Vsphere ha virtual machine failover failed что делать
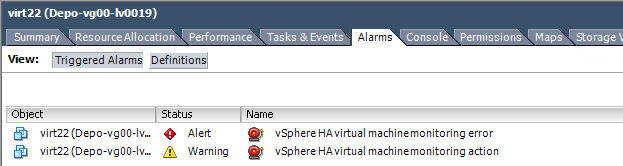
Ошибка vsphere ha virtual machine monitoring error
Всем привет сегодня расскажу, как решается и из-за чего выскакивает ошибка vsphere ha virtual machine monitoring error и vsphere ha virtual machine monitoring action. Данная ошибка вполне может перезагрузить виртуальную машину, нештатно завершив все рабочие процессы, ладно если это случиться в вечернее время, с минимальными последствиями для клиентов, а если в самый час пик, это очень сильно ударит по репутации компании и может повлечь денежные убытки.
Вот более наглядное представление этих ошибок в VMware vCenter 5.5.
Ошибка vsphere ha virtual machine monitoring error-02
Видим сначала идет предупреждение и потом alert
vsphere ha virtual machine monitoring action
Анализ log файла
Сначала нужно проанализировать лог файл виртуальной машины, для этого щелкаем правым кликом по datastore и выбираем browse datastore
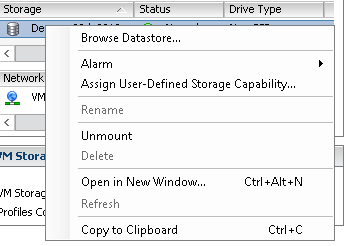
browse datastore vmware
Переходим в нужную папку виртуальной машины и находим там файл vmware.log
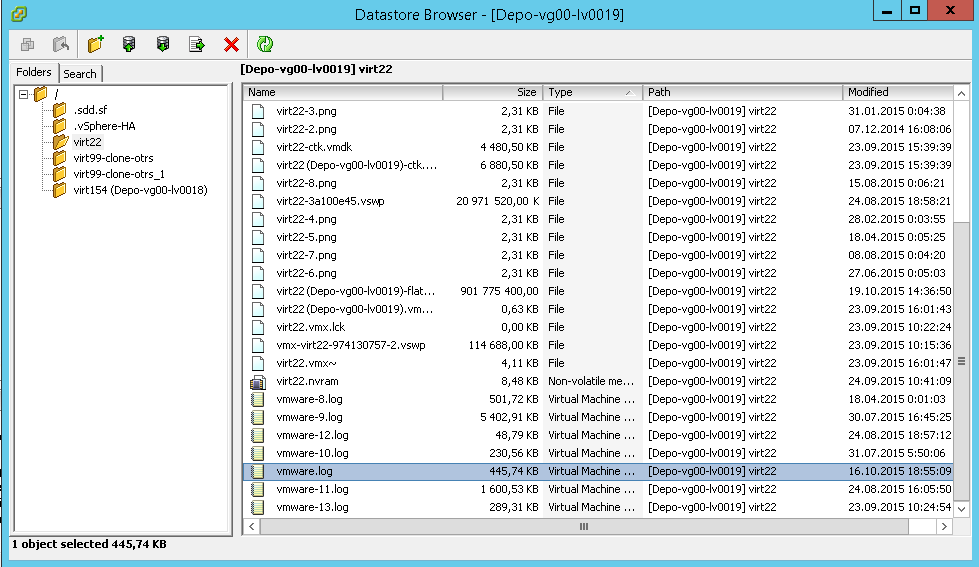
Этот файл vmware.log, нам нужно скачать, сделать это можно к сожалению только на выключенной виртуальной машине, щелкаем по нему правым кликом и выбираем Download
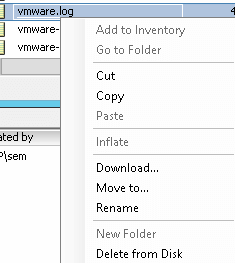
скачиваем лог файл
Указываем место куда нужно закачать ваш файл, для дальнейшего изучения. Все ошибки в данном файле в большинстве случаев сводятся к необходимости обновить vmware tools
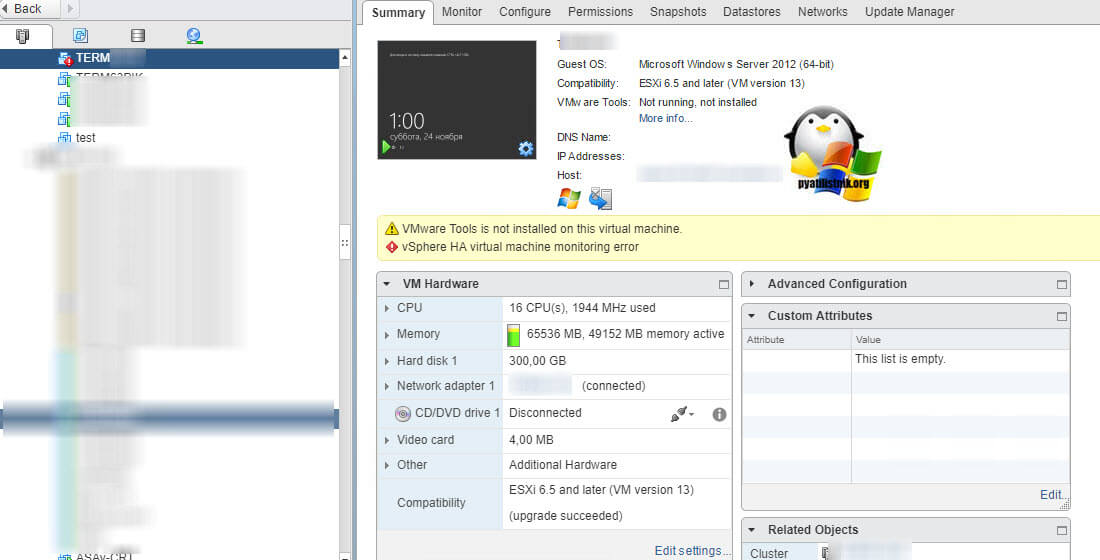
То же самое вы можете увидеть и на Vmware ESXI 6.5. (VMware Tools is not installed on this virtual machine)
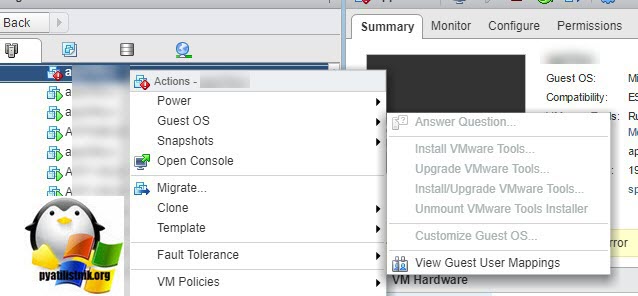
Обновление vmware tools
Напомню vmware tools это пакет драйверов который устанавливается внутри виртуальной машины для лучшей интеграции и расширения функционала. Как обновить vmware tools в VMware ESXI 5.5 я рассказывал ранее. Еще отмечу, что вначале вам придется удалить Vmware Tools из гостевой операционной системы, так как смонтировать диск с дистрибутивом для обновления вы не сможете, так как поле будет не активно.
Так же если вы будите медлить с решением данной проблемы, вы будите постоянно ловить синий экран с кодом 0x00000050. При его анализе он будет ругаться на драйвера.
vSphere HA virtual machine failed to failover error on VMs in a partitioned cluster
I received two questions this week around partition scenarios where after the failure has been lifted some VMs display the error message “vSphere HA virtual machine failed to failover”. The question that then arises is: why did HA try to restart it, and why did it fail? Well, first of all, this is an error that in most cases you can safely ignore. There’s a KB on the topic which gives a bit of detail to be found here, but let me explain also in a bit more depth.
In a partitioning scenario, each partition will have its own primary node. If there is no form of communication (datastore/network) possible, what the HA primary will do is it will list all the VMs that are currently not running within that partition. It will also want to try to restart those VMs. A partition is extremely uncommon in normal environments but may happen in a stretched cluster. In a stretched cluster when a partition happens a datastore only belongs to 1 location. The VMs which appear to be missing typically are running in the other location, as typically the other location will have access to that particular datastore. Although the primary has listed these VMs as “missing and need to restart” it will not be able to do this. Why? It doesn’t have access to the datastore itself, or when it has access to the datastore the files are locked as the VMs are still running. As a result, this will, unfortunately, be reported as a failed failover. Even though the VM was still running and there was no need for a failover. So if you hit this during certain failure scenarios, and the VMs were running as you expected, you can safely ignore this error.
Share it:
Related
Primary Sidebar
About the author
Duncan Epping is a Chief Technologist in the Office of CTO of the Cloud Platform BU at VMware. He is a VCDX (# 007), the author of the «vSAN Deep Dive» and the “vSphere Clustering Technical Deep Dive” series, and he is the host of the «In de aap gelogeerd» (Dutch) and «unexplored territory» (English) podcasts.
Vsphere ha virtual machine failover failed что делать

There are 3 ESX hosts in our cluster. One of them (say Host3) just exit Maintenance Mode.
Then we change the DRS setting to aggressive and run HA reconfigure on the other two ESX hosts (Let us call them Host1 and Host2). We just want to migrate VM to the ESX host that just exit from maintenance mode.

It doesn’t sound like HA should have kicked in at all in your circumstance as long as there were no unplanned host outtages. Do you have VM Monitoring enabled in your cluster HA settings? You’ll definitely want to check the logs for evidence as to why this is happening.
Ensure each of your hosts can ping their isolation address, usually the default gateway of the management network. If you have VM Monitoring enabled, ensure VMware Tools is running in the VMs that had the error. You can also disable HA on the cluster and wait for the AAM agent to be uninstalled from each host, then re-enable HA.
If you don’t want to disable HA cluster-wide, you can also remove individual hosts from vCenter. This will also uninstall the AAM agent. Once it’s removed, re-add it to vCenter and the HA-enabled cluster. This will then re-install the HA agent.
Without looking at the logs, it’s difficult to say exactly what caused your problem. Feel free to attach your log files here for the community to peruse.
Виртуализация vSphere, Hyper-V, Xen и Red Hat
Более 5540 заметок о виртуализации, виртуальных машинах VMware, Microsoft и Xen, а также Kubernetes
Диагностика неполадок VMware High Availability (HA) в VMware vSphere.
Диагностика неполадок VMware High Availability (HA) в VMware vSphere.
Автор: Александр Самойленко
Дата: 05/04/2011
Механизм VMware High Availability (HA) в VMware vSphere позволяет автоматически перезапустить виртуальные машины отказавшего сервера в кластере с общего хранилища в случае сбоя. При настройке кластера VMware HA можно использовать несколько расширенных настроек (HA Advanced Settings), которые позволяют настроить его работу наиболее гибко.
Если в процессе настройки кластера VMware HA вы сталкиваетесь с проблемами, вам может помочь информация, приведенная ниже. Для начала, какие симптомы бывают у проблем, которые можно решить, следуя советам данной заметки:
1. Ошибки при настройке VMware High Availability (HA):
HA agent on in cluster in has an error
Insufficient resources to satisfy HA failover level on cluster
2. Ошибки при конфигурации агента HA на хостах ESX / ESXi:
Failed to connect to host
Failed to install the VirtualCenter agent
cmd addnode failed for primary node:/opt/vmware/aam/bin/ft_startup failed
Configuration of hosts IP address is inconsistent on host address resolved to and
Ports not freed after stop_ftbb
5. Первый узел кластера VMware HA настраивается корректно, но второй узел выдает ошибку на 90%
6. Сетевые настройки кластера HA настроены корректно, DNS работает и все пинги проходят нормально.
7. vSphere Client или VI Client выдают ошибку:
8. В логах aam на сервере VMware ESX в файле aam_config_util_addnode.log отображаются похожие строчки:
11/27/09 16:20:49 [myexit ] Failure location:
11/27/09 16:20:49 [myexit ] function main::myexit called from line 2199
11/27/09 16:20:49 [myexit ] function main::start_agent called from line 1168
11/27/09 16:20:49 [myexit ] function main::add_aam_node called from line 171
11/27/09 16:20:49 [myexit ] VMwareresult=failure
9. Добавление хоста в кластер вызывает ошибку в vSphere Client:
Cannot complete the configuration of the HA agent on the host. Other HA configuration error.
Алгоритм решения проблем
HA использует следующие порты на хост-серверах:
Incoming port: TCP/UDP 8042-8045
Outgoing port: TCP/UDP 2050-2250

Вебинары VMC о виртуализации:
Постер VMware vSphere PowerCLI 6.3: 
Постер VMware ESXi 5.1: 
Постер VMware Hands-on Labs 2015: 
Постер VMware Platform Services Controller 6.0: 
Постер VMware vCloud Networking: 
Постер VMware NSX (референсный): 
Постер VMware vCloud SDK: 
Постер VMware vCloud Suite: 
Постер VMware vCenter Server Appliance: 
Порты и соединения VMware vSphere 6:
Порты и соединения VMware Horizon 7: 
Порты и соединения VMware NSX: 
Управление памятью в VMware vSphere 5:
Как работает кластер VMware High Availability: 
Постер VMware vSphere 5.5 ESXTOP (обзорный): 
Постер Veeam Backup & Replication v8 for VMware: 
Постер Microsoft Windows Server 2012 Hyper-V R2: 
vSphere HA VMs Fail to Failover
Here’s a case that vSphere HA VMs fail to failover.
Symptom
1. In a cluster with isolation response set to Leave powered on, when a host becomes isolated, the following alarm may be displayed on a VM:
vSphere HA virtual machine failed to failover.
2. VMs are operating properly.
Fault Diagnosis
As long as the HA primary proxy claims that the host crashes, this problem persists.
At the same time, VMs run properly.
This alarm does not indicate that HA has failed and stopped working.
Possible causes of the problem are:
1. The host is still running but has been disconnected from the network.
The cluster’s host isolation response is set to Leave powered on.
2. The host is still running but has been disconnected from the network.
The cluster’s host isolation response is set to Shut down or Power off.
3. The host stops running and VM storage is in degraded status.
If other hosts in the cluster cannot connect to the storage nor power on VMs, an alarm is triggered.
Solution
This problem is expected to happen in VMware vCenter Server 5.0 x, 5.1 x, and 5.5 x, and has no impact on VM running.
To clear this alarm from the VMs, perform the following:
1. Select the VM that has triggered the alarm.
2. Click the Alarms tab. On the tab page, click Triggered Alarms.
3. Right-click the alarm of vSphere HA switchover failure and clear the alarm.
If this alarm exists on multiple VMs, select host, cluster, data center, or vCenter object in the left window and performs step 2. This can simplify alarm clearing.
To avoid this problem, try the following operations:
1. Deploy multiple management networks.
For details, see http://www.vmware.com/files/pdf/techpaper/vmw-vsphere-high-availability.pdf.
2. Ensure that when a management network problem occurs, datastores in vCenter Server detects that signals are communicating properly so that HA can function effectively.
For example, if SAN and IP-based storage is used, mount SAN-based datastores to hosts in the cluster so that HA can replace IP-based storage with these datastores.
Or, if only IP-based storage is used, isolate the storage networks from management network in case of fault occurrence.
This is my solution, how about yours? Go ahead and share it with us!