – всего будет подключён 1 светодиод. 3. Второй канал нам не нужен, отключаем его. 4. Нажимаем кнопку OK. Нажав плюсик около интерфейса GPIO модуля axi_gpio_0 увидим, что порт gpio_io_o имеет разрядность 1 (вектор [0:0]) – рис. 21.
Рисунок 21. Вид блока AXI GPIO после настройки
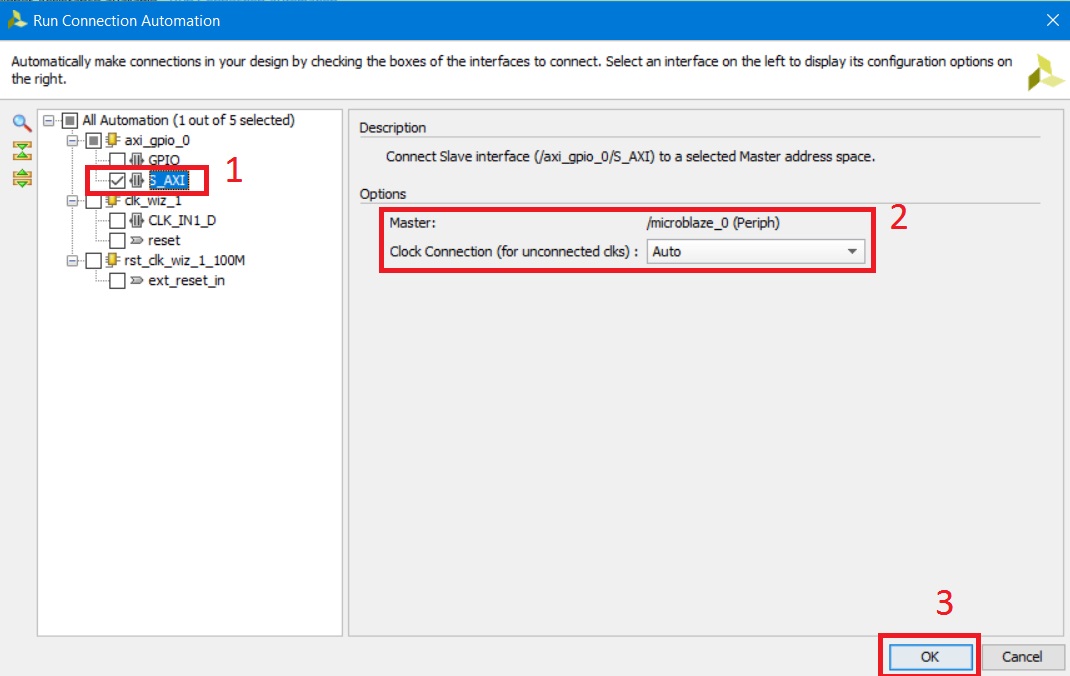
Теперь давайте попробуем подключить наш настроенный блок AXI GPIO к MicroBlaze. Предлагаю довериться автоматике и посмотреть, что нам создаст Vivado. Нажимаем на строку Run connection Automation (см рис. 19) и ждём появления окна помощника доступных подключений (рис. 22)
Рисунок 22. Окно помощника подключений
В окне помощника подключений: 1. Выберите подключение axi_gpio_0 и поставьте галочку S_AXI (далее мы рассмотрим и поясним это подключение). 2. Установите подключение тактового сигнала как Auto. 3. Нажмите OK. После завершения подключения нажмите кнопку оптимизации рабочего пространства в панели инструментов. Как вы можете заметить, появился дополнительный модуль AXI Interconnect [11] (рис. 23). Кратко опишу его назначение. Дело в том, что взаимодействие между процессором и периферией происходит по шине AXI [12] (о ней и её видах должна быть отдельная статья, если кто то захочет в этом помочь – напишите мне). На шине есть мастер (обычно это процессор) и слэйв (Slave), в нашей литературе это ведущий и ведомый соответственно. Мастер отправляет команды слейву. Однако AXI не позволяет подключить к мастеру более одного слейва напрямую. Именно напрямую нельзя, но можно через коммутатор, который и называется AXI Interconnect – назначение этого модуля обеспечить подключение между несколькими мастерами и несколькими слейвами. Пока в нашей системе один мастер – microblaze_0 и один слейв – axi_gpio_0.
Рисунок 23. Результат работы помощника подключений: автоматическая вставка модуля AXI Interconnect, его подключение к MicroBlaze и AXI GPIO
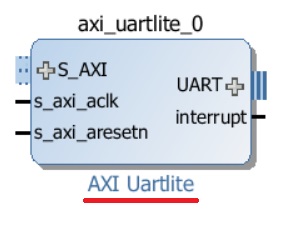
После работы мастера синяя строка сверху не пропала. Это потому что ещё есть что автоматизировать, но делать этого мы пока не будет. Теперь давайте попробуем добавить модуль UART Lite в нашу систему. Надеюсь, что последовательность запомнили. Нажимаем кнопку , вводим в строке поиска Uartlite, дважды кликаем и ждём. Если все сделали корректно, должен появиться модуль как на рис. 24.
Рисунок 24. Блок Uartlite (именно Uartlite, а не тот, который не Uartlite)
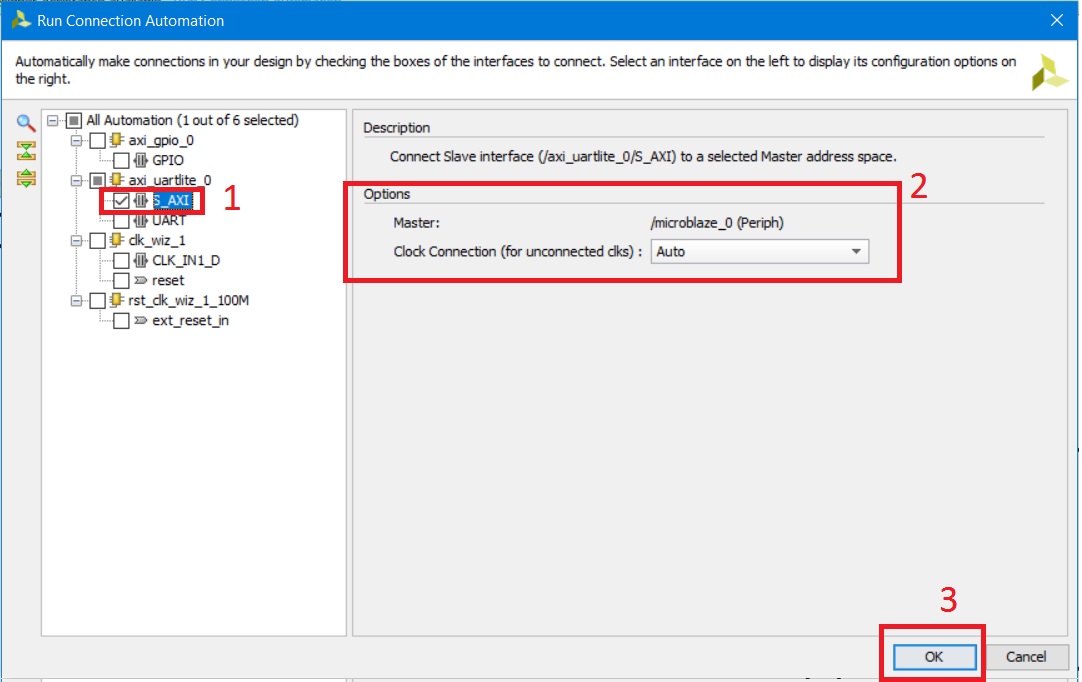
При желании просмотрите доступные настройки для модуля и если есть необходимость, измените. Настройки обычные: скорость (9600), количество стоп бит (1), чётность (нет), количество бит (8). Для подключения Uartlite к нашей системе, давайте вновь воспользуемся автоматизацией, которую предлагает Vivado, нажав строку Run Connection Automation. Для модуля axi_uart_0 выберите S_AXI и нажмите OK (рис. 25).
Рисунок 25. Настройка помощника подключений для Uartlite
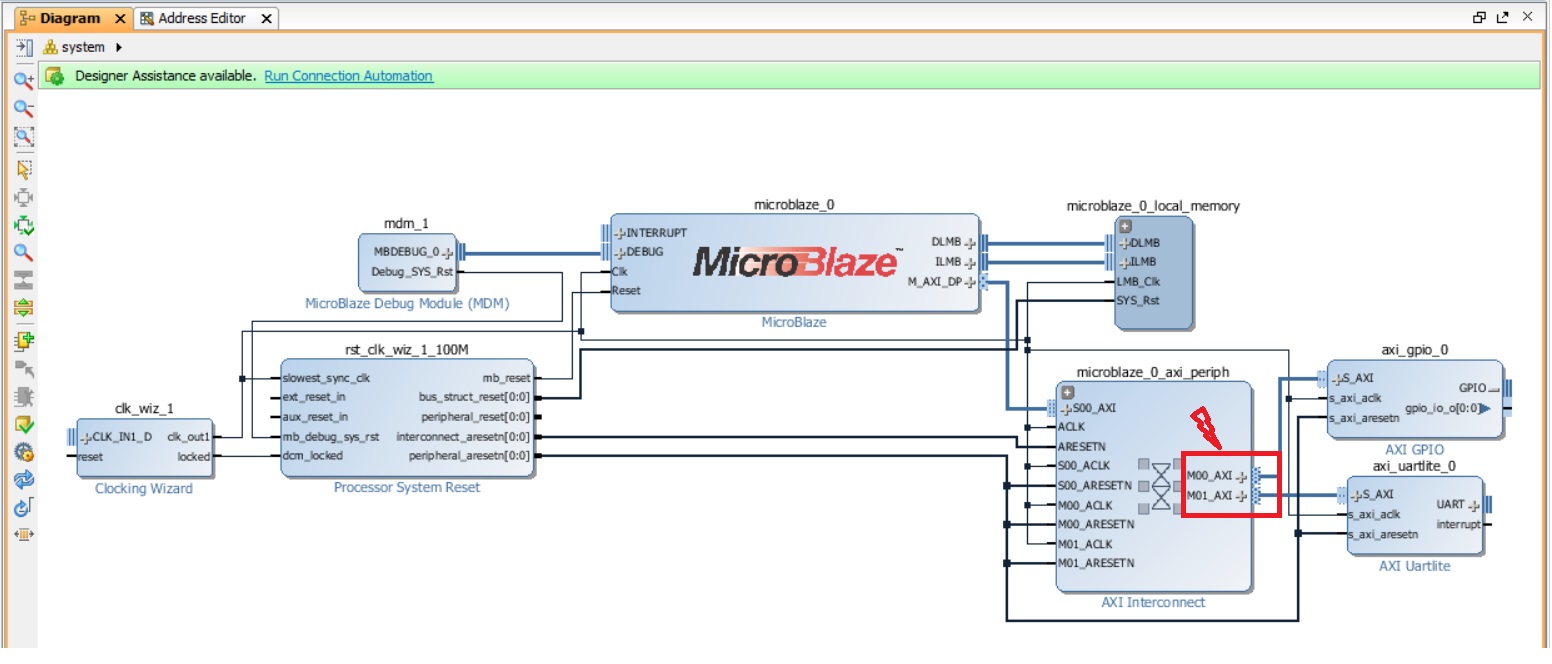
После завершения подключения нажмите кнопку оптимизации рабочего пространства в панели инструментов и обратите внимание на изменения в AXI Interconnect (если не помните что было, обратитесь к рис. 23). Что произошло и почему? В AXI Interconnect добавился дополнительный мастер-порт для подключения второго слэйва (Uartlite – это ведомое устройство). MicroBlaze имеет один мастер-порт, который называется M_AXI_DP. Мастер один, а слейва два, но подключать напрямую можно только один слейв. Для подключения нескольких слейвов мы используем AXI Interconnect. Поэтому в AXI Interconnect добавился ещё один порт (рис. 26). В общем случае, AXI Interconnect может обеспечивать взаимное подключение нескольких мастеров и нескольких слейвов.
Рисунок 26. После окончания работы помощника подключений, количество слейв устройств на шине стало равным двум. Поэтому в AXI Interconnect добавился ещё один порт
Часть дела сделана. Теперь давайте настроим модуль управления тактовой частотой и синхронизацией clk_wiz_1. Для Ваших плат значения могут быть другими – надеюсь, что Вы сможете найти в документации значение частоты системного тактового генератора, тип идущего от него сигнала, и ножку(и) FPGA к которым он подключён. Ниже приведены настройки для Arty Board (рис. 27). Настройка любого модуля производится двойным щелчком по нему.
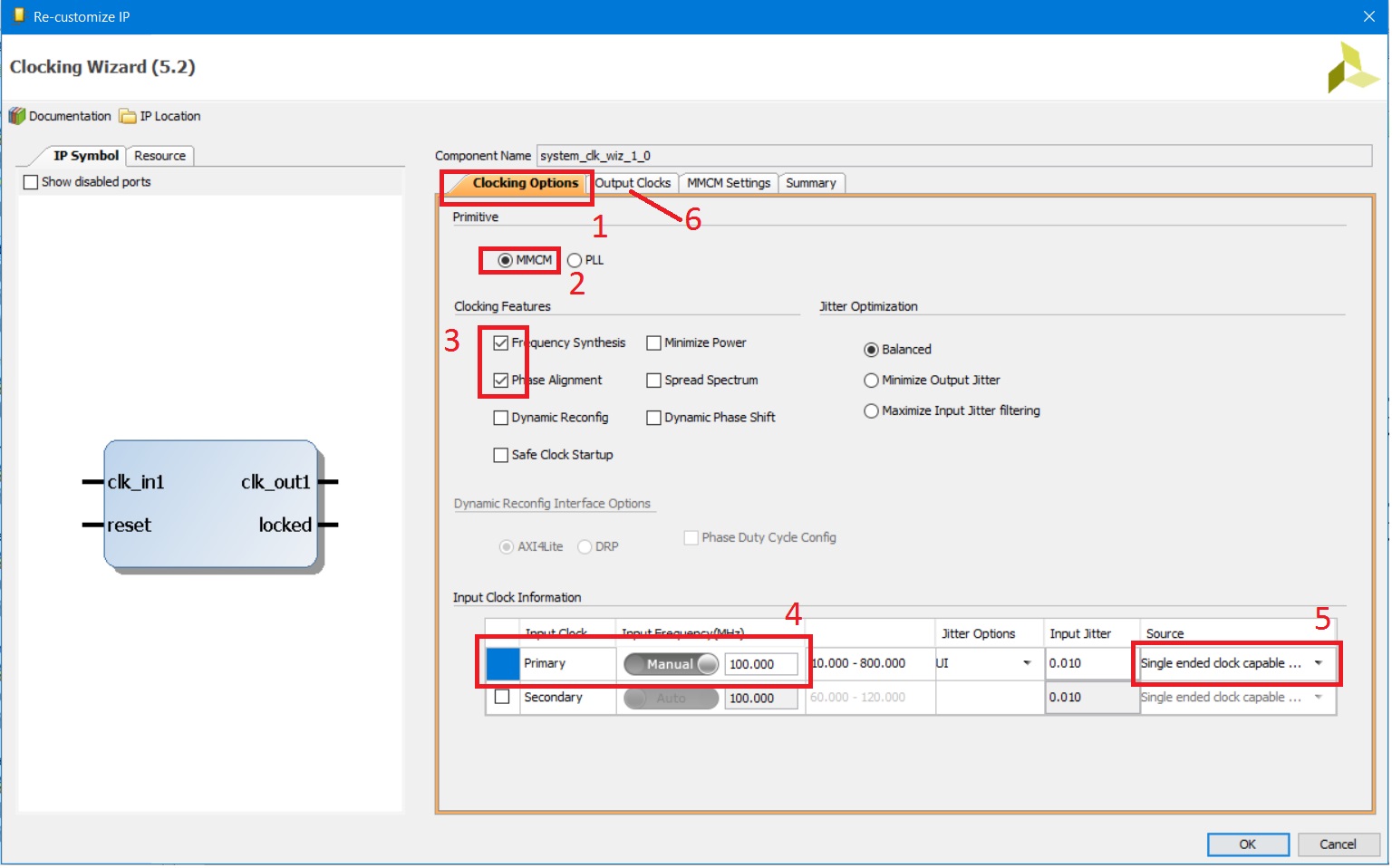
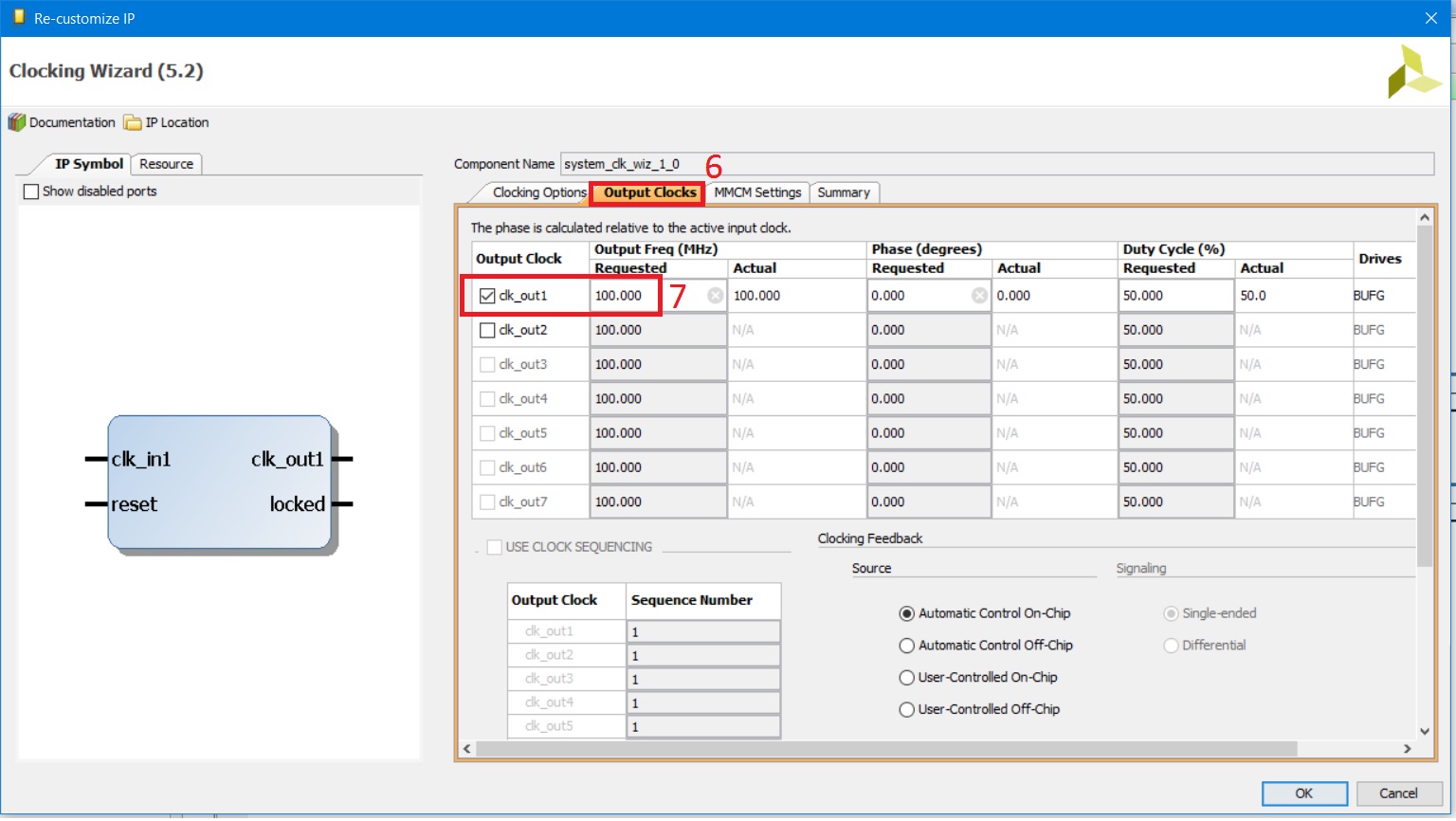
Рисунок 27. Окно настройки модуля управления тактовой частотой и синхронизацией: вкладка Clocking Options
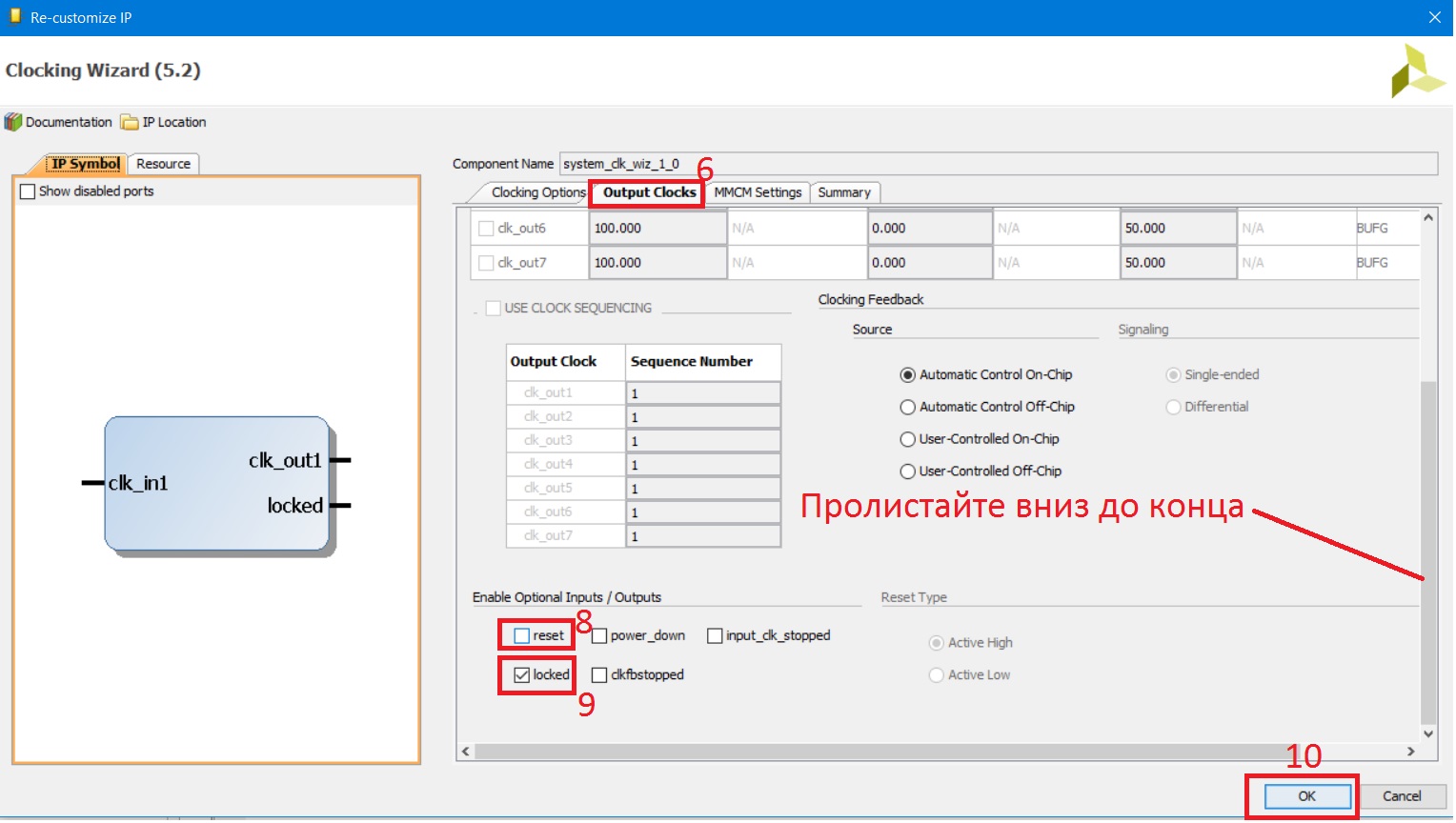
В окне настроек clk_wiz_1: 1. Выберите вкладку Clocking Options. 2. Тип модуля – MMCM. 3. Включены возможности синтеза частоты и фазовой подстройки. 4. Основная тактовая частота – 100MГц. 5. Тип сигнала с системного тактового генератора на плате – однополярный. 6. Затем выберите вкладку Output Clocks (рис. 28). 7. На ней – установите выходное значение частоты (тактовая частота процессора) – также 100 МГц. Пролистайте вниз до конца 8. Снимите галочку с сигнала reset. 9. Установите галочку locked. 10. Нажмите OK.
Рисунок 28. Окно настройки модуля управления тактовой частотой и синхронизацией: вкладка Clocking Options
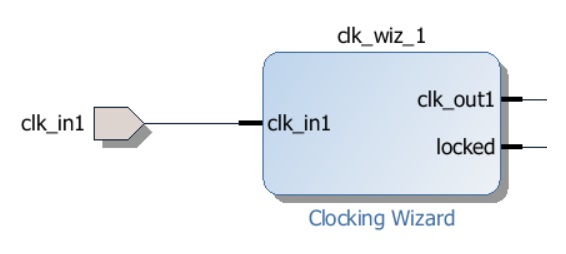
Установленные настройки могут повлиять на внешний вид clk_wiz_1 (для Arty Board он примет вид, как на рис. 29).
Рисунок 29. Изменение внешнего вида модуля после проделанных настроек (для Arty Board)
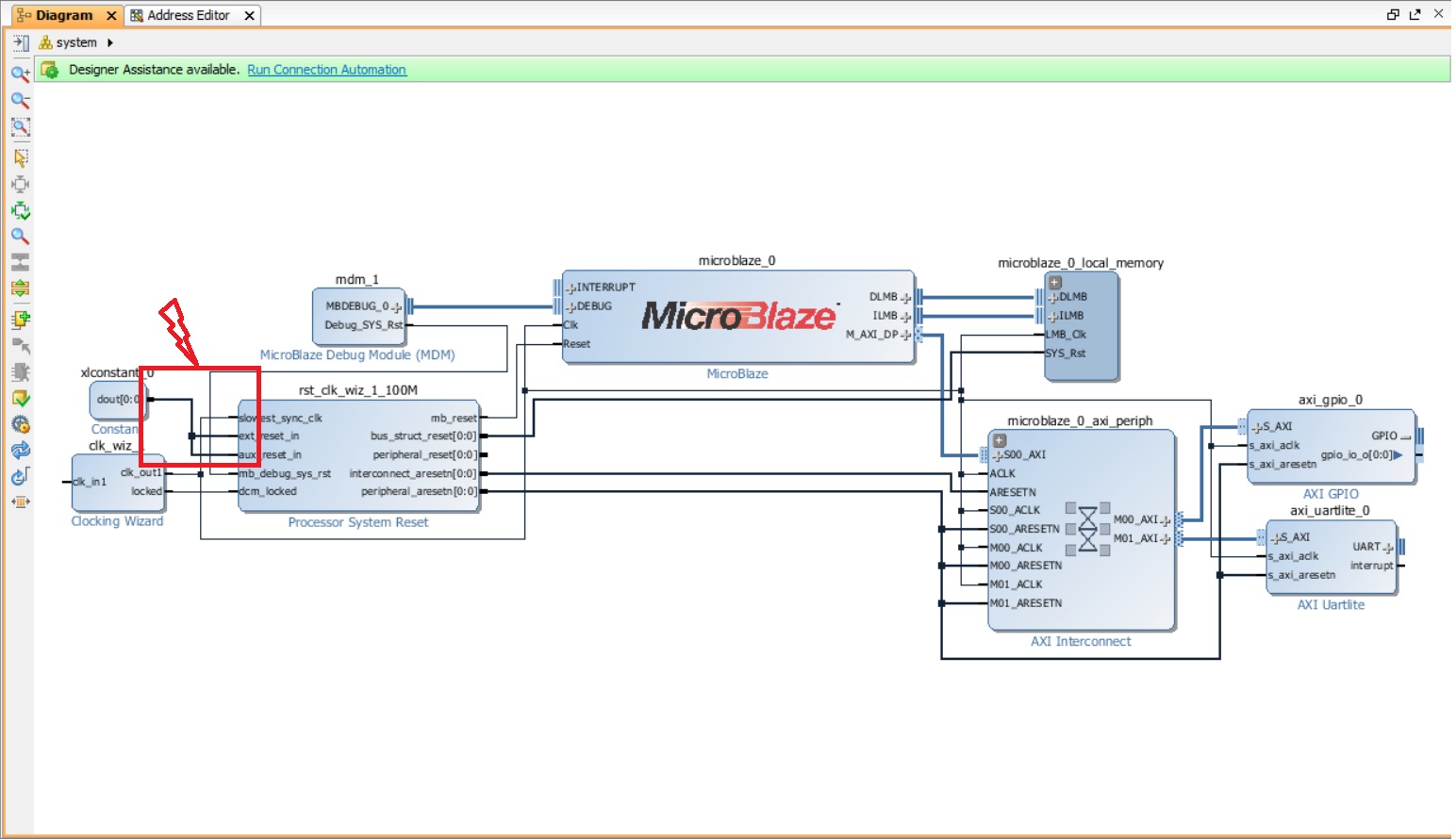
Если оставить незадействованные выводы модуля сброса неподключенными, то может возникнуть ситуация, при которой процессор будет всегда в состоянии сброса. Потому выполним явное их подключение к логической «1» – неактивному для них логическому уровню. Для этого: 1. Добавьте блок constant. 2. Установите в нем значение 1 (если по умолчанию оно другое). 3. Подключите выход блока Constant к входам aux_reset_in и ext_reset_in блока rst_clk_wiz_1_100M. Подключение осуществляется следующим образом: подведите мышку к выходу блока Constant (указатель должен принять вид карандашика), нажмите на выход и, не отпуская левую кнопку мыши, подведите соединение к входу aux_reset_in – а затем повторите те же действия для ext_reset_in. В очередной раз нажмите кнопку оптимизации рабочего пространства в панели инструментов. Соединение должно принять вид, как на рис. 30.
Рисунок 30. Соединение выхода блока Constant с входами aux_reset_in и ext_reset_in блока rst_clk_wiz_1_100M
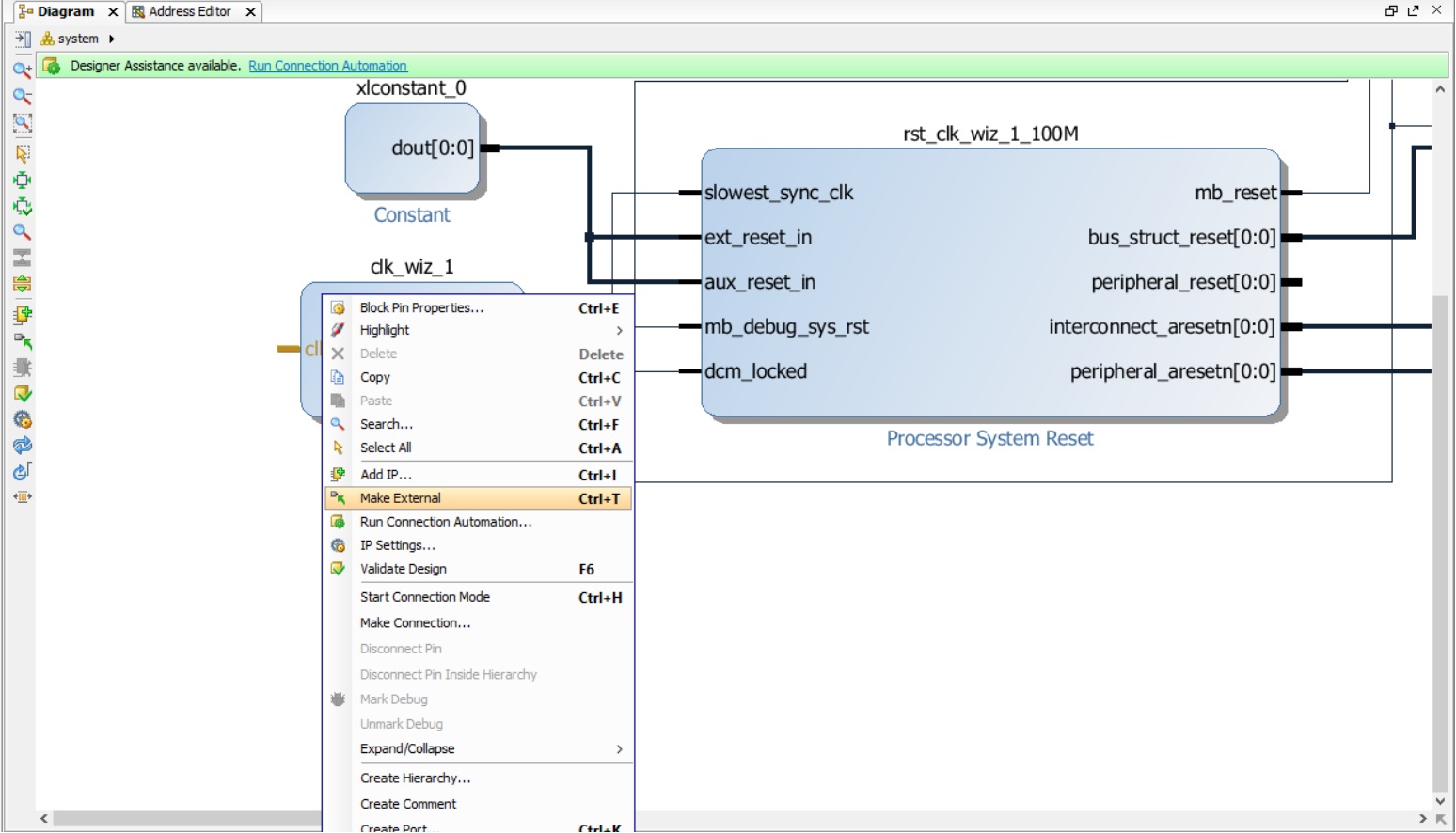
Теперь необходимо создать внешние входы и выходы для нашей процессорной системы. Если вы обратили внимание, сейчас не подключены clk_in1 и выходы экземпляров модулей axi_gpio_0 и axi_uartlite_0. Сейчас мы должны обозначить, какие порты являются внешними и должны выходить из нашей процессорной системы наружу. Назначим вход clk_in1 модуля Clocking Wizard внешним. Для этого кликнем по нему правой кнопкой мыши и выберем Make External (рис.31).
После этого к входу clk_in1 будет подключён порт, с таким же именем (рис. 32).
Рисунок 32. Внешний порт clk_in1, созданный автоматически, подключён к входу clk_in1 модуля clk_wiz_1
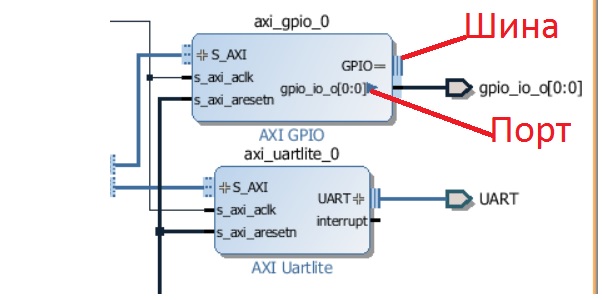
Аналогично поступаем и с выходом GPIO модуля axi_gpio_0 и шиной UART модуля axi_uartlite_0. Сделать внешним можно как шину, так и отдельный порт из шины; а если портов в шине несколько (как в шине UART), то направление портов будет определено автоматически (см. 33). Некоторые незадействованные порты можно оставить неподключёнными – например, interrupt модуля axi_uartlite_0.
Рисунок 33. Объявление внешними порт управления светодиодом и шины UART
Помните про вкладку Address Editor (рис.34)? Самое время обратиться к ней и понять её назначение. Наши модули соединены по шине AXI, полное название AXI Memory Map, это значит, что все модули, подключённые к шине должны иметь уникальный адрес, чтобы процессор смог к ним обратиться и «не перепутать» один модуль с другим. Назначение уникальных адресов (распределение адресного пространства) как раз и происходит во вкладке Address Editor, где в ручном, полуавтоматическом или автоматическом режиме можно установить диапазон адресов для конкретных модулей.
Рисунок 34. Вкладка Address Editor
Поскольку мы пользовались помощником соединений и мастерами настроек, адресное пространство уже полностью сконфигурировано, но если бы мы делали подключение шин в ручном режиме, то увидели бы следующую картину (рис. 35). Эта картинка только для демонстрации: я временно удалил шину AXI, соединяющую экземпляры AXI Interconnect и GPIO, а потом соединил её вручную. Из-за ручного соединения назначения адреса не произошло. Но мы можем назначить адрес, нажав на кнопку автоматического назначения адресов на панели инструментов вкладки Address Editor. После этого, картинка станет прежней (то есть как на рис. 34).
Рисунок 35. В случае ручного соединения шин AXI появляется неразмеченная область. Нажатие кнопки запускает автоматическое распределение адресного пространства
К сожалению, для нашей будущей программы не достаточно памяти, которую мы задали, когда пользовались мастером экспресс-настроек MicroBlaze (рис. 16). Нам необходимо увеличить количество памяти для данных и инструкций с 8К до 16К. Сделать это можно простым выбором из выпадающего списка доступного количества памяти, нажав на стрелочку в соответствующем поле (рис. 36). Изменить необходимо размер памяти и инструкций. В обоих полях должно быть значение 16К.
Рисунок 36. Изменение количества памяти, выделяемой для процессорной системе
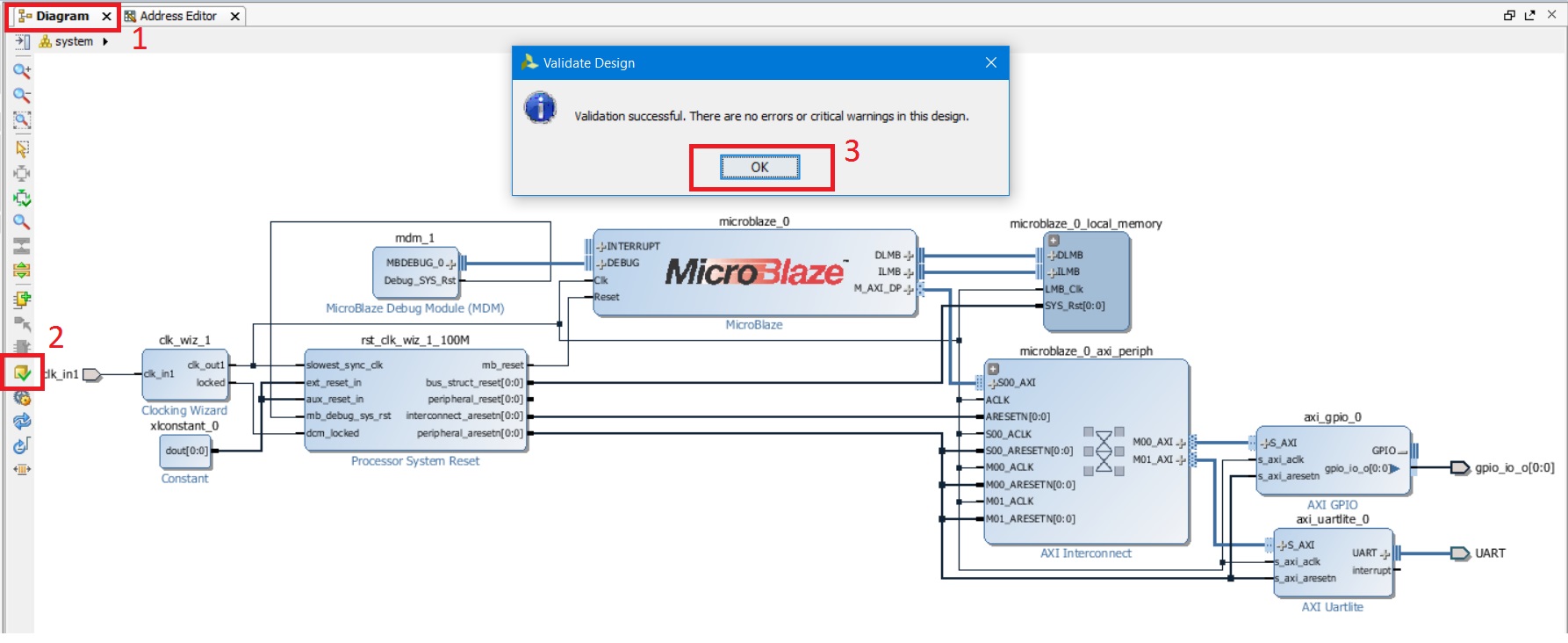
Мы проделали много действий, закончили собирать систему и назначили все адреса. Но все ли корректно и правильно? В панели инструментов на вкладке Diagram есть одна из самых важных кнопок, называется она Validate Design (2 на рис. 37). Нажатие этой кнопки запускает инструмент проверки ошибок сборки HW-части процессорной системы (рис. 37). Нажмите эту кнопку и дождитесь результата. Если появилось окно, как на рис. 37, то поздравляю Вас, сборка HW-части проекта закончена. Если же появились ошибки – внимательно прочитайте их и постарайтесь самостоятельно исправить, вернувшись по тексту к соответствующим пунктам либо проделав всю последовательность с начала ещё раз, более внимательно и аккуратно.
Рисунок 37. Проверка на ошибки сборки HW части процессорной системы
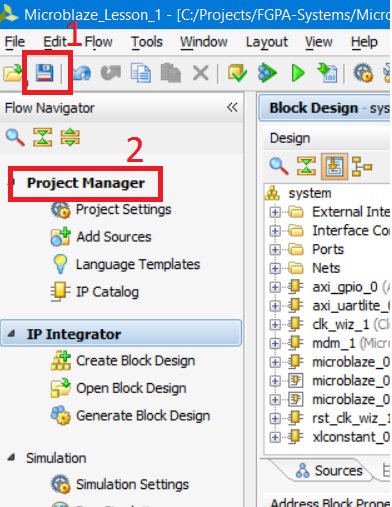
Нажмите на основной панели Vivado кнопку сохранения, а затем – кнопку Project Manager, чтобы выйти из IP Integrator и вернуться в основной режим работы Vivado (рис. 38):
Рисунок 38. Сохранение и выход из IP Integrator
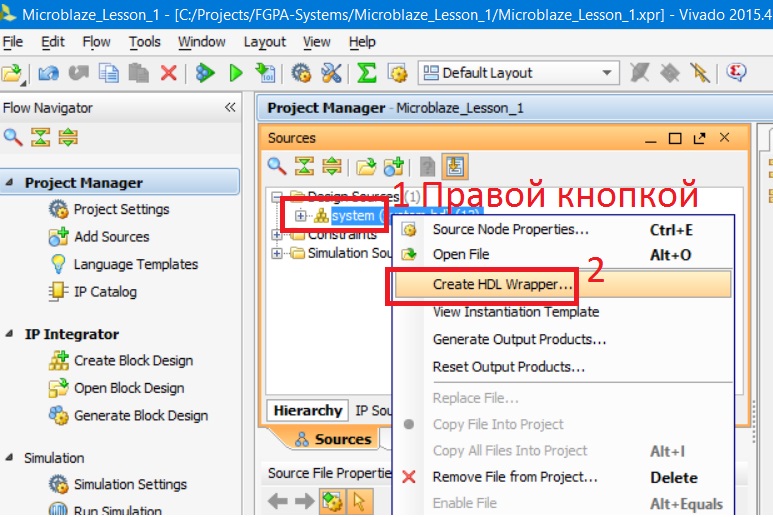
Далее следуют стандартные этапы проектирования: синтез, имплементация, генерация файла прошивки (битстрима). Но для блочного проекта обязательно нужно сделать обёртку (wrapper); это показано на рис. 39. Нажмите правой кнопкой на созданном блочном проекте и выберите Create HDL Wrapper. В появившемся окне нажмите OK.
Рисунок 39. Создание обёртки для блочного проекта.
Обёртка – это простой VHDL- или Verilog-файл (с расширениями «vhd» или «v» соответственно), в который включена наша процессорная система, как часть иерархии. Таким образом, нашей собранной процессорной системой мы сможем оперировать, как простым модулем, добавляя её в качестве подмодуля в модули верхнего уровня.

 Программа установки Vivado 2018.2
Программа установки Vivado 2018.2  Вейвформы сигналов при моделировании
Вейвформы сигналов при моделировании 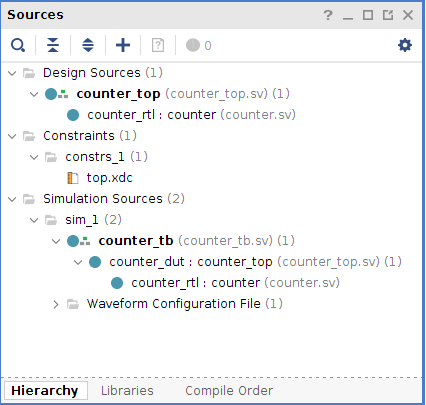 Исходные файлы проекта
Исходные файлы проекта 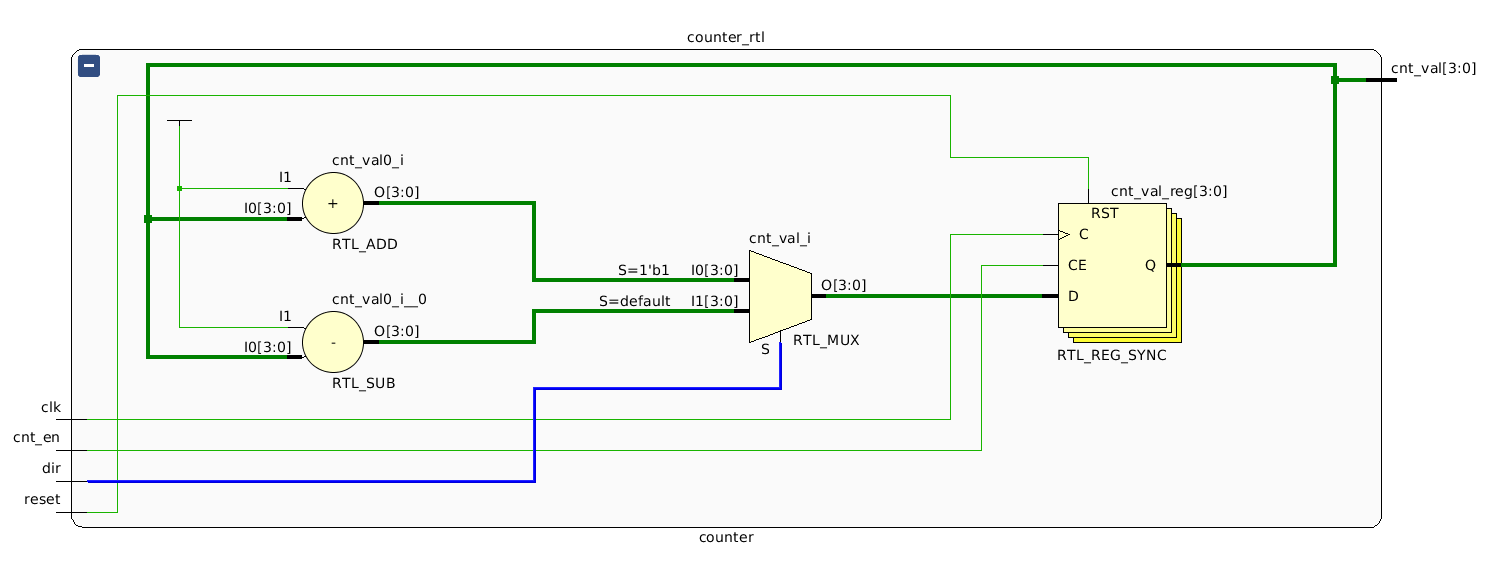 RTL Analysis Counter
RTL Analysis Counter 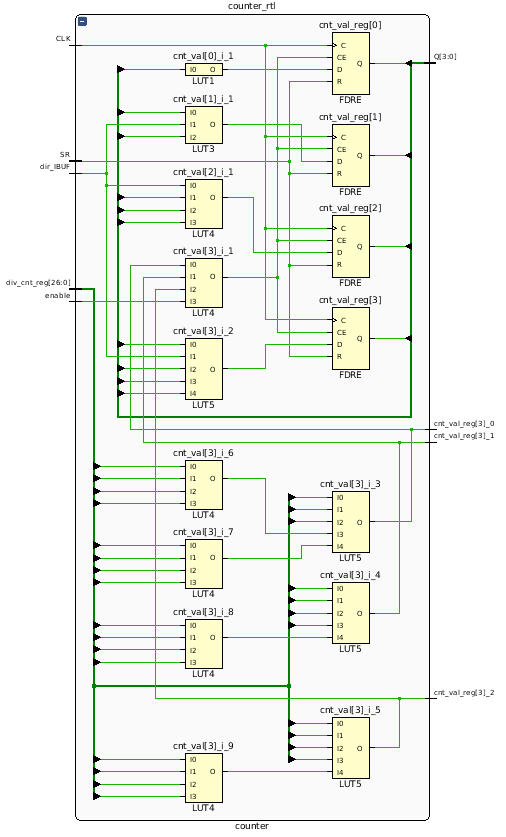 Counter after Synthesis
Counter after Synthesis 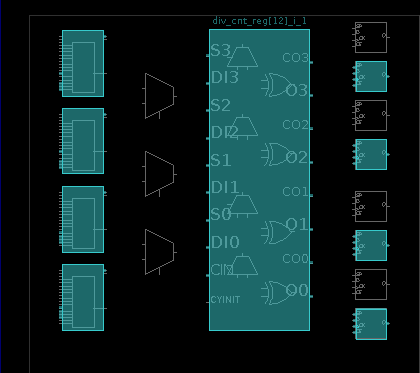 Placed hardware resources
Placed hardware resources 

















 , расположенной в панели инструментов слева во вкладке Diagram или нажать Ctrl+I. После нажатия на кнопку откроется каталог блоков, которые можно добавить на поле Diagram (рис. 13).
, расположенной в панели инструментов слева во вкладке Diagram или нажать Ctrl+I. После нажатия на кнопку откроется каталог блоков, которые можно добавить на поле Diagram (рис. 13).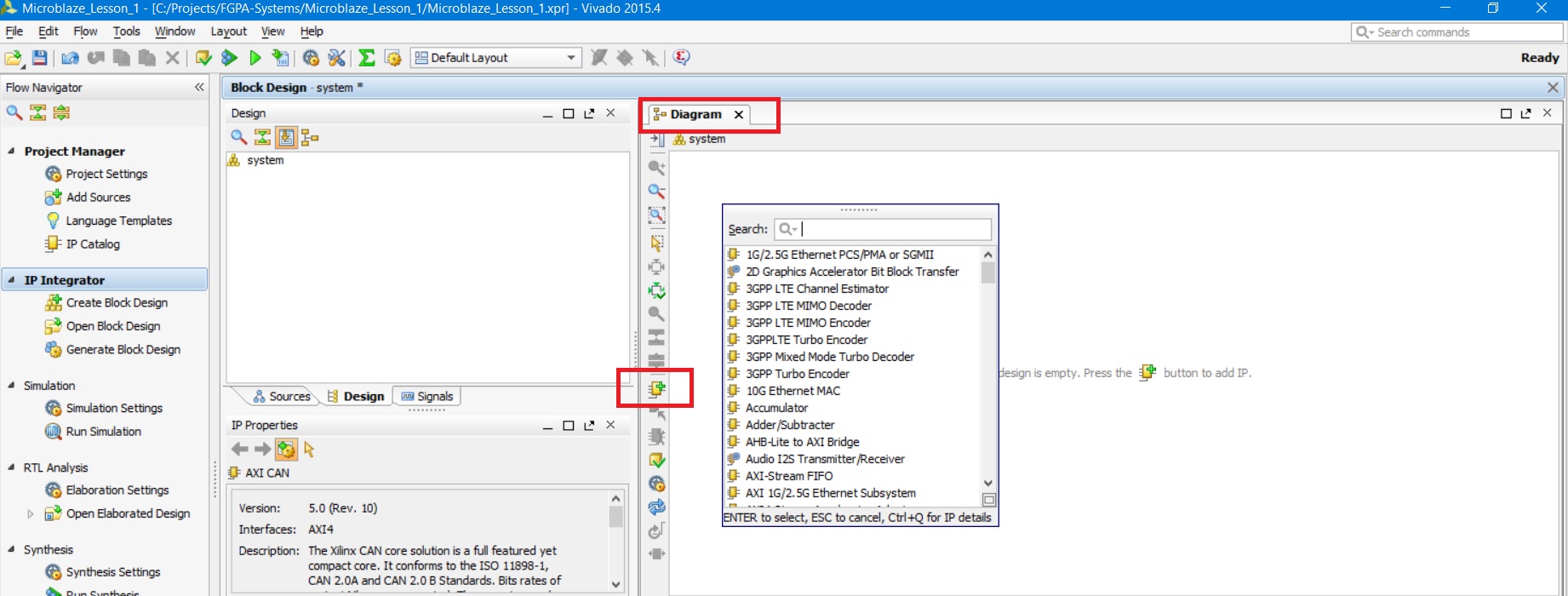
 в панели инструментов (рис. 17).
в панели инструментов (рис. 17).