HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
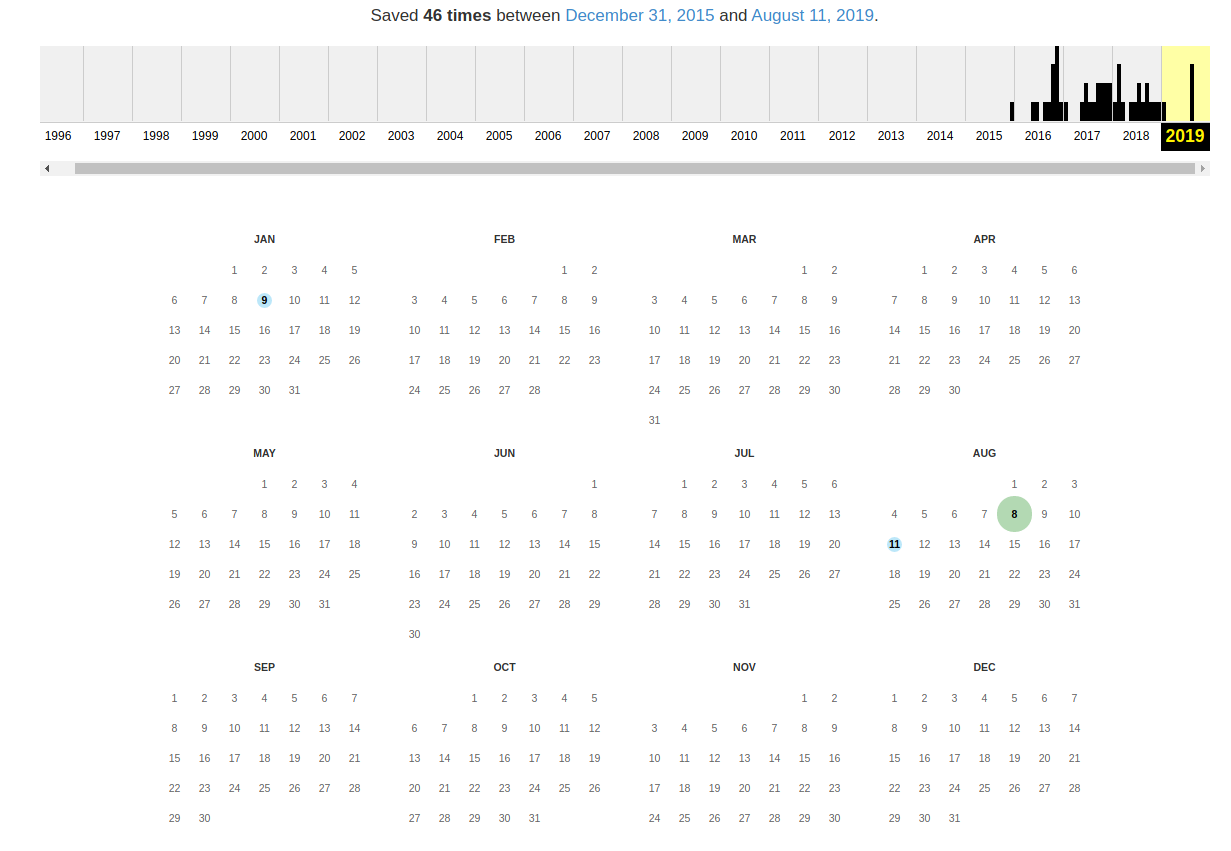
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
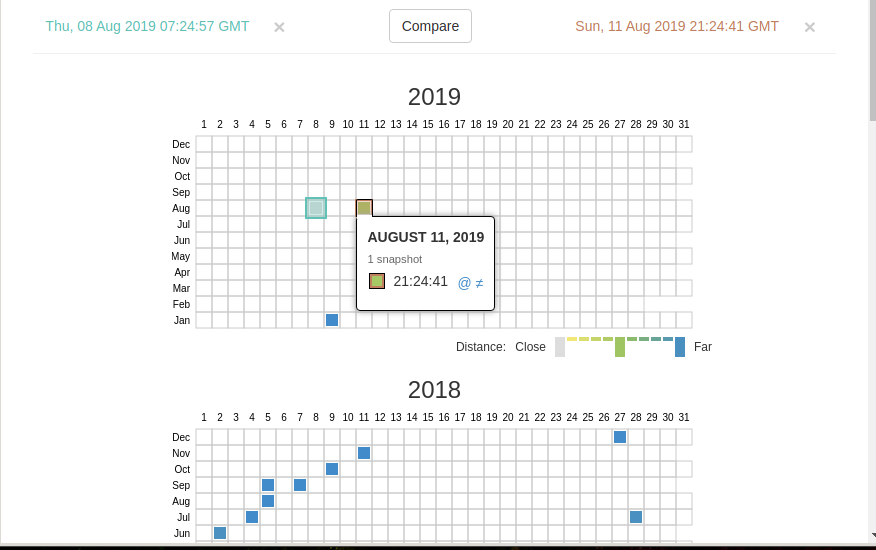
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
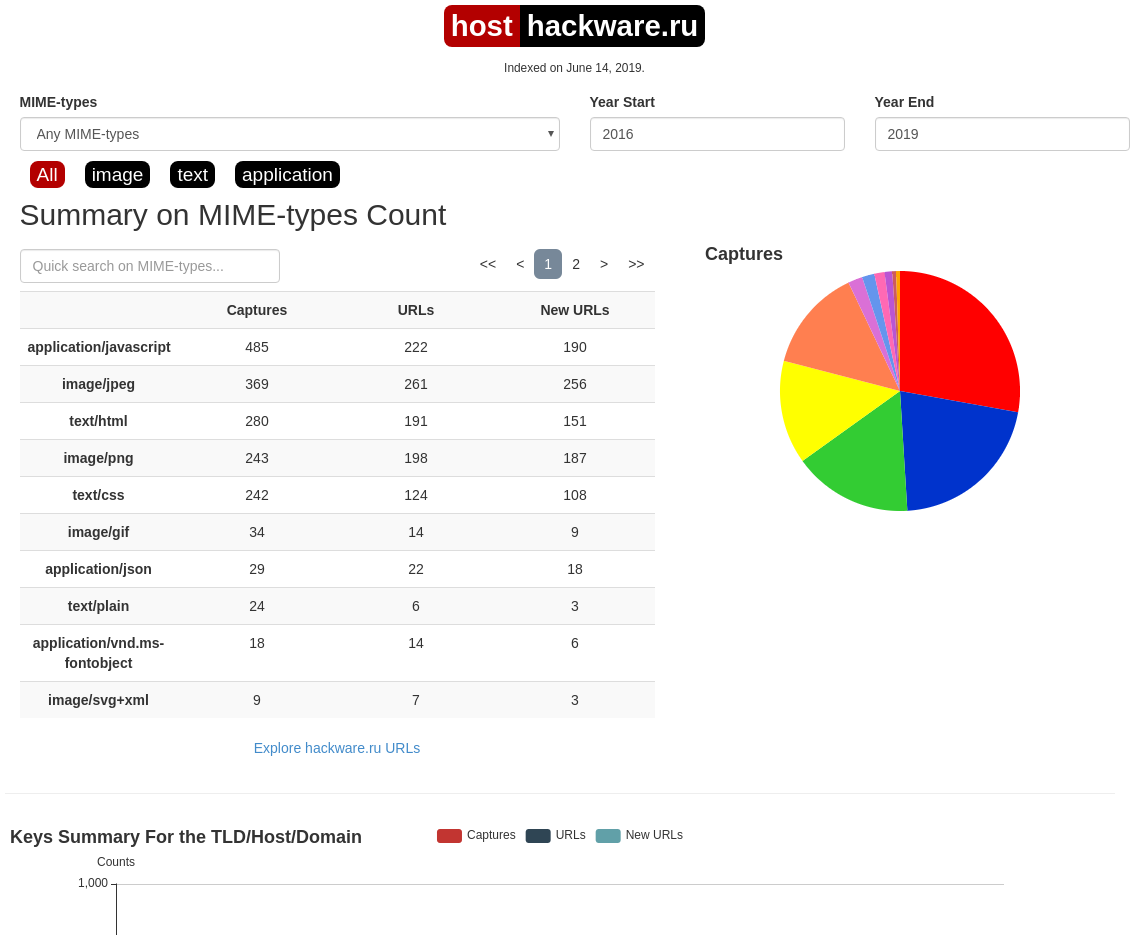
Summary
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
Данный сервис сохраняет следующие части страницы:
Не сохраняются следующие части веб-страниц:
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
Дату можно продолжить далее, указав часы, минуты и секунды:
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
Также возможно обратиться ко всем снимкам указанного URL:
Все сохранённые страницы домена:
Все сохранённые страницы всех субдоменов
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
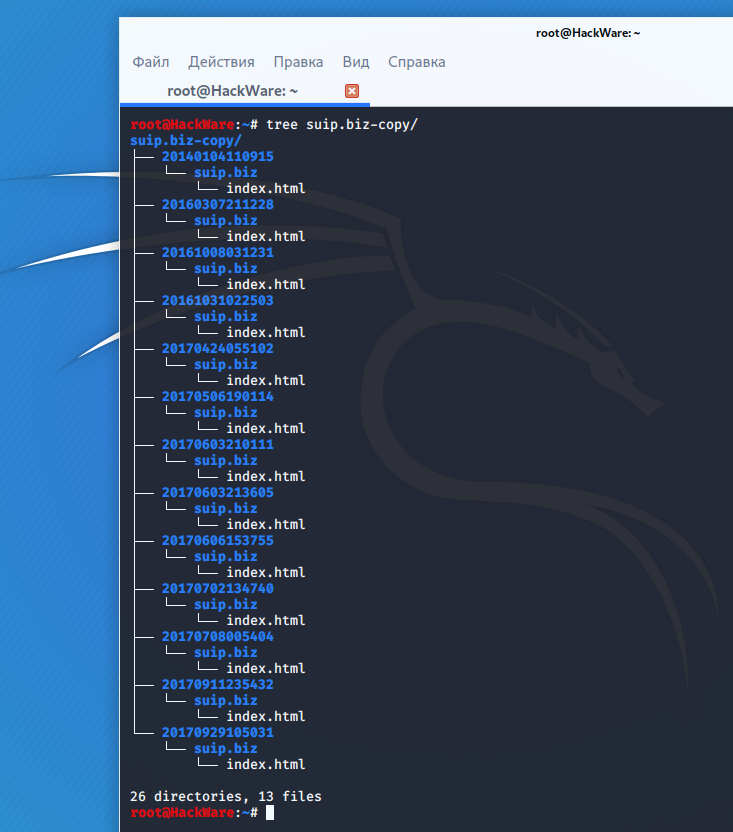
Пример скачивания полной копии сайта suip.biz из веб-архива:
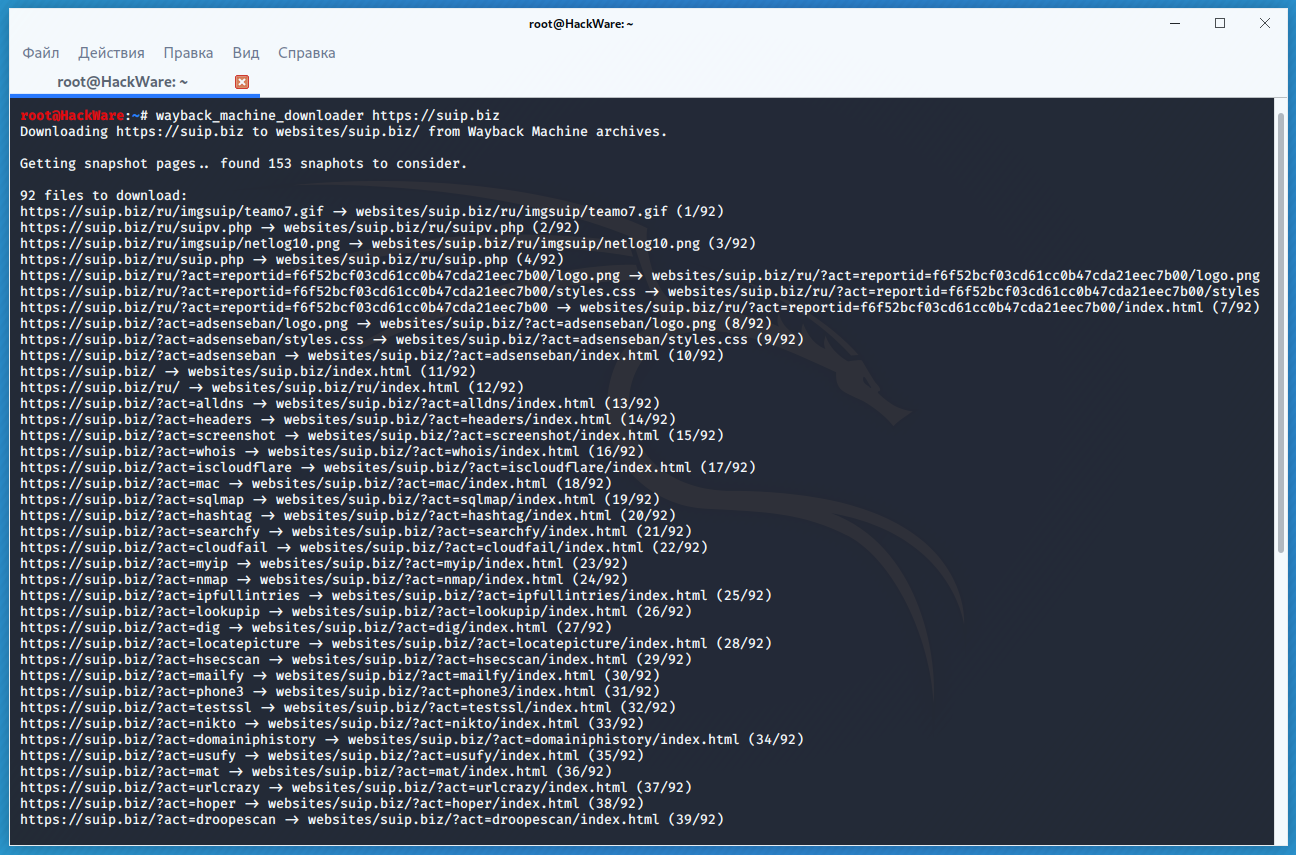
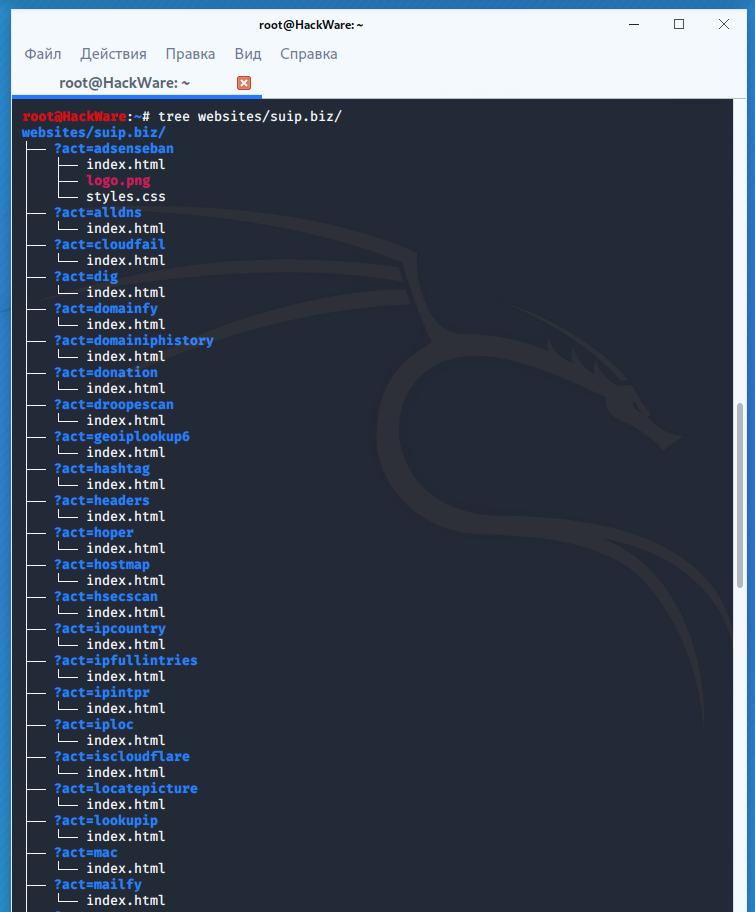
Структура скаченных файлов:
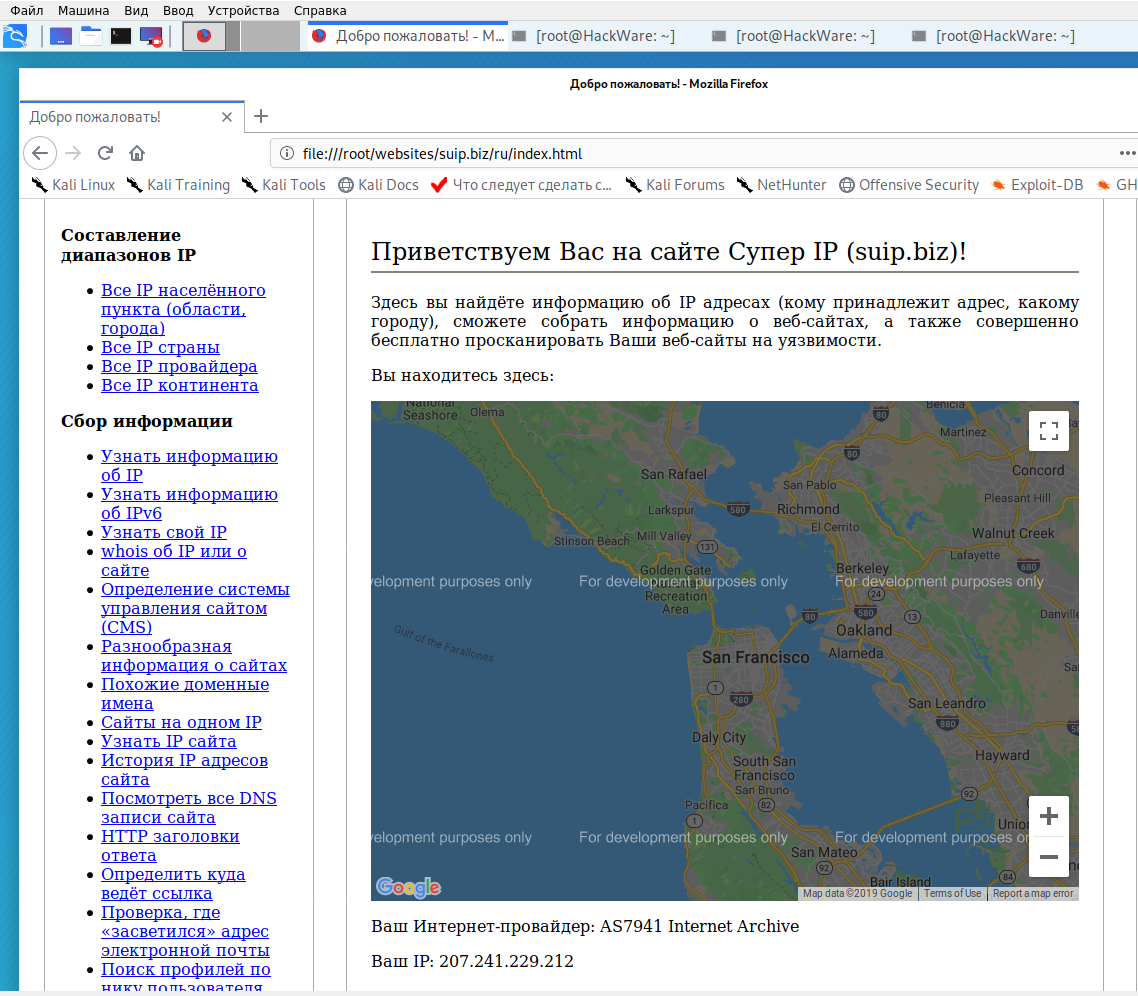
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
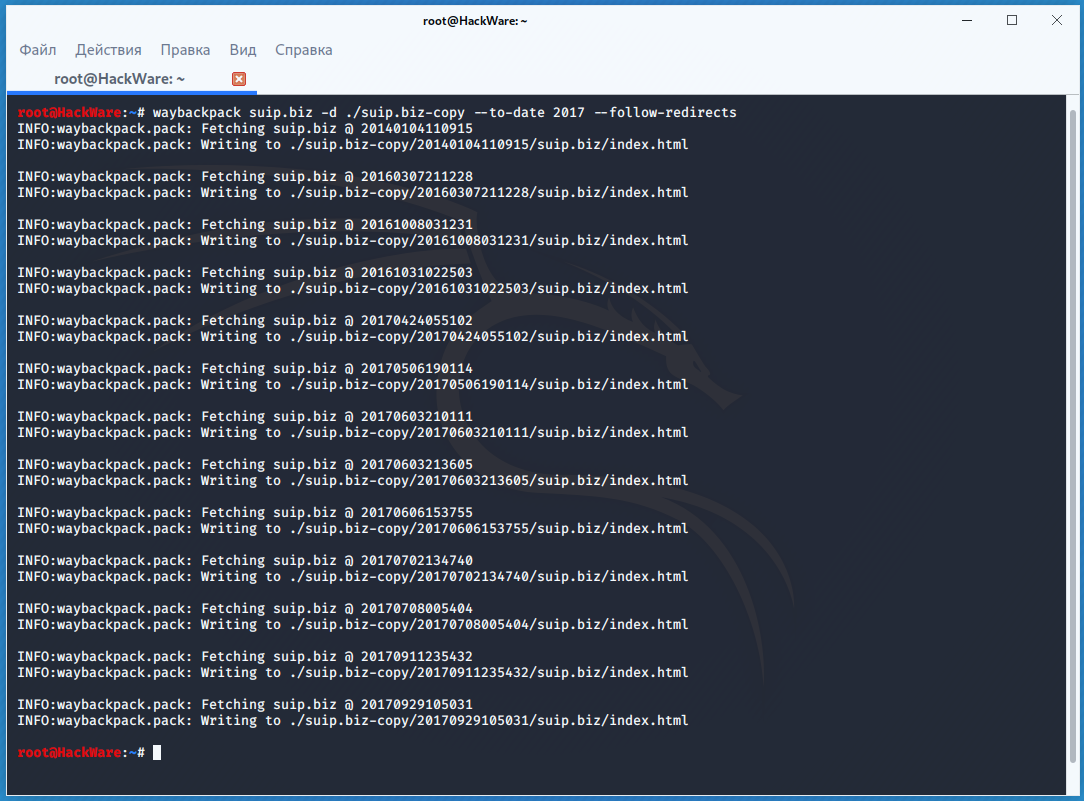
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Ещё парочка программ, которые работают с архивом интернета:
Справочная: “Архив Интернета” — история создания, миссия и дочерние проекты

Вероятно, на Хабре не так много пользователей, кто никогда не слышал об «Архиве Интернета» (Internet Archive), сервисе, который занимается поиском и сохранением важных для всего человечества цифровых данных, будь то интернет-странички, книги, видео или информация иного типа.
Кто управляет Интернет-архивом, когда он появился и какова его миссия? Об этом читайте в сегодняшней «Справочной».
Зачем вообще нужен «Архив»?
Это далеко не только развлечение. Миссия организации — всеобщий доступ ко всей информации. «Интернет-архив» стремится бороться с монополией на предоставление информации со стороны как телекоммуникационных компаний (Google, Facebook и т.п.), так и государств.
При этом «Архив» является законопослушной организацией. Если по закону США какую-то информацию необходимо удалить, организация это делает.
«Архив Интернета» также служит инструментом работы ученых, спецслужб, историков (например, археографов) и представителей многих других сфер, не говоря уже об отдельных пользователях.
Когда появился «Интернет-архив»?
Создатель «Архива» — американец Брюстер Кейл, который создал компанию Alexa Internet. Оба его сервиса стали чрезвычайно популярными, оба они процветают и сейчас.
«Интернет-архив» начал архивировать информацию с сайтов и хранить копии веб-страниц, начиная с 1996 года. Штаб-квартира этой некоммерческой организации располагается в Сан-Франциско, США.
Правда, в течение пяти лет данные были недоступны для общего доступа — данные хранились на серверах «Архива», и это все, просмотреть старые копии сайтов могла лишь администрация сервиса. С 2001 года администрация сервиса решила предоставить доступ к сохраненным данным всем желающим.
В самом начале «Интернет-архив» был лишь веб-архивом, но затем организация начала сохранять книги, аудио, движущиеся изображения, ПО. Сейчас «Интернет-архив» выступает хранилищем для фотографий и других изображений НАСА, текстов Open Library и т.п.
На что существует организация?
Как работает «Архив»?
Большинство сотрудников заняты в центрах по сканированию книг, выполняя рутинную, но достаточно трудоемкую работу. У организации три дата-центра, расположенных в Калифорнии, США. Один — в Сан-Франциско, второй — Редвуд Сити, третий — Ричмонде. Для того, чтобы избежать опасности потери данных в случае природной катастрофы или других катаклизмов, у «Архива» есть запасные мощности в Египте и Амстердаме.
«Миллионы людей потратили массу времени и усилий, чтобы разделить с другими то, что мы знаем в виде интернета. Мы хотим создать библиотеку для этой новой платформы для публикаций», — заявил основатель Архива интернета Брюстер Кале (Brewster Kahle)
Насколько велик сейчас “Архив”?
У «Интернет-архива» есть несколько подразделений, и у того, которое занимается сбором информации с сайтов, есть собственное название — Wayback Machine. На момент написания «Справочной» в архиве хранилось 339 миллиардов сохраненных веб-страниц. В 2017 году в «Архиве» хранилось 30 петабайт информации, это примерно 300 млрд веб-страниц, 12 млн книг, 4 млн аудиозаписей, 3,3 млн видеороликов, 1,5 млн фотографий и 170 тыс. различных дистрибутивов ПО. Всего за год сервис заметно «прибавил в весе», теперь «Архив» хранит 339 млрд веб-страниц, 19 млн книг, 4,5 млн видеофайлов, 4,7 млн аудиофайлов, 3,2 млн изображений разного рода, 381 тыс. дистрибутивов ПО.
Как организовано хранение данных?
Информация хранится на жестких дисках в так называемых «дата-нодах». Это серверы, каждый из которых содержит 36 жестких дисков (плюс два диска с операционными системами). Дата-ноды группируются в массивы по 10 машин и представляют собой кластерное хранилище. В 2016 году «Архив» использовал 8-терабайтными HDD, сейчас ситуация примерно такая же. Получается, что одна нода вмещает около 288 терабайт данных. В целом, еще используются жесткие диски и других размеров: 2, 3 и 4 ТБ.
В 2016 году жестких дисков было около 20 000. Дата-центры «Архива» оснащены климатическими установками для поддержания микроклимата с постоянными характеристиками. Одно кластерное хранилище из 10 нод потребляет около 5 кВт энергии.
Структура Internet Archive представляет собой виртуальную «библиотеку», которая поделена на такие секции, как книги, фильмы, музыка и т.п. Для каждого элемента есть описание, внесенное в каталог — обычно это название, имя автора и дополнительная информация. С технической точки зрения элементы структурированы и находятся в Linux-директориях.
Общий объем данных, хранимых «Архивом» составляет 22 ПБ, при этом сейчас есть место еще для 22 ПБ. «Потому, что мы параноики», — говорят представители сервиса.

Посмотрите на скриншот содержимого директории — там есть файл с названием, оканчивающимся на «_files.xml». Это каталог с информацией обо всех файлах директории.
Что будет с данными, если выйдет из строя один или несколько серверов?
Ничего страшного не произойдет — данные дублируются. Как только в библиотеке «Архива» появляется новый элемент, он тут же реплицируется и размещается на различных жестких дисках на разных серверах. Процесс «зеркалирования» контента помогает справиться с проблемами вроде отключения электричества и сбоях в файловой системе.
Если выходит из строя жесткий диск, его заменяют на новый. Благодаря зеркалируемой и редуплицируемой структуре данных новичок сразу же заполняется данными, которые находились на старом HDD, вышедшем из строя.
У «Архива» есть специализированная система, которая отслеживает состояние HDD. В день приходится заменять 6-7 вышедших из строя накопителей.
Что такое Wayback Machine?
Это лишь один из сервисов «Интернет-архива», который специализируется на сохранении веб-страниц. У сервиса есть собственный «паук», который регулярно обследует все доступные в сети сайты и сохраняет их на специализированных серверах. Чем популярнее веб-сайт, тем чаще робот копирует его содержимое. Если администратор ресурса не желает, чтобы информация сайта копировалась ботом, достаточно прописать запрет в файле robots.txt.
Популярные ресурсы копируются часто — практически ежедневно. Wayback Machine индексирует даже социальные сети, включая Twitter, Facebook
В 2017 году «Архив» запустил обновленный сервис Wayback Machine, пообещав более удобный доступ к сохраненным веб-страницам. Сервис был написан если не с нуля, то здорово переработан. Теперь он поддерживает ряд форматов файлов, которые ранее просто не сохранялись В том же 2017 году организация заявила, что каждую неделю ее сервера сохраняют около 1 млрд веб-страниц.
Так выглядел Twitter в 2007 году
Что еще можно найти в базе «Интернет-архива»?
Книги. Коллекция организации огромна, она включает оцифрованные книги, как распространенные, так и очень редкие издания. Книги сохраняются не только англоязычные, но и на многих других языках. У «Архива» есть специализированные центры по сканированию книг, всего таких центров 33, расположены они в пяти странах по всему миру.
В день сотрудники центров сканируют около 1000 книг. В базе сервиса содержатся миллионы изданий, работа по их оцифровке финансируется как обычными людьми, так и различными организациями, включая библиотеки и фонды.
С 2007 года «Интернет-архив» сохраняет в своей базе общедоступные книги из Google Book Search. После запуска, база книг быстро разрослась — в 2013 году насчитывалось уже более 900 тысяч книг, сохраненных из сервиса Google.
Один из сервисов «Архива» также предоставляет доступ к книгам, которые полностью открыты, таковых насчитывается уже более миллиона. Называется этот сервис Open Library.
Видео. Сервис хранит 4,5 млн роликов. Они разбиты по тематикам и имеют самую разную направленность. На серверах «Архива» хранятся фильмы, документальные фильмы, записи спортивных соревнований, ТВ-шоу и многие другие материалы.
В 2015 году «Архив» дал начало масштабному проекту — оцифровке видеокассет. Сначала речь шла о 40 тысячах кассет из архива Мэрион Стоукс, женщины, которая в течение многих десятилетий записывала на кассеты новости. Затем добавились и другие видеокассеты, которые присылали «Архиву» поклонники идеи оцифровки данных, важных для человечества.
Аудио. Аналогично видео, «Архив» хранит и аудиофайлы, которые также разбиты по тематикам. В прошлом году «Архив» начал реализовывать свой новый проект — расшифровку шеллачных пластинок, старейшего формата аудиозаписей. Звук сохранялся на пластинках из шеллака — природной смолы, которую выделяют самками червецов. Всего в архиве Great 78 Project несколько сотен тысяч пластинок.
Программное обеспечение. Конечно, хранить все созданное человечеством ПО просто невозможно, даже для «Архива». На серверах хранится винтаж — например, программы для Macintosh, ПО под DOS и прочий софт. В 2016 году сотрудники «Архива» выложили 1500+ программ под Windows 3.1, работать можно прямо в браузере. В 2017 Internet Archive выпустил архив софта для первых Macintosh.
Игры. Да, «Архив» предоставляет доступ к огромному количеству игр. В некоторые из них можно поиграть в среде браузерного эмулятора. Игры хранятся самые разные, в том числе, и с портативных аналогово-цифровых приставок. Есть игры под MS-DOS и консольные игры для Atari и ColecoVision.
Впервые архив старых игр организация выложила еще в 2013 году. Речь идет о тайтлах 30–40 летней давности, в которые можно было играть прямо в браузере. Это игры для приставок Atari 2600 (1977 года выпуска), Atari 7800 (1986 г.), ColecoVision (1982 г.), Philips Videopac G7000 (1978 г.) и Astrocade (1983 г.). Самое интересное, что Internet Archive добился того, что играть можно вполне легально. Сейчас коллекция насчитывает уже более 3400 игр и продолжает пополняться.
На каких серверах держится Архив Интернета?
Фото 1. Один из дата-центров Internet Archive в Сан-Франциско
Internet Archive — некоммерческая организация, которая с 1996 года сохраняет копии веб-страниц, графические материалы, видео- и аудиозаписи и программное обеспечение. Каждый может зайти в Wayback Machine и посмотреть, как выглядел Хабр в 2006 году или «Яндекс» в 1998 году, хотя загрузка архивных копий занимает около минуты (это не для реализма 90-х, а по техническим причинам, см. ниже).
Архив быстро растёт. Сейчас объём всех накопителей достиг 200 петабайт. Но Internet Archive принципиально не обращается к стороннему хостингу или облачному сервису вроде AWS. У некоммерческой организации собственные дата-центры, свои серверы и свои инженеры. Это гораздо дешевле, чем услуги AWS.
Архив Интернета против облаков
Технические подробности серверного устройства Internet Archive раскрыл Джона Эдвардс (Jonah Edwards), руководитель инженерной группы Core Infrastructure Team.
По его мнению, понятие «облако» многих людей вводит в заблуждение как нечто абстрактное. На самом деле это просто чужие компьютеры, то есть серверы посторонней компании. Для Internet Archive это неприемлемо. У организации собственные серверные в собственных зданиях, компьютеры принадлежат им, и персонал тоже свой.
Четыре дата-центра Internet Archive располагаются в Сан-Франциско, Ричмонде и Редвуд-Сити (это пригороды Сан-Франциско)
Кто-то может посчитать такой подход архаичным, но в некоторых случаях он действительно оправдан. В случае Internet Archive на то есть три причины: это дешевле, обеспечивает лучший контроль за серверами и даёт гарантию, что пользователей не отслеживают рекламные трекеры.
Инфраструктура
Что представляет собой инфраструктура, которой управляет Core Infrastructure Team? На февраль 2021 года цифры такие:
Разумеется, техника постепенно обновляется. На смену старым накопителям приходят новые. Например, маленькие диски на 2 и 3 терабайта полностью вышли из обращения в 2017 и 2018 годах, соответственно, а с прошлого года постоянно растёт доля дисков на 16 ТБ.
Как показано на графике ниже, несмотря на увеличение ёмкости накопителей, общее число HDD тоже постепенно растёт: за три года оно выросло с 15 тыс. до 20 тыс.
Количество жёстких дисков разного объёма на серверах Internet Archive
Диски реплицируются по дата-центрам, для производительности контент по запросу выдаётся одновременно со всех копий. Все элементы Архива представляют собой директории на дисках. Веб-страницы Wayback Machine хранятся в файлах WARC (Web ARChive, сжатые файлы Web Archive). При запросе отдельной страницы её нужно извлечь из середины архива WARC, а если страница требует загрузки дополнительных ресурсов, то процесс повторяется. Это одна из причин, почему полная загрузка страниц из Wayback Machine достигает 90 секунд, хотя закэшированные копии и популярный контент загружаются быстрее.

Для надёжности копии Архива хранятся не только в Сан-Франциско, но и ещё в нескольких локациях по всему миру, в том числе в Амстердаме (Нидерланды) и Новой Александрийской библиотеке (Египет).
В 1996 году первые серверы Internet Archive подняли на недорогих компьютерах из стандартных комплектующих: по сути, на обычных десктопах под Linux. Хотя инфраструктура сильно выросла, в качестве операционной системы всегда использовали только Linux. С 2004 года все серверы перешли на Ubuntu, сейчас продолжается миграция на Ubuntu 20.4 LTS (Focal Fossa).
Объём Архива
В последнее время объём Архива возрастает примерно на 25% в год, сейчас это соответствует 5−6 петабайтам в квартал. С учётом резервных копий нужно добавлять накопителей на 10−12 петабайт в квартал.
Одна копия Архива занимает более 45 петабайт, но на дисках и лентах хранится минимум две копии каждого объекта.
Как видно на графике вверху, обновление дискового массива происходит только за счёт моделей максимальной ёмкости. Например, в конце 2021 года планируется переход на диски по 20 ТБ, и тогда в серверы будут устанавливать только их. Остальные HDD постепенно доживают свой век, и их количество медленно снижается.
Internet Archive возлагает большие надежды на новые технологии записи данных, такие как HAMR (heat-assisted magnetic recording), чтобы ёмкость HDD увеличивалась ещё быстрее. Технология HAMR предусматривает предварительное нагревание магнитной поверхности лазером в процессе записи, что позволяет значительно уменьшить размеры магнитной области, хранящей один бит информации — и увеличить плотность записи. Нагрев выполняется с помощью лазера, который за 1 пс разогревает область записи до 100 °C.
Разработка этой технологии затянулась на 15 лет, но в январе 2021 года были официально представлены первые диски HAMR на 20 ТБ. Пока что они официально поставляются только избранным клиентам в рамках фирменного сервиса Seagate Lyve, но вскоре должны появиться в свободной продаже.
Seagate обещает, что HAMR позволит наращивать ёмкость HDD на 20% в год. Поэтому в ближайшее время можно ожидать модель на 24 ТБ, а в будущем — диски на 30 и 50 ТБ. Internet Archive тоже надеется на это и внимательно следит за последними разработками.
На текущем размере дисков понадобится 15 вот таких серверных стоек, чтобы разместить одну копию Архива:

У Internet Archive 750 серверов и 20 000 жёстких дисков
Сейчас в дата-центрах установлено 75 серверных стоек, что обеспечивает некоторый запас и избыточное копирование.
По состоянию на февраль 2021 года на серверах хранились копии 534 млрд веб-страниц, 16 млн аудиозаписей, 8,7 млн видеозаписей фильмов, клипов и телепередач, 3,8 млн изображений, 629 тыс. компьютерных программ, более 29 млн книг и текстов, в том числе 72 771 текстов на русском языке.
Любой пользователь может создать аккаунт и добавить в архив медиафайлы.
В 2020 году Internet Archive пережил серьёзный рост количества запросов и объёма внешнего трафика с 40 до 60 Гбит/с. Из-за пандемии коронавируса и самоизоляции ресурсы Архива стали более востребованы. Количество запросов росло так быстро, что в определённый момент маршрутизаторы Internet Archive перестали справляться с нагрузкой, пришлось делать апгрейд сетевой инфраструктуры быстрее, чем планировалось. Сейчас веб-сайт входит в топ-300 крупнейших сайтов интернета.
Работа на собственных серверах имеет и свои недостатки. Основные причины сбоев Internet Archive — обрывы оптоволокна из-за строительных работ в городе, сбои энергоснабжения, случайные провалы напряжения в сети. Впрочем, прошлый год сайт завершил с аптаймом 99,9%.
Internet Archive планирует расширять внешний канал. Ожидается, что в ближайшее время внешний трафик вырастет до 80 Гбит/с.
Примерно так выглядит дизайн внутренней сети:
Дата-центры подключены к нескольким провайдерам первого уровня (Tier 1) и соединены между собой по оптоволокну с применением технологии плотного спектрального уплотнения (DWDM). Локальные университетские сети подключаются к этому кольцу напрямую через локальные точки обмена трафиком.
Вместо нынешнего оптоволокна планируется проложить пары 100-гигабитных кабелей по всему кольцу из четырёх дата-центров, так что внешний трафик тоже можно будет увеличить до 100 Гбит/с.
Прокладка новых кабелей по Сан-Франциско — весьма хлопотное и дорогое дело. Приходится перекладывать асфальт на автомобильных дорогах и тротуарах. К счастью, Internet Archive удалось получить официальный статус библиотеки, что даёт доступ к государственным субсидиям, в том числе к бюджету Федеральной комиссии по связи США (FCC) на подключение всех библиотек к интернету. Таким образом, львиную долю расходов на прокладку, обслуживание оптоволокна и трафик оплачивает FCC по программе E-Rate Universal Service Program.
С 2005 года Internet Archive начал проект Open Library по сканированию книг. С одной стороны, это действительно важный общественный проект. С другой стороны, он позволил получить государственные льготы и финансирование в качестве публичной библиотеки.
Кроме государственных грантов и пожертвований, организация оказывает платные услуги по сканированию книг, в основном, для других библиотек и университетов. Это ещё один источник финансирования.
Планы на будущее
Инженеры Internet Archive сейчас обдумывают варианты использования SSD и GPU в основных серверах, чтобы увеличить их производительность. Главная проблема здесь в том, что все дата-центры находятся в стеснённых городских условиях Сан-Франциско и пригородов с очень ограниченными возможностями охлаждения (см. фото 1). Так что каждый апгрейд требуется хорошо обдумать: не приведёт ли он к повышению температуры.
Интересно наблюдать за ростом инфраструктуры Internet Archive с увеличением количества серверных стоек. Есть подозрение, что рано или поздно наступит момент, когда сложность поддержания своей инфраструктуры превысит некий порог — и библиотека откажется от собственных дата-центров. Но пока что инженеры Core Infrastructure Team успешно справляются с работой.
В зависимости от методологии расчёта, хранение данных в собственных дата-центрах Internet Archive обходятся в 2−5 раз дешевле, чем в облаке. И это только хранение. Сложно даже посчитать, сколько будет стоить круглосуточный исходящий трафик 60 Гбит/с на AWS. Вероятно, он обойдётся даже дороже, чем хранение 200 петабайт.
Похоже, что некоторые сервисы просто «слишком велики» для облака. Компаниям приходится поднимать собственные дата-центры, потому что у них нет выхода. Другой вопрос: должна ли библиотека заниматься этим самостоятельно? Получается, что современная цифровая библиотека — это по сути хостинг-провайдер и дата-центр?
На правах рекламы
Эпичные серверы — это надёжные VDS на Linux или Windows с мощными процессорами семейства AMD EPYC и очень быстрой файловой системой, используем исключительно NVMe диски от Intel. Попробуйте как можно быстрее!