Weight of evidence and Information Value using Python

Apr 29, 2018 · 4 min read
Weight of evidence (WOE) and Information value (IV) are simple, yet powerful techniques to perform variable transformation and selection. These concepts have huge connection with the logistic regression modeling technique. It is widely used in credit scoring to measure the separation of good vs bad customers.

The formula to calculate WOE and IV is provided below.



Here is a simple table that shows how to calculate these values.

The advantages of WOE transformation are
Also, IV value can be used to select variables quickly.

You can view the entire code in the github link.
Sundar0989/WOE-and-IV
Contribute to WOE-and-IV development by creating an account on GitHub.
The d ataset for this demo is downloaded from UCI Machine Learning repository. Please have a look at the code, to follow the explanations provided below. A sample of the dataset is shown below.


I changed the ‘y’ variable to numeric and named it as ‘target’. As mentioned before, monotonic binning ensures linear relationship is established between independent and dependent variable. In the code, I have two functions mono_bin() and char_bin().The mono_bin function is used for numeric variables and char_bin is used for character variables. I used spearman correlation to perform monotonic binning.
The ‘max_bin’ variable is used to provide the maximum number of bins (categories) for numeric variable binning. For some numeric variables, the mono_bin function produce only one category while binning. To avoid that, I have another variable called ‘force_bin’ to ensure it at least produces 2 categories.
The WOE and IV calculation can be invoked using the below code.
The final_iv dataframe has all the WOE transformations and looks similar to the Figure 2 shown above. The IV dataframe gives the consolidated IV values for each input variables and looks like below.

Based on the above information, the variables can be selected based on their predictive power.

Now you can perform WOE variable transformation and IV variable selection using Python. Have fun!
Also, please look at my other articles, if you would like to see the real time application of WOE and IV
Разработка скоринговых карт
Я занимался построением скоринговых карт в банке для самых разных продуктов и могу сказать, что жизненный цикл разработки стандартный. И цель этой заметки пройти цикл и построить скоринговую карту для оценки платежеспособности заёмщиков на основе данных из кредитной заявки.
Моделирование кредитных рисков
Моделирование кредитных рисков в банковский сектор пришло из ботаники. В статистике идеи классификации популяции на группы были разработаны Фишером в 1936 г. на примере растений. Этот тот самый знаменитый пример Ирисов Фишера. Он часто используется для иллюстрации работы статистических алгоритмов.
В 1941 г. Дэвид Дюран впервые применил данную методику к классификации кредитов на «плохие» и «хорошие». С началом Второй мировой войны банки столкнулись с необходимостью срочной замены аналитиков. Аналитики составили свод правил, которыми следовало руководствоваться при принятии решения о выдаче кредита, чтобы анализ мог проводиться неспециалистами. Это и был прообраз будущих систем принятия решения.
| Параметр | Критерий оценки |
| Возраст | 0,1 балла за каждый год свыше 20 лет (максимум — 0,30) |
| Пол | женский (0,40), мужской (0) |
| Срок проживания в регионе | 0,042 за каждый год (максимально — 0,42) |
| Профессия | 0,55 за профессию с низким риском, 0 за профессию с высоким риском, 0,16 — другие профессии |
| Работа | 0,21 на предприятиях общественной отрасли, 0 — другие |
| Срок занятости | 0,059 за каждый год работы на данном предприятии |
| Финансовые показатели | 0,45 за наличие банковского счета, 0,35 за наличие недвижимости, 0,19 — за наличие полиса по страхованию |
Современные подходы к моделированию
Из-за требований внешних регуляторов в качестве моделей для скоринга кредитных заявок рассматриваются интерпретируемые модели. Например, решающее дерево или логистическая регрессия. Интерпретация решающего дерева простая и понятная. Визуализируйте.

С интерпретацией логистической регрессии немного сложнее. Для этих целей и разрабатывается скоринговая карта.
Жизненный цикл разработки скоринговых карт
Рассмотрим жизненный цикл на примере. Возьмём анонимизированный учебный набор данных по заявкам на кредитные карты — Credit Approval Data Set. К сожалению, нам не известны наименование признаков, но можем предположить, что туда входят возраст, пол, доход и т.д. Набор данных состоит из 14 признаков и целевой переменной. Предобработка данных в этом датасете очень простая. Заменим все «?» на NaN, а потом пропуски в числовых признаках на средние значения и на самое часто встречаемое в категориальных признаках.
Монотонный WOE binning признаков
Теперь необходимо написать WOE binning для числовых и категориальных переменных.
WOE считается для каждого признака!
Плюсы монотонного WOE binningа признаков:
Объединим категории с близкими значениями WOE в одну категорию так, чтобы максимизировать разницу между группами. Теперь можно посмотреть на графиках, как переменные разбились по группам и проверить монотонность возрастает или убывает.

Далее оценим по графикам, монотонно возрастают или убывают. При необходимости провести ручной бининг. Ручной бининг нужен для объединения категорий с близкими значениями WOE в одну категорию так, чтобы максимизировать разницу между группами.
Отбор признаков по Information Value
Information Value (IV) измеряет предсказательную силу признаков. Считается для каждого признака.

Значения Information Value (IV) для определения cutoff по отбору признаков:
План отбора признаков по IV:
Построение логистической регрессии
Строим логистическую регрессию и оцениваем метрики на кросс-валидации и тестовой выборке. Смотрим на коэффициент ROC AUC или Gini.

Построение скоркарты — масштабирование баллов
Скорбалл считается по следующей формуле:
Score = (β×WoE+ α/n)×Factor + Offset
β — коэффициент логистической регрессии признака
WoE — Weight of Evidence признака
n — количество признаков, включенных в модель
Factor, Offset — параметры масштабирования. Множитель и смещение.
Множитель и смещение считаются так:
Factor = pdo/Ln(2) Offset = B — (Factor × ln(Odds))
pdo — количество баллов, удваивающее шансы
B — значение на шкале баллов, в которой соотношение шансов составляет С:1
Например: Если скоринговая карта имеет базовые коэффициенты 50 : 1 в 600 баллах, а pdo из 20 (вероятность удвоения каждые 20 баллов), то множитель и смещение будут: Factor = 20/Ln(2) = 28.85 Offset = 600- 28.85 × Ln (50) = 487.14

Получаем следующие скорбаллы:
Таким образом скорбаллы считаются и для остальных признаков и составляется итоговая скоркарта. Дополнительный плюс этого подхода, что потом реализовать готовую скоркарту можно на любом языке программирования, в любой системе используя конструкцию if else.
Как банки принимают решение по кредитным заявкам? Разработка скоринговых карт
Каждый раз, когда вы подаёте заявку в банк на выдачу кредита, он проверяет вас по многим параметрам. Таким образом банк хочет управлять кредитным риском. В то же время, чтобы быстро обрабатывать тысячи заявок используются автоматизированные системы принятия решения. Давайте заглянем под капот таких систем и узнаем, как это работает.
Моделирование кредитных рисков в банковский сектор пришло из ботаники. В статистике идеи классификации популяции на группы были разработаны Фишером в 1936 г. на примере растений. Этот тот самый знаменитый пример Ирисов Фишера. Он часто используется для иллюстрации работы статистических алгоритмов.
В 1941 г. Дэвид Дюран впервые применил данную методику к классификации кредитов на «плохие» и «хорошие». С началом Второй мировой войны банки столкнулись с необходимостью срочной замены аналитиков. Аналитики составили свод правил, которыми следовало руководствоваться при принятии решения о выдаче кредита, чтобы анализ мог проводиться неспециалистами. Это и был прообраз будущих систем принятия решения.
Из-за требований внешних регуляторов в качестве моделей для скоринга кредитных заявок рассматриваются интерпретируемые модели. Например, решающее дерево или логистическая регрессия. Интерпретация решающего дерева простая и понятная. Визуализируйте.
С интерпретацией логистической регрессии немного сложнее. Для этих целей и разрабатывается скоринговая карта.
Жизненный цикл разработки скоринговых карт
Рассмотрим жизненный цикл на примере. Возьмём анонимизированный учебный набор данных по заявкам на кредитные карты — Credit Approval Data Set. К сожалению, нам не известны наименование признаков, но можем предположить, что туда входят возраст, пол, доход и т.д. Набор данных состоит из 14 признаков и целевой переменной. Предобработка данных в этом датасете очень простая. Заменим все «?» на NaN, а потом пропуски в числовых признаках на средние значения и на самое часто встречаемое в категориальных признаках.
Теперь необходимо написать WOE binning для числовых и категориальных переменных.
WOE считается для каждого признака!
Плюсы монотонного WOE binningа признаков:
Объединим категории с близкими значениями WOE в одну категорию так, чтобы максимизировать разницу между группами. Теперь можно посмотреть на графиках, как переменные разбились по группам и проверить монотонность возрастает или убывает.
Далее оценим по графикам, монотонно возрастают или убывают. При необходимости провести ручной бининг. Ручной бининг нужен для объединения категорий с близкими значениями WOE в одну категорию так, чтобы максимизировать разницу между группами.
Отбор признаков по information value
Information Value (IV) измеряет предсказательную силу признаков. Считается для каждого признака.
Значения Information Value (IV) для определения cutoff по отбору признаков:
План отбора признаков по IV:
Строим логистическую регрессию и оцениваем метрики на кросс-валидации и тестовой выборке. Смотрим на коэффициент ROC AUC или Gini.
Скорбалл считается по следующей формуле:
Score = (β×WoE+ α/n)×Factor + Offset
β — коэффициент логистической регрессии признака
WoE — Weight of Evidence признака
n — количество признаков, включенных в модель
Factor, Offset — параметры масштабирования. Множитель и смещение.
Множитель и смещение считаются так:
Factor = pdo/Ln(2) Offset = B — (Factor × ln(Odds))
pdo — количество баллов, удваивающее шансы
B — значение на шкале баллов, в которой соотношение шансов составляет С:1
Например: Если скоринговая карта имеет базовые коэффициенты 50: 1 в 600 баллах, а pdo из 20 (вероятность удвоения каждые 20 баллов), то множитель и смещение будут: Factor = 20/Ln(2) = 28.85 Offset = 600- 28.85 × Ln (50) = 487.14
Дата публикации Sep 9, 2019

Это не так, как было.
Внезапно слушать о моделировании оттока стало интереснее!
Но какого чёрта это анализ релевантности атрибутов?
Хороший вопрос. Я процитирую параграф из официальной учебной книги:
На этапе анализа релевантности атрибутов ставится задача распознавать атрибуты (характеристики), оказывающие наибольшее влияние на отток. Атрибуты, которые показывают наибольшую степень сегрегации по отношению к оттоку (отток = «Да» или «Нет») по анализу релевантности атрибутов, будут выбраны в качестве лучших кандидатов для построения прогнозирующей модели оттока. [1]
Почему-то английский в этой книге ужасен. Я не говорю, что у меня все идеально, но слушать эту аудиокнигу было болезненным процессом.
Тем не менее, я надеюсь, что вы понимаете суть этого.
Анализ релевантности атрибутов ни в коем случае не используется только для разработки прогнозной модели оттока, его можно использовать для каждой задачи классификации. Он основан на двух терминах:Информационная ценностьа такжеВес доказательств,
Информационная ценность и вес доказательств
Хорошо, я обещаю, что я буду кратким с теорией. Согласно сwww.listendata.comВес доказательств объясняется следующим образом:
Вес доказательств говорит о предсказательной способности независимой переменной по отношению к зависимой переменной. Так как он произошел из мира кредитного скоринга, его обычно описывают как меру разделения хороших и плохих клиентов.«Плохие клиенты»относится к клиентам, которые не выполнили свои обязательства по кредиту. а также«Хорошие клиенты»относится к клиентам, которые вернули кредит. [2]
И из того же источника информационная ценность объясняется следующим образом:
Оба действительно просты для расчета. Ниже приведены формулы:

Если мы говорим о моделировании оттока,Грузбыли бы клиенты, которые не били, иантитоварыбудут клиенты, которые совершили отток. Именно из этого вы можете увидеть простоту формул.
Горе и IV Предпосылки
Чтобы выделить предпосылки, я помещу их в упорядоченный список.
Как только ваш набор данных будет в этой форме, вы можете перейти к процессу расчета WoE и IV.
Пример моделирования оттока
Для создания этого примера я использовалМоделирование оттоканабор данных изKaggle, При загрузке в Pandas это выглядит так:

Анализ релевантности атрибутов для примера моделирования оттока разделен на 6 шагов:
Итак, без лишних слов, давайте начнем!
Шаг 1. Очистка и подготовка данных
Набор данных не содержит пропущенных значений, поэтому условие 1 из 2 выполнено!
Есть 10 000 наблюдений и 14 столбцов. С этого момента я приступил к очистке данных. Вот шаги, которые я предпринял:
Ниже приведен фрагмент кода для выполнения этих шагов:
Набор данных теперь чистый и не содержит непрерывных переменных. Условие 2 из 2 выполнено!
Новая очищенная версия набора данных выглядит следующим образом:

Шаг 2. Расчет IV и WoE
Внизу находится функция, которая будет рассчитывать вес доказательств и ценность информации. Учитывая Pandas DataFrame, имя атрибута и имя целевой переменной, он будет выполнять вычисления.
Функция вернет Pandas DataFrame и IV балл. На первый взгляд код может показаться немного сложным, но не сложным, если вы читаете его построчно.
Чтобы избежать создания множества ненужных кадров данных в памяти, простой цикл распечатает все для вас:
Обратите внимание, что здесьвозбужденномэто имя целевой переменной, и по логическим причинам вы не будете делать для нее вычисления. Когда эта ячейка кода будет выполнена, вы получите много выходных данных в своем блокноте:

Есть простое объяснение.
На данный момент, вы должны просто заботиться о строке, которая говорит IV балл. Точнее,Думайте о переменных с самыми высокими показателями IV, Ниже приведена таблица для IV интерпретации:

Теперь вы должны увидеть более четкую картину. Вы должны сохранять только те атрибуты, которые обладают хорошей предсказательной силой! В текущем наборе данных это:
Шаг 3. Определение профиля Churners
Это на самом деле не обязательный шаг, но он весьма полезен.
Вы, как компания, вероятно, хотите знать, как выглядит типичная машина для перемешивания. Я имею в виду, что вы не заботитесь о его / ее внешнем виде, но вы хотите знать, где живет чирнер, каков его / ее возраст и т. Д…
Чтобы выяснить это, вам нужно более внимательно посмотреть на возвращенные фреймы данных для тех переменных, которые обладают наибольшей предсказательной силой. Точнее, посмотрите наГореколонка. В идеале вы найдетеотрицательный рейтинг WoE— это ценность, которую имеют большинство взбалтывателей.
В нашем примере это типичный профиль churners:
Получив эту информацию, вы, как компания, можете действовать и решать эту критически важную группу клиентов.
Часть 4. Грубая классификация
Еще раз, мне нужно было написать код для этого самостоятельно.
Для этого набора данных следует применять грубую классификациюИспанияа такжеФранциявгеографияатрибут (горе 0,24 и 0,28).

Внизу находится функция для грубой классификации, а также вызов функции. Чтобы вызвать функцию, вы должны знать заранее, каковы местоположения индекса двух строк, которые вы хотите объединить. Код довольно понятен, посмотрите:
А вот как выглядит набор данных после грубого процесса классификации:

Вы можете заметить, чтоЦенностьявляетсяNaNдля вновь созданного ряда. Не о чем беспокоиться, вы можете просто переназначить исходный набор данных, чтобы заменитьИспанияа такжеФранцияс чем-то новым, например,Spain_and_France,
Шаг 5. Создание фиктивной переменной
Мы почти на финише. Почти.
Как вы знаете, модели классификации работают лучше всего, когда существуют только двоичные атрибуты. Вот тут и появляются фиктивные переменные.
Фиктивные переменные понадобятся для следующих атрибутов:
Если вы теперь посмотрите на голову недавно созданного Data Frame:

Шаг 6. Корреляции между фиктивными переменными
Вы сделали это до конца. Завершающим этапом этого процесса является вычисление корреляций между фиктивными переменными и исключение тех, которые имеют высокую корреляцию.
То, что считается высоким коэффициентом корреляции, остается спорным, но я бы посоветовал вамудалить что-либо с соотношением выше 0,7(по абсолютной стоимости).
Если вам интересно, какую фиктивную переменную удалить между двумя,удалить тот, у кого меньше вес доказательств, из-за более слабого соединения с целевой переменной.
Я решил построить матрицу корреляции, чтобы получить хорошее визуальное представление корреляций:

Здесь видно, что не существует корреляции между фиктивными переменными, и, следовательно, все они должны остаться.
Вывод
Я закончу эту часть здесь. Следующая часть будет доступна через пару дней, самое большее через неделю, и будет посвящена разработке и оптимизации прогнозной модели на основе этих фиктивных переменных.
Ссылка на часть 2 будет прикреплена здесь после публикации статьи.
До тех пор, следите за обновлениями!
Ссылки
[1] Клепац Г., Копал Р., Мршич Л. (2014).Разработка моделей оттока с использованием методов интеллектуального анализа данных и анализа социальных сетей.США: IGI-Global
Weight of Evidence (WOE) and Information Value (IV) Explained
What is Weight of Evidence (WOE)?
The weight of evidence tells the predictive power of an independent variable in relation to the dependent variable. Since it evolved from credit scoring world, it is generally described as a measure of the separation of good and bad customers. «Bad Customers» refers to the customers who defaulted on a loan. and «Good Customers» refers to the customers who paid back loan.
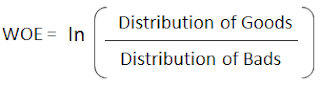 |
| WOE Calculation |
WOE = In(% of non-events ➗ % of events)
Steps of Calculating WOE
Terminologies related to WOE
Create 10/20 bins/groups for a continuous independent variable and then calculates WOE and IV of the variable
Combine adjacent categories with similar WOE scores
Usage of WOE
Weight of Evidence (WOE) helps to transform a continuous independent variable into a set of groups or bins based on similarity of dependent variable distribution i.e. number of events and non-events.
For continuous independent variables : First, create bins (categories / groups) for a continuous independent variable and then combine categories with similar WOE values and replace categories with WOE values. Use WOE values rather than input values in your model. For categorical independent variables : Combine categories with similar WOE and then create new categories of an independent variable with continuous WOE values. In other words, use WOE values rather than raw categories in your model. The transformed variable will be a continuous variable with WOE values. It is same as any continuous variable.
Why combine categories with similar WOE?
If a particular bin contains no event or non-event, you can use the formula below to ignore missing WOE. We are adding 0.5 to the number of events and non-events in a group.
AdjustedWOE = ln (((Number of non-events in a group + 0.5) / Number of non-events)) / ((Number of events in a group + 0.5) / Number of events))
How to check correct binning with WOE
Benefits of WOE
What is Information Value (IV)?
Rules related to Information Value
| Information Value | Variable Predictiveness |
|---|---|
| Less than 0.02 | Not useful for prediction |
| 0.02 to 0.1 | Weak predictive Power |
| 0.1 to 0.3 | Medium predictive Power |
| 0.3 to 0.5 | Strong predictive Power |
| >0.5 | Suspicious Predictive Power |
According to Siddiqi (2006), by convention the values of the IV statistic in credit scoring can be interpreted as follows.
Weight of Evidence and Information Value in Python, SAS and R
Step 1 : Install and Load Package First you need to install ‘Information’ package and later you need to load the package in R.
![]()
Why should WOE be monotonic? For example, when there is U/inverse U relationship between independent variable and outcome.
It is because logistic regression assumes there must be a linear relationship between logit function and independent variable.
![]()
in health insurance. incidence (event or disease) rate is higher in infant/toddler and then older people. People with age in the middle has the lowest incidence rate. How could this be a monotonic WOE? But this can be modeled by logistic regression, with age as categories.
Groupings doesnt mean categorical data but continuous data. That is the variables that are directly used as a feature in logistic regression. Am sure age is not directly used as a variable in that case. We categorize age into groups to solve that problem.
![]()
Can I ask for your help? I am a first time SPSS user. I need to calculate WOE and IV for more than thousands of variables in a SPSS dataset. Can you tell me how to write a SPSS macro to calculate WOE and IV automatically and output the result?
I have been struggling for a month how to do it already and really need your help.
![]()
Dont know for SPSS, but in R you can use *Information* package and *smbinning* package.