SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Основы использования хинта NOLOCK в SQL Server
Основная идея механизма блокировок в SQL Server состоит в контроле согласованности транзакций. Согласно этому принципу, если процессу требуется выполнить операции вставки, удаления или обновления, ядро SQL Server блокирует строку или строки и не позволяет другим процессам получить доступ к данным до завершения транзакции. При определенных обстоятельствах этот механизм блокировок может привести к падению производительности, например, при множестве конкурирующих процессов. В результате вы можете столкнуться с проблемой тупиковой ситуации вашей базы данных (это такая ситуация, когда две транзакции требуют доступа к одним и тем же данным в одно и то же время). В этой статье мы уделим внимание тому, как избежать проблем блокировки с помощью хинта NOLOCK. Сначала давайте познакомимся с основными положениями и деталями методологии «грязного чтения», поскольку хинт NOLOCK может приводить к грязному чтению.
Грязное чтение: В этой методологии процесс считывает незафиксированные данные и не обращает внимания на открытые транзакции, поэтому блокировки не вызывают никаких проблем в процессе чтения. Таким образом, этот тип чтения снижает уровень блокировок. Однако грязное чтение имеет как положительные, так и отрицательные стороны, поскольку грязное чтение может вызывать проблемы несогласованности данных в результирующем наборе оператора SELECT. Как отмечалось ранее, этот результирующий набор может включать следы незафиксированных транзакций, и мы должны принимать это в расчет, решая использовать этот вид чтения. Мы не можем быть уверены в реальности строк, которые мы получаем при грязном чтении, поскольку для этих строк может быть выполнен откат. С другой стороны, этот тип чтения позволяет избежать проблем с блокировками и увеличить производительность SQL Server.
NOLOCK: По умолчанию SQL Server использует уровень изоляции Read Committed (чтение зафиксированных транзакций), и этот уровень изоляции не позволяет читать объекты, которые заблокированы незавершенными транзакциями. Кроме того, эти заблокированные объекты могут изменяться в соответствии с эскалацией блокировки.
Представьте себе, что имеется два пользователя базы данных, и эти пользователи хотят выполнить операции update и select. Первый пользователь начинает обновление некоторой строки таблицы, а затем другой пользователь читает ту же строку. Действия этих пользователей иллюстрирует следующий рисунок.

В этом случае User2 ждет, по меньшей мере, 10 секунд, а затем транзакция откатывается пользователем user1, после чего пользователь user2 может прочитать строку, отмеченную зеленым, поскольку блокировка строки снимается пользователем user1. Это поведение по умолчанию уровня изоляции Read Committed в SQL Server.
Теперь продемонстрируем этот случай в SQL Server. Сначала создадим таблицу FruitSales и добавим в неё несколько строк.
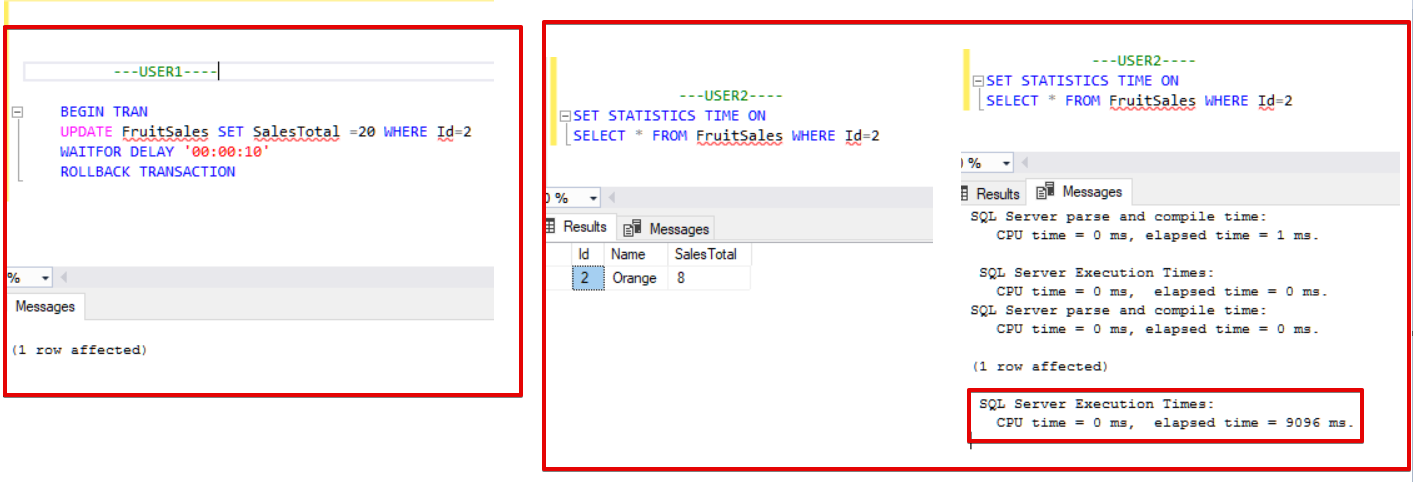
Как вы можете увидеть, второй запрос ожидает до тех, пока пользователь user1 не выполнит откат транзакции.
Теперь мы добавим хинт NOLOCK в оператор SELECT пользователя user2, а затем выполним UPDATE пользователя user1 с последующим оператором SELECT пользователя user2.
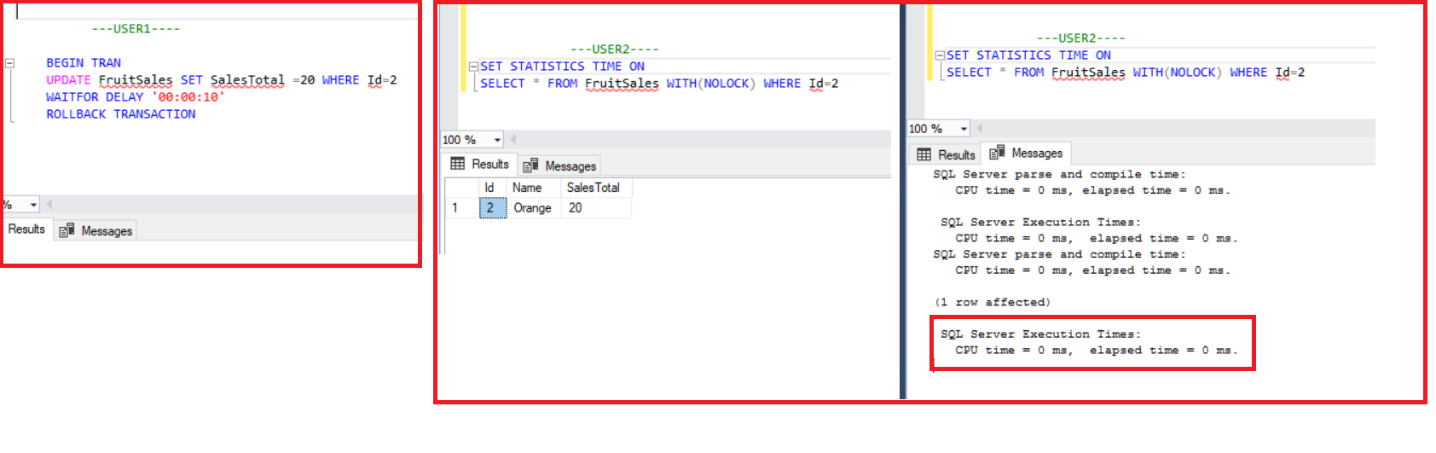
Теперь посмотрим на результат выполнения оператора SELECT. Оператор SELECT пользователя user2 возвращает значение 20 столбца SalesTotal, хотя реальное значение осталось равным 8. Запомните, что если вы используете табличный хинт NOLOCK в запросе на выборку, то можете столкнуться с подобным типом несоответствия результатов.
Совет. Ключевое слово «WITH» является устаревшим, поэтому Майкрософт рекомендует не использовать его в новых проектах баз данных и удалить из текущих разработок. Вы можете использовать хинт NOLOCK без слова «WITH».
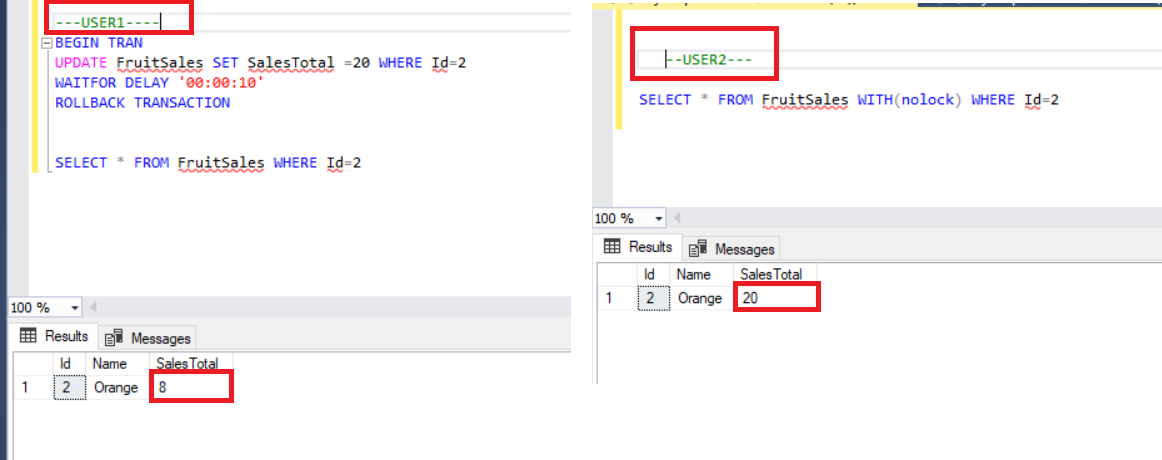
Кроме этого, табличный хинт READUNCOMMITTED эквивалентен хинту NOLOCK, и мы можем использовать его вместо NOLOCK.
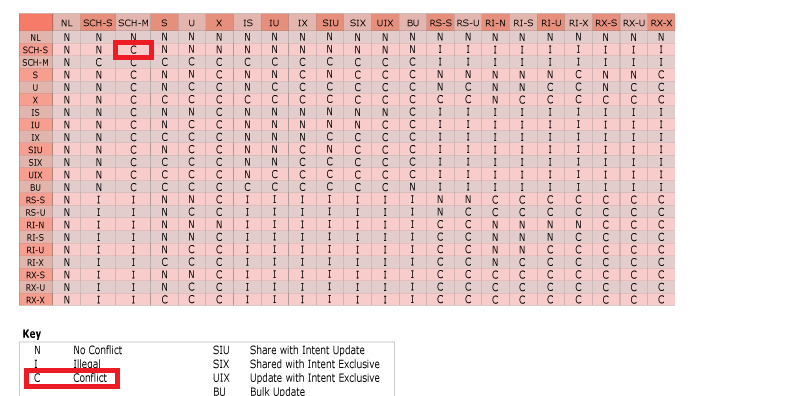
Несмотря на это, существует случай, когда хинт NOLOCK не в состоянии преодолеть барьер блокировки. Если некоторый процесс изменяет структуру таблицы, NOLOCK не может изменить тип блокировки и не позволит продолжить операцию чтения. Причина заключается в том, что хинт NOLOCK ориентирован на блокировки Sch-S (стабильность схемы), а оператор ALTER TABLE накладывает Sch-M блокировку (модификация схемы), так что имеет место конфликт.
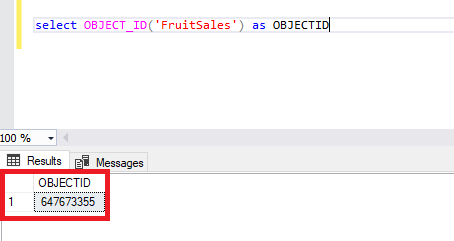
Сначала мы определим Object_id (идентификатор объекта) таблицы FruitSales с помощью следующего запроса.
Запустите следующий запрос user1, а затем запрос user2. В результате запрос user2 будет ожидать завершения процесса изменения таблицы пользователем user1.
Откройте новое окно запроса и выполните следующий код. Этот запрос поможет выяснить тип блокировки запросов user1 и user2.

Теперь мы сверимся с матрицей совместимости блокировок для SCH-M и SCH-S. Матрица указывает на конфликт между SCH-M и SCH-S.
Заключение
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Аноним on Четверг, 7 октября. 2021 :
В статье допущена небольшая смысловая ошибка.
«Совет. Ключевое слово «WITH» является устаревшим, поэтому Майкрософт рекомендует не использовать его в новых проектах баз данных и удалить из. «
В справке Microsoft указано следующее:
Omitting the WITH keyword is a deprecated feature: This feature will be removed in a future version of Microsoft SQL Server.
Автор не разрешил комментировать эту запись
Что такое «с (nolock)» в SQL Server?
Может ли кто-нибудь объяснить последствия использования with (nolock) запросов, когда вы должны / не должны использовать его?
Например, если у вас есть банковское приложение с высокой скоростью транзакций и большим количеством данных в определенных таблицах, в каких типах запросов все будет нормально? Есть ли случаи, когда вы всегда должны использовать его / никогда не использовать?
WITH (NOLOCK) является эквивалентом использования READ UNCOMMITED в качестве уровня изоляции транзакции. Таким образом, вы рискуете прочитать незафиксированную строку, которая впоследствии откатывается, то есть данные, которые никогда не попадали в базу данных. Таким образом, хотя он может предотвратить блокировку чтения другими операциями, он сопряжен с риском. В банковском приложении с высокой скоростью транзакций это, вероятно, не будет правильным решением для любой проблемы, которую вы пытаетесь решить с его помощью, IMHO.
Вопрос в том, что хуже:
В финансовой базе данных вы используете бизнес-операции. Это означает добавление одной строки к каждой учетной записи. Крайне важно, чтобы эти транзакции были завершены и строки были успешно записаны.
Временное неправильное получение баланса счета не имеет большого значения, для этого и нужна выверка на конец дня. А овердрафт со счета гораздо чаще возникает из-за одновременного использования двух банкоматов, чем из-за незафиксированного чтения из базы данных.
Тем не менее, SQL Server 2005 исправил большинство ошибок, которые сделали NOLOCK необходимыми. Поэтому, если вы не используете SQL Server 2000 или более раннюю версию, вам это не нужно.
К сожалению, речь идет не только о чтении незафиксированных данных. В фоновом режиме вы можете закончить чтение страниц дважды (в случае разбиения страницы), или вы можете пропустить страницы в целом. Таким образом, ваши результаты могут быть сильно искажены.
Взять актуальный пример. Если крупный крупный банк США хотел запустить почасовой отчет в поисках первых признаков уровня города в банке, запрос nolock мог бы сканировать таблицы транзакций, суммирующие депозиты и снятие наличных по городам. Для такого отчета небольшой процент ошибок, вызванных откатом транзакций обновления, не уменьшит значение отчета.
Если у вас есть проблемы с блокировкой, реализуйте управление версиями и очистите ваш код.
Без блокировки не только возвращает неправильные значения, он возвращает фантомные записи и дубликаты.
Это распространенное заблуждение, что это всегда заставляет запросы выполняться быстрее. Если в таблице нет блокировки записи, это не имеет значения. Если в таблице есть блокировки, это может сделать запрос быстрее, но есть причина, по которой блокировки были изобретены в первую очередь.
Справедливости ради, вот два специальных сценария, где подсказка Nolock может обеспечить полезность
1) База данных SQL Server до 2005 года, которая должна выполнять длинный запрос к действующей базе данных OLTP, это может быть единственным способом
Дедлоки в SQL Server — часть 1: Что такое блокировки


Введение
В сложных, распределенных, высоконагруженных системах очень часто возникает проблема конкурентного доступа к данным, что приводит к использованию различного рода блокировок в запросах к БД. Кроме того, могут возникать взаимоблокировки, с которыми нужно бороться.
Мы начинаем серию публикаций, посвященную блокировкам в базах данных, в которых поделимся своим опытом, наработанном в нашей компании, по следующим вопросам:
– Какие виды блокировок использовали при разработке наших продуктов
– Какие средства диагностики и инструменты использовали при определении взаимоблокировок
– Как боролись с взаимоблокировками
В данной статье серии, мы рассмотрим блокировки, с которыми столкнулись при разработке программных продуктов.
Прежде чем приступить, кратко напомним, зачем вообще нужны блокировки.
Зачем нужны блокировки
В распределенных системах, использующих в качестве хранилища БД, могут возникать различные побочные эффекты при параллельном доступе к данным:
– Потерянное обновление (lost update) — две транзакции выполняют одновременно UPDATE для одной и той же строки, и изменения, сделанные одной транзакцией, затираются другой;
– «Грязное» чтение (dirty read) — это такое чтение, при котором могут быть считаны добавленные или изменённые данные из другой транзакции, которая впоследствии откатится;
– Неповторяющееся чтение (non-repeatable read) — проявляется, когда при повторном чтении в рамках одной транзакции, ранее прочитанные данные, оказываются изменёнными;
– Фантомное чтение (phantom reads) — можно наблюдать, когда одна транзакция в ходе своего выполнения несколько раз выбирает множество строк по одним и тем же критериям. При этом другая транзакция в интервалах между этими выборками добавляет или удаляет строки, или изменяет столбцы некоторых строк, используемых в критериях выборки первой транзакции, и успешно заканчивается. В результате получится, что одни и те же выборки в первой транзакции дают разные множества строк.
Современные СУБД имеют возможность решать подобные проблемы при помощи встроенных механизмов, например MS SQL Server делает это с помощью использования различных уровней изоляции транзакций:
Для реализации требования изолированности транзакции используется в свою очередь механизм блокировок. Таким образом, механизм блокировок предназначен решать проблемы параллелизма. Стоит также отметить, что неправильное использование блокировок может приводить к деградации производительности, взаимоблокировкам и потере данных.
Блокировки
В MS SQL Server существует много различных видов блокировок и на эту тему написано много хороших статей и технической документации. В статье мы затронем только часть из них, с которыми столкнулись на практике при разработке наших продуктов.
Задача извлечения данных из очереди
Классической задачей, при котором используется блокировка, это задача извлечения элемента из очереди, c которой одномоментно может работать ограниченное количество клиентов. Доступ к такому элементу одновременно должен получить только один клиент очереди.
В нескольких наших продуктах используется очередь, хранимая в БД, доступ к которой должен быть синхронизирован между клиентами. Рассмотрим, как решалась данная задача в наших продуктах.
Представим, что у нас есть очередь задач для клиентов, которая хранится в БД. Каждую задачу может получить одновременно максимум N клиентов. Т.е. появляется связанность задачи с ее результатами, это связь 1-N. Это привносит дополнительную сложность, т.к. извлекаемые данные находятся в двух таблицах, связанных внешним ключом. Структура таблиц выглядит примерно следующим образом:
Task — таблица с задачами
TaskResult — таблица с результатами задач.
Для решения этой задачи мы использовали блокировку обновления (UPDLOCK) записей корневой таблицы Task совместно с хинтами ROWLOCK и READPAST.

Использование блокировки UPDLOCK гарантировало нам, что к задаче не смогут получить доступ другие клиенты, хинтом ROWLOCK мы рекомендовали MS SQL серверу использовать блокировку на уровне строки, READPAST — выбирал нам только незаблокированные другими транзакциями записи. Помимо извлечения данных, мы также во все операции обновления данных, как корневой, так и дочерней таблицы, включили хинты UPDLOCK и ROWLOCK.
Таким образом мы решили задачу конкурентного доступа к задачам клиентами.
Задача извлечения данных, которые параллельно изменяются
В высоконагруженных системах, разработкой которых занимается компания ITA Labs, часто бывает необходимо мониторить данные, которые часто изменяются параллельными транзакциями. Если нам важно лишь состояние данных в конкретный момент времени, можно не ставить блокировку вообще. В таком случае есть риск прочтения неконсистентных данных в конкретный момент времени, но которые актуализируются спустя некоторое время. При этом мы увеличиваем скорость чтения отображаемых данных, вместо того, чтобы ждать освобождения блокировок. Это очень важно для своевременного отклика программы и увеличивает дружественность пользовательского интерфейса.
В одном из разрабатываемых продуктов нам необходимо было отображать историю выполненных задач конкретным оператором, а также выбирать команды, соответствующие определенным критериям, т.е. фильтровать. Из-за того, что параллельно к этим данным обращались множество клиентов с операциями обновления, таблица блокировалась и прочитать данные не всегда удавалось за необходимое время, выходил таймаут. Эту проблему мы решили чтением данных без блокировки с помощью хинта NOLOCK, но сразу отметим, что подобный метод не годится, если на основании прочитанных данных будет приниматься какое-либо решение. Пример:

Указание хинта NOLOCK указывает SQL Server-у не использовать блокировки при выполнении данной транзакции, в результате чтение данных происходит быстро. Но здесь стоит отметить один момент — на самом деле все же один тип блокировки, даже при использовании хинта NOLOCK, будет устанавливаться. Это блокировка стабилизации схемы (schema stability lock, Sch-S). Но обычно редко во время выполнения бизнес-логики, затрагивающее работу с БД, требуется менять схему БД, поэтому данная блокировка не будет оказывать никакого влияния. Но, в тех системах, в которых все же меняется схема БД параллельно с доступом к данным БД, нужно учитывать данное обстоятельство и использовать другие механизмы блокировок.
Задача синхронизации доступа к модифицируемым данным
Очень часто в распределенных системах встречается задача синхронизации доступа к данным с последующей их модификацией. В наших продуктах мы также сталкиваемся с подобным. В таких случаях необходимо использовать блокировку обновления UPDLOCK в операторе извлечения данных. Это гарантирует, что извлекаемые для последующего изменения данные блокируются до момента завершения транзакции.

Рассмотрим пример на Рис.2. Допустим, у нас есть 2 параллельно выполняющиеся транзакции, которые выбирают вторую строку из таблицы Table для последующей модификации. Для того, чтобы предотвратить одновременный доступ к этой строке для модификации мы наложили блокировку обновления UPDLOCK на оператор выборки SELECT. Таким образом, доступ ко второй строке получит транзакция, первой наложившая блокировку обновления. Вторая же транзакция будет ожидать освобождения наложенной блокировки.
Управление эскалацией блокировок
Эскалация блокировок — это процесс, который направлен на оптимизацию работы сервера, позволяющий заменять множество низкоуровневых блокировок одной или несколькими блокировками более высокого уровня.
Например, если у нас создано множество блокировок уровня строки, и все строки принадлежат одной странице, то сервер, в целях экономии ресурсов, может заменить их все одной блокировкой уровня страницы и далее до уровня всей таблицы (см. Рис. 3).

В наших продуктах мы также использовали управление опцией эскалации блокировок там, где это нужно. В одном из проектов мы столкнулись с эскалацией блокировок с уровня строк до более верхних уровней — страниц, экстентов. Эскалации возникали при высокой нагрузке на несколько связанных между собой таблиц. Транзакции блокировали друг друга и завершались по ошибке. Чтобы решить данную проблему мы запретили эскалацию блокировок для некоторых таблиц, которые ссылались на множество других таблиц.

После отключения эскалации блокировок, проблема с взаимными блокировками решилась. Общая пропускная способность системы тоже возросла за счет того, что значительно сократилось общее количество блокировок.
Также следует отметить, что нельзя злоупотреблять этой опцией и отключать эскалацию там, где это не требуется, т.к. это может негативно сказаться на производительности SQL Server и скорости выполнения SQL-инструкций.
Взаимоблокировки
Взаимоблокировка (deadlock) — это ситуация при которой, одному процессу для продолжения работы требуется ресурс, захваченный вторым процессом, а второму процессу требуется ресурс, захваченный первым процессом. В такой ситуации оба процесса оказываются в заблокированном состоянии и не могут продолжать работу.
Рассмотрим простейший пример. Допустим, у нас есть таблица Students, состоящая из 2-х строк:

Параллельно запускаются 2 транзакции:


На операторе обновления мы получим блокировку в обеих транзакциях. Что же тут происходит? Оператор SELECT в обеих транзакциях накладывает блокировку обновления на вторую и первую строки соответственно. Затем, при выполнении оператора UPDATE в первой транзакции, процесс пытается наложить эксклюзивную блокировку на первую строку, но не может этого сделать, т.к. она заблокирована второй транзакцией и остается ждать его освобождения.
Аналогично вторая транзакция при выполнении оператора UPDATE пытается наложить эксклюзивную блокировку на вторую строку, но она уже заблокирована первой транзакцией и процесс остается ждать освобождения блокировки. Это классический пример взаимной блокировки.
Обе транзакции ждут освобождения заблокированных друг другом ресурсов. Но на этом процессы не виснут. MS SQL Server с помощью встроенного менеджера блокировок определяет взаимные блокировки и разрешает их. Разрешает очень просто — жертвует одной из транзакций, т. е. попросту откатывает ее и возвращает ошибку. Вторая транзакция продолжит выполняться. Какая транзакция будет выбрана в качестве жертвы — определяет сам MS SQL Server, исходя из соображений производительности или же, определяется при помощи задания приоритета DEADLOCK_PRIORITY.
Заключение
В данной статье мы рассказали о блокировках и для чего они нужны. Если говорить вкратце — блокировки являются механизмом для реализации требования различных уровней изоляции транзакций.
Мы рассмотрели проблемы, которые приходилось решать на практике с помощью блокировок в многопользовательской конкурентной среде:
– это задача извлечения данных из очереди — когда одномоментно к данным имеет доступ только один клиент;
– это задача извлечения изменяемых данных с конкурентным доступом — когда клиенты одновременно обращаются к общим, часто изменяемым данным, но только для чтения;
– это задача синхронизации доступа к модифицируемым данным — когда необходимо получить доступ к данным с последующим изменением.
Также мы коснулись темы эскалации блокировок — когда блокировки более низкого уровня укрупняются до уровня страниц, таблиц при превышении критического значения.
Ну и на десерт, мы затронули вкратце о взаимоблокировках — ситуации, при котором 2 процесса ждут освобождения заблокированного ресурса друг у друга.
Эта тема заслуживает отдельного внимания, и в продолжении статьи мы расскажем о том, как диагностировать и бороться с взаимоблокировками.
Автор статьи: Николай Иванов, Старший Разработчик, ITA Labs
7 вещей, которые разработчик должен знать о SQL Server
Привет. Я бывший разработчик, ставший администратором баз данных, и ниже написал о том, что, в своё время, хотел бы услышать сам.
7. Производительность скалярных UDF оставляет желать лучшего
Хорошие разработчики любят повторно использовать код, помещая его в функции и вызывая эти функции из разных мест. Это отлично работает на уровне приложения, но на уровне баз данных может привести к огромным проблемам с производительностью.
Посмотрите этот пост о принудительном использовании параллелизма – в частности, список того, что приводит к генерации «однопоточного» плана выполнения запроса. Скорее всего, использование скалярных UDF (прим. переводчика: а для серверов младше 2008 R2 и не только скалярных) приведёт к тому, что ваш запрос будет выполняться в одном потоке (*грустно вздыхает*).
Если вы хотите, чтобы ваш код использовался повторно, подумайте о хранимых процедурах и представлениях. (На самом деле, они могут привнести свои проблемы с производительностью, но я просто хочу направить вас на правильный путь как можно быстрее, а UDF, увы, таковым не является).
6. «WITH (NOLOCK)» не означает, что блокировок не будет вообще
На одном из этапов своей карьеры разработчика вы можете начать использовать хинт WITH (NOLOCK) повсеместно, поскольку с ним ваши запросы выполняются быстрее. Это не всегда плохо, но может сопровождаться неожиданными побочными эффектами, про которые Kendra Little рассказывала вот в этом видео. Я же сфокусируюсь только на одном из них.
Когда ваш запрос обращается к какой-либо таблице, даже с хинтом NOLOCK, вы накладываете блокировку стабилизации схемы (schema stability lock, Sch-S). Никто не сможет изменить эту таблицу или её индексы до тех пор, пока ваш запрос не завершится. Это не кажется серьёзной проблемой до тех пор, пока вам не понадобится удалить индекс, но вы не сможете этого сделать, поскольку люди постоянно работают с этой таблицей, находясь в полной уверенности, что не создают никаких проблем, поскольку они используют хинт WITH (NOLOCK).
Здесь нет «серебряной пули», но начните читать об уровнях изоляции SQL Server — я полагаю, что уровень изоляции READ COMMITTED SNAPSHOT будет наилучшим выбором для вашего приложения. Вы будете получать целостные данные с меньшим количеством проблем с блокировками.
5. Используйте три строки соединения в своём приложении
Я знаю, что сейчас у вас только один SQL Server, но поверьте мне, оно стоит того. Создайте три строки соединения, которые сейчас будут ссылаться только на один сервер, но потом, когда вы задумаетесь о масштабировании, у вас будет возможность использовать разные сервера «для обслуживания» каждой из этих строк.
4. Используйте промежуточную БД
Вероятно, вы используете БД для выполнения каких-то второстепенных задач – вычисления, сортировка, загрузка и т.д. Если вдруг эти данные пропадут, вы вряд ли сильно расстроитесь, но вот структура таблиц – это, конечно, другое дело. Сейчас вы делаете всё в «основной базе данных» вашего приложения.
Создайте отдельную базу данных, назовите её MyAppTemp, и делайте всё в ней! Поставьте ей простую модель восстановления и просто создавайте резервную копию раз в день. Не заморачивайтесь с высокой доступностью или аварийным восстановлением этой БД.
Использование такой техники имеет кучу плюсов. Она минимизирует количество изменений в основной БД, а значит резервные копии журнала транзакций и дифференциальные бэкапы будут делаться быстрее. Если вы используете log shipping, по-настоящему важные данные будут копироваться быстрее. Вы даже можете хранить эту БД отдельно от других баз, например на недорогом, но шустром SSD-диске, оставив основную систему хранения данных для критически важных в продакшене данных.
3. «Вчерашние» статьи и книги могут перестать быть актуальными сегодня.
SQL Server вышел уже больше десяти лет назад и за эти годы в нём произошло множество изменений. К сожалению, старые материалы не всегда обновляются, чтобы описать «сегодняшние» изменения. Даже свежие материалы из проверенных источников могут быть неправильными – вот, например, критика методики Microsoft по повышению производительности SQL Server. Microsoft Certified Master Jonathan Kehayias нашёл множество по-настоящему плохих советов в документе Microsoft.
Когда вы слышите что-то, что звучит как хороший совет, я предлагаю вам использовать стратегию, обратную стратегии доктора Фила. Доктор Фил говорит, что вы должны «проникнуться» любой идеей на протяжении 15 минут. Вместо этого, попробуйте возненавидеть её – постарайтесь опровергнуть то, что вы прочитали перед тем как применять это в продакшене. Даже если совет чертовски хорош, он может быть не очень-то и полезным на вашей системе. (Да, это относится и к моим советам).
2. Избегайте использования ORDER BY; сортируйте данные в приложении
Как можно быстрее отдавайте полученные результаты запросов своему приложению и там сортируйте. Вероятно, ваш сервер приложений спроектирован таким образом, что сможет распределить нагрузку процессора по разным узлам, в то время как ваш сервер баз данных так не может.
UPD. Я получил множество комментариев о том, что приложение нуждается, например, только в десяти строках, вместо десяти миллионов строк, возвращаемых запросом. Да, конечно, если вы пишете TOP 10, вам нужна сортировка, но как на счёт того, чтобы переписать запрос так, чтобы он не возвращал кучу ненужных данных? Если же данных так много, что серверу приложений приходится тратить слишком много ресурсов на сортировку – так ведь и SQL Server выполняет ту же самую работу. Мы поговорим о том как находить такие запросы на вебинаре, ссылка на который есть в конце поста. Кроме того, помните, что я сказал «Избегайте использования ORDER BY», а не «Никогда не используйте ORDER BY». Я точно так же использую эту инструкцию – но, если я могу избежать этого на очень дорогом уровне баз данных, я стараюсь это сделать. Вот что означает «избегать».
(А это часть, в которой фанаты MySQL и PostgreSQL рассказывают о том как снизить стоимость лицензий, используя СУБД с открытым исходным кодом). (А в этой части вы ждёте, что я им остроумно отвечу, но я не буду этого делать. Если вы разрабатываете новое приложение и задумались о выборе БД, прочтите мой ответ на StackOverflow о том какая БД выдержит наибольшую нагрузку.)
1. У SQL Server есть встроенные инструменты для поиска узких мест, не влияющие на производительность
Динамические административные представления SQL Server (DMV) могут показать вам все места, пагубно влияющие на производительность, т.е.:
Примечание переводчика: любые предложения и замечания по переводу и стилистике, как обычно, приветствуются.