Установка и настройка MongoDB на Debian, а также ReplicaSet и пара других мелочей

Это руководство описывает пошаговую установку и настройку реплики из 3 узлов mongoDB на базе движка WiredTiger. А также несколько полезных мелочей для людей, впервые столкнувшихся с MongoDB.
Важное уточнение:
Немного о движке WiredTiger
Engine WiredTiger — новый движок mongoDB, использующийся по умолчанию вместо MMAP, начиная с версии 3.4. Хорош тем, что работает с данными на уровне коллекций и отдельных документов, а не полностью базой. Также устраняет проблему Global lock по вышеуказанной причине, из-за чего и был выбран в продакшен.
Установка OS и компонентов
Ставим Debian любой удобной вам версии, у меня использовался 8.6.0.
Для упрощения масштабирования узлов и баз данных, рекомендую использовать lvm.
Из компонентов понадобится только ssh для более удобного доступа к серверу.
Установка MongoDB.
У меня используется бесплатная Community Edition, руководство будет на её основе.
По необходимости допишу Enterpise версию, т.к. она тоже крутилась и разбиралась.
Данное руководство описывается для варианта 3-х серверов (master, slave, arbiter).
Копируем репозиторий и сохраняем изменения.
Обновляем список доступных пакетов
Повторяем процедуру для 3(трех) серверов,
На этом первоначальная настройка завершена.
Теперь переходим к настройке mongoDB.
Настройка и добавление серверов в Replica Set
В начале было слово
Давайте для начала разберемся, что такое replica set.
Replica Set — это кластер серверов MongoDB, реализующий механизм репликации master-slave и автоматическое переключение между ними. Это рекомендуемый механизм репликации от разработчиков MongoDB. ссылка на офф. документацию.
Мы используем механизм репликации, приведенный на картинке:
мастер, два вторичных и арбитр.
Primary — основной сервер mongoDB.
Secondary — точные копии баз(ы) данных с real-time синхронизацией.
Arbiter — сервер выбора вторичной реплики с высшим приоритетом, которая станет главной в случае падения сервера.
ОЧЕНЬ ВАЖНО:
Arbiter отвечает только за выборы преемника, сам стать преемником он не может, поэтому рекомендуется отдавать под арбитра минимальные ресурсы.
ЕЩЁ БОЛЕЕ ВАЖНО:
Технически можно вообще жить без арбитра, однако с ним выборы будут происходить в разы быстрее, соответственно время простоя будет минимизировано. Плюс есть ненулевая вероятность потерять ReplicaSet целиком.
Primary
Настройки пишем в файл /etc/mongod.conf У меня файл выглядит следующим образом:
Указываемые значения переменных:
dbPath — путь к базе данных. При указании на пустое место, создаст там базы. При разворачивании бэкапа подцепит существующую.
journal — включает журналирование.
replSetName — название реплики. Должно быть идентичным у всех узлов внутри реплики.
bindIp — список адресов, с которых можно принимать соединения по порту 27017.
Далее для конфигурирования я использовал саму mongoDB:
попадаем внутрь и первым делом проверяем статус:
Начальный статус должен быть 0 — startup. Означает что узел не является членом ни одной реплики.
Инициализируем реплику.
Выполняем в MongoShell на первичном узле
Сразу после добавления в реплику узел будет в статусе 5 — Startup2, это означает что он присоединился к реплике и в данный момент синхронизируется. Может занять продолжительное время.
Добавляем следующие узлы:
Статусы в rs.status() будут:
1 — Primary
2 — Secondary
7 — Arbiter
Приоритеты
Первый:
Необходимо проставить приоритеты (цифры member id берем из статуса):
Чем выше цифра приоритета, тем ниже сам приоритет при выборе Primary узла.
Второй:
Добавляем узлы с заранее прописанным приоритетом:
Проверяем что все узлы доступны и выставлены с правильными приоритетами:
В моем случае конфиги и статусы приобрели следующий вид:
При добавлении узла в уже существующую реплику она какое-то время будет недоступна в связи с синхронизацией.
На этом установка и настройка MongoDB в режиме ReplicaSet завершена и можно с чистой совестью наполнять базу данными.
Другие полезные команды
Сбрасывание PRIMARY. Смена первичного узла и переназначение приоритетов
60 секунд — время, в течение которого сервер, с которого запущено выполнение команды, не может стать Primary; 40 секунд — время перевыборов нового Primary.
30 секунд — время отключения Primary и перевыборы. Выполнение команды допустимо с любого из серверов mongoDB.
Узел, с которого запущена команда, в течение 60 секунд не сможет стать Primary.
/var/lib/mongodb/ — Тут лежат файлы баз.
Восстановление из дампа:
Восстанавление базы в каталог по умолчанию. Если файл в с таким именем есть, то он перезаписывается:
Восстановление всех баз из указанного каталога:
Восстановление отдельной таблицы(коллекции):
Создание дампа
создание бэкапа всех баз в папку Backup:
создание бэкапа отдельной базы:
создание бэкапа отдельной таблицы:
Запуск от имени root, создание бэкапа указанной базы в указанный каталог + текущая дата:
Подумываете об использовании MongoDB?
Будет ли MongoDB правильным выбором для вашего приложения?
Выбор базы данных — важный этап разработки приложения. Неправильный выбор может негативно сказаться как на процессах разработки и сопровождения вашего продукта, так и привести к снижению производительности.
В принципе, можно использовать любую базу данных, и она будет работать. Но одна база данных лучше работает с одним типом рабочей нагрузки, а другая с другим.
Не стоит выбирать MongoDB только потому, что это круто и ее используют много компаний. Вы должны понимать насколько она соответствует вашей рабочей нагрузке и ожиданиям. Поэтому выбирайте правильный инструмент.
В этой статье мы обсудим несколько возможностей MongoDB, которые стоит знать прежде чем вы решитесь выбрать и развернуть ее.
MongoDB работает с JSON-документами и разработчикам это нравится
Базовым компонентом MongoDB является документ, очень похожий на JSON. Технически это BSON, который содержит некоторые дополнительные данные (например, datetime), которые недопустимы в JSON.
Мы можем рассматривать документ как запись в реляционной базе данных. Документы помещаются в коллекции, которые соответствует концепции таблиц в реляционной базе данных.
JSON-документы очень популярны среди программистов и используются при разработке веб-сервисов, приложений и для обмена данными. Работать с базой данных со встроенной поддержкой таких данных может быть действительно эффективно.
Разработчики часто выбирают MongoDB, потому что ее можно начать использовать без специальных знаний об администрировании и проектировании баз данных, а также без изучения сложного языка запросов. Язык запросов MongoDB также представлен в формате JSON документов.
Разработчики могут легко создавать, сохранять, запрашивать и изменять JSON-документы. Здорово! Обычно это значительно ускоряет разработку.
В MongoDB нет схемы
Вы знакомы с реляционными базами данных? Наверняка да, ведь реляционные базы данных используются и изучаются уже очень давно и в школе и университете. В настоящее время на рынке это наиболее широко используемый тип баз данных.
Реляционная схема требует предопределенной и фиксированной структуры таблиц. Каждый раз, когда вы добавляете или изменяете столбец, вам необходимо выполнить DDL-запрос, и приложить дополнительные усилия, чтобы изменить код вашего приложения для работы с новой структурой. В случае значительных изменений, требующих изменения нескольких столбцов и/или создания новых таблиц, изменения в приложении могут быть весьма значительными. Отсутствие схемы в MongoDB означает, что ничего из этого не требуется. Вы просто добавляете документ в коллекцию и все. Например, у вас есть коллекция с данными пользователя. Если в какой-то момент вам нужно добавить новое поле «date_of_birth», вы просто начинаете работать с новыми JSON-документами с дополнительным полем. И все. Нет необходимости менять что-либо в схеме.
Вы также можете вставлять в одну и ту же коллекцию совершенно разные JSON-документы, представляющие разные сущности. Технически это осуществимо, но все же так делать не рекомендуется.
MongoDB также значительно сокращает цикл разработки приложения по нетехнической причине — устраняется необходимость координации миграции изменений схемы базы данных с DBA. Нет необходимости ждать, пока команда DBA еще раз все проверит и выпустит релиз в продакшн (с планами отката), что, как правило, потребует еще и некоторого простоя.
В MongoDB нет внешних ключей, хранимых процедур и триггеров. JOIN поддерживается, но не приветствуется
Проектирование реляционной базы данных должно осуществляться с учетом того, чтобы SQL-запросы могли выполнять различные JOIN для нескольких таблиц по определенным колонкам. Также необходимо предусматривать внешние ключи (foreign key) для контроля целостности данных и автоматических изменений в связанных полях.
Что насчет хранимых процедур? Хранимые процедуры могут быть полезны для встраивания в базу данных некоторой логики приложения для упрощения ряда задач или повышения безопасности.
А триггеры? Триггеры нужны для автоматического инициирования изменений данных при определенных событиях, таких как добавление / изменение / удаление строк. Они помогают управлять согласованностью данных и, в некоторых случаях, упростить код приложения. Но они отсутствуют в MongoDB. Так что имейте это в виду.
Примечание: честно говоря, есть агрегирование, которое может реализовать то же самое, что и LEFT JOIN, но это единственный случай.
Как жить без JOIN?
Соединение (JOIN) должно выполняться в коде вашего приложения. Если требуется выполнить JOIN двух коллекций, то сначала нужно прочитать первую, выбрать поле для JOIN и использовать его для запроса второй коллекции и т.д. Это кажется весьма дорогим с точки зрения разработки приложения и может привести к увеличению количества запросов. И это действительно так. Хорошая новость заключается в том, что в большинстве случаев вам не придется использовать JOIN.
Помните, что MongoDB — это база данных без схемы, не требующая нормализации. Если вы правильно спроектируете коллекции, то сможете встраивать (embed) и дублировать данные в одной коллекции без необходимости создания дополнительных коллекций. Таким образом, вам не придется выполнять соединение, потому что все данные, которые вам нужны, уже будут в одной коллекции.
Внешние ключи не поддерживаются. Но так как можно встраивать в одну коллекцию несколько документов, они вам просто не нужны.
Хранимые процедуры могут быть легко реализованы в виде внешних скриптов, написанных на любом языке программирования. Триггеры также реализуются снаружи с помощью Change Stream API.
Если у вас много коллекций, содержащих ссылки на поля, то в коде приложения вам придется реализовать много JOIN или выполнить множество проверок для обеспечения согласованности. Это все возможно, но потребует больших затрат на разработку. В этом случае MongoDB может оказаться неправильным выбором.
Очень просто развернуть репликацию и шардирование
MongoDB изначально разрабатывалась для работы в распределенных окружениях. Она была задумана как часть большого пазла. Для реализации репликации и шардирования сервер mongod может работать совместно с другими экземплярами mongod без использования каких-либо сторонних инструментов.
Replica Set (набор реплик) — это группа процессов mongod, которые обслуживают один и тот же набор данных, обеспечивая избыточность и высокую доступность. С оговорками, касающимися потенциально устаревших данных, вы также бесплатно получаете масштабируемость чтения. Для продакшн-решения всегда следует применять такую конфигурацию.
Sharding Cluster развертывается как группа из нескольких Replica Set с возможностью разделения и равномерного распределения данных по ним. В дополнение к избыточности, высокой доступности и масштабируемости чтения Sharding Cluster обеспечивает масштабируемость записи. Топология шардинга подходит для развертывания очень больших наборов данных. Количество шардов, которые вы можете добавить, теоретически не ограничено.
Обе топологии можно изменить в любое время, добавив больше серверов и шардов. Что еще более важно, никаких изменений в приложении не требуется, поскольку каждая топология полностью прозрачна с точки зрения приложения.
И, наконец, развертывание таких топологий очень просто. Вначале вам придется потратить некоторое время, чтобы понять несколько основных концепций, но затем, в течение нескольких часов, вы сможете развернуть даже очень большой кластер с шардированием. В случае нескольких серверов вместо того, чтобы делать все вручную, вы можете автоматизировать многие вещи с помощью плейбуков Ansible или других подобных инструментов.
Дополнительные материалы:
В MongoDB есть индексы, и они очень важны
В MongoDB можно создавать индексы для полей JSON-документа. Индексы используются так же, как и в реляционных базах данных для ускорения выполнения запросов и уменьшения использования ресурсов компьютера: памяти, времени процессора и операций ввода-вывода в секунду (IOPS).
Для всех регулярно выполняемых запросов, операций изменения и удаления данных необходимо создавать необходимые индексы, которые помогут ускорить их выполнение.
MongoDB обладает очень мощными возможностями индексирования. Есть TLL-индексы, GEO Spatial — индексы для пространственных данных, индексы для элементов массива, частичные (partial) и разреженные (sparse) индексы. Если вы хотите подробнее изучить доступные типы индексов, вы можете обратиться к следующим статьям:
Создавайте все необходимые индексы для ваших коллекций. Они очень помогут вам улучшить общую производительность вашей базы данных.
MongoDB требует много памяти
MongoDB использует оперативную память для кэширования наиболее часто и недавно используемых данных и индексов. Чем больше этот кэш, тем лучше будет общая производительность, потому что MongoDB сможет быстрее извлекать большой объем данных. Кроме того, изменения данных происходят в памяти. Запись на диск выполняется асинхронно: сначала в файл журнала (обычно в пределах 50 мс), а затем в обычные файлы данных (один раз в минуту).
WiredTiger — наиболее популярный движок хранения данных, используемый в MongoDB. Раньше это был MMAPv1, но в последних версиях он больше не доступен. Движок хранения WiredTiger использует кэш памяти (WiredTiger Cache) для кэширования данных и индексов.
Помимо WTCache, для доступа к диску MongoDB использует кэш файловой системы. Это еще одна важная оптимизация, для которой также может потребоваться значительный объем памяти.
Кроме того, MongoDB использует память для управления клиентскими соединениями, выполнения сортировки в памяти, временных данных при выполнении пайплайнов агрегации и другого.
Будьте готовы обеспечить MongoDB достаточным объемом памяти.
Но сколько нужно памяти? Эмпирическим правилом является оценка размера «рабочего набора».
«Рабочий набор» — это данные, которые чаще всего запрашиваются вашим приложением. Типичное приложение работает с ограниченным объемом данных. При обычной работе ему не нужны все данные. Например, в случае с временными рядами (time-series data), скорее всего, вам нужно будет получить только последние несколько часов или дней. Только в редких случаях вам понадобится читать более старые данные. В таком случае в вашем рабочем наборе может будут храниться данные только за несколько дней.
Предположим, что ваш набор данных составляет 100 ГБ, и вы оценили ваш рабочий набор в 20%, тогда вам потребуется как минимум 20 ГБ для WTCache.
Так как по умолчанию для WTCache используется 50% памяти (обычно мы рекомендуем не увеличивать ее значительно), то на сервере должно быть 40 ГБ памяти.
Каждый случай индивидуален, и иногда бывает трудно правильно оценить размер рабочего набора. В любом случае, основная рекомендация заключается в том, что вы должны предоставить максимальное количество памяти, которое можете себе позволить. Это будет полезно для MongoDB.
В каких случаях использовать MongoDB?
На самом деле таких ситуаций очень много. Я видел использование MongoDB в самых разных приложениях.
Например, MongoDB подходит для следующих типов приложений:
Welcome WiredTiger to MongoDB
This blog post was updated on January 22, 2014 to reflect the renaming of MongoDB 2.8 to 3.0.
Today, we are announcing our acquisition of WiredTiger, an open source, high-performance storage engine company co-founded and led by world-renowned experts Keith Bostic and Dr. Michael Cahill. Keith is a co-founder of Sleepycat Software, where he and Michael both architected Berkeley DB, “the most widely used database toolkit in the world, with hundreds of millions of deployed copies running in everything from routers and browsers to mailers and operating systems.” [1]
We first met the WiredTiger team while we were still seeking out a preliminary set of storage engines to pilot the pluggable storage engine API. At this point we were still developing the API, and thinking about the types of storage engines that we want to make available to users. We wanted a flagship engine, one that could offer our users advanced features and performance improvements for write-heavy workloads. It was during this time that we started getting questions from the WiredTiger team about the storage engine API… for the integration that they had already largely built!
When we saw what great work the WiredTiger team did on the MongoDB codebase, we knew right away that they were the kind of engineers we’d love to work with. We went up to Boston for an integration summit.
The WiredTiger team was equally enthusiastic about working with MongoDB, it turned out.
To sum up: Keith and Michael are both luminaries in the fields of data storage and transaction management, and they and the entire WiredTiger team are on exactly the same page as we are. They are true paragons of the free software movement, and on their team, 15 year’s experience in the field makes you a relative newcomer. As much as the synergy was obvious from the standpoint of complementary technologies, it was even more obvious from a team composition standpoint.
Following the acquisition, WiredTiger will live on as its own project, under active development, and we will drive towards making it the default storage engine for MongoDB 3.2. For those that want to adopt WiredTiger under 3.0, there is a no-downtime migration path. As for MMAPv1, it will continue to see active development and support, even after WiredTiger becomes the default. It will become one of a wide array of options made possible by our pluggable API, and for certain workloads, it will be the best choice.
The WiredTiger storage engine is available today in the latest release candidate for MongoDB 3.0. Have a look at the release notes, which contain instructions for upgrading, as well as for migrating to the WiredTiger storage engine. As we fine-tune the release, we are encouraging members of the community to test the RC through our Bug Hunt, offering prizes to those that identify critical issues. As of this announcement, we’re extending the hunt through the holidays! If you’re ready to test out just how amazing our new storage engine is, we’d love to have your feedback on how it works for your application.
[1] Bostic, Keith, and Margo Seltzer. «Berkeley DB.» Ed. Amy Brown and Greg Wilson. The Architecture of Open Source Applications.
To learn more about upgrading your deployment of MongoDB to 3.0, explore our consulting services
An Overview of WiredTiger Storage Engine for MongoDB


Every database system has a structured component which is responsible for maintaining how data is stored and served both in memory and disk. This is often referred to as a storage engine. More often when evaluating the architecture of operational databases, developers put into the account on first-hand factors such as data modeling, reduced latency, improved throughput operations, data consistency, scalability easiness, and minimal fault tolerance. In spite of that, one needs to have a detailed and advanced knowledge on the underlying storage engine for a better tuning so that it delivers on the highlighted factors efficiently.
A simple cycle of an application to db system is illustrated below.
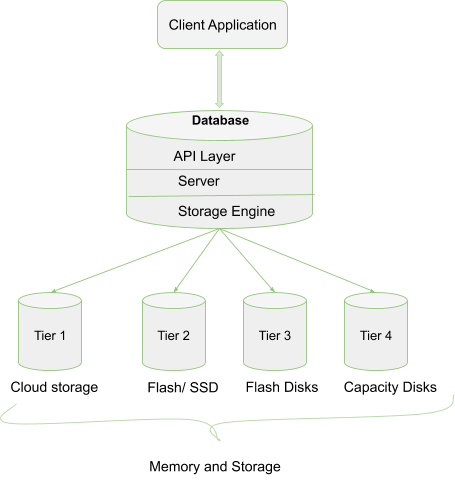
WiredTiger Storage Engine
MongoDB supports mainly 3 storage engines whose performance differ in accordance to some specific workloads. The storage engines are:
The WiredTiger storage engine has both configurations of a B-Tree Based Engine and a Log Structured Merge Tree Based Engine.
B-Tree Based Engine
This is one of the ancient storage engines from which other sophisticated setups are derived from. It is a self-balancing tree data structure that ensures data sorting and enables searches, sequential access, insertions and deletes in a logarithmic manner. It is row-based storage such that each row is considered as being a single record in the database
Merits of a B-Tree Storage Engine
Limitations of a B-Tree storage engine
Log Structured Merge Tree Based Engine
Because of the poor write performance of the B-Tree Based Engine, developers had to come up with a way to cope with larger datasets to DBMS. The Log Structured Merge Tree Based Engine (LSM Tree) was hence established to improve performance for indexed access to files with high write volume over an extended period. In this case, random writes at the first stage of cascading memory are turned into sequential writes at the disk-based first component.
Merits of a LSM Tree Storage Engine
Limitations of a B-Tree storage engine
Consume more memory as compared to B-Tree during read operations due to read and space amplification. However, some approaches such as bloom filters have mitigated this effect in practice such that the number of files to be checked during a point query is reduced.
The WiredTiger technology was designed in a way to employ both B-Tree and LSM advantages making it sophisticated and the best storage engine for MongoDB. IT is actually MongoDB’s default storage engine.
WiredTiger Storage Engine Architecture
As mentioned above, it involves the concept of two basic storage engines that is the B-Tree and LSM Tree engines hence it is a multiversion concurrency control (MVCC) storage engine. The merits of the two combined enable the system see a snapshot of the database at the time it accesses a collection. Checkpoints are established such that a consistent view of data is recorded to disk between checkpoints. In case of a crash between checkpoints, it is easy to recover with these checkpoints or rather, even if there are no checkpoints for data, one can recover it from disk journal files.
Extensive usage of cache rather than disk to enhance low latency. WiredTiger storage engine relies heavily on the OS page-cache such that compressed data is fetched without involving the disk. Besides, the least recently used data is cleared from the RAM preserving more space for the cache.
B-Tree storage concept offers highly efficient reads and good write performance with low CPU utilization. It also has a document-level locking implementation that enables highly concurrent workloads and this concurrency consequently facilitates the server to take advantage of many core CPUs. In general, all theses enhances the high scalability of the database.
The enterprise edition supports on-disk encryption for the WiredTiger storage engine which is a feature that greatly improves data security.
WiredTiger storage engine enables a write-ahead logging which ensures an automatic crash recovery and makes writes durable.
Advantages of the WiredTiger Storage Engine
WiredTiger Storage Engine Setbacks
Difficulties in updating data. The concurrency scheme prevents in-place updates such that updating a field value in a document re-writes the entire document.
Conclusion
WiredTiger storage engine integrates concepts from two major storage engines,the B-Tree and LSM tree storage engine to achieve maximum and optimal performance. Weighing the advantages from both cases and collectively employing them makes the WiredTiger a general purpose storage engine. For this reason, in the current versions of MongoDB, it is the default storage engine. This implies if you really don’t have a strong reason to abhor it, then it is the best for your data. However, the storage engine choice heavily relies on your data use case or rather where the WiredTiger cannot meet your expectations. In general, this is the best default storage engine.