Анализ логов веб-сервера с помощью GoAccess

Не так давно мы натолкнулись на утилиту GoAccess, которая позволяет анализировать логи веб серверов и строить отчеты. Утилита написана на C и имеется почти во всех репозиториях дистрибутивов Linux. Адрес проекта.
В данной заметке не будет ничего революционного, лишь краткое HOWTO, большую часть из которого вы сможете найти в документации.
И так по порядку:
В файле /etc/goaccess.conf раскомментируем строки для анализа логов nginx:
Результат анализа может быть получен в двух режимах, в консольном(интерактивном), и в виде отчета. Программа поддерживает несколько видов отчетов, таких как html, json и csv
Самый простой случай запуска программы, для анализа текущего лога:
В этом случае мы получим анализ текущего лога в таком виде: 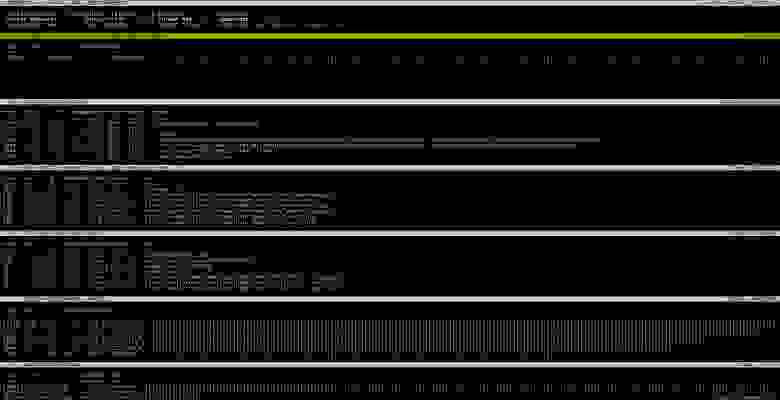
По параметрам можно перемещаться с помощью TAB.
А веб-отчет будет выглядеть так: 
А теперь рассмотрим случай когда нам надо анализировать не весь лог, а только его определенную часть:
Логирование является очень важным инструментом разработчика, но при создании распределённых систем оно становится камнем, который нужно заложить прямо в фундамент вашего приложения, иначе сложность разработки микросервисов очень быстро даст о себе знать.
В этой статье мы возьмём простое веб-апи приложение и организуем логирование, которое будет
сохранять сквозную корелляцию между логами независимых сервисов так, чтобы можно было легко посмотреть все активности, которые были вызваны конкретным запросом с клиента
иметь единую точку входа с удобным анализом, чтобы инструментом логирования смогла пользоваться даже Поддержка, к которой летят вопросы вроде «у меня тут в приложении выскочила ошибка с таким-то айдишником запроса»
Во-первых, нам необходимо определиться с поставщиком логирования в нашем приложении. Главное требование к современному логированию это структурность, т.е. мы должны работать не с плоскими текстовыми сообщениями, а с объектами. Благодаря таким логам мы можем легко строить представления наших сообщений в разных разрезах и проводить аналитику.
Для нашего приложения мы воспользуемся пакетом Serilog (Серилог), который имеет отличную поддержку структурного логирования и богатую систему дополнений. Я опущу базовые этапы его настройки (вы можете найти большое количество статей на эту тему) и сделаю допущение о том, что
Серилог уже сконфигурирован и является логером по-умолчанию у вашего поставщика внедрения зависимостей
в его конфигурации включено обогащение сообщений свойствами контекста (Enrich.FromLogContext)
Следующим шагом необходимо выбрать в какую систему централизованного сбора логов посылать сообщения из Serilog. Пожалуй, самый распространённый на сегодня вариант из открытого ПО это стек ELK (Elasticsearch, Logstash и Kibana), его и возьмём. Для этого воспользуемся предложением от Logz.IO — после регистрации на бесплатном тарифе в наших руках оказывается вся мощь поискового движка Lucene.
Нам остаётся добавить в наш проект пакет Serilog.Sinks.Logz.Io
И добавить соответствующий энричер в конфигурацию нашего логера, скормив ему токен доступа
Запустив приложение мы сможем наблюдать наши сообщения не только в консоли, но и в Кибане.
Интерфейсы
В приложении сервисного типа можно выделить два главных интерфейса его взаимодействия с внешним миром, обозначим их как вертикальный и горизонтальный. Вертикальный интерфейс — это веб-апи, через который прилетают вызовы от клиентского приложения. Горизонтальный — это брокер сообщений, который используется для обмена данными с другими внутренними сервисами.
Рассмотрим этапы внедрения корелляционности на каждом из этих интерфейсов.
Корелляция в HTTP-запросах
Чтобы получать как можно больше информации нам необходимо генерировать идентификатор корелляции как можно ближе к началу активности, т.е. на шлюзе или прямо на клиенте (мобильном или веб). Поскольку мы сегодня имеем дело с бекендным приложением, то просто обозначим на нём требование обязательного заголовка «X-Correlation-ID» во всех запросах к веб-апи.
Добавляем пакет CorrelationID, функция которого заключается в заборе значения из необходимого нам заголовка
Добавим его в конвейер обработки запроса
Теперь с его помощью сделаем простой action-фильтр:
И добавим его в контроллер
В результате контроллер станет выводить 400 Bad request на все запросы без заголовка с соответствующим идентификатором.
После того, как мы стали получать идентификатор от клиента мы должны добавить его в контекст журналирования, сделаем для этого обрамляющую прослойку:
В нашем приложении мы используем стандартный ILogger из пакета Microsoft.Extensions.Logging.Abstractions, поэтому значение будем добавлять с помощью нехитрого расширения к нему.
Добавляем прослойку в конвейер обработки запроса и получаем нужный результат.
Теперь все активности, которые порождены запросами к нашему веб-апи, содержат корелляционный идентификатор по которому их можно легко связать.
Корелляция в сообщениях брокера
Следующим шагом нам необходимо наладить передачу и приём корелляционного идентификатора через брокер сообщений. В нашем примере мы будем использовать RabbitMQ, а в качестве клиента возьмём фреймворк MassTransit (МассТранзит). Опять же, опустим первоначальную настройку работы с МассТранзита и перейдём сразу к настройке логирования.
Для начала мы можем включить логи самого МассТранзита, для этого добавим в наше приложение пакет MassTransit.SerilogIntegration
Теперь после добавления логера в настройки MassTransit мы сможем видеть логи фреймворка.
Пусть наше приложение в качестве реакции на POST-запрос отправляет событие SomethingHappened со значением «Hello». Контракт такого сообщения можно описать так:
Сообщения МассТранзита по сути являются конвертом, в который вложены сообщения брокера. Выглядит конверт примерно так:
В сообщении видны служебные поля, которые необходимы для работы самого фреймворка, но мы имеем возможность добавлять в этот конверт и собственные дополнительные свойства. Более того, MassTransit имеет встроенные средства работы с некоторыми опциональными полями, более всего из которых нам интересен идентификатор корелляционности CorrelationId.
Добавим к контракту сообщения интерфейс CorrelatedBy:
Реализуем его и будем присваивать значение свойству CorrelationId при создании сообщения:
Если мы посмотрим на обновлённое сообщение, то увидим что идентификатор корелляции стал не только частью нашего сообщения, но и частью конверта — этот идентификатор теперь будет также использоваться во всех логах МассТранзита, а значит нам будет гораздо проще разбираться с проблемами на уровне брокера сообщений.
Нам осталось настроить логирование этих служебных свойств сообщения, для этого добавим в проект пакет Serilog.Enrichers.MassTransitMessage. Пакет добавляет фильтр в конвейер обработки сообщений MassTransit, который складывает контекст сообщения в потокобезопасный стек. Серилог читает контекст из стека и добавляет в наши объекты логов эти дополнительные свойства.
В МассТранзите вставляем фильтр
А в конфигурации Серилога добавляем энричер
Поскольку приложение, которое получает сообщение из очереди RabbitMQ, имеет доступ ко всем свойствам конверта MassTransit, мы можем использовать полученный идентификатор корелляционности внутри приложения-потребителя, а также передавать его дальше по всей цепочке вызовов.
В результате наши логи стали содержать CorrelationId не только в пределах одного сервиса, но и при взаимодействии с другими приложениями.
Разумеется, в таком виде логирование не покроет сложные варианты взаимодействия ваших сервисов и различных внешних систем, но наведение подобного порядка в самом начале развития проекта — это одна из тех вещей, за которые вы сами себе не раз скажете спасибо.
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Логи Apache (ч. 3): Программы для анализа логов Apache
Оглавление: Всё о логах Apache — от настройки до анализа
4. Криминалистические логи
5. Дополнительные настраиваемые журналы отладки. Журналы выполнения CGI скриптов
Объединение логов Apache в один файл
Текущий журнал логов Apache обычно хранится в обычном текстовом файле с именем access_log, а журнал ошибок в файле error_log. Журналы за предыдущие дни, как правило, также сохраняются, но сжимаются в архивы. Им присваиваются имена access_log.1.gz, access_log.2.gz и так далее.
Если необходимо проанализировать журнал не только за последний день, но и за предыдущие, то все логи Apache можно объединить в один файл. Это можно сделать в командной строке с помощью группировки команд:
GoAccess
GoAccess — это мощнейший анализатор логов Apache, программа создаёт интерактивные отчёты, которые можно просматривать в любом браузере. Работает как на Linux, так и на Windows. Подходит для общего анализа логов веб сервера, для мониторинга активности в реальном времени или для анализа определённых аспектов активности или проблем.
Способы установки и ещё больше примеров вы найдёте в подробном описании данной программы на странице «GoAccess: программа для анализа логов веб-серверов (полная документация, примеры)».
Самый типичный запуск программы goaccess для анализа файлов журналов и генерации отчёта, который можно открыть в веб-браузере:
Поддерживаются следующие форматы логов и значений для опции —log-format:
Если у вас особый формат, не подходящий ни под один из указанных выше, то вы можете настроить обработку любого формата в конфигурационном файле, для этого смотрите раздел «Как настроить goaccess.conf».
Для того, чтобы собрать статистику по странам, которые обращались к сайту (геолокация), нужно указать с опцией —geoip-database путь до базы данных GeoIP, например GeoLiteCity.dat или GeoLite2-City.mmdb.
Если используется GeoIP2, то нужно скачать базу данных GeoLite2-City.mmdb или GeoLite2-Country.mmdb. Эти базы данных можно скачать с сайта MaxMind.com — скачивание бесплатно, но требует получение API, поэтому нужно зарегистрироваться на сайте — всё это бесплатно.
Итак, мой большой объединённый лог Apache размещён в файле biglog.txt, он в формате COMBINED, я хочу сохранить созданный отчёт в файл файл logs_report.html и при анализе использовать геолокацию с помощью БД GeoLite2-City.mmdb, тогда команда следующая:
Открыть сгенерированный отчёт можно в любом браузере:

Если вас интересует подробное описание каждого пункта, то смотрите статью «Зачем и как анализировать логи веб-сервера».
Можно указать различные форматы вывода: -o —output=
То есть формат определяется расширением файла, поэтому имя можно указать любое, а расширение файла выбрать одно из трёх представленных.
Для анализа рефереров (ссылающиеся сайты) можно исключить сам анализируемый сайт, а также разные некорректные значения, это делается опцией —hide-referer, которую можно использовать много раз:
Если среди ссылающихся сайтов не интересуют поисковые системы, то их также можно добавить в исключения:
Ещё одна опция, которая улучшает наглядность результатов, это -d или длинный вариант —with-output-resolver, эта опция включает преобразование IP адресов в имена хостов, работает только для форматов HTML и JSON.
Обратите внимание, что для при использовании опции -d выполняется большое количество DNS запросов и создание файла отчёта может проходить медленнее.
Кстати, вы можете воспользоваться онлайн сервисом GoAccess для анализа логов веб-сервера: https://suip.biz/ru/?act=goaccess
Там написано, что это анализатор логов Apache, но на самом деле принимается любой формат логов, который поддерживает GoAccess.
LORG — анализатор безопасности лог файлов Apache, это инструмент для расширенного анализа безопасности журналов HTTPD. Он нацелен на реализацию различных современных подходов к обнаружению атак на веб-приложения в журналах HTTP-трафика (например, в журналах доступа Apache (файлы access_log)), включая методы на основе сигнатур, статистики и машинного обучения. Обнаруженные инциденты впоследствии группируются в сеансы, которые классифицируются как «ручные» или автоматизированные, чтобы определить, является ли злоумышленник человеком или машиной. Кроме того, могут быть выполнены геотаргетинг и поиск DNSBL, чтобы увидеть, происходят ли атаки с определённой геолокации или ботнета. Кроме того, атаки могут быть определены количественно с точки зрения успеха или неудачи на основе аномалий в пределах размера ответов HTTP, кодов ответов HTTP или активного воспроизведения подозрительных запросов.
Подробное описание LORG, полный список опций и инструкции по установке вы найдёте на этой странице: https://kali.tools/?p=4852
Я буду использовать следующие опции в команде:
Файл с журналом Apache находится в файле
/access_log, отчёт я хочу сохранить в текущую папку в файл с именем report.htm, тогда команда следующая:
Отчёт можно открыть в веб-браузере:
Как отредактировать форматы логов в LORG
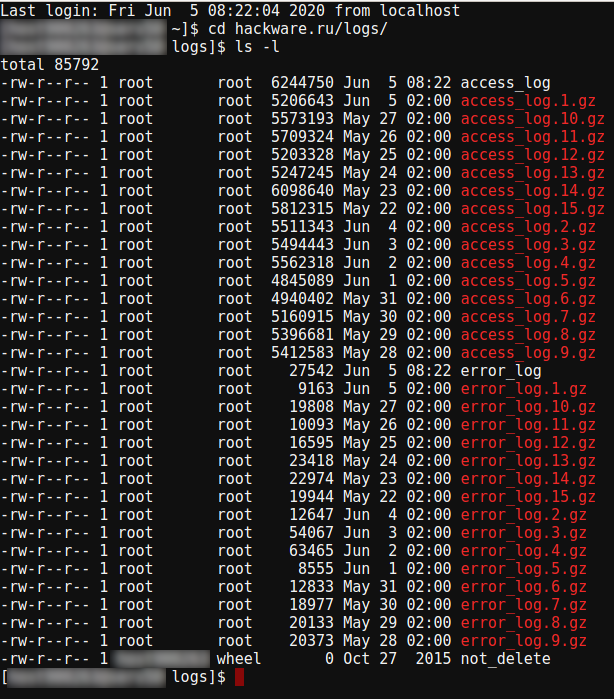
На самом деле, формат моего журнала веб-сервера не подходит ни под один из предлагаемых форматов LORG (common combined vhost logio cookie). Формат моего файла очень похож на combined с тем отличием, что в конце строки идёт имя хоста (домен сайта). Можно отредактировать имеющиеся поддерживаемые форматы логов или добавить свои. Для этого открываем исполнимый файл программы:
Находим там строки:
К этим строкам я добавлю новый формат моего хостера Hostland:
Сохраняем и закрываем файл.
Вновь запускаю команду для анализа логов, но в этом случае указываю в качестве типа формата combined_hostland:
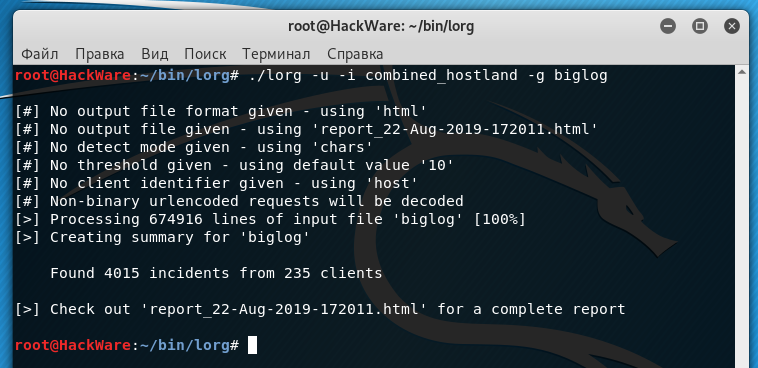
Хотя в файле biglog.txt почти 6 миллионов записей, анализ прошёл довольно быстро.
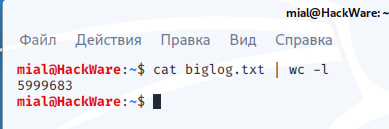
Когда программа завершает работу, она выводит обобщённую статистику — сколько найдено инцидентов и какое количество пользователей в них задействовано:
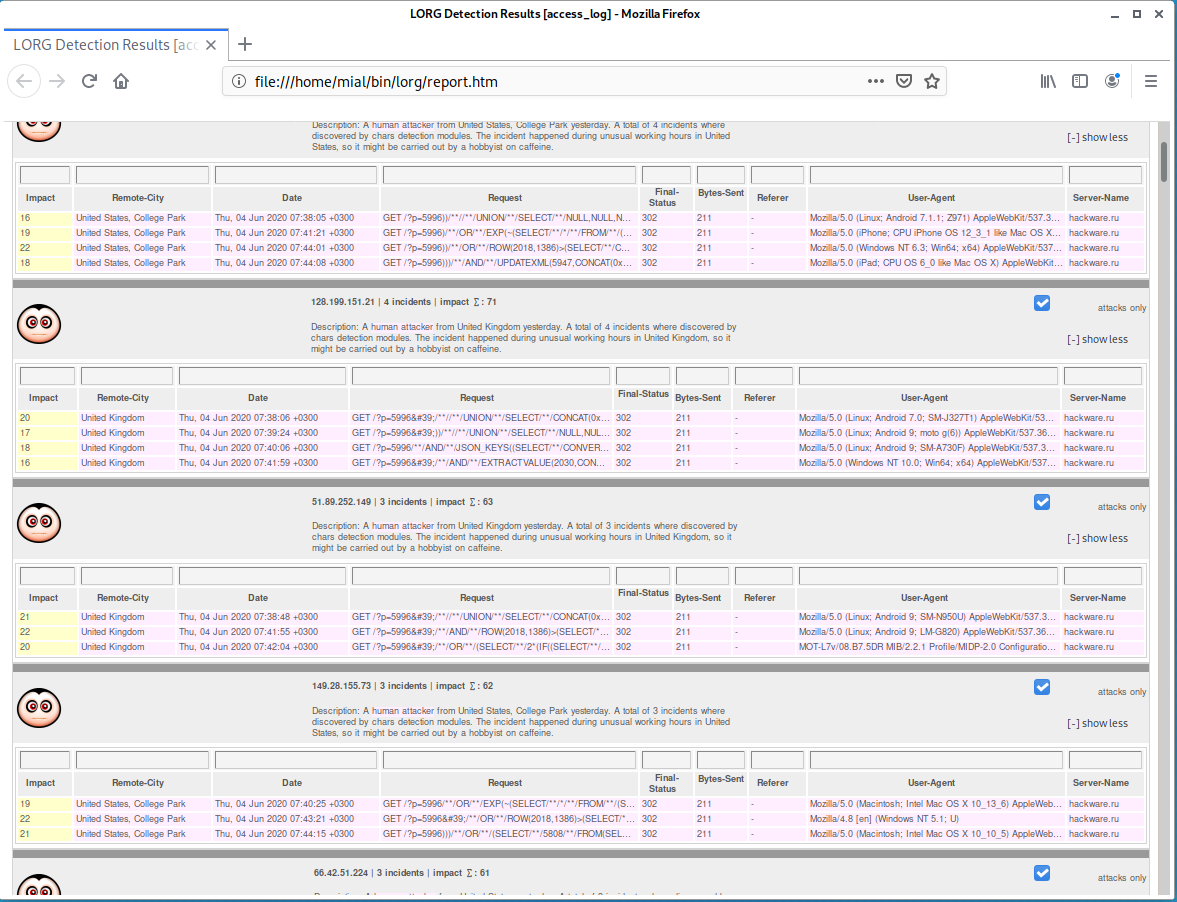
Открываем созданный отчёт:
Вверху диаграмма с обобщённой информацией:

Для каждого инцидента можно просмотреть детальную информацию:
ARTLAS
ARTLAS — это анализатор логов Apache в реальном времени. Основываясь на важнейших 10 уязвимостях по классификации OWASP, эта программа выявляет попытки эксплуатации ваших веб-приложений и уведомляет вас или вашу команду по реагированию на инциденты по Telegram, Zabbix и Syslog/SIEM.
ARTLAS использует регулярные выражения из проекта PHP-IDS для идентификации попыток эксплуатации.
Подробности и инструкцию по установке смотрите на странице: https://kali.tools/?p=4832
К сожалению, данная программа написана на Python 2 и давно не обновлялась.
Анализ логов с помощью инструментов командной строки (Bash)
Очень удобно использовать комбинацию из команд Linux для быстрого анализа логов. Это поможет определить, например, с каких IP пришло больше всего запросов.
В следующих командах вместо файла access_log подставляйте имя вашего файла журналов Apache. Вы можете указать полный путь до этого файла, например, /var/log/httpd/access_log.
Если файл заархивирован, то вместо cat используйте zcat:
Если в команде не используется cat, но файл заархивирован, то вы можете чуть отредактировать команду. Допустим, в следующем примере обрабатывается файл access_log:
Программа awk (смотрите Уроки по Awk) как и большинство других может принимать данные из стандартного ввода, поэтому эту же команду можно переписать следующим образом:
Как вы видите, теперь в неё есть cat и, следовательно, для сжатых файлов этот сниппет можно использовать следующим образом:
Поиск по произвольной строке
Простейший пример, поиск среди запросов по произвольной строке (IP адрес, User-Agent, адрес страницы и т. д.) с помощью grep:
Чтобы найти все строки, содержащий определённый статус ответа, например, 403 (доступ запрещён):
Список всех пользовательских агентов, отсортированных по количеству раз, которое они появлялись:
Анализ различных ответов сервера и запросов, которые вызвали их:
Вывод показывает как много типов запросов получил ваш сайт. «Нормальный» результат запроса — это код 200, который означает, что страница или файл были запрошены и доставлены. Но возможны и многие другие варианты.
Наиболее распространённые ответы:
Ошибка 404 говорит об отсутствующем ресурсе. Посмотрите на запрашиваемые URI, которые получили эту ошибку.
Ещё один вариант вывода самых часто не найденных страниц на сайте:
IP адреса, сделавшие больше всего запросов:
Первые 25 IP адресов, сделавших больше всего запросов с показом их страны:
Установим необходимые зависимости:
Команда для показа страны IP адресов, сделавших больше всего запросов к серверу:
Для поиска сайтов, которые вставляют изображения моего сайта (при воровстве статей, например):
В предыдущей и следующей командах не забудьте отредактировать доменное имя.
Для анализа всех архивов:
Пустой пользовательский агент
Пустой пользовательский агент обычно говорит о том, что запрос исходит от автоматического скрипта. Следующая команда выдаст список IP адресов для этих пользовательских агентов и уже на основе него вы сможете решить, что с ними делать дальше — блокировать или разрешить заходить:
Слишком большая нагрузка из одного источника?
Когда ваш сайт находится под тяжёлой нагрузкой, вам следует разобраться, нагрузка исходит от реальных пользователей или от чего-нибудь ещё:
Вывод IP адресов, отсортированных по количеству запросов:
10 самых активных IP:
Трафик в килобайтах по кодам статуса:
10 самых популярных рефереров (не забудьте отредактировать доменное имя):
10 самых популярных пользовательских агентов:
Анализ активности IP по последним 10,000 запросам на сайт.
Распределение активности пользователей по времени
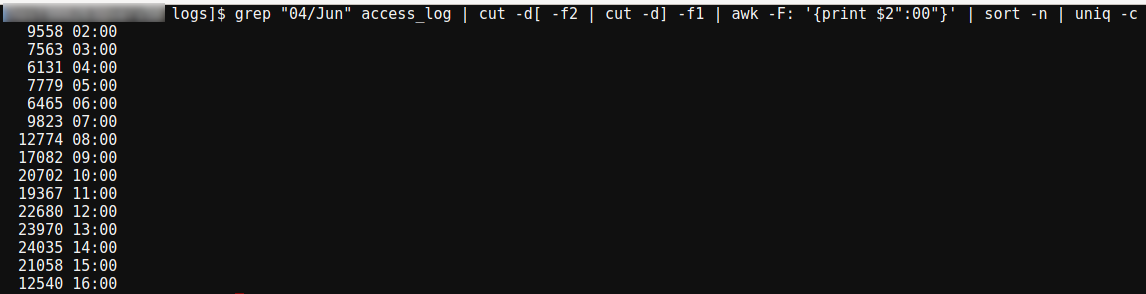
Количество запросов за день:
Количество запросов по часам (укажите день):
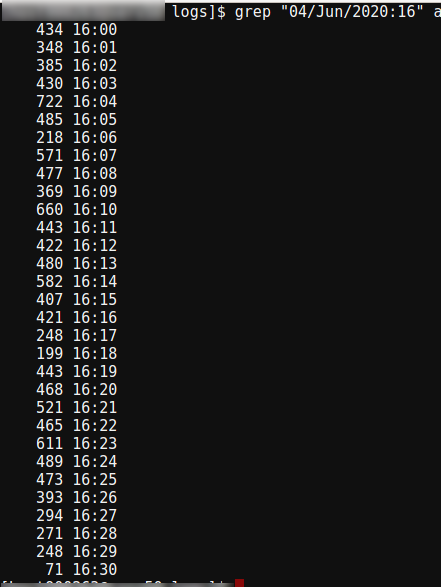
Количество запросов поминутно (укажите дату и время):
Всего уникальных посетителей:
Уникальные посетители сегодня:
Уникальные посетители в этом месяце:
Уникальные посетители на произвольную дату:
Уникальные посетители за месяц:
Популярное на сайте
Отсортированная статистика по «количеству посетителей/запросов» «IP адреса посетителей»:
Наиболее популярные URL:
Мониторинг запросов на сайт в реальном времени
Наблюдение за запросами в реальном времени:
Информация об IP адресах в реальном времени:

Анализ IP адресов
Список всех уникальных IP адресов:
Уникальные IP адреса с отметкой даты-времени:
Уникальные IP адреса и браузеры:
Уникальные IP адреса и ОС:
Уникальные IP адреса, дата-время и метод запроса:
Уникальные IP адреса, дата-время и запрошенный URL:
Команды для проверки логов на виртуальных хостингах
Быстрый показ количества запросов по каждому из сайтов на аккаунте Hostland (полезно когда нужно выяснить, какой из сайтов является причиной повышенной загрузки, какой сайт потребляет больше всего ресурсов сервера):
Новый подход к просмотру логов

Одно время, приходилось много работать с логами. Они могли быть большими и находиться на разных серверах. Требовалось не найти что-то конкретное, а понять почему система ведёт себя не так как надо. По некоторым причинам, лог-агрегатора не было.
Хотелось иметь просмотрщик логов, позволяющий, в любой момент, открыть любой файл, без скачивания на локальную машину, как команда less в linux консоли. Но при этом, должна быть удобная подсветка текста, как в IDE, и фильтрация записей по различным параметрам. Фильтрация и поиск должны работать по событиям в логе, а не по строкам, как grep, это важно когда есть многострочные записи, например ошибки со стектрейсами. Так же должна быть возможность просматривать записи сразу из нескольких файлов на одной странице, смёржив их по таймстемпу, даже если файлы находятся на разных нодах.
И я придумал как сделать такую утилиту!
Предвижу вопросы о производительности типа «Разве можно быстро фильтровать записи без индексации? В плохих случаях придётся остcканировать весь лог чтобы найти хоть одну запись подходящую под фильтр». Во первых, сканирование лога работает довольно быстро, 1Гб читается около 3,5сек, это терпимо. Во вторых, обычно известен временной интервал, в котором ищем проблему, если задан фильтр по дате, то будет сканироваться только та часть файла, в которой находятся записи относящиеся к тому времени. Найти границу временного интервала в файле можно очень быстро бинарным поиском.
Отображение лога
Чтобы легче различать границы одной записи, запись под курсором подсвечивается прямоугольником; поле severity подсвечивается различными цветами в зависимости от значения, парные скобки подсвечиваются когда наводишь курсор на одну из них.
Имя логгера тоже сокращено: «
.SecurityManager». Показывается только имя класса, а пакет сворачивается в «
Фолдинг влияет только на отображение, поиск работает по оригинальному тексту. Если совпадение найдётся в сокращённой части текста, то эта часть текста автоматически появится. Также, если пользователь выделит текст и нажмёт Ctrl+C, в буфер скопируется исходный текст, без всяких сокращений.
Архитектура позволяет легко навешивать на текст подсветку или всплывающие подсказки, благодаря этому, сделаны разные приятные мелочи типа показа даты в человеческом формате, если она напечатана в виде числа:
Фильтрация
Набор фильтров зависит от формата лога. Некоторые фильтры доступны всегда, например фильтр по подстроке, а некоторые появляются если в логе присутствует поле определённого типа. Это позволяет создавать специализированные фильтры для некоторых типов полей. Например, если в логе есть поле severity, то в верхней панельке появится такой UI компонент:
Очень удобно добавлять фильтры из контекстного меню. Можно выделить текст, кликнуть правой кнопкой мыши и выбрать «Не показывать записи с таким текстом». На панельку с фильтрами автоматически добавится фильтр по тексту, скрывающий записи с таким текстом. Помогает когда лог завален однообразными записями, не интересными в данный момент.
Добавление фильтров из контекстного меню
Можно кликнуть на запись и выбрать «Скрыть последующие записи» или «Скрыть предыдущие записи», чтобы работать только с определённой частью лога. Скрытие происходит добавлением фильтра по дате.
Для сложных случаев можно задать фильтр с условием написанным на JavaScript. Такой фильтр представляет из себя функцию принимающую одну записи и возвращающую true или false.
Пример фильтра на JavaScript
При изменении фильтров, просмотрщик старается максимально сохранить позицию в логе. Если есть выделенная запись, то изменение фильтров не изменит её положения на экране, а записи вокруг пропадут или появятся. Пользователь может задать фильтр, чтобы были видны только ошибки, найти подозрительную ошибку, затем убрать фильтр и смотреть что происходило вокруг этой ошибки.
Состояние панели фильтров отображается в параметрах URL, чтобы можно было добавить в закладки браузера текущую конфигурацию.
Мелкие, но полезные фичи
Когда находишь что-то интересное — хочется поделиться этим с командой, для этого можно создать специальную ссылку на текущую позицию в логе, и любой кто её откроет увидит точно такую же страницу, которая была при создании ссылки, включая состояние фильтров, текста в поле поиска, выделенной записи и т.д.
Если сервер расположен в другой таймзоне, над текстом с датой будет всплывающая подсказка с датой в таймзоне пользователя.
Конфигурация
Я старался сделать конфигурацию как можно проще, чтобы всё работало из коробки. Если попросить пользователя задать формат лога, то большинство просто закроют приложение и пойдут смотреть по старинке. Поэтому формат лога распознаётся автоматически. Конечно, это работает не всегда и часто не точно. Для таких случаев можно задать формат лога вручную в файле конфигурации. Можно использовать паттерны log4j, logback или просто регексп. Если ваш лог не распознался, но вам кажется что должен — создайте issue на GitHub, этим вы поможете проекту.
Самая нужная настройка — список видимых файлов. По умолчанию доступны все файлы с расширением «.log» и видна вся структура каталогов, но это не очень хорошо с точки зрения секьюрити. В конфигурационном файле можно ограничить видимость файлов с помощью списка паттернов типа такого:
/work и её поддиректориях.
Более подробная информация в документации на GitHub.
Работа с несколькими нодами
Мёрж файлов, расположенных на разных нодах — это киллер фича, ради которой и затевался проект. Как я уже говорил, файл никогда не скачивается полностью с одной ноды на другую и не индексируется. Поэтому, на каждой из нод должен быть запущен Log Viewer. Пользователь открывает web UI на одной из нод, указывает расположение логов, и Log Viewer коннектится к другим инстансам LogViewer чтобы подгружать содержимое лога через них. Записи из всех открытых файлов мёржатся по таймстемпу и показываются как буд-то это один файл.
Вкратце опишу как это работает под капотом. Когда пользователь открывает страницу, надо показать конец лога, для этого на каждую ноду отправляется запрос «дай последние N записей», где N — количество строк помещающихся на экран. Полученные записи сортируются по таймстемпу, берутся последние N записей и показываются пользователю. Когда пользователь скролит страницу вверх, на все ноды посылается запрос «дай последние N записей с таймстемпом меньше T», где T — таймстемп самой верхней записи на экране. Полученные записи сортируются и добавляются на страницу. При скроле вниз происходит тоже самое, только в другую сторону. Поиск позиции в файле, где находятся записи старше/младше T, работает очень быстро, так как записи отсортированы по таймстемпу и можно использовать бинарный поиск. Там есть много нюансов, но общая схема такая. Мёрж работает только если система смогла определить фомат лога и в каждой записи задан полный тайстемп.
На данный момент, нет UI для выбора файлов на разных нодах, приходится прописывать файлы в параметрах URL в таком виде:
http://localhost:8111/log?path=/opt/my-app/logs/a.log@hostname1&path=/opt/my-app/logs/b.log@hostname1&path=/opt/my-app/logs/c.log@hostname2
здесь каждый параметр «path» задаёт один файл, после «@» указывается хост, на котором лежит файл и запущен инстанс просмотрщика логов. Можно указать несколько хостов через запятую. Если «@» отсутствует — файл находится на текущей ноде. Чтобы не иметь дела с огромными URL, есть возможность задать короткие ссылки в конфигурации, в разделе log-paths = < … >.
Встраивание просмотрщика в своё приложение
Log Viewer можно подключить к своему Java Web приложению как библиотеку, чтобы оно могло показывать пользователю свои логи. Иногда это удобней чем запуск отдельным приложением. Достаточно просто добавить зависимость на библиотеку библиотеку через Maven/Gradle и подключить один конфигурационный класс в spring context. Всё остальное сконфигурится автоматически, log viewer сам распознает какая система логгирования используется и возьмёт из её конфигурации расположение и формат логов. По умолчанию UI маппится на /logs, но всё можно кастомизировать. Пока автоматическая конфигурация работает только с Log4j и Logback.
Это тестировалось на маленьком количестве приложений, если у вас возникнут проблемы — смело пишите в discussions на GitHub.
Что планируется сделать в будущем
Было бы удобно, если бы была возможность оставлять комментарии к записям. Например, прикрепить номер тикета к сообщению об ошибке. Комментарий должен быть виден всем пользователям и, когда такая же ошибка вылетит в следующий раз, будет понятно что с ней делать.
Есть много идей по мелкому улучшению UI. Например, если в тексте встретился кусок JSON, то хочется чтобы просмотрщик умел показывать его в отформатированном виде, а не одной строкой. Хочется иметь возможность задать фильтр по severity для отдельного класса, а не сразу для всех.
Иногда нет возможности открыть порт на сервере для просмотра логов, есть только SSH доступ. Можно сделать поддержку работы через SSH. Web UI будет подниматься на локальной машине, коннектиться через SSH к серверу и запускать там специального агента. Агент будет принимать команды через input stream и возвращать нужные части лога через output stream.