Более 5540 заметок о виртуализации, виртуальных машинах VMware, Microsoft и Xen, а также Kubernetes
VM Guru / Articles / Типы виртуальных дисков vmdk виртуальных машин на VMware vSphere / ESX 4.
Типы виртуальных дисков vmdk виртуальных машин на VMware vSphere / ESX 4.
Типы виртуальных дисков vmdk виртуальных машин на VMware vSphere / ESX 4.
Автор: Александр Самойленко Дата: 07/07/2009
Виртуальные машины на платформе VMware vSphere размещаются на хранилищах Fibre Channel, iSCSI, NAS/NFS или локальных дисках серверов ESX. Диски виртуальных машин могут располагаться на томах в файловой системе VMFS (Virtual Machine File System), NFS (Network File System) или на томах RDM (Raw Device Mapping). При этом на томах VMFS и NFS виртуальные диски машин хранятся в формате vmdk, а на томах RDM виртуальная машина хранит свои данные напрямую на LUN. Сегодня мы поговорим о том, в каких форматах могут быть виртуальные диски машин в VMware vSphere, к которым обращаются серверы VMware ESX 4.
Диски типа Raw
Файловая система VMFS поддерживает схему Raw Device Mapping (RDM), которая представляет собой механизм для прямого доступа виртуальной машины к дисковой подсистеме (конкретному LUN) устройств хранения Fibre Channel или iSCSI. Этот тип виртуального диска доступен для создания из vSphere Client.
Если в сети хранения данных используется ПО для создания мгновенных снимков системами резервного копирования, которые запущены в виртуальных машинах, требуется прямой доступ к дисковой подсистеме устройств хранения. Кроме того Raw-диски используются для кластеров Microsoft Clustering Services (MSCS), включая кластеры типа «виртуальный-виртуальный» и «виртуальный-физический».
RDM может обеспечиваться путем предоставления символьной ссылки в томе VMFS к разделу Raw (режим виртуальной совместимости). В этом случае файлы маппирования, относящиеся к конфигурации виртуальных машин, отображаются как файлы в томе VMFS в рабочей директории виртуальной машины. Когда том Raw открывается для записи, файловая система VMFS предоставляет доступ к файлу RDM на физическом устройстве и реализует через него механизм блокирования и контроля доступа. После этого операции чтения и записи идут напрямую к тому Raw, минуя файл маппирования.
Файлы RDM содержат метаданные, используемые для управления и перенаправления доступа к физическому устройству. RDM предоставляет возможности прямого доступа к дискам, при этом сохраняются некоторые возможности, присущие файловой системе VMFS. Схема взаимодействия виртуальной машины с устройством хранения посредством механизма RDM изображена на рисунке:
Перед началом операций ввода-вывода виртуальная машина посредством файла маппирования инициирует открытие тома Raw. Далее файловая система VMFS осуществляет разрешение адресов секторов физического устройства, а виртуальная машина начинает производить операции чтения-записи на физическое устройство.
Используя RDM возможно производить следующие операции:
Для RDM используются два режима совместимости:
Использование функций VMotion, DRS и HA поддерживаются в обоих режимах совместимости.
Диски типа Thick («толстые диски»)
Это тип дисков vmdk на томах VMFS или NFS, размер которых предопределяется заранее (при создании) и не изменяется в процессе наполнения его данными.
Существует три типа дисков thick:
Thick disks
Zeroed thick disks (lazy zeroed thick disks)
Eager zeroed thick disks
Диски типа Thin («тонкие диски»)
Создание нового виртуального диска vmdk определенного типа на VMware ESX
Если вы хотите создать диск виртуальной машины определенного типа, то при ее создании выберите опцию «Do not create disk». Далее необходимо зайти в сервисную консоль сервера ESX по SSH с помощью Putty и выполнить такую команду (предварительно командой cd перейдите в папку с виртуальной машиной) для создания диска типа thin максимальным объемом 10 ГБ :
vmkfstools –c 10G –d thin thin.vmdk
для создания диска типа thick:
vmkfstools –c 10G –d thick thick.vmdk
для создания диска типа Zeroed thick:
vmkfstools –c 10G –d zeroedthick zeroedthick.vmdk
для создания диска типа Eager zeroed thick (операция достаточно долгая):
Изменение типа существующего виртуального диска vmdk на VMware ESX
Конвертация диска vmdk типа thin в thick. С помощью данной команды диск thin затирает содержимое блоков до своего максимального размера и превращается в диск thick (операция достаточно долгая):
vmkfstools –j thin.vmdk
Конвертация диска vmdk типа thick в thin. С помощью данной команды из диска vmdk типа thick копированием получаем диск типа thin (операция достаточно долгая):
Чтобы оставлять комментарии, вы должны быть зарегистрированы на сайте.
RedHat (и CentOS) начиная с версии 6.4 поддерживают Thin provisioned storage разряженные тома. Основная мысль похожа на разреженные (sparce) файлы. Том выглядит большим, но на самом деле занимает мало места — только то, которое нужно для хранения данных.
1. Уже должна существовать группа дисков (VG) и в ней должно быть свободное место, например storage 2. Создается пул разреженных томов, например на 100Гб. Эти 100Гб сразу отмечаются в VG как занятые и их нельзя исползовать под обычные LVM-разделы. Разреженные тома создаются внутри этого пула. Пул разреженных томов нигде симлинками не отмечен и напрямую не используется.
3. Создается разреженный том. Видимый размер разреженного тома может быть больше чем доступное место в пуле и даже больше размера самого пула, пока данные фактически могут поместиться в пул. Для разреженного тома так же как и для обычного создается симлинк (/dev/storage/test) и далее с ним можно работать как с обычным LVM-томом.
Просмотр фактически занятого места в пуле и на томе:
Если место в пуле будет полностью израсходовано и кто-то в этот момент попробует записать данные на диск — операция ввода/вывода будет приостановлена пока в пуле не появится место (можно что-то удалить или расширить пул через lvextend), после появления места операция записи будет завершена.
Кроме постепенного выделения места поддерживается и освобождение в пуле места которое раньше было занято, но теперь не нужно. Например на каком-то разделе потребовалось место чтобы создать/распаковать большой архив. А потом архив удаляется. Освобождение места поддерживается через механизм TRIM (аналогично очистке места на SSD) и в LVM называется discard_data.
освобождать место можно двумя путями: 1. Вручную, командой fstrim — место освобождается только при запуске команды в указанной точке монтирования
2. монтировать файловую систему с опцией discard. например — тогда место освобождается сразу после удаления данных с диска. (прим. XFS активно кеширует все изменения, так что в случае использования XFS нужно сделать sync если нужно очистить место быстро, либо подождать несколько минут пока изменения фактически применятся на диск сами).
Основы тонкого выделения томов на системах хранения (или юбилей 3PAR thin provisioning)
В этом году исполняется 10 лет с момента продажи первой системы хранения данных 3PAR с технологией Thin Provisioning. И несмотря на то что технология стала очень популярной и востребованной, толкового описания того как же это работает на низком уровне мне встретить до сих пор не удалось. В этой статье я попробую осветить наиболее «темные», на мой взгляд, стороны thin provisioning – технические основы данной технологии. То есть, то как именно хост взаимодействует с системой хранения данных. Эти технологии сейчас уже не являются эксклюзивом 3PAR, так как теперь это индустриальные стандарты, но так как технология thin provisioning впервые появилась в 3PAR, то позволю себе отдать все лавры именно этим массивам.
Зачем нужен thin provisioning
Для тех, кто пропустил предыдущие 10 лет, я всё же вкратце напомню, что такое thin provisioning и для чего он нужен, а остальные могут с чистой совесть пропустить этот раздел.
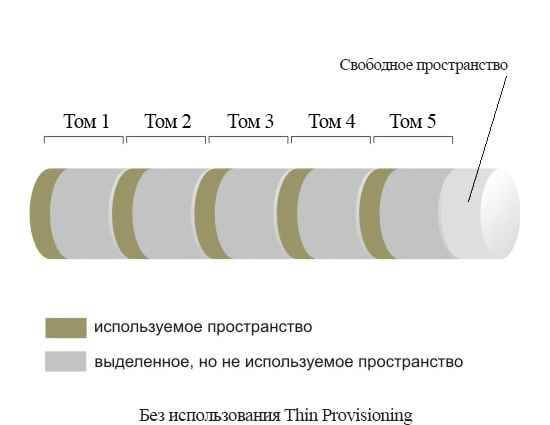
Thin provisioning – это технология виртуализации систем хранения данных, которая позволяет увеличить эффективность использования ресурсов системы хранения. Эта технология необходима для уменьшения использования дискового пространства, которое непосредственно не используется для хранения данных приложений. В частности файловые системы никогда в нормальных условиях не бывают заполнены на 100%. Однако всегда нужно иметь некий запас свободного места для обеспечения нормального функционирования файловой системы и для обеспечения готовности к росту данных. Это фактически не используемое пространство выделяют для всех логических томов на системе хранения данных. Логические тома, дисковое пространство для которых выделяется в полном объеме в момент создания на системе хранения, называют «тостыми». Такая модель использования дисковых ресурсов появилась вместе с первыми устройствами для хранения данных и жива до сих пор.
Для решения подобных проблем и были придуманы thin provisioning и thin reclamation о которых мы и поговорим более подробно.
Как работает thin provisioning
Исходя из вышесказанного, представить схему работы thin provisioning не составляет труда. При получении системой хранения команды SCSI Write (инкапсулированной в стек FC, SAS, iSCSI и пр.) она выделяет очередную порцию данных и записывает туда данные из SCSI Write. В случае с 3PAR блоки выделяются размером в 16К.
Как работает thin reclamation
А теперь обсудим гораздо более интересные и неочевидные моменты – каким образом хост взаимодействует с системой хранения для возврата освободившегося дискового пространства в общий пул. Взаимодействие хоста и системы хранения – крайне важный нюанс, так как только хост знает какие блоки можно удалять, а какие нет. Технология thin reclamation была впервые реализована на массивах 3PAR и сегодня является индустриальным стандартом, утвержденным Международным Комитетом по стандартизации в сфере информационных технологий (INCITS). Документ называется T10 SBC-3 и расширяет стандарт SCSI новыми командами для взаимодействия с системами хранения (эти команды были добавлены в восемнадцатой ревизии документа 23 февраля 2009 года). Аналогичный стандарт есть также для ATA/SATA устройств.
UNMAP
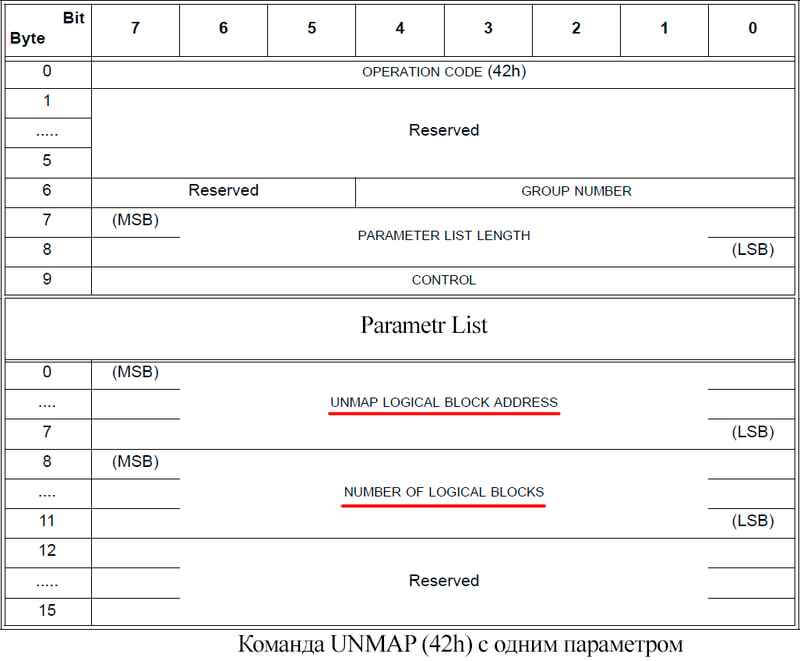
Сообщает системе хранения о необходимости освободить одну или несколько групп последовательных LBA (Logical Block Address). Система хранения должна пометить данные LBA как свободные (unmapped, в терминах SCSI), освободить место на бекэнде и фоновым процессом затереть данные которые там ранее находились на тот случай, если эти блоки будут потом выделены другому хосту. В этой команде передаётся исключительно служебная информация в виде множества пар состоящих из «LBA Address» и «Number of Logical Blocks».
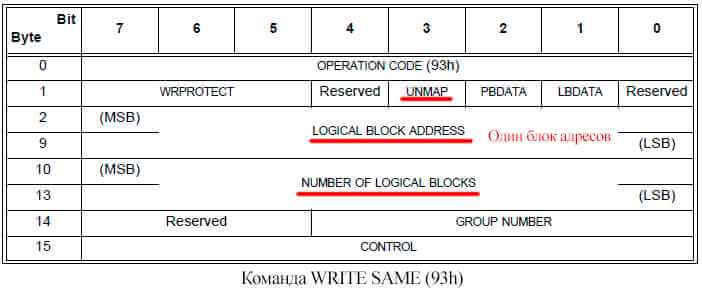
WRITE SAME
Если по каким-то причинам хост не желает использовать команду UNMAP он может получить похожий эффект с помощью команды WRITE SAME. Для этого предусмотрено битовое поле unmap. Если команда WRITE SAME с установленным битом unmap придет на массив с thin provisioning и том на массиве тонкий, то массив сделает тоже что и в случае с командой UNMAP. Отличается от команды UNMAP (42h) тем, что используя WRITE SAME нет возможности указать большое количество блоков для освобождения. Можно указать только одну пару «LBA Address» и «Number of Logical Blocks».
Также не стоит забывать, что команда WRITE SAME это в первую очередь команда для записи данных. В том случае, если бит unmap не установлен, система хранения не поддерживает thin provisioning или том толстый, то будет выполнена обычная операция записи данных по заданным LBA. Из этого следует, что в данных случаях SCSI READ обязан вернуть именно те данные, которые туда были записаны. Тут некоторые производители вроде того же Хьюлета хитрят и вместо последовательной записи однотипных данных (например нулей) помечают в метаданных логического тома эти блоки как выделенные но «заполненные нулями». Называется эта технология – zero detection.
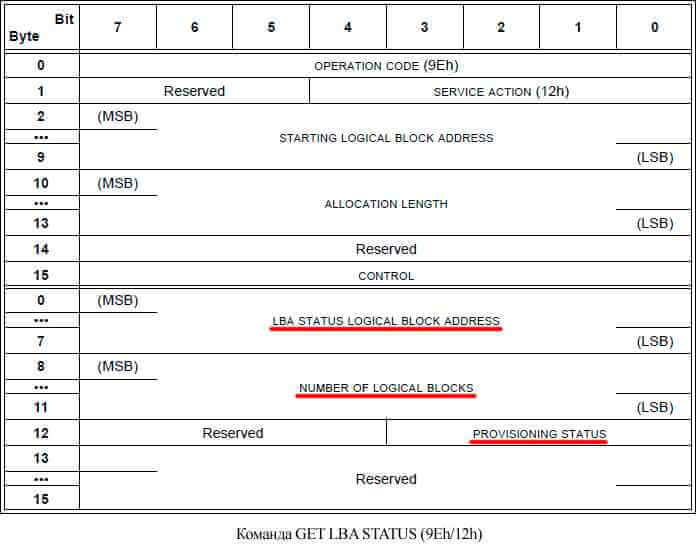
GET LBA STATUS
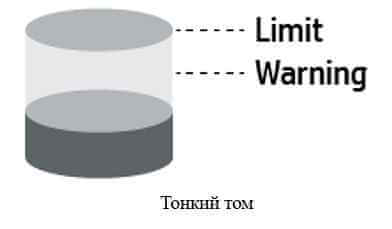
Это сервисная операция (специфичная для устройства) и она использует код команды SERVICE ACTION IN (9Eh). Она позволяет узнать серверу: 1. Поддерживает ли том thin provisioning. 2. Статус определенного блока на системе хранения (выделены ли для него реальные ёмкости на бекэнде или нет). 3. Гранулярность thin provisioning для тома. 4. Лимиты (тревожный уровень и максимальный объем).
Команда очень полезна например для фонового поиска со стороны хоста блоков, выделенных на массиве, но не используемых хостом для хранения данных или при переезде с толстых томов на тонкие.
LVM Thin Provision: опыт эксплуатации на малом объекте
Краткая вводная
О тонких томах я уже писал в более ранней статье. Производительность хорошая, слабо зависит от количества снимков, за более чем год, не было сбоев по вине именно LVM, все проблемы были созданы лично мной для себя любимого.
Грабли
Всем, кто начинает использовать тонкие тома, настоятельно рекомендуется чтение man lvmthin с пристрастием. Упущение, казалось бы, маловажного аспекта, что место в пуле томов может кончится, может привести к печальным последствиям.
Исчерпание места в Data space:
В зависимости от ФС. Обычно, после остановки io с переполненным томом, ФС остается целой, особенно если ФС журналируемая. Если вы успели расширить пул, и io-операции не успели отвалится по таймауту, то вообще все будет хорошо. Иначе откат журнала и небольшая потеря данных.
Исчерпание места в Metadata space:
Рекомендации:
Задавайте политику автоматического расширения тонких томов глобально. Задав разумные значения, вы потом сможете используя профили, настроить любую другую политику для пула. Однако, если система не применит профиль (в метаданных пула хранится имя профиля, который могли удалить), она сообщит об этом факте где-то в логах (чего можно и не заметить), но благодаря глобальной политике, все будет относительно неплохо.
LVM Thin Provision отлично работает в ситуации ленивого планирования. Это значит, что стоит под разные задачи создать пулы тонких томов разумно небольших размеров. В этих пулах создать тома, и просто наблюдать, как по мере заполнения растут размеры пулов. Выделять место сразу не стоит, не всегда можно предугадать под, что нужно место.
Размеры chunksize задавайте исходя из задачи. Большие размеры приведут к снижению накладных расходов в метаданных, но повлекут больший расход места на снимках (если совпадет с RAID5-6, то и тут бонус будет).
Zeroing — если отключить, получите чуть-чуть бонуса по скорости, но готовьтесь, в выделенных блоках может встретится всяких мусор.
Работа со снимками
Снимок создается без проблем, а вот его применение может вызвать некоторую проблему. Все дело в том, что пока том активен (хотя и не используемый), снимок к нему не применяется до следующей активации (или применяется в ленивом режиме). Поэтому, перед накатом снимка, дезактивируйте целевой том.
По умолчанию снимки создаются с флагом отмены активации. Это может обескуражить, при попытке его подключить.
Thin provisioned disk что это
В этом году исполняется 10 лет с момента продажи первой системы хранения данных 3PAR с технологией Thin Provisioning. И несмотря на то что технология стала очень популярной и востребованной, толкового описания того как же это работает на низком уровне мне встретить до сих пор не удалось. В этой статье я попробую осветить наиболее «темные», на мой взгляд, стороны thin provisioning – технические основы данной технологии. То есть, то как именно хост взаимодействует с системой хранения данных. Эти технологии сейчас уже не являются эксклюзивом 3PAR, так как теперь это индустриальные стандарты, но так как технология thin provisioning впервые появилась в 3PAR, то позволю себе отдать все лавры именно этим массивам.
Зачем нужен thin provisioning
Для тех, кто пропустил предыдущие 10 лет, я всё же вкратце напомню, что такое thin provisioning и для чего он нужен, а остальные могут с чистой совесть пропустить этот раздел.
Thin provisioning – это технология виртуализации систем хранения данных, которая позволяет увеличить эффективность использования ресурсов системы хранения. Эта технология необходима для уменьшения использования дискового пространства, которое непосредственно не используется для хранения данных приложений. В частности файловые системы никогда в нормальных условиях не бывают заполнены на 100%. Однако всегда нужно иметь некий запас свободного места для обеспечения нормального функционирования файловой системы и для обеспечения готовности к росту данных. Это фактически не используемое пространство выделяют для всех логических томов на системе хранения данных. Логические тома, дисковое пространство для которых выделяется в полном объеме в момент создания на системе хранения, называют «тостыми». Такая модель использования дисковых ресурсов появилась вместе с первыми устройствами для хранения данных и жива до сих пор.
Как работает и зачем нужен thin provisioning-01
ля решения подобных проблем и были придуманы thin provisioning и thin reclamation о которых мы и поговорим более подробно.
Как работает thin provisioning
Концепция thin provisioning проста и заключается в следующем:
Как работает и зачем нужен thin provisioning-02
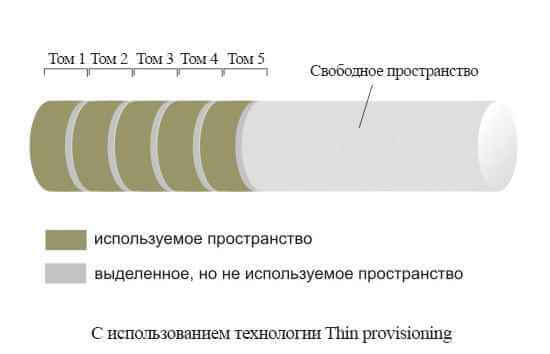
При запросе сервером размера тома (SCSI Read Capacity) система хранения отдаёт максимальный размер тома, который установил администратор СХД. Сумма максимальных объемов всех томов на системе хранения может превышать физически доступное пространство на системе хранения.
Как работает и зачем нужен thin provisioning-03
Исходя из вышесказанного, представить схему работы thin provisioning не составляет труда. При получении системой хранения команды SCSI Write (инкапсулированной в стек FC, SAS, iSCSI и пр.) она выделяет очередную порцию данных и записывает туда данные из SCSI Write. В случае с 3PAR блоки выделяются размером в 16К.
Как работает thin reclamation
А теперь обсудим гораздо более интересные и не очевидные моменты – каким образом хост взаимодействует с системой хранения для возврата освободившегося дискового пространства в общий пул. Взаимодействие хоста и системы хранения – крайне важный нюанс, так как только хост знает какие блоки можно удалять, а какие нет. Технология thin reclamation была впервые реализована на массивах 3PAR и сегодня является индустриальным стандартом, утвержденным Международным Комитетом по стандартизации в сфере информационных технологий (INCITS). Документ называется T10 SBC-3 и расширяет стандарт SCSI новыми командами для взаимодействия с системами хранения (эти команды были добавлены в восемнадцатой ревизии документа 23 февраля 2009 года). Аналогичный стандарт есть также для ATA/SATA устройств.
Для реализации thin provisioning стандарт предусматривает 3 SCSI команды:
Стандарт обязывает все системы хранения данных с thin provisioning в обязательном порядке поддерживать как минимум команду UNMAP или же команду WRITE SAME с битом unmap. Рассмотрим описанный протоколом API.
UNMAP
Сообщает системе хранения о необходимости освободить одну или несколько групп последовательных LBA (Logical Block Address). Система хранения должна пометить данные LBA как свободные (unmapped, в терминах SCSI), освободить место на бекэнде и фоновым процессом затереть данные которые там ранее находились на тот случай, если эти блоки будут потом выделены другому хосту. В этой команде передаётся исключительно служебная информация в виде множества пар состоящих из «LBA Address» и «Number of Logical Blocks».
Как работает и зачем нужен thin provisioning-04
Если по каким-то причинам хост не желает использовать команду UNMAP он может получить похожий эффект с помощью команды WRITE SAME. Для этого предусмотрено битовое поле unmap. Если команда WRITE SAME с установленным битом unmap придет на массив с thin provisioning и том на массиве тонкий, то массив сделает тоже что и в случае с командой UNMAP. Отличается от команды UNMAP (42h) тем, что используя WRITE SAME нет возможности указать большое количество блоков для освобождения. Можно указать только одну пару «LBA Address» и «Number of Logical Blocks».
Также не стоит забывать, что команда WRITE SAME это в первую очередь команда для записи данных. В том случае, если бит unmap не установлен, система хранения не поддерживает thin provisioning или том толстый, то будет выполнена обычная операция записи данных по заданным LBA. Из этого следует, что в данных случаях SCSI READ обязан вернуть именно те данные, которые туда были записаны. Тут некоторые производители вроде того же Хьюлета хитрят и вместо последовательной записи однотипных данных (например нулей) помечают в метаданных логического тома эти блоки как выделенные но «заполненные нулями». Называется эта технология – zero detection.
Как работает и зачем нужен thin provisioning-05
Это сервисная операция (специфичная для устройства) и она использует код команды SERVICE ACTION IN (9Eh). Она позволяет узнать серверу: 1. Поддерживает ли том thin provisioning. 2. Статус определенного блока на системе хранения (выделены ли для него реальные ёмкости на бекэнде или нет). 3. Гранулярность thin provisioning для тома. 4. Лимиты (тревожный уровень и максимальный объем).
Команда очень полезна например для фонового поиска со стороны хоста блоков, выделенных на массиве, но не используемых хостом для хранения данных или при переезде с толстых томов на тонкие.



















 В этом году исполняется 10 лет с момента продажи первой системы хранения данных 3PAR с технологией Thin Provisioning. И несмотря на то что технология стала очень популярной и востребованной, толкового описания того как же это работает на низком уровне мне встретить до сих пор не удалось. В этой статье я попробую осветить наиболее «темные», на мой взгляд, стороны thin provisioning – технические основы данной технологии. То есть, то как именно хост взаимодействует с системой хранения данных. Эти технологии сейчас уже не являются эксклюзивом 3PAR, так как теперь это индустриальные стандарты, но так как технология thin provisioning впервые появилась в 3PAR, то позволю себе отдать все лавры именно этим массивам.
В этом году исполняется 10 лет с момента продажи первой системы хранения данных 3PAR с технологией Thin Provisioning. И несмотря на то что технология стала очень популярной и востребованной, толкового описания того как же это работает на низком уровне мне встретить до сих пор не удалось. В этой статье я попробую осветить наиболее «темные», на мой взгляд, стороны thin provisioning – технические основы данной технологии. То есть, то как именно хост взаимодействует с системой хранения данных. Эти технологии сейчас уже не являются эксклюзивом 3PAR, так как теперь это индустриальные стандарты, но так как технология thin provisioning впервые появилась в 3PAR, то позволю себе отдать все лавры именно этим массивам.