Выполнение тестов вручную
Azure Test Plans | Azure DevOps Server 2020 | Azure DevOps Server 2019 | TFS 2018-2015
Выполните ручные тесты и запишите результаты тестов для каждого шага с помощью Microsoft Test Runner. При обнаружении проблемы при тестировании используйте Test Runner, чтобы создать ошибку. Шаги теста, снимки экрана и комментарии автоматически включаются в ошибку. Вы можете использовать веб-средство запуска для веб-приложений или классическое средство для сбора данных для настольных приложений.
Предварительные требования
Дополнительные сведения см. в разделе доступ к тестам и разрешения вручную.
Запуск тестов для веб-приложений
Выберите тест из набора тестов и выполните его.

Приложение Microsoft Test Runner открывается и запускается в новом браузере.
Запустите тестируемое приложение. Приложение не нужно запускать на том же компьютере, что и средство запуска тестов. Вы просто используете средство выполнения тестов, чтобы записывать шаги теста, пройденные или не пройденные, при ручном выполнении теста. например, можно запустить средство запуска тестов на настольном компьютере и запустить приложение для хранения Windows 8, которое тестируется на Windows 8 планшете.

Сравнив результаты с ожидаемыми, пометьте шаги теста как пройденные или не пройденные. В случае сбоя шага теста можно ввести комментарий по причине сбоя или сбор диагностических данных для теста.

Любой шаг теста, который имеет ожидаемый результат, называется проверочным этапом проверки. Если тест проверочный, тест-инженеры должны отмечать шаги теста состояниями. Общий результат тестового случая отражает состояние всех шагов теста, отмеченных тест-инженером. Таким образом, тестовый случай окажется в состоянии «непройденный», если тест-инженер отметил любой шаг теста как «непройденный» или не отметил его вообще.
Создайте ошибку, чтобы описать компонент, в котором произошел сбой.

Шаги и свои комментарии добавляются к ошибке автоматически. Кроме того, тестовый случай связывается с ошибкой.
Если средство запуска тестов выполняется в окне веб-браузера, можно скопировать снимок экрана из буфера обмена непосредственно в ошибку.
Можно посмотреть все ошибки, о которых вы сообщили во время сеанса тестирования.

После выполнения всех тестов сохраните результаты и закройте Test Runner. Все результаты теста хранятся в Azure DevOps. Разделы справки возобновить тестирование или выполнить один или несколько тестов еще раз?
Просмотрите состояние тестирования для набора тестов. Вы увидите самые последние результаты для каждого теста.


Запуск тестов для классических приложений
Если вы хотите получить дополнительные диагностические данные для приложения для настольных систем, выполните тесты с помощью клиента средства запуска тестов:


Убедитесь, что клиент Runner Test доступен для вашей платформы. В настоящее время клиент Runner Test доступен только для x64.
Удобный BDD: SpecFlow+TFS
В сети есть много статей о том как использовать SpecFlow, как настраивать TFS для запуска тестов, но нет ни одной которая содержала бы в себе все аспекты. В статье я расскажу, как можно сделать запуск и редактирование сценариев SpecFlow удобным для всех.
Под катом вы узнаете как получить:
Предыстория
Перед нами встала задача автоматизировать тестирование приложения используя BDD подход. Так как основой системой таск-трекинга в нашей компании является TFS, в моей голове сложилась картина, где шаги сценария SpecFlow — это шаги тесткейсов в TFS, а запуск тестов осуществляется из тест-планов. Далее о том как я это реализовал.
Что нам потребуется:
Настройка
1. Создание сборки проекта с тестами
Здесь всё просто, сборка и публикация артефактов. О третьем таске подробнее дальше.

2. Создание релиза для запуска тестов
Создаём релиз с одним таском — Visual Studio Test

В данном случае таск настроен для запуска тестов вручную из тест плана
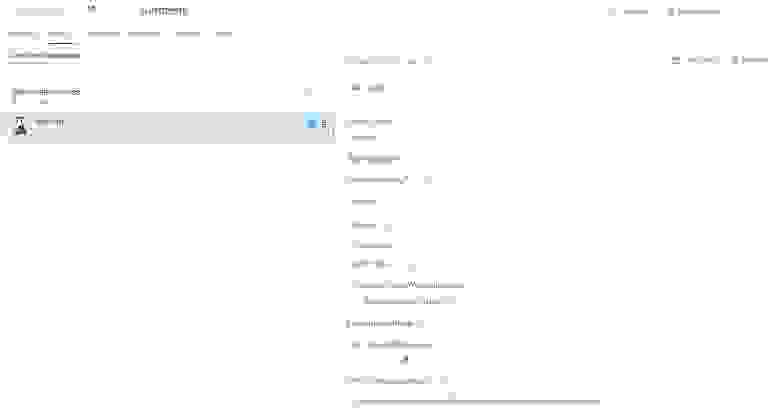
3. Синхронизация тесткейсов
Мы знаем, что Visual Studio позволяет линковать тестовые методы к тесткейсам в TFS и запускасть их из тест-планов. Для того чтобы не делать это вручную, а так же, для того чтобы синхронизировать содержание сценариев, я написал простое консольное приложение FeatureSync. Принцип прост — парсим feature файл, и с помощью API TFS обновляем тесткейсы.
Как использовать FeatureSync
Добавляем namespace и локаль в заголовок feature файла:
Создаём пустые тесткейсы в TFS и добавляем теги с их id к сценариям:

Запускаем FeatureSync:
В нашем случае запуск происходит после сборки проекта с тестами:

Результат синхронизации
Синхронизированы шаги SpecFlow сценария и проставлен статус Automation
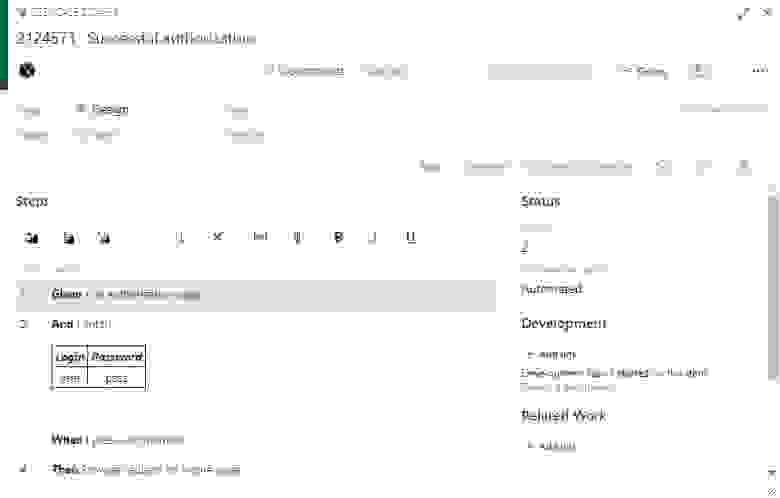

4. Настройка тест-плана
Создаём тест-план, добавляем в него наши автоматизированные кейсы, в настройках выбираем сборку и релиз
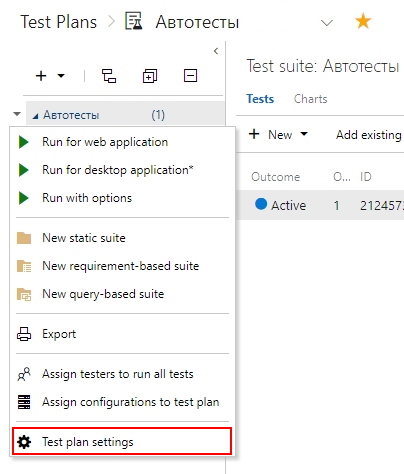

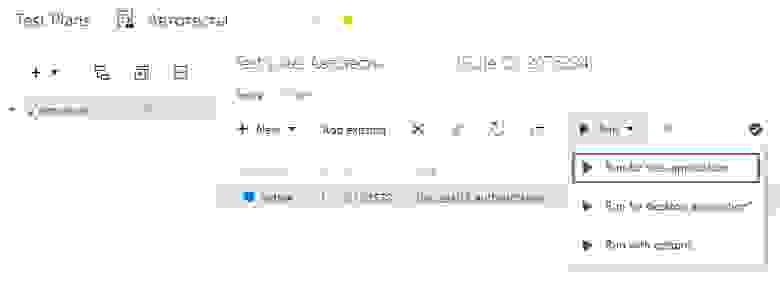
5. Запуск тестов
Выбираем необходимый тест в тест-плане и запускаем.
Заключение
Плюсы такого конфига:
Как менеджеру проектов выжать максимум из дашбордов в TFS
Если вы когда-нибудь использовали проектную аналитику, то наверняка в какой-то момент разочаровывались в этом инструменте. Многие PM-ы со временем забрасывают дашборды, потому что данные оказывается сложно применить для пользы дела. Мы тоже через это прошли и теперь хотим поделиться опытом – как превратить проектную аналитику в действительно удобный инструмент.
Рассказывать будем на примере TFS, который с этого года используют все наши команды. В разное время мы перебрали разные системы управления проектами, и в итоге поняли, что именно TFS объединяет в себе практически всё, что нужно разработчику: управление проектом, репозиторий кода, управление сборками, тестами и релизами.
И, возвращаясь к нашей теме, здесь есть дашборды, которые позволяют отслеживать динамику команд, качество релизов, отработку багов. Одни встроены в систему по умолчанию, другие можно настроить руками.
Чтобы аналитика оказалась действительно полезной, она должна выполнять следующие условия:
1. Ещё до появления дашборда вы уже собирали эти данные вручную, а новая панель лишь автоматизирует эту работу.
2. Дашборд описывает реальные процессы внутри команды, которые имеют прямое отношение к её эффективности.
3. Аналитика даёт реальное понимание о ситуации, проблемах и рисках, а не просто показывает, какие все молодцы.
4. Выводы можно масштабировать на другие команды и проекты – у всех появляется единая система координат.
Теперь расскажем про возможности TFS в этом отношении.
Мы спросили наших PM-ов, какие данные из базового набора они используют в своих панелях, и получили следующий список:
· Lead Time. Показывает время прохождения одной задачи через весь процесс – от создания до закрытия.
· Cycle Time. Показывает время, которое задача находится в разработке с того момента, как ей начали заниматься, до конечной поставки.
· Качество поставок. Это количество багов, которые были заведены и прошли проработку в рамках спринта. При нажатии на график можно посмотреть, что это за баги, фильтр позволяет их сортировать (например, можно ввести «спринт 64» и получить всё, что к нему относится).
Эти показатели дают примерное представление о том, как обстоят дела в команде. Как это часто бывает с базовыми фичами, весь потенциал аналитики они не раскрывают. Например, Lead Time – вроде бы полезный показатель, который показывает, сколько задача висит в бэклоге. Но вот если ваши разработчики, как и мы сами, заводят задачи на несколько спринтов вперёд, ценность этих цифр оказывается небольшой. Можно поставить себе цель – приблизить Lead Time к длительности спринта. Но получается, что вы подстраиваете свои процессы под дополнительный инструмент – зачем это делать, если всё и так работает? Поэтому команды в итоге и отказываются от дашбордов, которые оказываются пятым колесом в прекрасно едущей повозке.
С другой стороны, в TFS можно настроить дополнительные панели, чтобы получать аналитику именно в том ключе, который нужен PM-у.
Так что у каждого PM-а будет свой набор дашбордов, которые нужны именно ему. Для общего представления о том, с какими данными можно так работать, вот несколько примеров из нашего опыта:
· Незавершённые задачи по текущему спринту. Помогает быстро понять, на чём сосредоточить усилия, чтобы всё успеть.
· Задачи, не прошедшие ревью. Сюда попадают работы, которые могут попасть проблемную категорию из-за того, что команда слишком поздно или некорректно оценит нужные ресурсы.
· Незакрытые задачи на PROD. Это уже переданные заказчику задачи, которые по какой-то причине остаются висеть в списке. Для PM-а это повод связаться с клиентом и узнать, нет ли с этими тасками каких-то проблем.
· Высокая оценка в спринте. Это задачи с трудозатратами более 40 человекочасов, к которым явно требуются особое внимание.
· Новые задачи в активном спринте. Помогает бороться с появлением несогласованных работ поду спринта.
Каждый пункт в этом списке – это потенциальный риск, который PM-у очень важно не пропустить. Окно с аналитикой становится рабочим местом, с которого можно начинать свой день. Пока окошки не горят красным, всё хорошо.
· PM-у не нужно совершать лишние движения, чтобы получить представление о положении дел по спринту. Менеджеры получили удобный доступ к данным, за которыми раньше приходилось идти в разные системы.
· Если назревают трудности, специальный алёрт заранее о них предупредит. Появляется тревожный сигнал – можно его сразу отработать, пока он не вырос в реальную проблему.
· Повысилось качество управления – стали дробить PBI на более мелкие таски, ускорили выдачу релизов. Здесь, кстати, помог дашборд Cycle Time из базового набора, так что вовсе отказываться от них не стоит.
· Не только PM, но и другие участники команды пользуются аналитикой – все говорят на одном языке и знают, какие показатели играют важную роль для релиза. Эти технологии можно легко масштабировать дальше, чтобы вся компания работала по единым успешным практикам.
Тестирование с инструментами Microsoft — полевой опыт
Эта статья создана нашими друзьями, партнерами из компании Лаборатория Касперского и описывает реальный опыт использования инструментов тестирования от Microsoft с рекомендациями. Автор — инженер по тестированию в Лаборатории Касперского, Игорь Щегловитов.
Привет всем. Я работаю инженером по тестирования в Лаборатории Касперского в команде, занимающейся разработкой серверной облачной инфраструктуры на облачной платформе Microsoft Azure.
Команда состоит из разработчиков и тестировщиков (примерно в соотношении 1 к 3). Разработчики пишут код на C# и практикуют TDD и DDD, благодаря этому код получается пригодным для тестирования и слабосвязанным. Тесты, которые пишут разработчики, запускаются либо вручную из Visual Studio, либо автоматически при сборке билда на TFS. Для запуска билда у нас установлен триггер Gated Check-In, таким образом он запускается при чекине в Source Control. Особенностью данного триггера является, то что если по каким-то причинам (будь то ошибка компиляции либо тесты не прошли) билд падает, то сам чекин, который запустил билд не попадает в SourceControl.
Вы, наверное, сталкивались с утверждением, что код протестировать сложно? Некоторые прибегают к парному программированию. В других компаниях специально выделены отделы тестирования. У нас же это обязательное код-ревью и автоматизированное интеграционное тестирование. В отличие от модульных — интеграционные тесты разрабатываются специально выделенными инженерами по тестированию, к которым отношусь и я.
Клиенты взаимодействуют с нами через удаленное SOAP и REST API. Сами сервисы основаны на WCF, MVC, данные же хранятся в Azure Storage. Для надежности и масштабирования длительных бизнес-процессов используются Azure Service Bus и Azure Cloud Queue.
Немного лирики: есть мнение, что тестировщик — это некая ступень, чтобы стать разработчиком. Это не совсем так. Грань между программистами и инженерами по тестированию с каждым годом исчезает. Тестировщики должны обладать большим техническим бекграундом. Но в то же время иметь несколько иное мышление, нежели разработчики. Тестировщики должны быть нацелены на разрушение в первую очередь, разработчики же на создание. Вместе же они должны стараться сделать качественный продукт.
Интеграционные тесты, также как и основной код, разрабатываются на C#. Имитируя действия конечного потребителя, они проверяют бизнес процессы на сконфигурированных и запущенных сервисах. Для написания этих тестов используется Visual Studio и фреймворк MsTest. Разработчики используют то же самое. В процессе тестировщики и разработчики производят взаиморевью кода, благодаря чему члены команды могут всегда говорить на одном языке.
Тестовые сценарии (тест-кейсы) живут и управляются через MTM (Microsoft Test Manager). Тест кейс в данном случае — такая же сущность TFS, как баг или таск. Тест-кейсы бывают ручными или автоматическими. В связи со спецификой нашей системы, мы используем только вторые.
Автоматические тест кейсы связываются по полному CLR наименованию с тестовыми методами (один кейс — один тестовый метод). До момента появления MTM (Visual Studio 2010) я запускал тесты как модульные, ограничиваясь студией. Было сложно строить отчеты по тестированию, управлять тестами. Теперь это делается напрямую через MTM.
Появилась возможность объединять тест кейсы в планы тестирования, а внутри планов строить плоские и иерархические группировки через TestSuite.
У нас Feature Branch разработка, т.е. крупные доработки делаются в отдельных ветках, стабилизационных и релизных. Под каждую ветку у нас создан тест план (чтобы избежать хаоса). После завершения стабилизации в Feature Branch ветке, в основную ветку переносится код, а тесты переносятся в соответствующий ей тест план. Тест-кейсы очень легко добавлять в тест-планы (Ctrl+C Ctrl+V, либо через TFS query).
Немного рекомендаций. Лично я стараюсь для каждой ветки разделять стабильные тесты от новых. Это легко делать через TestSuite. Особенность здесь в том, что стабильные (или регрессионные) тесты должны проходить на 100%. Если у вас не так, то стоит задуматься. Ну, а после того, как новый функционал становится стабильным, то соответствующие ему тесты просто переносятся в регрессионный Test Suite.
Лично для меня одним из самых скучных и рутинных процессов было создание тест-кейсов. Процесс разработки автотестов у всех разный. Кто-то в начале пишет подробные тестовые сценарии, а потом на основе создает авто тесты. У меня наоборот. Я пишу в коде (в тестовом классе) тесты-пустышки (без логики). Потом уже идет реализации логики, архитектуры компонент тестирования, тестовых данных и так далее.
После того как тесты созданы, их надо перенести в TFS. Одно дело, когда тестов штук 10, а если 50 или 100, придется потратить кучу времени на рутинное заполнение шагов, связывания каждого нового тест-кейса с тестовым методом.
Для упрощение данного процесса Microsoft придумал утилиту tcm.exe, которая умеет автоматически, создавать тестовые сценарии в TFS и включать в план тестирования. Данная утилита имеет ряд недостатков, в один тест план почему-то нельзя добавить тесты из разных сборок или для тест-кейса нельзя задать шаги и нормальное название. Кроме того, сама утилита появилась сравнительно недавно. Когда ее еще не было — мы создали самописную утилиту которая автоматизирует процесс создания тестовых сценариев. Также разработаны специальные кастомные атрибуты TestCaseName и TestCaseStep, для задания имени и шагов тестового сценария.
Сама утилита может как обновлять, так и создавать тестовые сценарии, включать в нужный план. Утилита может работать в silent режиме, ее запуск включен в Worfklow TFS билда. Таким образом она запускается автоматически сама и добавляет либо обновляет существующие тестовые сценарии. В результате мы имеем актуальный тест-план.
Статус прогона тестов в тест-плане (что эквивалентно качеству кода) виден в специальных отчетах. В TFS есть набор шаблонов готовых отчетов, которые на основе данных OLAP кубов строят диаграммы по статусам тест кейсов и тест планов. Но у нас отчет самописный и упрощенный. Мы сделали его таким, чтобы каждый, кто на него бы ни посмотрел, сразу все понял.

Особенностью отчета является то, что он строится не на основе кубов, которые перестраиваются не синхронно и могут содержать еще не актуальные данные, наш отчет использует данные, которые подтягиваются напрямую через МТМ API. Таким образом мы в любой момент времени получаем актуальный статус плана тестирования.
Отчет строится в HTML формате и рассылается на всю команду через SmtpClient. Делается это все с помощью простой утилиты, запуск которой включен прямо в Workflow билда: скачать утилиту.
Кроме управления тестовыми сценариями, МTM используется и для управления окружениями тестирования и настройкой агентов, запускающих тесты. Чтобы ускорить выполнение тестов (здесь идет речь о тестах, проверяющих длительные асинхронные бизнес процессы) мы используем 6 агентов тестирования, т.е. за счет горизонтального масштабирования агентов у нас достигается параллельность выполнения тестов.
Сами по себе интеграционные авто тесты можно вручную запускать как через MTM, так и через Visual Studio. Но ручной запуск происходит во время отладки (либо тестов, либо кода). У нас в команде почти на каждый баг заводится воспроизводящий тест. Далее баг вместе с тестом передается в разработку. И разработчикам проще смоделировать проблемную ситуацию и исправить ее.
Теперь о процессе регресса.
В нашем проекте есть специальный билд, который инициирует полный прогон тестов, он запускается по триггеру как Rolling Build. Т.е., если прошел успешно быстрый Gated Checkin билд, то запускается Rolling Build. Особенность данного билда – в один момент времени собирается максимум один билд.
Начало данного билда такое же, как и у предыдущего — сбор последних версий тестового и основного проекта, и далее следует прогон модульных тестов.
Если все прошло успешно, то запускаются специально написанные Power Shell скрипты, которые деплоят пакет собранных сервисов в Azure. Для управлением деплоем используется REST API Azure. Сам деплой осуществляется на промежуточное развертывание облачной службы. Если деплой прошел успешно и роль запускается без ошибок, то стартую скрипты проверки конфигурации. Если все хорошо, то происходит переключение ролей (промежуточное развертывание становится основным) и запускаются сами интеграционные тесты.
После прогона тестов на всю команду рассылается письмо, которое содержит отчет о статусе выполнения тестов.
Прежде чем писать тесты, классические модульные, так и интеграционные я рекомендую ознакомиться с книгами The Art of Unit Testing и xUnit Test Patterns: Refactoring Test Code
Эти книги (лично я люблю первую), содержат большое число советов и приемов, как надо и не надо писать тесты на любом xUnit фреймворке.
Я бы хотел закончить свою статью перечислением основных принципов написания кода авто-тестов в нашей команде:
Как мы автоматизируем тестирование с помощью управления выпусками — Часть 1
В ноябре 2015 г. мы открыли доступ к версии службы Release Management для публичного тестирования в Visual Studio Team Services. Материалы этого блога помогут Вам быстро начать использовать весь комплекс возможностей RM. Документация MSDN, доступная здесь, позволит Вам глубоко разобраться в сценариях и концепциях RM.
Вы можете использовать службу RM в двух сценариях: для внедрения кода на нескольких используемых средах и для выполнения тестов при разработке продукта. В этой публикации я расскажу о втором сценарии, а именно о том, как мы (группа разработчиков службы RM корпорации Microsoft) автоматизируем тестирование с помощью RM. Уже в течение семи месяцев мы используем RM для тестирования, за что я благодарю мою коллегу Лову (Lova).
Я разделил эту статью на две части. Первая часть представляет собой общее описание нашего опыта процесса комплексной автоматизации тестирования. Во второй части речь пойдет о некоторых проектных решениях, проблемах, с которыми мы столкнулись в процессе автоматизации тестирования, и способах решения этих проблем.
Обзор и общее описание
VSTS состоит из нескольких единиц масштабирования (scale units, SU), обеспечивающих такие службы, как управление версиями, сборка, управление выпусками, отслеживание рабочих элементов и др. Все группы, участвующие в разработке и применяющие инструменты VSTS, используют SU0 в своей повседневной работе. Таким образом, SU0 является «рабочим вариантом». Как правило, группы сначала развертывают новый код в SU0 и передают его в другие единицы масштабирования лишь после того, как поэкспериментируют с ним в течение некоторого времени.
Аналогичным образом группа RM использует службы SU0 в своей повседневной работе. Мы ведем разработку (дополняем код и вносим исправления) в функциональной ветви TF Git под названием features/rmmaster, собираем код с помощью службы Build и тестируем его с помощью службы RM.
Настройка «непрерывного конвейера автоматизации»
Имя нашей CI-сборки непрерывной интеграции — VSO.RM.CI. Сборка публикует единственный артефакт под названием «drop», который содержит в себе все двоичные файлы, созданные в результате ее выполнения.
Мы связываем это определение сборки с набором определений выпуска с помощью свойства триггера определения выпуска. Другими словами, каждое определение выпуска, выделенное ниже, активизируется автоматически по окончании сборки VSO.RM.CI.
(Обратите внимание на то, что каждое определение выпуска имеет единственную среду. Мы были вынуждены использовать девять определений выпуска, поскольку RM не поддерживает параллельное выполнение сред. Такая функция появится в ближайшее время. Когда это произойдёт, мы объединим девять определений выпуска в одно определение выпуска с девятью параллельно выполняющимися средами, что улучшит отслеживаемость сборок).
Общая идея заключается в том, что каждое определение выпуска загружает двоичные файлы, необходимые для его тестирования, настраивает тестовую среду, удаляя старые и развертывая новые двоичные файлы (зависимые службы и тестовые библиотеки DLL), выполняет тесты с помощью задачи VsTest (которая также публикует результаты, что упрощает подготовку отчетов и последующий анализ) и еще раз очищает среду. Позже я подробнее рассмотрю устройство определения выпуска в этом блоге.
Процесс обработки кода и публикации теста схематически выглядит следующим образом: 
Настройка пула агентов
Для того чтобы приступить к выполнению задач, необходимо сначала настроить агент сборки/выпуска для нашей CI-сборки непрерывной интеграции и определений выпуска. Обычно на одних серверах сначала запускаются задачи в пуле агента сборки/выпуска для развертывания служб RM/SPS/TFS, а на других серверах выполняются тесты для этих задач. В данном случае мы решили развернуть службы на агентском компьютере, чтобы одновременно использовать несколько экземпляров одного теста.
Каждый тест имел свои собственные требования, что не позволяло использовать размещаемый пул агентов. По этой причине мы создали единственный пул агентов с названием RMAgentPool. Мы подготовили отдельные компьютеры для каждого определения выпуска RM.CDP.*, установили агент сборки/выпуска на каждый из них и добавили эти компьютеры в пул RMAgentPool.
(Для этого мы скачали агента на каждый тестовый компьютер с помощью ссылки «Download agent» («Скачать агент»), выделенной на приведенном ниже рисунке). Мы распаковали zip-файл агента и настроили его, указав нашу учетную запись в параметре «URL for Team Foundation Server» («URL-адрес для Team Foundation Server»), например: https://OurAccount.visualstudio.com).
Каждому компьютеру была предоставлена новая возможность пользователя с названием «RmCdpCapability». Значение этого параметра определяло предназначение компьютера: например, на компьютерах, подготовленных для сборок непрерывной интеграции, использовался параметр RmCdpCapability=CI.
Еще один пример: Для агента, на котором выполнялось определение выпуска RM.CDP.TfsOnPrem, использовался параметр «RmCdpCapability=TfsOnPrem».
Затем определения выпуска использовали параметр RmCdpCapability как требование для того, чтобы тесты выполнялись на подходящих агентах.
Обзор определений выпуска RM.CDP.*
Разработка определения выпуска RM.CDP.*
Анализ результатов тестирования
По мере внесения изменений разработчиками, мы можем легко определить, чьи изменения стали причиной сбоев. Например, на представленном ниже снимке экрана тестирование стало завершаться неудачно после сборки VSO.RM.CI_rmmaster_20151231.5. Дважды щелкнув по выделенному выпуску, мы открываем страницу Release Summary (Сводка выпуска):
Затем мы переходим в раздел Test Results (Результаты тестирования) страницы Release Summary (Сводка выпуска) и видим, что после этой проверки два теста пользовательского интерфейса стали завершаться неудачно. Щелкнув по выделенной ниже ссылке на тест, мы попадаем в раздел Test (Тест):
Вложенная вкладка Test Results (Результаты теста) дает нам ценную исходную информацию для подробного анализа проблем:
Журналы тестов доступны во вложенной вкладке Run summary (Сводка выполнения).
Мы можем получить более подробную информацию о фиксациях этого выпуска, чтобы определить их возможную связь с регрессом, с помощью вкладки Commits (Фиксации) страницы Release Summary (Сводка выпуска). Например, приведенный ниже снимок экрана показывает, что некоторые изменения пользовательского интерфейса в данной проверке могли стать причиной двух неудачных тестов.
Преимущества тестирования с помощью RM
(В ближайшие несколько месяцев эта возможность станет более интегрирована со страницей Release Summary (Сводка выпуска).
Заключение
Вначале мы использовали RMO при тестировании процессов разработки только для того, чтобы понять его возможности. С течением времени мы пришли к выводу, что эффективность RMO существенно выше, чем у тестовой инфраструктуры, которой мы пользовались ранее. Разработчикам нравится, что они могут тестировать крупные изменения без трудоемкой настройки локальной тестовой среды.
Теперь Вы имеете представление о том, как группа разработчиков RM использует RM для автоматизации тестирования. Мы надеемся, что наш опыт подскажет Вам идеи, как автоматизировать процесс тестирования.
Во второй части этого статьи речь пойдет о некоторых проектных решениях, проблемах, с которыми мы столкнулись в процессе организации управления выпусками и способах решения этих проблем.