Визуализация данных с использованием matplotlib и seaborn на Python
В этой статье мы разберем, что такое визуализация данных и как ее можно использовать для создания графиков с использованием matplotlib и seaborn в Python. Мы также поговорим о различных типах анализа наряду с наиболее распространенными типами графиков, используемых при визуализации данных.
Что такое визуализация данных?
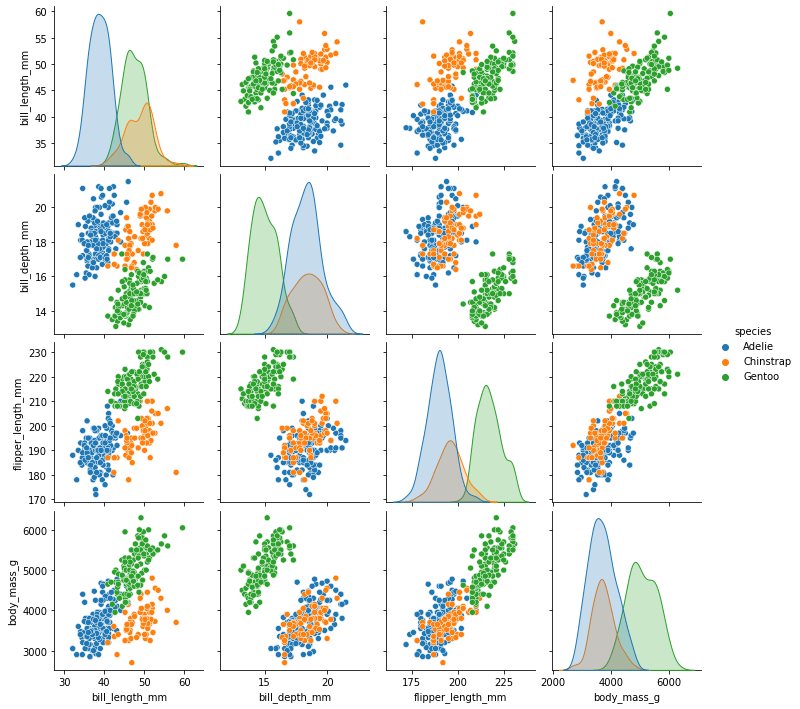
Мы будем реализовывать различные методы визуализации данных в наборе данных ‘iris’.
Различные виды анализа:
Наиболее распространенные типы графиков, используемых при визуализации данных:
Давайте посмотрим на некоторые из этих графиков, используемых при визуализации данных:
Импорт библиотек для визуализации данных
Загрузить файл в dataframe
Scatter, Точечный график
Это один из наиболее часто используемых графиков для простой визуализации данных. Он дает нам представление о том, где присутствуют каждая точка во всем наборе данных относительно любых 2 или 3 объектов (или столбцов). Они доступны как в 2D, так и в 3D.

Pair plot, Парный график
Допустим, у нас есть n объектов в наших данных. Парный график поможет нам создать фигуру (nxn ), где диагональные графики будут гистограммами объектов, соответствующих этой строке, а остальные графики представляют собой комбинацию объектов, — каждая строка по оси y и элемент из каждого столбца по оси x.
Фрагмент кода для парного графика, реализованного в наборе данных Iris:

Box plot, Ящик с усами, диаграмма размаха
Код для построения объектов с использованием Box plots:

Violin plot, Скрипичный график
Скрипичный график тоже из seaborn. Код прост и выглядит следующим образом.

Joint plot, Гибридный график
Есть различные опции которые вы можете выбрать и настроить с использованием параметра kind функции jointplot в seaborn:

Line plot, Strip plot, Линейный график
Линейный график может быть использован сам по себе, но он также является хорошим дополнением к ящику с усами или скрипичному графику в тех случаях, когда вы хотите показать весь анализ вместе с некоторым представлением основного распределения.
Это метод анализа графических данных для суммирования одномерного набора данных. Обычно он используется для небольших наборов данных.

Функция lmplot ( ) в seaborn
Lmplot от Seaborn — это двумерная диаграмма рассеяния с дополнительной наложенной линией регрессии. Логистическая регрессия для двоичной классификации также поддерживается с помощью lmplot. Он предназначен в качестве удобного интерфейса для подгонки регрессионных моделей к условным подмножествам набора данных.
Функция может нарисовать диаграмму рассеяния двух переменных, x и y затем подогнать регрессионную модель y
x и построить результирующую линию регрессии с 95% доверительным интервалом для этой регрессии.
lmplot ( ) имеет data в качестве требуемого параметра и x и y переменные должны быть заданы как строки.

Заключение:
Визуализация данных не только помогает вам лучше анализировать ваши данные, но всякий раз, когда вы обнаруживаете какие-либо идеи, вы можете использовать эти методы, чтобы поделиться своими результатами с другими людьми в простой и интуитивно понятной форме.
Seaborn для визуализации данных в Python
Seaborn — библиотека для создания статистических графиков на Python. Она построена на основе matplotlib и тесно интегрируется со структурами данных pandas. Seaborn помогает вам изучить и понять данные. Его функции построения графиков работают с датасетами и выполняют все необходимы преобразования для создания информативных графиков.
Синтаксис, ориентированный на набор данных, позволяет сосредоточиться на графиках, а не деталях их построения.
Установка seaborn
Официальные релизы seaborn можно установить из PyPI:
Библиотека также входит в состав дистрибутива Anaconda:
Библиотека работает с Python версии 3.6+. Если их еще нет, эти библиотеки будут загружены при установке seaborn: numpy, scipy, pandas, matplotlib.
Как только вы установите Seaborn, можете скачать и построить тестовый график для одного из встроенных датасетов:
Выполнив этот код в Jupyter Notebook, увидите такой график.
Если вы не работаете с Jupyter, может потребоваться явный вызов matplotlib.pyplot.show() :
Давайте более детально рассмотрим построение популярных типов графиков.
Весь дальнейший код будет выполняться в Jupyter Notebook
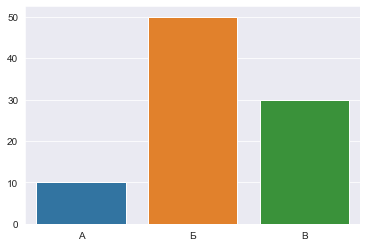
Построение Bar Plot в Seaborn
Гистограммы отображают числовые величины на одной оси и переменные категории на другой. Они позволяют вам увидеть, значения параметров для каждой категории.
Гистограммы можно использовать для визуализации временных рядов, а также только категориальных данных.
Построение гистограммы
В результате получается четкая и простая гистограмма:
Чаще всего вы будете работать с датасетами, которые содержат гораздо больше данных, чем тот что приведен в примере. Иногда к этим наборам данным требуется сортировка, или подсчитать, сколько раз повторяются то или другое значение.
Когда вы работаете с данными можете столкнуться с ошибками и пропусками, которые в них имеются. К счастью, Seaborn защищает нас и автоматически применяет фильтр, который основан на вычислении среднего значения предоставленных данных.
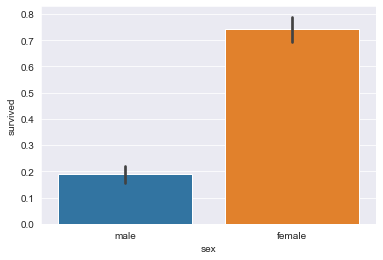
Давайте импортируем классический датасет Titanic и визуализируем Bar Plot с этими данными:
Если мы выведем первые строки датасета ( titanic_dataset.head() ), увидим такую таблицу:
Наконец, мы используем эти данные и передаем их в качестве аргумента функции, с которой работаем. И получаем такой результат:
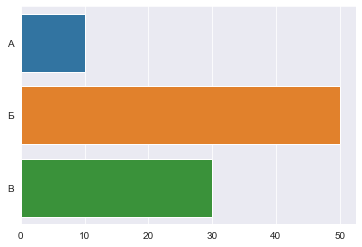
Построение горизонтальной гистограммы
В этом случае категориальная переменная будет отображаться по оси Y, что приведет к постройке горизонтального графика:
График будет выглядеть так:
Как изменить цвет в barplot()
Изменить цвет столбцов довольно просто. Для этого нужно задать параметр color функции barplot и тогда цвет всех столбцов изменится на заданный.
Изменим на голубой:
Тогда график будет выглядеть так:
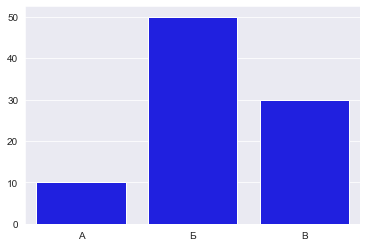
Что приведет к такому результату:
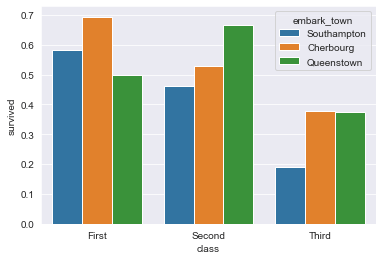
Группировка Bar Plot в Seaborn
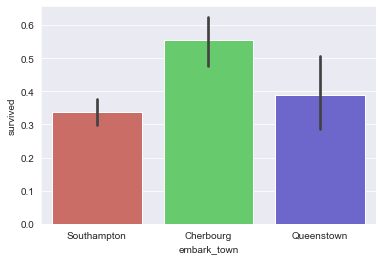
Часто требуется сгруппировать столбцы на графиках по одному признаку. Допустим, вы хотите сравнить некоторые общие данные, выживаемость пассажиров, и сгруппировать их по заданным критериям.
Нам может потребоваться визуализировать количество выживших пассажиров, в зависимости от класса (первый, второй и третий), но также учесть, города из которого они прибыли.
Всю эту информацию можно легко отобразить на гистограмме.
Давайте посмотрим на только что обсужденный пример:
Получим такой график:
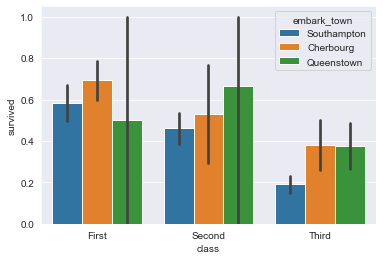
Настройка порядка отображения групп столбцов на гистограмме
Например, до сих пор он упорядочивал классы с первого по третий. Что, если мы захотим сделать наоборот?
Получится такой график:
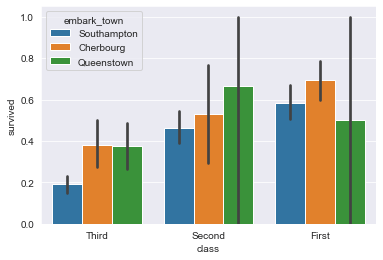
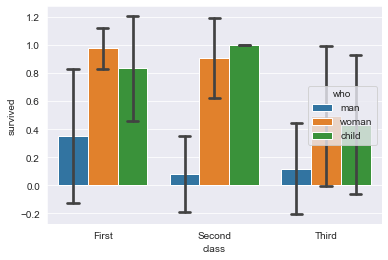
Изменяем доверительный интервал в barplot()
Давайте немного поэкспериментируем с атрибутом доверительного интервала:
Получим такой результат:
Или мы можем использовать стандартное отклонение:
Мы рассмотрели несколько способов построения гистограммы в Seaborn на примерах. Теперь перейдем к тепловым картам.
Построение Heatmap в Seaborn
Давайте посмотрим, как мы можем работать с библиотекой Seaborn на Python, чтобы создать базовую тепловую карту корреляции.
Для наших целей мы будем использовать набор данных о жилье Ames, доступный на Kaggle.com. Он содержит более 30 показателей, которые потенциально могут повлиять на стоимость недвижимости.
Поскольку Seaborn была написана на основе библиотеки визуализации данных Matplotlib, их довольно просто использовать вместе. Поэтому помимо стандартных модулей мы также собираемся импортировать Matplotlib.pyplot.
Следующий код создает матрицу корреляции между всеми исследуемыми показателями и нашей переменной y (стоимость недвижимости).
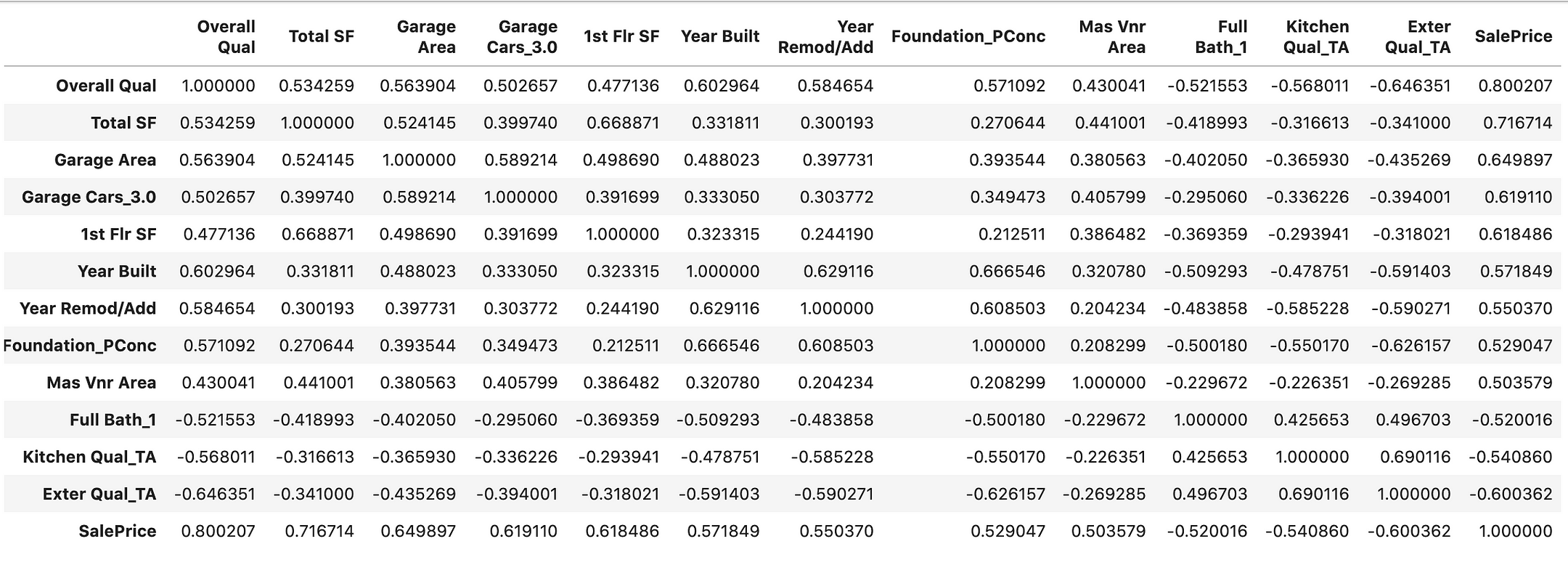
Корреляционная матрица всего с 13 переменными. Нельзя сказать, что она совсем не читабельна. Однако почему бы не облегчить себе жизнь визуализацией?
Простая тепловая карта в Seaborn
Seaborn прост в использовании, но в нем довольно сложно ориентироваться. Библиотека поставляется с множеством встроенных функций и обширной документацией. Может быть трудно понять, какие именно аргументы использовать, если вам не нужны все возможные навороты.
Давайте сделаем базовую тепловую карту более полезной с минимальными усилиями.
Взгляните на список аргументов heatmap :
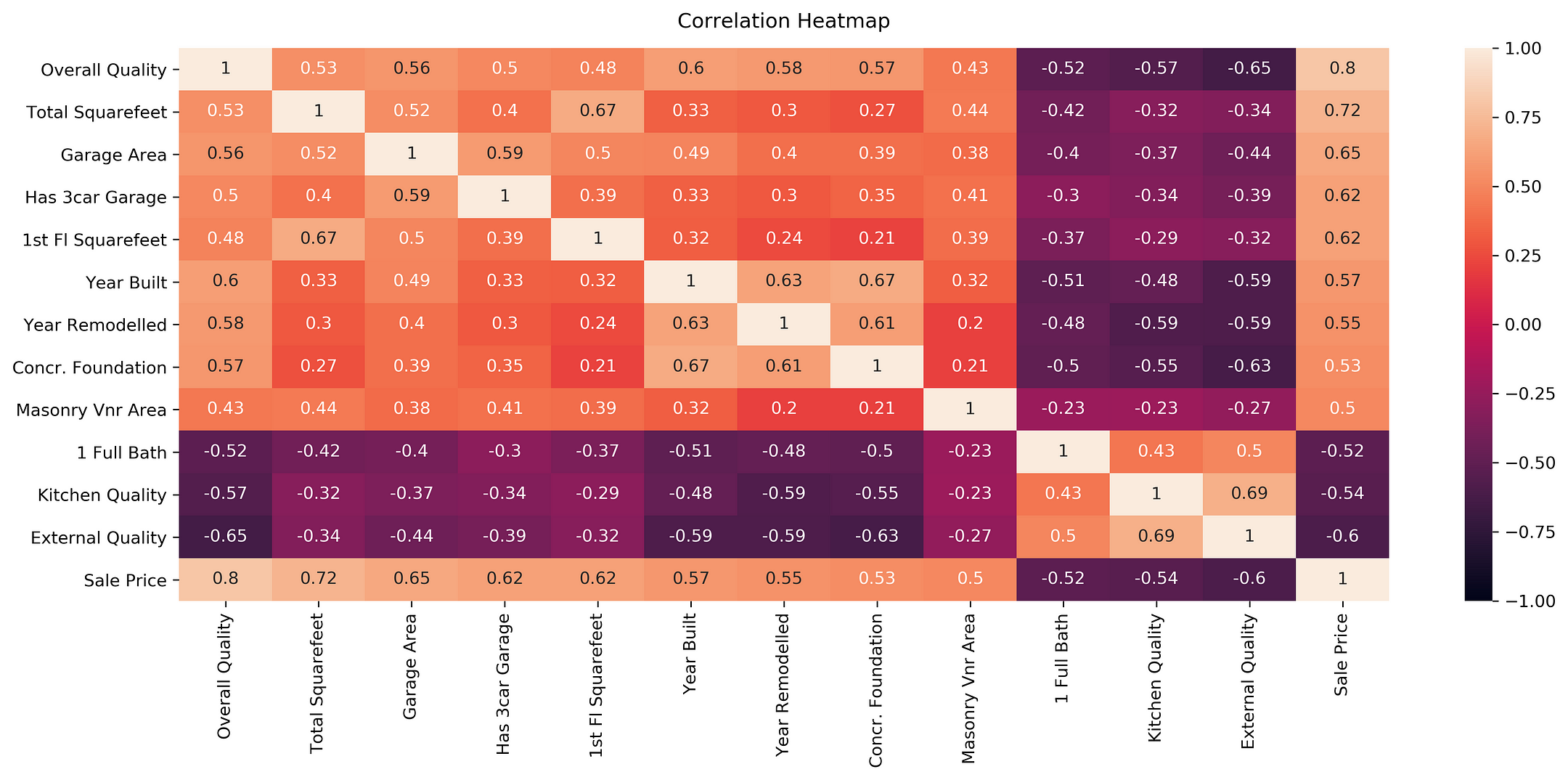
Для работы с heatmap лучше всего подходит расходящаяся цветовая палитра. Она имеет два очень разных темных (насыщенных) цвета на соответствующих концах диапазона интерполированных значений с бледной, почти бесцветной средней точкой. Проиллюстрируем это утверждение и разберемся с еще одной небольшой деталью: как сохранить созданную тепловую карту в файл png со всеми необходимыми x и y метками ( xticklabels и yticklabels ).
Треугольная тепловая карта корреляции
Взгляните на любую из приведенных выше тепловых карт. Если вы отбросите одну из ее половин по диагонали, обозначенной единицами, вы не потеряете никакой информации. Итак, давайте сократим тепловую карту, оставив только нижний треугольник.
Давайте воспользуемся функцией np.triu() библиотеки numpy, чтобы изолировать верхний треугольник матрицы, превращая все значения в нижнем треугольнике в 0. np.tril() будет делать то же самое, только для нижнего треугольника. В свою очередь функция np.ones_like() изменит все изолированные значения на 1.
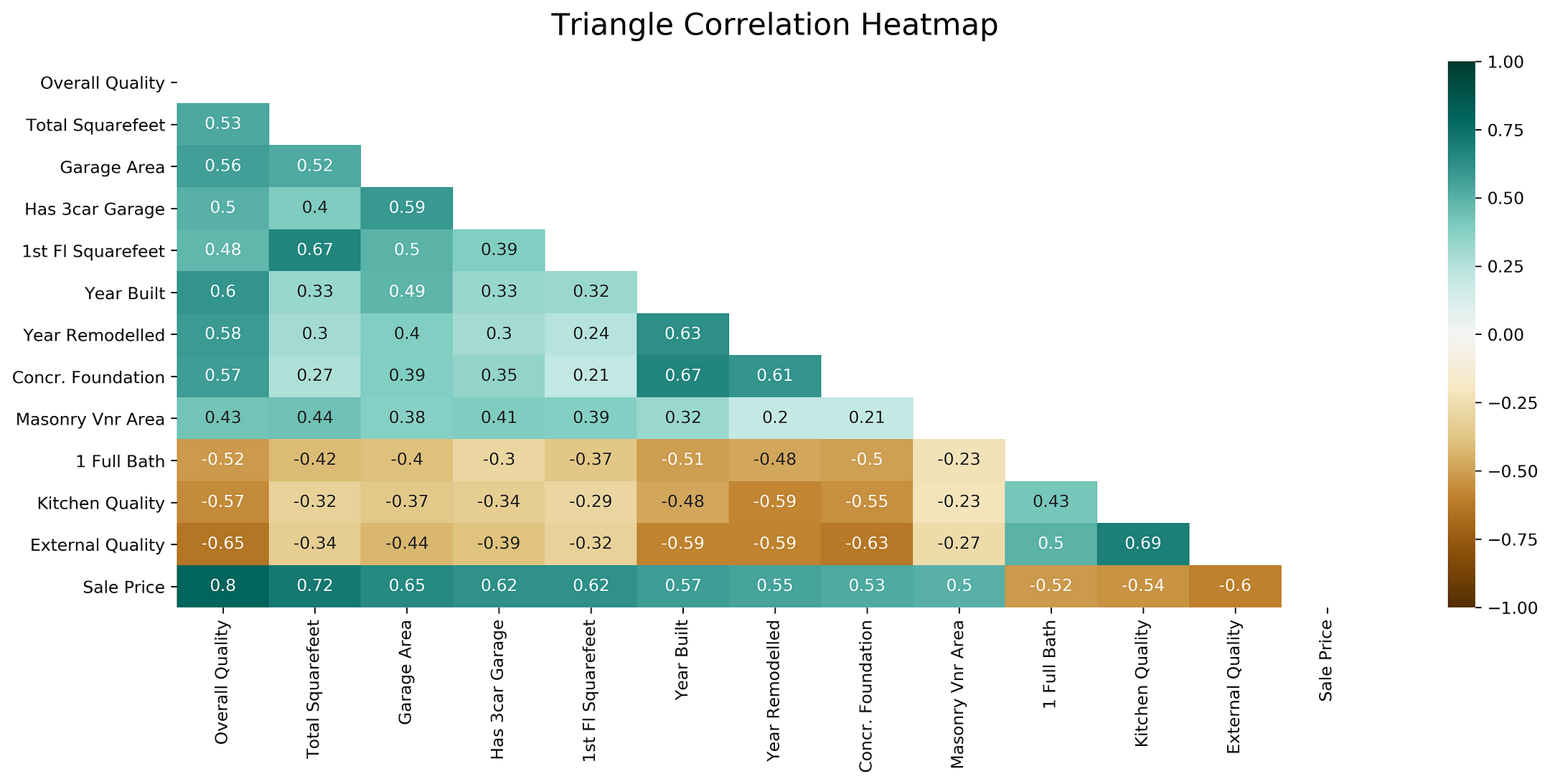
Корреляция независимых переменных с зависимой
Довольно часто мы хотим создать цветную карту, которая показывает выраженность связи между каждой независимой переменной, включенной в нашу модель, и зависимой переменной.
Следующий код возвращает корреляцию каждого параметра с «ценой продажи», единственной зависимой переменной в порядке убывания.
Давайте используем полученный список в качестве данных для отображения на тепловой карте.
Эти примеры демонстрируют основную функциональность heatmap в Seaborn. Теперь перейдем к точечным диаграммам.
Построение Scatter Plot в Seaborn
Давайте рассмотрим процесс создания точечной диаграммы в Seaborn. Построим простые и трехмерные диаграммы рассеивания, а также групповые графики на базе FacetGrid.
Импорт данных
Мы будем использовать набор данных, основанный на мировом счастье. Сравнение его индекса с другими показателям отразит факторы, влияющие на уровень счастья в мире.
Построение точечной диаграммы
На графике отразим соотношение индекса счастья к экономике страны (ВВП на душу населения):
Оси диаграммы по умолчанию подписываются именами столбцов, которые соответствуют заголовкам из загружаемого файла. Ниже мы рассмотрим, как это изменить.
После выполнения кода мы получим следующее:
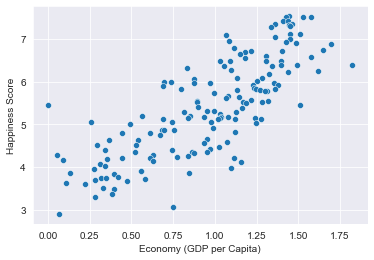
Результат показал прямую зависимость между ВВП на душу населения и предполагаемого уровня счастья жителей конкретной страны или региона.
Построение группы графиков scatterplot при помощи FacetGrid
Если требуется сравнить много переменных друг с другом, например, среднюю продолжительность жизни наряду с оценкой счастья и уровнем экономики, нет необходимости строить 3D-график.
Несмотря на существование двумерных диаграмм, позволяющих визуализировать соотношение между множествами переменных, не все из них просты в применении.
Взглянем на следующий пример:
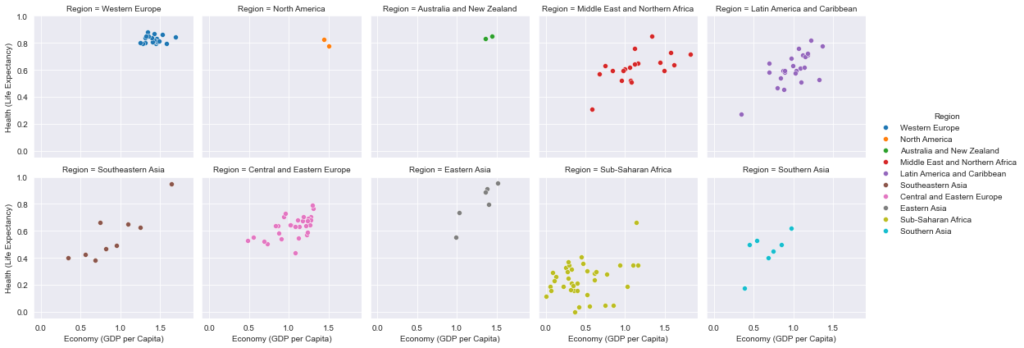
В этом примере мы создали экземпляр объекта FacetGrid с параметром dataframe в качестве данных. При передаче значения «Region» аргументу col библиотека сгруппирует датасет по регионам и построит диаграмму рассеивания для каждого из них.
Параметр hue задает каждому региону собственный оттенок. Наконец, при помощи аргумента col_wrap ширина области Figure ограничивается до 5-ти диаграмм. По достижении этого предела следующие графики будут построены на новой строке.
В результате будет сформировано 10 графиков по каждому региону с соответствующими им осями. Непосредственно перед печатью мы вызываем метод, добавляющий легенду с обозначением цветовой маркировки.
Построение 3D-диаграммы рассеивания
К сожалению, в Seaborn отсутствует собственный 3D-движок. Являясь лишь дополнением к Matplotlib, он опирается на графические возможности основной библиотеки. Тем не менее, мы все еще можем применить стиль Seaborn к трехмерной диаграмме.
Посмотрим, как она будет выглядеть с выборкой по уровням счастья, экономики и здоровья:
Открытый курс машинного обучения. Тема 2: Визуализация данных c Python

Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE. Есть и видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
UPD: теперь курс — на английском языке под брендом mlcourse.ai со статьями на Medium, а материалами — на Kaggle (Dataset) и на GitHub.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!
План этой статьи
Демонстрация основных методов Seaborn и Plotly
В начале как всегда настроим окружение: импортируем все необходимые библиотеки и немного настроим дефолтное отображение картинок.
После этого загрузим в DataFrame данные, с которыми будем работать. Для примеров я выбрала данные о продажах и оценках видео-игр из Kaggle Datasets.
Seaborn
Познакомимся с первым таким «сложным» типом графиков pair plot ( scatter plot matrix ). Эта визуализация поможет нам посмотреть на одной картинке, как связаны между собой различные признаки.
Как можно видеть, на диагонали матрицы графиков расположены гистограммы распределений признака. Остальные же графики — это обычные scatter plots для соответствующих пар признаков.
Для понимания лучше один раз увидеть, поэтому вот еще и картинка с Wikipedia:
Plotly
Прелесть интерактивных графиков заключается в том, что можно посмотреть точное численное значение при наведении мыши, скрыть неинтересные ряды в визуализации, приблизить определенный участок графика и т.д.
Для начала построим line plot с динамикой числа вышедших игр и их продаж по годам.
Параметр show_link отвечает за ссылки на online-платформу plot.ly на графиках. Поскольку обычно это функциональность не нужна, то я предпочитаю скрывать ее для предотвращения случайных нажатий.
Можно сразу сохранить график в виде html-файла.
С помощью plotly можно построить и другие типы визуализаций. Графики получаются достаточно симпатичными с дефолтными настройками. Однако библиотека позволяет и гибко настраивать различные параметры визуализации: цвета, шрифты, подписи, аннотации и многое другое.
Пример визуального анализа данных
Считываем в DataFrame знакомые нам по первой статье данные по оттоку клиентов телеком-оператора.
Проверим, все ли нормально считалось – посмотрим на первые 5 строк (метод head ).
Число строк (клиентов) и столбцов (признаков):
Посмотрим на признаки и убедимся, что пропусков ни в одном из них нет – везде по 3333 записи.
| Название | Описание | Тип |
|---|---|---|
| State | Буквенный код штата | категориальный |
| Account length | Как долго клиент обслуживается компанией | количественный |
| Area code | Префикс номера телефона | количественный |
| International plan | Международный роуминг (подключен/не подключен) | бинарный |
| Voice mail plan | Голосовая почта (подключена/не подключена) | бинарный |
| Number vmail messages | Количество голосовых сообщений | количественный |
| Total day minutes | Общая длительность разговоров днем | количественный |
| Total day calls | Общее количество звонков днем | количественный |
| Total day charge | Общая сумма оплаты за услуги днем | количественный |
| Total eve minutes | Общая длительность разговоров вечером | количественный |
| Total eve calls | Общее количество звонков вечером | количественный |
| Total eve charge | Общая сумма оплаты за услуги вечером | количественный |
| Total night minutes | Общая длительность разговоров ночью | количественный |
| Total night calls | Общее количество звонков ночью | количественный |
| Total night charge | Общая сумма оплаты за услуги ночью | количественный |
| Total intl minutes | Общая длительность международных разговоров | количественный |
| Total intl calls | Общее количество международных разговоров | количественный |
| Total intl charge | Общая сумма оплаты за международные разговоры | количественный |
| Customer service calls | Число обращений в сервисный центр | количественный |
Целевая переменная: Churn – Признак оттока, бинарный (1 – потеря клиента, то есть отток). Потом мы будем строить модели, прогнозирующие этот признак по остальным, поэтому мы и назвали его целевым.
Посмотрим на распределение целевого класса – оттока клиентов.
Выделим следующие группы признаков (среди всех кроме Churn ):
Посмотрим на корреляции количественных признаков. По раскрашенной матрице корреляций видно, что такие признаки как Total day charge считаются по проговоренным минутам (Total day minutes). То есть 4 признака можно выкинуть, они не несут полезной информации.
Теперь посмотрим на распределения всех интересующих нас количественных признаков. На бинарные/категориальные/порядковые признакие будем смотреть отдельно.
Видим, что большинство признаков распределены нормально. Исключения – число звонков в сервисный центр (Customer service calls) (тут больше подходит пуассоновское распределение) и число голосовых сообщений (Number vmail messages, пик в нуле, т.е. это те, у кого голосовая почта не подключена). Также смещено распределение числа международных звонков (Total intl calls).
Еще полезно строить вот такие картинки, где на главной диагонали рисуются распределения признаков, а вне главной диагонали – диаграммы рассеяния для пар признаков. Бывает, что это приводит к каким-то выводам, но в данном случае все примерно понятно, без сюрпризов.
Дальше посмотрим, как признаки связаны с целевым – с оттоком.
Построим boxplot-ы, описывающее статистики распределения количественных признаков в двух группах: среди лояльных и ушедших клиентов.
На глаз наибольшее отличие мы видим для признаков Total day minutes, Customer service calls и Number vmail messages. Впоследствии мы научимся определять важность признаков в задаче классификации с помощью случайного леса (или градиентного бустинга), и окажется, что первые два – действительно очень важные признаки для прогнозирования оттока.
Посмотрим отдельно на картинки с распределением кол-ва проговоренных днем минут среди лояльных/ушедших. Слева — знакомые нам боксплоты, справа – сглаженные гистограммы распределения числового признака в двух группах (скорее просто красивая картинка, все и так понятно по боксплоту).
Интересное наблюдение: в среднем ушедшие клиенты больше пользуются связью. Возможно, они недовольны тарифами, и одной из мер борьбы с оттоком будет понижение тарифных ставок (стоимости мобильной связи). Но это уже компании надо будет проводить дополнительный экономический анализ, действительно ли такие меры будут оправданы.
Теперь посмотрим на связь бинарных признаков International plan и Voice mail plan с оттоком. Наблюдение: когда роуминг подключен, доля оттока намного выше, т.е. наличие международного роуминга – сильный признак. Про голосовую почту такого нельзя сказать.
Наконец, посмотрим, как с оттоком связан категориальный признак State. С ним уже не так приятно работать, поскольку число уникальных штатов довольно велико – 51. Можно в начале построить сводную табличку или посчитать процент оттока для каждого штата. Но данных по каждом штату по отдельности маловато (ушедших клиентов всего от 3 до 17 в каждом штате), поэтому, возможно, признак State впоследствии не стоит добавлять в модели классификации из-за риска переобучения (но мы это будем проверять на кросс-валидации, stay tuned!).
Доли оттока для каждого штата:
Видно, что в Нью-Джерси и Калифорнии доля оттока выше 25%, а на Гавайях и в Аляске меньше 5%. Но эти выводы построены на слишком скромной статистике и возможно, это просто особенности имеющихся данных (тут можно и гипотезы попроверять про корреляции Мэтьюса и Крамера, но это уже за рамками данной статьи).
Подглядывание в n-мерное пространство с t-SNE
Построим t-SNE представление все тех же данных по оттоку. Название метода сложное – t-distributed Stohastic Neighbor Embedding, математика тоже крутая (и вникать в нее не будем, но для желающих – вот оригинальная статья Д. Хинтона и его аспиранта в JMLR), но основная идея проста, как дверь: найдем такое отображение из многомерного признакового пространства на плоскость (или в 3D, но почти всегда выбирают 2D), чтоб точки, которые были далеко друг от друга, на плоскости тоже оказались удаленными, а близкие точки – также отобразились на близкие. То есть neighbor embedding – это своего рода поиск нового представления данных, при котором сохраняется соседство.
Раскрасим полученное t-SNE представление данных по оттоку (синие – лояльные, оранжевые – ушедшие клиенты).
Видим, что ушедшие клиенты преимущественно «кучкуются» в некоторых областях признакового пространства.
Чтоб лучше понять картинку, можно также раскрасить ее по остальным бинарным признакам – по роумингу и голосовой почте. Синие участки соответствуют объектам, обладающим этим бинарным признаком.
Теперь понятно, что, например, много ушедших клиентов кучкуется в левом кластере людей с поключенным роумингом, но без голосовой почты.
Напоследок отметим минусы t-SNE (да, по нему тоже лучше писать отдельную статью):
И еще пара картинок. С помощью t-SNE можно действительно получить хорошее представление о данных (как в случае с рукописными цифрами, вот хорошая статья), а можно просто нарисовать елочную игрушку.
Домашнее задание № 2
Актуальные домашние задания объявляются во время очередной сессии курса, следить можно в группе ВК и в репозитории курса.
В качестве закрепления материала предлагаем выполнить это задание – провести визуальный анализ данных о публикациях на Хабрахабре. Проверить себя можно отправив ответы в веб-форме (там же найдете и решение).
Обзор полезных ресурсов
Статья написана в соавторстве с yorko (Юрием Кашницким).