Splunk – Установка агентов для сбора логов Windows и Linux
Нам часто задают вопросы о том, как загрузить различные данные в Splunk. Одними из самых распространенных источников, представляющих интерес, оказались логи Windows и Linux, которые позволяют отслеживать неполадки операционных систем и управлять ими. Загружая данные в Splunk, Вы можете анализировать работу всех систем в одном месте, даже когда у Вас десятки или сотни различных источников.

В данной статье мы пошагово объясним Вам, как загрузить данные из Windows и Linux в Splunk, для последующей обработки и анализа.
Настройка базовой инфраструктуры
Для того, чтобы начать собирать данные нам необходимы следующие элементы системы:
Для того, чтобы загружать логи в Splunk, необходимо сначала предварительно настроить индексер, для этого потребуется:
В первую очередь, вам понадобится Splunk на машине, которая является нашим индексером. Если у вас нет установленного Splunk, то прочитать подробнее, как и на какие системы можно поставить его вы можете прочитать тут.
Это приложение необходимо для того, упростить управление источниками данных, когда этих источников много или доступ к ним для внесения изменений затруднителен. Также приложение позволит вам не совершать потенциально ошибочные изменения конфигурации на многих хостах, ограничивая изменением только на одном месте.
Создаем приложение: Apps — Manage Apps — Add New
После создания приложения, необходимо сформировать конфигурационный файл оutputs.conf (Подробнее об том файле Вы можете прочитать на официальном сайте Splunk)
В текстовом редакторе введите следующий текст, заменив indexer_hostname_or_ip_address именем хоста или IP-адресом индексера и получающим портом, установленным на предыдущем шаге:
Сохраните как outputs.conf и добавьте в папку \etc\apps\sendtoindexer\local (Папку local необходимо создать).
На этом этапе мы заканчиваем предварительную настройки индексера и переходим к установке агентов на машины Windows и Linux.
WINDOWS
Универсальным инструментом для загрузки логов является специальный агент – Splunk Universal Forwarder. Universal Forwarder представляет собой версию Splunk Enterprise с существенно ограниченным функционалом, единственной задачей которого является сбор данных с хоста и отправка их.
Скачать его можно по этой ссылке.
На картинке выше видно, что Universal Forwarder можно установить как на Windows, так и на Linux, Solaris и другие операционные системы.
1. Устанавливаем Universal Forwarder
В качестве Deployment Server указываем IP-адрес или название Splunk индексера, где мы создали приложение «Send to indexer». Порт по умолчанию: 8089. Раздел Receiving Indexer оставим пустым, так как эти функции выполнит «Send to indexer».
2. Следующий шагом нам необходимо вернуться к Splunk и определить класс сервера для приложения «Send to indexer».
Класс сервера что-то похожее на правило, в котором мы указываем какие приложения мы будем распределять между какими целевыми машинами-клиентами. Критериями для формирования разных классов сервера могут стать тип машины, ОС, географическая область или тип приложения, причем классы могут пересекаться между собой. (Более подробно можно прочитать на официальном сайте)
Settings — Forwarder Management — edit action — add new classes.
3. После сохранения вам будет предложено добавить приложения, которые мы будем рассылать и целевые системы, так называемые клиенты, которым мы будем их рассылать.
Добавляем «Send to indexer» в раздел приложений.
4. Затем добавляем клиента. Клиентом будет наша машина с Windows, на которую мы установили Universal Forwarder. Если Universal Forwarder был установлен правильно, то машина должна появиться в списке клиентов, подключенных к Deployment Server. Заносим ее в Include (whitelist).
5. Проверить правильно ли все работает можно, посмотрев на содержимое индекса _internal. После добавления «Send to indexer» в класс сервера Universal Forwarder начинает отправлять свои внутренние логи туда. Также в этом индексе далее мы можем следить за тем, правильно ли работают наши агенты.
6. Далее скачиваем специальный Add-on с сайта SplunkBase, который позволяет собирать данные о работе Windows.
7. Устанавливаем приложение на Splunk-Indexer ( Apps — Manage Apps — Install app from file)
По умолчанию оно устанавливается в каталог . \Splunk\etc\apps\Splunk_TA_windows, но нам необходимо скопировать его в папку deployment-apps, чтобы это приложение было доступно для deployment server, чтобы потом мы могли отправить его на другие машины также, как и «Send to indexer». (Важно: в папке apps оно также должно остаться, чтобы на индексере сформировались нужные нам индексы для данных).
8. Затем необходимо сделать преднастройку приложения.
Переходим в каталог . \Splunk\etc\deployment-apps\Splunk_TA_windows
Создаем в нем под-каталог «local» (Важно: Вносить изменения в конфигурационные файлы необходимо всегда в каталоге local).
Включим индексацию требуемых данных. Для этого в файле inputs.conf из каталога local через текстовый редактор делаем некоторые изменения. Заменим значения disabled=1 на disabled=0 в необходимых блоках файла. Давайте добавим логи системы по Application, Security, System.
9. Далее, на Splunk-indexer, добавляем к приложению созданный ранее сервер-класс. (Settings — Forwarder Management — Apps — Splunk_TA_Windows – «+» — Windows Forwarder)
10. Перезагрузим deployment server, это можно сделать через командную строку из каталога … /splunk/bin:
Проверям, загружаются ли данные. (Settings – Indexes ) Они должны попадать в индекс wineventlog. Как видно на нашем рисунке последние данные, которые были загружены на данный момент имеют временную метку 3 минуты назад.
LINUX
Одним из инструментов, позволяющих повысить уровень безопасности в Linux, является подсистема аудита auditd. C её помощью можно получить подробную информацию обо всех системных событиях. Именно данные, генерируемые этой системой мы будем индексировать в Splunk.
(Код будет представлен для Linux CentOS)
1. Проверим, если ли на машине предустановленная система аудита, если нет установим ее.
Добавим новое правило, которое мы будем отслеживать.
Проверить его наличие можно с помощью функции.
Логи, генерируемые auditd попадают в файл:
2. Далее, установим Universal Forwarder. Найти дистрибутив можно по ссылке.
3. Далее на создадим нового пользователя, который будет отвечать за работу со splunk.
4. Дадим разрешения пользовалелю, которого мы только что создали и запустим UniversalForwarder от его имени.
5. Проведем настройку форвардера и укажем Deployment Server, также как в части с Windows, это IP-адрес или имя Splunk-indexer/
6. Можно проверить, работает ли форвардер, следующим образом:
7. Далее переходим в Splunk-indexer и устанавливаем на него специальный Add-on, позволяющий передавать логи с Linux. Скачать дистрибутив можно по ссылке.
8. После установки, находим папку с приложением по следующему адресу ../splunk/etc/apps/Splunk_TA_nix. Копируем папку Splunk_TA_nix из apps в deployment-apps. Чтобы это приложение появилось как доступное для deployment server.
В файл …/ deployment-apps/Splunk_TA_nix/ local/ input.conf через текстовый редактор вносим изменения, которые покажут данные из каких папок мы хотим собирать. В нашем случае это /var/log/audit.
В input.conf есть раздел [monitor:///var/log], в котором необходимо изменить disabled=1 на disabled=0 (Важно: убедитесь, что необходимая папка есть в whitelist, если ее нет, но нужно ее добавить)
9. Далее проверим, увидел ли Deployment server нового клиента, нашу машину Linux. (Settings — Forwarder Management – Clients).
Если ее нет, то необходимо проверить название (Host name) машины, если он совпадает с названием машины индексера, то необходимо его изменить, иначе возникает ошибка.
10. Затем создаем новый сервер класс, относящийся к Linux.
Settings — Forwarder Management – Server Classes — New Server Class
11. Добавляем в этот класс приложения «Send to indexer» и «Splunk_TA_nix», а в качестве клиента добавляет машину Linux.
Обратите внимание, что файлы не будут загружаться, если у Universal Forwarder (у юзера, под которым мы используем Universal Forwarder) нет доступа к папкам, которые необходимо мониторить. Так что необходимо учесть этот момент и разрешить доступ.
12. В конце необходимо перезагрузить deployment server, это можно сделать через командную строку из каталога … /splunk/bin :
После проведения выше описанных операций, Вы получите логи Linux, которые будут загружены в индекс OS.
Заключение
Таким образом, мы показали вам, как загрузить ваши логи из Windows и Linux в Splunk для дальнейшего анализа и обработки. Надеемся, что эта информация будет полезна для Вас.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Splunk — общее описание платформы, базовые особенности установки и архитектуры
В рамках корпоративного блога компании TS Solution мы начинаем серию обучающих статей про такой продукт для анализа машинных данных как Splunk. Большинство статей будут представлять собой «how to tutorial», описание интересных кейсов и решение популярных проблем.
В данной статье мы кратко расскажем о самой системе и её назначении, а также рассмотрим варианты по её установке. 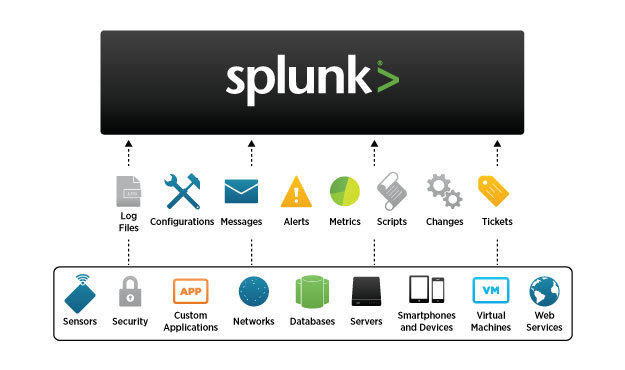
Пару слов про Splunk
Splunk это платформа для сбора, хранения, обработки и анализа машинных данных, то есть логов. На сегодняшний день является крайне популярной в США и в Европе и постепенно выходит на другие рынки, включая Россию. Одной из главных особенностей платформы является то, что она может работать с данными практически из любых источников, и поэтому список возможных применений системы очень широк.
Splunk, в большинстве случаев, (автоматически или с помощью аддонов) разбирает входные данные на поля и значения и в последствии обрабатывает их. Обработка происходит посредством SPL запросов (специальный язык от Splunk), с помощью которого можно строить различные выборки и таблицы, сортировать, фильтровать, агрегировать, строить отчеты, создавать вычисляемые поля, обращаться как к внутренним, так и внешним справочникам, создавать дашборды, с широким спектром визуализации и делать алерты (например по результату выполнения запроса отправлять тикеты в Service Desk). Все это можно упаковать в свое персональное приложение.
Основные отличия или сильные стороны Splunk
Почему это важно? Потому что Splunk может обеспечить сбор данных в реальном времени из тысяч разнородных источников — и это может быть как физический или виртуальный хост, так и облако. Также Splunk поддерживает поиск не только в реальном времени, но и по всему временному промежутку, данные за который были собраны. То есть мы можем осуществлять поиск, мониторинг, оповещения, отчетность и анализ за любое время (исторический данные и данные в реальном времени в одном решении). И наконец, Splunk обеспечивает быстрый результат и высокую интерактивность поисковых запросов на чрезвычайно больших объемах данных.
Где скачать?
Бесплатная версия Splunk c ограничением на индексацию в 500 Мб в день доступна на официальном сайте компании, единственное что вам нужно сделать это пройти регистрацию.
Системные требования
Splunk поддерживает как 32-bit, так и 64-bit разрядную архитектуру. Ниже представлены таблицы с доступными платформами для Splunk отдельно для Unix и Microsoft. В последнем столбце таблицы находится информация о Splunk Universal Forwarder. Это отдельный дистрибутив и отдельная роль в платформе Splunk, которая выступает в качестве агента и отвечает исключительно за сбор логов и пересылку их на сервер.
Unix
А – версия доступна для скачивания, но не имеет официальной поддержки
D – версия в данный момент поддерживается, но в будущих релизах компания может снять ее с официальной поддержки
Windows
D – версия в данный момент поддерживается, но в будущих релизах компания может снять ее с официальной поддержки
… — версия поддерживается, но Splunk не рекомендует использовать данную архитектуру
Установка
После того как вы скачали установочный файл просто запускайте установку и по умолчанию система встанет в базовой конфигурации. Подробная пошаговая инструкция по установке на Windows здесь, на Unix системы здесь.
После установки Splunk должен быть доступен через веб интерфейс порт 8000: localhost:8000 и после смены пароля и входа вы увидите следующий интерфейс.

На этом мы закончим вводный обзор. В следующей статье мы расскажем как загрузить данные в Splunk, как пользоваться языком SPL, как строить графики и дашборды.
Также, мы недавно делали вебекс общего характера про Splunk — его запись вы можете посмотреть по ссылке на Youtube. В этом вебинаре был показан базовый функционал и рассказаны некоторые кейсы применения продукта.
Splunk Universal Forwarder в докере как сборщик системных логов
Splunk является одним из нескольких наиболее узнаваемых коммерческих продуктов для сбора и анализа логов. Даже сейчас, когда продажи в России больше не производятся, это не повод не писать инструкции/how-to по этому продукту.
Задача: собирать системные логи с docker нод в Splunk не меняя конфигурацию хост-машины
Начать хотелось бы с официального подхода, который выглядит странноватым при использовании докера.
Ссылка на Docker hub
Что же мы имеем:
2. Стартуем контейнер с нужными параметрами
3. Заходим в контейнер
Далее нас просят пройти по известному адресу в документацию.
И конфигурировать контейнер после его запуска:
Но на этом сюрпризы не заканчиваются. Если вы запустите контейнер из официального образа в интерактивном режиме, то увидите следующее:
Отлично. В образе даже нет артефакта. То есть, каждый раз при запуске будет тратиться время, чтобы выкачать архив с бинарниками, распаковать и настроить.
А как же docker-way и всё такое?
Нет, спасибо. Мы пойдём другим путём. Что, если все эти операции мы выполним на этапе сборки? Тогда поехали!
Чтобы долго не тянуть, покажу сразу итоговый образ:
И так, что же содержится в
При первом старте, Splunk просит задать ему логин/пароль, НО эти данные используются только для выполнения административных команд этой конкретной инсталляции, то есть, внутри контейнера. В нашем случае же, мы просто хотим запустить контейнер, чтобы всё работало и логи лились рекой. Конечно, это хардкод, но других способов я не нашёл.
Дальше по сценарию выполняется
splunkclouduf.spl — Это файл креды для Splunk Universal Forwarder, которые можно загрузить из веб интерфейса.
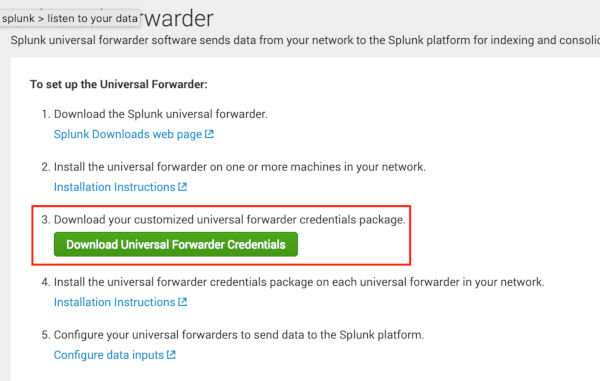
Это обычный архив, который можно распаковать. Внутри — сертификаты и пароль для подключения к нашему SplunkCloud и outputs.conf со списком наших input инстансов. Этот файл будет актуален до тех пор, пока вы не переустановите свою инсталляцию Splunk или не добавите input нод, если инсталляция on-premise. Поэтому ничего страшного нет в том, чтобы добавить его внутрь контейнера.
И последнее — restart. Да, для применения изменений, нужно его рестартануть.
В наш inputs.conf добавляем логи, которые мы хотим отправлять в Splunk. Необязательно добавлять этот файл в образ, если вы, к примеру, раскидываете конфиги через puppet. Главное лишь в том, чтобы Forwarder видел конфиги, при старте демона, иначе будет нужен ./splunk restart.
А что за docker stats скрипты? На гитхабе есть старое решение от outcoldman, скрипты взяты оттуда и доработаны для работы с актуальными версиями Docker (ce-17.*) и Splunk (7.*).
С полученными данными можно строить такие


Исходный код дэшей лежит в репе, указанной в конце статьи. Обратите внимание, что там присутствует 2 select поля: 1 — выбор индекса (ищутся по маске), выбор хоста/контейнера. Маску индекса скорее всего вам придётся обновить, в зависимости от имён, которые вы используете.
В завершение, хочу обратить внимание на функцию start() в
Также стоит отметить момент, что по какой-то причине на Splunk не влияет наличие docker параметра hostname. Он всё равно будет упорото слать логи с id своего контейнера в поле host. Как решение, можно монтировать /etc/hostname с хост-машины и при старте делать замену, аналогичную именам индексов.
Да, возможно, решение не идеальное и уж точно не универсальное для всех, так как присутствует много «хардкода». Но на основе него каждый может собрать свой образ и положить его в свой приватный артифактори, если, так уж случилось, вам необходим Splunk Forwarder именно в докере.
Загрузка данных в Splunk: Universal Forwarder vs Heavy Forwarder. В чем разница?
Сегодня мы поговорим об агентах(форвардерах) для загрузки данных в Splunk. В статье мы кратко расскажем о том, что это такое, какие типы бывают, в чем между ними разница и в каких ситуациях лучше использовать тот или иной форвардер.
Корректная загрузка данных — это самый проблемный вопрос в любой системе по работе с данными. Передача данных может осуществляться различными способами, но самый распространенный из них это использование форвардеров.
У Splunk форвардера есть ряд преимуществ:
Всего существует 2 вида форвардеров:
Universal Forwarder
Universal Forwarder имеет ряд преимуществ перед использованием Heavy Forwarder. И поэтому зачастую рекомендуется использовать именно его, если нет конкретных предпосылок использования Heavy Forwarder, о которых мы расскажем далее.
Наиболее заметным преимуществом является то, что Universal Forwarder использует значительно меньше аппаратных ресурсов, чем другие программные продукты Splunk. Он меньше нагружает CPU, использует меньше памяти и занимает меньше места на диске. Он также более масштабируемый, чем другие продукты Splunk, поскольку можно установить более тысячи экземпляров, которые не будут сильно влиять на производительность сети и хостов.
Еще преимуществом является его доступность для установки на многих различных платформах. Его можно установить не только на Windows, Linux и Mac OS, как Splunk Enterprise, но и на Solaris, FreeBSD и AIX.
Universal Forwarder доступен как отдельный установочный пакет и включает только необходимые компоненты, необходимые для пересылки данных в другие экземпляры платформы Splunk. Хотя он не имеет веб-интерфейса, но все равно его можно настраивать, управлять и масштабировать, редактируя конфигурационные файлы.
Для достижения более высокой производительности Universal Forwarder имеет несколько ограничений:
Heavy Forwarder
Хотя Universal Forwarder является предпочтительным способом пересылки данных, но вам может потребоваться Heavy Forwarder, если необходимо проанализировать или внести изменения в данные, прежде чем пересылать их, или вам нужно будет контролировать, куда данные идут, основываясь на их содержании.
Одним из ключевых преимуществ Heavy Forwarder является то, что он может фильтровать нежелательные события, даже в неструктурированных данных, что позволит сократить объем индексации, а от этого зависит размер лицензии.
Правда, следует отметить, что использование Heavy Forwarder увеличивает сетевой трафик, использование ЦП и памяти. Это связано с тем, что Heavy Forwarder отправляет проанализированные данные по сети не просто сырыми событиями, а со всеми полями, которые выделяются во время индексации и дополнительными метаданными.
Чтобы сравнить показатели работы Heavy и Universal Forwarder, было проведено испытание.
В тестовом файле было 367 463 625 событий.
| Сетевой трафик (Гб) | Средняя скорость передачи (кбит/с) | Средняя скорость индексации (кбит/с) | Длительность (сек) | |
|---|---|---|---|---|
| Heavy Forwarder | 38.4 | 1922 | 5139 | 20998 |
| Universal Forwarder | 6.4 | 1015 | 17466 | 6662 |
Итоги эксперимента
При использовании Universal Forwarder:
Рекомендации
Используйте Heavy Forwarder, только когда:
Если вы все еще не пробовали Splunk, то самое время начать, бесплатная версия до 500Мб в сутки доступна всем желающим. А если у вас есть вопросы или проблемы со Splunk — вы можете задать их нам, а мы поможем.
Загрузка данных в Splunk: Universal Forwarder vs Heavy Forwarder. В чем разница?

Корректная загрузка данных — это самый проблемный вопрос в любой системе по работе с данными. Передача данных может осуществляться различными способами, но самый распространенный из них это использование форвардеров.
У Splunk форвардера есть ряд преимуществ:
Всего существует 2 вида форвардеров:
Universal Forwarder
Universal Forwarder имеет ряд преимуществ перед использованием Heavy Forwarder. И поэтому зачастую рекомендуется использовать именно его, если нет конкретных предпосылок использования Heavy Forwarder, о которых мы расскажем далее.
Наиболее заметным преимуществом является то, что Universal Forwarder использует значительно меньше аппаратных ресурсов, чем другие программные продукты Splunk. Он меньше нагружает CPU, использует меньше памяти и занимает меньше места на диске. Он также более масштабируемый, чем другие продукты Splunk, поскольку можно установить более тысячи экземпляров, которые не будут сильно влиять на производительность сети и хостов.
Еще преимуществом является его доступность для установки на многих различных платформах. Его можно установить не только на Windows, Linux и Mac OS, как Splunk Enterprise, но и на Solaris, FreeBSD и AIX.
Universal Forwarder доступен как отдельный установочный пакет и включает только необходимые компоненты, необходимые для пересылки данных в другие экземпляры платформы Splunk. Хотя он не имеет веб-интерфейса, но все равно его можно настраивать, управлять и масштабировать, редактируя конфигурационные файлы.
Для достижения более высокой производительности Universal Forwarder имеет несколько ограничений:
Heavy Forwarder
Хотя Universal Forwarder является предпочтительным способом пересылки данных, но вам может потребоваться Heavy Forwarder, если необходимо проанализировать или внести изменения в данные, прежде чем пересылать их, или вам нужно будет контролировать, куда данные идут, основываясь на их содержании.
Одним из ключевых преимуществ Heavy Forwarder является то, что он может фильтровать нежелательные события, даже в неструктурированных данных, что позволит сократить объем индексации, а от этого зависит размер лицензии.
Правда, следует отметить, что использование Heavy Forwarder увеличивает сетевой трафик, использование ЦП и памяти. Это связано с тем, что Heavy Forwarder отправляет проанализированные данные по сети не просто сырыми событиями, а со всеми полями, которые выделяются во время индексации и дополнительными метаданными.
Чтобы сравнить показатели работы Heavy и Universal Forwarder, было проведено испытание.
В тестовом файле было 367 463 625 событий.
| Сетевой трафик (Гб) | Средняя скорость передачи (кбит/с) | Средняя скорость индексации (кбит/с) | Длительность (сек) | |
|---|---|---|---|---|
| Heavy Forwarder | 38.4 | 1922 | 5139 | 20998 |
| Universal Forwarder | 6.4 | 1015 | 17466 | 6662 |
Итоги эксперимента
При использовании Universal Forwarder:
Рекомендации
Используйте Heavy Forwarder, только когда: