Рекомендательная система: text mining как средство борьбы с холодным стартом
Предварительная обработка текстового контента (preprocessing)
Как мы уже обсуждали, предварительная обработка текста веб-страницы заключается в выделении полезного контента страницы, отброса стоп-слов и лемматизации. Этот стандартный «джентльменский» набор так или иначе появляется почти во всех задачах text mining, и его можно найти во многих уже готовых программных решениях, подобрав то, что нужно для вашей конкретной прикладной задачи и среды разработки.
Итак, первым шагом в предварительной обработке текстов является построение словаря всех различных слов W, встречающихся в корпусе текстов D, и подсчёт статистики встречаемости этих слов в каждом из документов. Сразу обращу внимание, что все описанные в этой статье методы будут опираться на модель «мешка слов», когда порядок следования слов в тексте не учитывается. Контекст слова может быть учтён на этапе лемматизации. Например, в предложении «мы ели землянику, а вдоль опушки росли раскидистые ели», слово «ели» в первом случае нужно лемматизировать как «есть», а во втором — как «ель». Однако учтите, что поддержка контекста при лемматизации — это сложная задача natural language processing, далеко не все лемматизаторы к этому готовы. При дальнейшем же анализе порядок слов не будет учитываться вовсе.
TF-IDF (TF — term frequency, IDF — inverse document frequency)
Следующим шагом в обработке текстов является расчет весов TF-IDF для каждого слова w в каждом документе d: 
где — число вхождений слова в документ, — общее число слов в данном тексте; ,
где |D| — число текстов в корпусе, а — число текстов, в которых встречается w. Теперь .
Или несколько усложненный вариант: ,
где .
Веса TF-IDF нужны для достижения двух целей. Во-первых, для слишком длинных текстов отбираются только слова с максимальным TF-IDF, а остальные отбрасываются, что позволяет сократить объём хранимых данных. Например, для методов relevance feedback и LDA, которые будут описаны ниже, нам было достаточно брать N=200 слов c максимальными весами TF-IDF. Во-вторых, эти веса будут в дальнейшем использованы для рекомендаций в алгоритме relevance feedback.
Релевантная обратная связь (relevance feedback, RF)
Алгоритм relevance feedback вплотную подводит нас к решению исходной задачи и предназначен для построения рекомендаций на основе текстового контента страниц и лайков пользователя (но без учёта лайков веб-страниц). Сразу оговорюсь, что алгоритм пригоден для рекомендаций новых сайтов, но существенно проигрывает традиционным методам коллаборативной фильтрации при наличии достаточного количества лайков (10-20 лайков и больше).
Первым шагом алгоритма является автоматический поиск ключевых слов (тегов) для каждого пользователя по истории его рейтингов (лайков). Для этого рассчитываются веса всех слов из веб-страниц, которые рейтинговал пользователь: ,
где — все веб-страницы, которые лайкал/дизлайкал пользователь, — рейтинг, который проставил пользователь. В качестве профиля пользователя выбирается заданное количество слов с максимальным весом (например, 400 слов).
Расстояние от пользователя до сайта рассчитывается как скалярное произведение векторов весов слов пользователя и сайта: ,
где — слова из профиля пользователя.
В результате алгоритм позволяет оценить сходство любого пользователя, у которого есть лайки, и любой веб-страницы, у которой есть текстовый контент. Кроме того, алгоритм достаточно прост в реализации и позволяет строить интерпретируемый профиль пользователя, состоящий из ключевых тегов его интересов. При регистрации можно просить пользователя указать свои ключевые интересы, что даст возможность делать рекомендации и для новых пользователей.
Латентное распределение Дирихле (latent Dirichlet allocation, LDA)
Метод LDA в нашем блоге уже достаточно подробно описывал Сергей Николенко. Алгоритм предназначен для описания текстов с точки зрения их тематик. Основное предположение модели LDA состоит в том, что каждый документ имеет несколько тематик, смешанных в некоторой пропорции. LDA — это вероятностная модель порождения текста, обучение которой позволяет выявить для каждого документа вероятностное распределение по тематикам, что в дальнейшем позволяет решать ряд прикладных задач, в том числе задачу рекомендаций.
Спецификой нашей задачи является наличие категорий для каждой веб-страницы и для каждого пользователя (всего категорий 63). Возникает вопрос: как согласовать полученные LDA-топики с известными категориями? Если обучать LDA без учета разделения на категории, то нужно брать достаточно большое количество топиков (более 200), иначе топики LDA фактически повторяют категории, и результатом работы алгоритма является разделение по тем же категориям (музыка, наука, религия и т.д.), которое нам и так известно. Сквозное обучение может быть полезно для задачи выявления ошибок классификации по категориям и рекомендации категорий для новых сайтов. Для рекомендаций же лучше обучать LDA по каждой категории отдельно с небольшим количеством LDA-топиков (5-7) на каждую категорию. В этом случае получается автоматическое разделение каждой категории на подкатегории, примерно вот так:
После того как получены LDA-топики для всех сайтов, можно строить рекомендации для каждого из пользователей. Для этого для каждого пользователя обучается логистическая регрессия на LDA-топиках сайтов, которые он рейтинговал. Положительным событием здесь является лайк, отрицательным — дизлайк. Длина вектора параметров регрессии для пользователя равна произведению числа LDA-топиков на число категорий, которые когда-либо были отмечены у пользователя в профиле (если пользователь отключил категорию в своем профиле, то информация по его предпочтениям в этой категории не потеряется). Рекомендация строится на основе оценки вероятности лайка по обученным параметрам регрессии пользователей и LDA-топикам сайтов стандартным образом.
Подведем итоги
Поэтому оптимальным представляется комбинация этих двух методов. Оба они действуют на этапе «раскрутки» новых страниц (до тех пор, пока сайт не набрал достаточно лайков, чтобы коллаборативная фильтрация смогла работать в полную силу). Если у страницы весь контент — это 5-10 слов (например, у страницы с фотографиями часто весь текстовый контент — это заголовок или подпись к картинке), то целесообразно использовать RF, в противном случае LDA. Для перечисленных выше дополнительных задач без топиков LDA не обойтись.
Удачи в дальнейшем изучении методов text mining!
Полное руководство о том, как работает Text Mining
Введение в разработку текстов
Что такое Text Mining
Text Mining также известен как Text Analytics. Это процесс понимания информации из набора текстов. Text Mining разработан, чтобы помочь бизнесу найти ценные знания из текстового контента. Это содержимое может быть в форме текстового документа, электронной почты или сообщений в социальных сетях.
Преимущества Text Mining
Есть много преимуществ использования Text Mining. Они перечислены ниже
Использование Text Mining
Важность текстового майнинга
Приложения Text Mining
Анализ ответов открытого опроса
Открытые вопросы опроса помогут респондентам высказать свое мнение или мнение без каких-либо ограничений. Это поможет узнать больше о мнениях клиентов, чем полагаться на структурированные анкеты. Анализ текста может быть использован для анализа такой информации в виде текста.
Автоматическая обработка сообщений, писем
Text Mining также в основном используется для классификации текста. Text Mining может использоваться для фильтрации ненужной почты, используя определенные слова или фразы. Такие письма будут автоматически отбрасывать такие письма для спама. Такая автоматическая система классификации и фильтрации выбранных писем и отправки их в соответствующий отдел осуществляется с помощью системы Text Mining. Text Mining также отправит пользователю электронной почты предупреждение об удалении писем с такими оскорбительными словами или контентом.
Анализ гарантийных или страховых претензий
В большинстве коммерческих организаций информация собирается в основном в виде текста. Например, в больнице интервью с пациентами можно кратко изложить в текстовой форме, а отчеты также в виде текста. Эти заметки теперь собираются в электронном виде за один день, чтобы их можно было легко перенести в алгоритмы интеллектуального анализа текста. Эти записи затем могут быть использованы для диагностики реальной ситуации.
Расследование конкурентов путем сканирования их веб-сайтов
Другой важной областью применения Text Mining является обработка содержимого веб-страниц в определенном домене. Таким образом, система интеллектуального анализа текста автоматически найдет список терминов, которые используются на сайте. Таким образом, вы можете узнать наиболее важные термины, используемые на сайте. Таким образом можно узнать о возможностях конкурентов, которые помогут вам эффективно вести бизнес.
Другие приложения Text Mining включают в себя следующее
Методы, используемые в Text Mining
В системе Text Mining используются пять основных технологий. Они подробно обсуждаются ниже
Извлечение информации
Это используется для анализа неструктурированного текста путем нахождения важных слов и выявления связей между ними. В этой технике процесс сопоставления с образцом используется для определения порядка в тексте. Это помогает в преобразовании неструктурированного текста в структурированную форму. Техника извлечения информации включает в себя модули языковой обработки. Это в основном используется там, где имеется большой объем данных. Процесс извлечения информации объясняется на рисунке ниже.
Категоризация
Техника категоризации классифицирует текстовый документ по одной или нескольким категориям. Он основан на примерах входных и выходных данных для классификации. Процесс категоризации включает в себя предварительную обработку, индексацию, уменьшение размеров и классификацию. Текст можно классифицировать с использованием таких методов, как наивный байесовский классификатор, дерево решений, классификатор ближайших соседей и машины поддержки поставщиков.
Кластеризация
Визуализация
Техника визуализации используется для упрощения процесса поиска актуальной информации. Этот метод использует текстовые флаги для представления документов или группы документов и использует цвета для обозначения компактности. Техника визуализации помогает отображать текстовую информацию более привлекательным способом. На картинке ниже представлена техника визуализации
Суммирование
Техника суммирования поможет сократить длину документа и кратко изложить детали документов. Это делает документ рабочим чтением для пользователей и сразу понимает его содержание. Суммирование заменяет весь комплект документов. Он суммирует большой текстовый документ легко и быстро. Людям требуется больше времени, чтобы прочитать, а затем обобщить документ, но этот метод делает его очень быстрым. Это помогает выделить основные моменты в документе. Процесс суммирования представлен на рисунке ниже.
Методы и модели, используемые в текстовом майнинге
На основе поиска информации Text Mining имеет четыре основных метода
Метод, основанный на сроках (TBM)
Фразовый метод (PBM)
В этом методе документ анализируется на основе фраз, которые менее очевидны для большего количества значений и более дискриминационны. К недостаткам этого способа относится
Концептуальный метод (CBM)
В этом методе документ анализируется на основе предложения и уровня документа. В этом методе есть три основных компонента. Первый компонент исследует значимую часть предложений. Второй компонент создает концептуальный онтологический граф для объяснения структур. Третий компонент извлекает основные понятия, основанные на первых двух компонентах. Этот метод может различать важные и неважные слова.
Метод таксономической структуры (PTM)
Как работает Text Mining
Теперь вы должны понимать, что анализ текста позволяет лучше понять текст, чем что-либо еще. Система Text Mining осуществляет обмен словами из неструктурированных данных в числовые значения. Анализ текста помогает идентифицировать шаблоны и связи, которые существуют в большом объеме текста. При анализе текста часто используются вычислительные алгоритмы для чтения и анализа текстовой информации. Без интеллектуального анализа текста будет трудно понять текст легко и быстро. Текст может быть получен более систематическим и всеобъемлющим образом, а информация о бизнесе может быть получена автоматически. Шаги в процессе добычи текста перечислены ниже.

Шаг 1: Поиск информации
Это первый шаг в процессе интеллектуального анализа данных. Этот шаг включает в себя помощь поисковой системы, чтобы найти коллекцию текста, также известную как совокупность текстов, которые могут нуждаться в некотором преобразовании. Эти тексты также должны быть собраны в определенном формате, который будет полезен для понимания пользователями. Обычно XML является стандартом для интеллектуального анализа текста.
Шаг 2: Обработка естественного языка
Этот шаг позволяет системе выполнить грамматический анализ предложения для чтения текста. Он также анализирует текст в структурах.
Шаг 3: извлечение информации
Это второй этап, на котором делается определение значения разметки текста. На этом этапе в базу данных добавляются метаданные о тексте. Это также включает добавление имен или местоположений к тексту. Этот шаг позволяет поисковой системе получить информацию и выяснить отношения между текстами, используя их метаданные.
Шаг 4: добыча данных
Text Mining включает в себя следующий список элементов
Проблемы текстового майнинга
Основной проблемой, с которой сталкивается система Text Mining, является естественный язык. Естественный язык сталкивается с проблемой неоднозначности. Двусмысленность означает, что один термин имеет несколько значений, одна фраза интерпретируется по-разному, и в результате получаются разные значения.
Другое ограничение заключается в том, что при использовании системы извлечения информации она включает семантический анализ. В связи с этим полный текст не представлен, только ограниченная часть текста представлена пользователям. Но в наши дни нужно больше понимания текста.
Text Mining также имеет ограничения с законодательством об авторском праве. Есть много ограничений в текстовом анализе документа. В большинстве случаев это включает в себя права владельцев авторских прав. Большинство текстов не будут найдены как открытый исходный код, и в таких случаях требуются разрешения от соответствующих авторов, издателей и других связанных сторон.
Еще одно ограничение заключается в том, что добыча текста не генерирует новых фактов и не является конечным процессом.
Вывод
Анализ текста или анализ текста является быстро развивающейся технологией, но результаты и глубина анализа варьируются от бизнеса к бизнесу. Организация может использовать интеллектуальный анализ текста, чтобы получить знания о конкретных значениях контента.
Text mining что это такое
Основные задачи Text Mining
Как и большинство когнитивных технологий, Text Mining – это алгоритмическое выявление прежде не известных связей и корреляций в уже имеющихся текстовых данных.
Важная задача технологии Text Mining связана с извлечением из текста его характерных элементов или свойств, которые могут использоваться как метаданные документа, ключевых слов, аннотаций.
Другая важная задача состоит в отнесении документа к некоторым категориям из заданной схемы их систематизации. Text Mining также обеспечивает новый уровень семантического поиска документов.
Возможности современных систем Text Mining могут применяться при управлении знаниями для выявления шаблонов в тексте, для автоматического «выталкивания» или размещения информации по интересующим пользователей профилям, создавать обзоры документов.
Основные элементы Text Mining
В соответствии с уже сформированной методологии к основным элементам Text Mining относятся:
Особенность систем Text Mining заключается в том, что количество объектов и их атрибутов может быть очень большой, поэтому должны быть предусмотрены интеллектуальные механизмы оптимизации процесса классификации.
Кластеризация применяется при реферировании больших документальных массивов, определение взаимосвязанных групп документов, упрощения процесса просмотра при поиске необходимой информации, нахождения уникальных документов из коллекции, выявления дубликатов или очень близких по содержанию документов.
• построение семантических сетей,
Построение семантических сетей или анализ связей, которые определяют появление дескрипторов (ключевых фраз) в документе для обеспечения навигации.
• извлечение фактов, понятий (feature extraction),
Извлечение фактов, предназначенное для получения некоторых фактов из текста с целью улучшения классификации, поиска и кластеризации.
• ответ на запросы (question answering),
• тематическое индексирование (thematic indexing),
• поиск по ключевым словам (keyword searching).
Также в некоторых случаях набор дополняют средства поддержки и создание таксономии (oftaxonomies) и тезаурусов (thesauri).
Текстомайнинг
Что такое текстомайнинг
Текстомайнинг (text mining) часто называют также текстовым дейтамайнингом (text data mining), что отчасти раскрывает взаимосвязь двух этих технологий. Если дейтамайнинг позволяет извлекать новые знания (скрытые закономерности, факты, неизвестные взаимосвязи и т.п.) из больших объемов структурированной информации (хранимой в базах данных), то текстомайнинг — находить новые знания в неструктурированных текстовых массивах.
В этом смысле текстомайнинг добавляет к технологии дейтамайнинга дополнительный этап — перевод неструктурированных текстовых массивов в структурированные. После чего данные могут обрабатываться с помощью стандартных методов дейтамайнигнга.
Наиболее простой задачей является текстомайнинг слабоструктурированных узкоспециализированных текстовых массивов (различные отчеты о поломках, результаты опросов и т.п.). В текстовых массивах, где форма документа и набор лексики ограничены, новую информацию можно извлекать, анализируя статистику на уровне отдельных ключевых слов (терминов). Когда мы говорим о неструктурированных текстах, то в общем виде задача сводится к «пониманию» произвольных текстов на естественном языке — это одна из старейших задач искусственного интеллекта (ИИ), которая может решаться с использованием различных технологий, в первую очередь на базе методов обработки данных на естественном языке — NLP (Natural Language Processing), на основе нейросетевых подходов, а также других методов и их комбинаций.
Огромное количество информации скапливается в многочисленных текстовых базах, хранящихся в личных ПК, локальных и глобальных сетях. И объем этой информации стремительно увеличивается. Чтение объемных текстов и поиск в гигантских массивах текстовых данных малоэффективны, поэтому становятся все более востребованными решения текстомайнинга.
Актуальность текстомайнинга растет по мере того, как людям самых разных профессий приходится принимать решения на базе анализа большого объема неструктурированных и слабоструктурированных текстов (рис. 1).
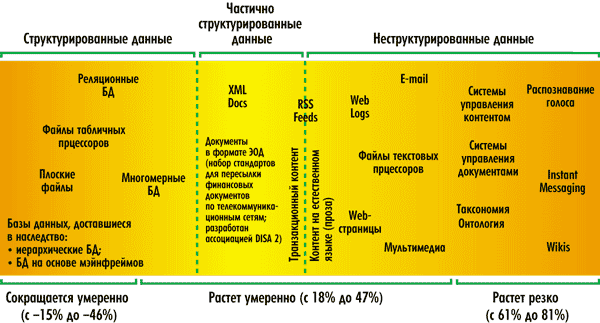
Рис. 1. Ожидаемое снижение/рост данных различной степени структурированности
в ближайшие три года (источник: Businessobjects)
Все более интересным становится анализ общественного мнения, выраженного в Web. В последнее время блогосфера демонстрирует практически троекратный ежегодный рост. Одним из новых направлений текстомайнинга является Opinion Mining (OM) (буквально — раскопка мнений) — технология, которая концентрируется не столько на содержании документа, сколько на мнении, которое он выражает.
Оценить успешность проведенной рекламной кампании, узнать, как к фирме относятся в прессе, — на эти и другие вопросы можно получить ответ с помощью технологии Opinion Mining.
Условно систему текстомайнинга можно разделить на четыре блока (рис. 2). Нижний блок объединяет технологии извлечения и фильтрации поступающих на обработку текстов. Блок над ним отвечает за «понимание» текстов на естественном языке.
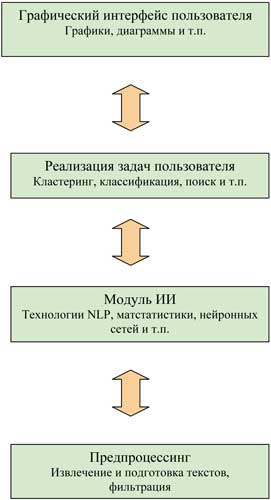
Рис. 2. Структура обобщенной системы
текстомайнинга
В следующем блоке перечислен набор необходимых пользователю задач, каждая из которых требует своего технологического решения. В общем случае набор этих задач может быть весьма широким. К ним следует отнести:
Последний блок объединяет средства, формирующие графический интерфейс пользователя, и является важным компонентом системы. Представленная надлежащим образом информация позволяет человеку увидеть те дополнительные скрытые закономерности, которые не удается выявить другими методами.
В настоящее время предлагается достаточно много инструментов текстомайнинга — от относительно простых программ, опирающихся на статистический анализ отдельных терминов в текстах, таких как WordStat, до сложнейших приложений типа Aerotext и Businessobjects Text Analysis. Далее мы кратко рассмотрим возможности наиболее популярных приложений текстомайнинга.
С развитием Интернета анализ, базирующийся на технологиях текстомайнинга, может реализовываться не только посредством внедряемых в организации приложений, но и в виде онлайнового сервиса. В последнее время текстомайнинговый анализ множественных открытых источников информации становится доступным для коммерческих, политических и других организаций за счет появления именно таких онлайновых служб. Одна из подобных служб — «Медиалогия» — базируется на аппаратно-программном решении компании IBS, о котором тоже пойдет речь в данной статье.
Решения на основе текстомайнинга
WordStat
WordStat (рис. 3) — это программа, которая базируется преимущественно на статистическом анализе слов в слабоструктурированных текстовых документах и позволяет извлекать информацию из инцидент-отчетов, жалобных книг, обрабатывать результаты опросов, разрабатывать таксономии и др.
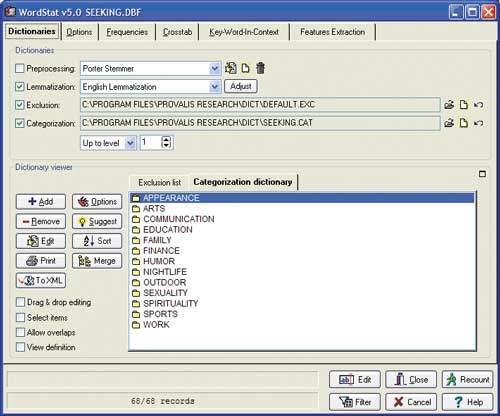
Рис. 3. Интерфейс программы WordStat
Программа предоставляет возможность статистического анализа совместного появления слов в текстовых базах, позволяет проводить иерархический кластерный и другие виды анализа. Обеспечивает развитые средства визуализации данных.
На рис. 4 показаны данные, построенные на основе многочисленных инцидент-отчетов авиакомпании JetBlue Airways. Метод иерархической кластеризации позволяет построить древовидную структуру, как показано на рис. 4: те ключевые слова, которые наиболее часто выпадают друг с другом, связаны короткими линиями; те, которые вместе выпадают редко, — длинными. Иерархическая кластеризация позволяет исследователю выбрать необходимое количество кластеров. На рис. 4 выбрано 17 кластеров, каждый из которых обозначен своим цветом. Программа разбивает массив на кластеры, которые логически или семантически связаны. Однако метод позволяет выявить и новые, неочевидные связи, например два фактора, которые часто выпадают с третьим.
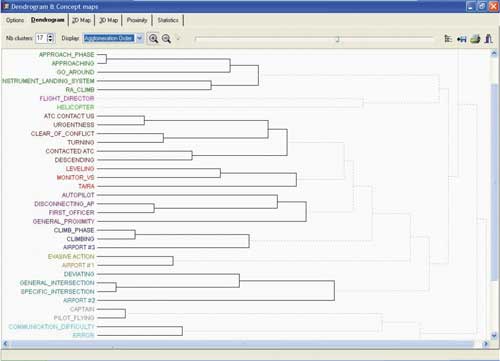
Рис. 4. Пример построения иерархической кластеризации
Программа предоставляет весьма наглядный метод анализа — так называемые горячие карты (Heat maps). На рис. 5 показана «горячая карта», построенная на основе отчетов авиакомпании JetBlue Airways. Она представляет собой таблицу: в строках представлены слова, отражающие тип механической проблемы, а в столбцах — марки самолетов. Кластеризация данных в строках и столбцах позволяет выявить группы самолетов, в которых появляются сходные механические проблемы.
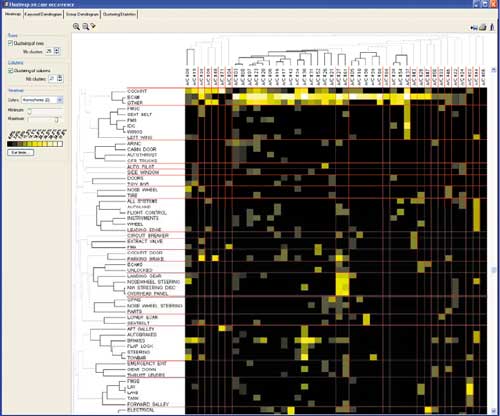
Рис. 5. Пример построения «горячей карты» (Heat map)
TextAnalyst
TextAnalyst (рис. 6) — это средство семантического анализа, навигации и поиска в неструктурированных текстах. В продукте реализована синергия от использования технологий лингвистического анализа и нейросетей.
Рис. 6. Интерфейс программы TextAnalyst
Система TextAnalyst поможет быстро резюмировать, эффективно управлять и объединять в группы документы в текстовой базе. Она облегчает поиск семантической информации либо может сфокусировать изучение текста на каком-то определенном предмете.
Продукт обеспечивает решение таких задач, как составление резюме объемного текста, дает представление о чем текст, позволяет эффективно осуществлять навигацию по большим текстовым документам и поиск информации с помощью запросов на естественном языке.
Основные возможности приложения отражены на рис. 7.

Рис. 7. Основные возможности программы TextAnalyst
Продукт существует как автономное и как встраиваемое решение.
Одна из возможностей системы — это построение сети семантических связей текста (Semantic Network). Полученная семантическая сеть служит основой для дальнейшего смыслового анализа текста. Семантическая сеть — это набор наиболее важных понятий, извлеченных из текста, и взаимосвязей между ними, оцененных на основе их относительной важности (рис. 8).
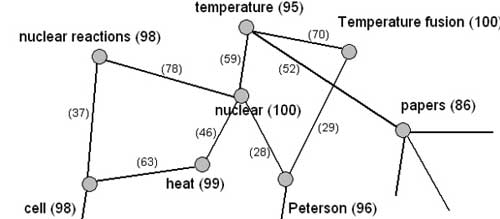
Рис. 8. Пример фрагмента семантической сети
Эффективная навигация по текстовым массивам осуществляется на основе гиперссылок по ключевым словам (понятиям) в семантической сети на те предложения в документе, которые содержат необходимые комбинации слов. Отдельные предложения могут иметь, в свою очередь, гиперссылки на те места в исходном тексте, где они были обнаружены.
Продукт обеспечивает возможность выявления тематической структуры текста — программа позволяет автоматически генерировать древообразную тематическую структуру исследуемого текста. Чем более существенными являются темы в тексте, тем ближе они располагаются к корню древовидной структуры.
С помощью подключения пользовательских словарей (включаемых и исключаемых слов) программа позволяет исследователю сконцентрироваться на изучаемом предмете.
Кластеризация текстов базируется на удалении слабых ссылок в семантической сети, что приводит к разбиению текста на семантически однородные кластеры.
Обработка запросов на естественном языке осуществляется на основе анализа на наличие семантически значимых слов в исследуемой базе и возвращении релевантных предложений из исходной текстовой базы. Дополнительно формируется так называемое поддерево понятий, относящихся к запросу, что также помогает усовершенствовать поиск.
Businessobjects Text Analysis
BusinessObjects Text Analysis обладает мощными лингвистическими возможностями по чтению и пониманию документов на 30 языках, базируясь на развитом NLP-аппарате, и позволяет обрабатывать данные на базе 220 файловых форматов. Анализ текста выполняется не на уровне слов и частоты их появления в тексте — программа идет от понимания построения предложений в естественных языках.
Данные возможности дополняются категоризацией, что позволяет применять пользовательские таксономии при анализе текста для последующей классификации, реферирования и построения связанных выжимок текста.
Программа позволяет извлекать информацию по 35 типам объектов и событий, включая людей, географические места, компании, даты, денежные суммы, email-адреса, и выявлять взаимосвязи между ними.
Мощный инструмент позволяет обрабатывать огромные массивы информации, определяя искомые объекты (рис. 9).
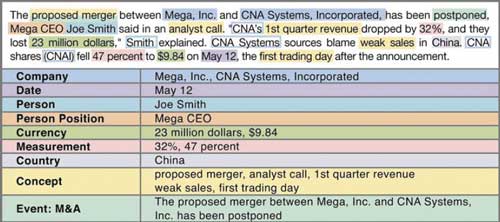
Рис. 9. Пример работы программы
BusinessObjects Text Analysis по распознаванию объектов в тексте
На основе структуры естественных языков программа может распознавать информацию, связанную с заданными пользователем объектами, такими как названия проектов, анализировать взаимосвязи между событиями и конкретные фразы на предмет сентимент-анализа (sentiment analysis).
BusinessObjects Text Analysis предоставляет возможность классификации документов по представленным категориям, которые могут явно и не присутствовать в исходном документе. Например, ваш документ может быть отнесен к категории «жалоба пользователя» даже в том случае, если слово «жалоба» нигде в нем не встречается. Программа сама выявит неудовлетворенность клиента и отнесет документ к этой категории автоматически.
Реферирование осуществляется на базе извлечения наиболее релевантных предложений, характеризующих смысловое содержание документа.
Программа может быть интегрирована с продуктами BusinessObjects (Crystal Reports, BusinessObjects Web Intelligence, BusinessObjects Enterprise. BusinessObjects Data Integrator и др.).
AeroText
AeroText — это текстомайнинговое приложение, используемое для контент-анализа, которое может применяться на разных языках. Оно разрабатывалось в подразделении Integrated Systems and Solutions корпорации Lockheed Martin Corporation для нужд оборонного ведомства США (U.S. Intelligence Community (Department of Defense)). Со временем это решение стало одним из ведущих в области текстомайнинга, интеллектуальный модуль AeroText интегрирован и в другие продукты. AeroText обеспечивает извлечение информации и анализ взаимосвязей между извлеченными единицами информации (рис. 10).
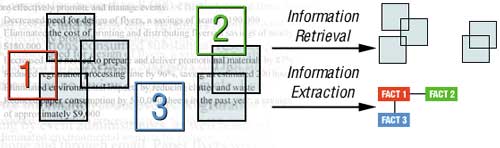
Рис. 10. Схема работы приложения AeroText
AeroText — это ПО, которое позволяет решать проблему информационной перегрузки на базе извлечения элементов анализа информации, таких как сущности (entities), взаимоотношения (relationships) и события (events), в неструктурированных текстах. Программа также позволяет выявлять скрытые взаимосвязи и события в текстах. Приложение может быть интегрировано с другими инструментами управления знаниями (knowledge management tools), обладает средствами индивидуальной настройки под исследуемую среду и поддерживает извлечение данных на различных языках.
AeroText — это решение data-independent, то есть решение, не зависящее от типа документа, тематики и типа языка. С помощью этой технологии могут решаться такие задачи, как построение базы данных, маршрутизация документов, броузинг, подготовка реферата (выжимки текста), построение полнотекстовых поисковых индексов и т.п. Версия AeroText 5.x существует в виде набора компонентов. Программа позволяет осуществлять извлечение информации, связанной с конкретными объектами (персоны, организации, географические объекты и т.п.), ключевые фразы (указание на конкретное время, объемы денег) и т.п. Решение также анализирует взаимосвязи между предметами, позволяя решить проблему множественных значений одного и того же предмета, осуществляет идентификацию взаимоотношений между предметами, извлечение событий (кто, где, когда), категоризацию тем (предмет, его определение), определение временного промежутка, когда имело место событие, определение места, которое может быть привязано к карте.
STATISTICA Text Miner
STATISTICA Text Miner — это дополнительное расширение программы STATISTICA Data Miner, предназначенное для перевода неструктурированных текстовых данных в информацию, пригодную для принятия решений. STATISTICA Text Miner позволяет извлекать из текста необходимые данные, структурировать их и представлять информацию в графическом виде (рис. 11). В качестве входных данных можно использовать не только текстовые документы или веб-страницы, но и файлы других типов. Программа обеспечивает доступ к текстовым документам в различных форматах, включая TXT, PDF, PS, HTML, XML, RTF и др.
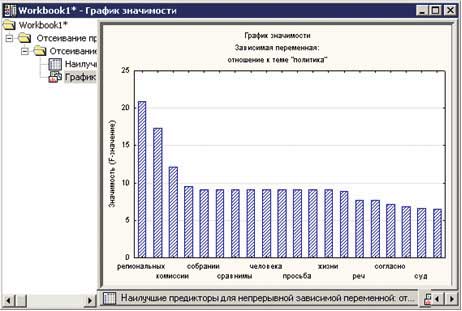
Рис. 11. Интерфейс STATISTICA Text Miner
Документы могут быть обработаны, прежде чем они будут проиндексированы (фактически эти процессы происходят одновременно). Программа написана таким образом, что поддержка дополнительных языков осуществляется с минимумом затрат. Средства анализа позволяют получить количественный отчет по исследуемому тексту. Путем статистического анализа можно оценивать степень похожести документов. На базе сопоставления документов по частоте появления в них различных слов можно установить принадлежность документа к той или иной смысловой категории. Кластерный анализ позволяет идентифицировать группы сходных по смыслу документов. Предсказательные методы добывания данных позволяют устанавливать связи между полученными численными характеристиками документов с другими индикаторами (например, оценить намерение ввести в заблуждение, медицинский диагноз и т.д.).
STATISTICA Text Miner имеетоткрытую архитектуру. Программное обеспечение для текстомайнинга может быть интегрировано с любым ПО из линейки продуктов STATISTICA: STATISTICA Data Miner workspace, WebSTATISTICA или с обычными приложениями STATISTICA.
Attensity suite
Attensity — это набор текстомайнинговых решений, базирующихся на статистических и NLP-технологиях.
Технологии Attensity — это результат десятилетних исследований в области компьютерной лингвистики, которые привели к созданию ПО, позволяющему извлекать знания из неструктурированных текстов. Программу отличают широкий набор технологий извлечения — от ключевых слов до событий, открытая архитектура и удобный интерфейс (рис. 12). Программа Attensity предлагает богатый набор инструментов для анализа текстов, который включает средства интеграции, интеллектуальный модуль, масштабируемую серверную платформу, использует запатентованные средства извлечения информации и позволяет создавать бизнес-решения «под ключ». Технология дает пользователям возможность извлекать и анализировать следующие факты: кто, что, где, когда и почему делал, — и впоследствии уточнять, кто, в каких местах и в каких событиях принимал участие и как они между собой связаны.
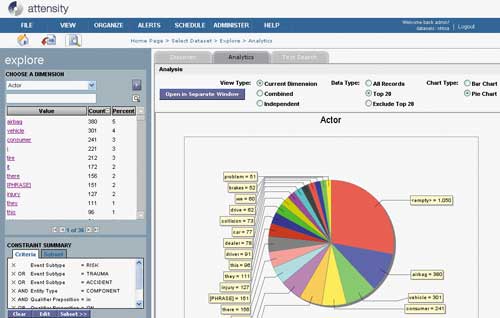
Рис. 12. Интерфейс Attensity
В основе Attensity Text Analytics suite лежит технология извлечения информации из неструктурированных текстов. Она позволяет извлекать информацию, спрятанную в неструктурированном тексте, и переводить ее в структурированные данные, имеющие связи, которые могут быть проанализированы теми же методами, что и другие виды структурированных данных. Извлечение информации как из неструктурированных, так и из структурированных источников дает дополнительные возможности.
Программа может работать даже с текстами, содержащими грамматические ошибки, что важно в том случае, когда приходится обрабатывать сообщения электронной почты, личные записи, жалобы клиентов и т.п.
ЕРАМ-Голос клиента
«ЕРАМ-Голос клиента» обеспечивает оперативную обратную связь с клиентами посредством анализа мнений в интернет-форумах и блогах по таким темам, как отношение к бренду, причины недовольства и т.п.
Инструмент представляет собой бизнес-приложение, в основе которого лежат лингвистические алгоритмы и технологии Opinion Mining, позволяющие извлекать данные из различных неструктурированных источников и структурировать информацию в виде базы данных. Полученные структурированные данные можно обрабатывать разными аналитическими инструментами, начиная с MS Excel и заканчивая системами OLAP, Business Intelligenсe (BI) и Data Mining. Система подключается к аналитическим инструментам разных вендоров, в том числе SAP, Oracle, SPSS, Cognos и др. Подходы, которые лежат в основе данного программного продукта, существенно расширяют возможности представленных сегодня на российском рынке корпоративных и онлайн поисковых систем (Yandex.ru, Google.ru и др.), поскольку последние предполагают последующую ручную обработку информации (просмотр ссылок, извлечение нужных данных, занесение их в базу данных). В случае, когда объем информации составляет десятки тысяч документов в день, ручная обработка просто неприемлема.
При этом инструмент может работать как с внешними (блоги, форумы, интернет-сайты, СМИ и т.д.), так и с внутренними (CRM, записи колл-центров, разного рода мессенджеры, переписка по электронной почте и т.д.) источниками. Система использует для анализа как структурированную (базы данных), так и неструктурированную (тексты, графика и т.д.) информацию. «ЕРАМ-Голос клиента» обеспечивает прямой доступ к мнению клиентов. Данные представляются в виде удобных отчетов, которые показывают ситуацию в целом или в подробностях. Можно проводить анализ трендов, выявлять аномальные отклонения и скрытые зависимости, составлять рейтинги и т.п.
Результаты могут использоваться для планирования маркетинговой кампании, вывода нового продукта на рынок, оценки эффективности инвестиций и т.п. В результате с помощью этого инструмента на основе данных из интернет-источников можно:
Программа «ЕРАМ-Голос клиента» уже используется такими компаниями, как сеть отелей Marriott, Johnson & Johnson, Novartis, Visa, маркетинговое агентство Rapp Collins, крупные электронные магазины R-Toys, E-Bay и т.д.
Система была разработана компанией EPAM Systems для американской компании Clarabridge, которая реализует ее на территории США, при этом в работе над ней принимали участие программисты, консультанты и лингвисты ЕРАМ. На территории стран СНГ эксклюзивным дистрибьютором системы является компания EPAM Systems. Качество обработки информации: точность — порядка 95-97%, производительность — более 20 тыс. документов в день. Система продуктивно работает с такими характеристиками с английским и русским языками и предназначена для автоматизации анализа больших массивов информации из разнообразных источников.
Galaktika-ZOOM («Галактика»)
«Галактика ZOOM» — это технология динамического контент-анализа. Она позволяет строить информационные портреты объектов по любой текстовой информации, в частности по сообщениям СМИ. Такой портрет состоит из статистически значимых слов и выражений, сопровождающих упоминание объекта.
«Галактика ZOOM» обеспечивает поиск в информационных массивах с применением языка запросов, а также контекстный или тематический поиск информации с учетом морфологии.
На рис. 13 показан пример «исследование — информационный портрет» — слова и словосочетания, отражающие информационное содержание объекта. Уникальной особенностью системы «Галактика ZOOM» является умение выявлять значимые слова и словосочетания документа, отражающие его смысл. Программа позволяет уточнить запрос, выбрав слово/словосочетание для включения (колонка «И») или исключения (колонка «И НЕ»).
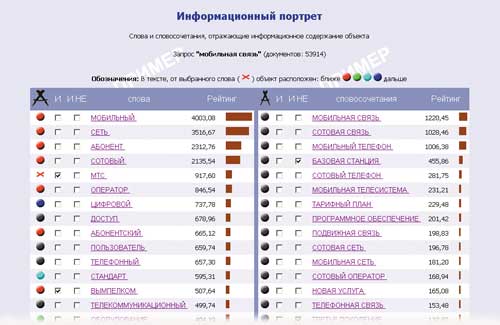
Рис. 13. Пример работы «Галактика ZOOM»
Медиалогия
«Медиалогия» — это система для проведения глубоких исследований по открытым источникам информации на базе технологии анализа массивов неструктурированной информации.
Система «Медиалогия» не предусматривает передачи программы заказчикам, производя обслуживание клиентов в онлайновом режиме. «Медиалогия» — это web-приложение, представляющее собой мощное решение со сложной архитектурой (рис. 14) и обеспечивающее непрерывную обработку поступающей информации, структурированное хранение данных, расчет аналитических параметров, проведение анализа по запросам пользователя и хранение настроек и отчетов.
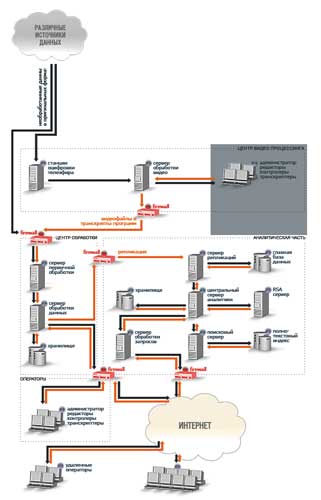
Рис. 14. Архитектура системы «Медиалогия»
Пользователь, имеющий доступ к системе, создает запрос и получает готовый отчет, доступный для просмотра через систему или экспорта на компьютер пользователя. Персональные настройки и пользовательский профиль тоже хранятся на сервере. Такая схема позволяет сделать систему максимально производительной и не привязанной к конкретному компьютеру.
Система «Медиалогия» ежедневно импортирует десятки тысяч сообщений, поступающих из различных источников (газет, журналов, телевидения, радио, информационных агентств, интернет-ресурсов). Эти сообщения структурируются, оцениваются и проходят семантическую обработку. Полученные в результате обработки расчетные индексы и семантические связи служат основой для проведения анализа информации. Схема превращения исходных материалов в хранилище знаний показана на рис. 15.
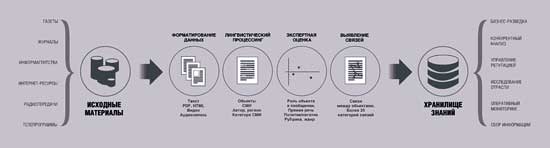
Рис. 15. Схема превращения исходных материалов в хранилище знаний
«Медиалогия» предназначена в том числе для решения следующих задач:
Она позволяет производить поиск сообщений по заданным параметрам и контексту с применением технологий искусственного и человеческого интеллекта. Система специализируется на анализе информационного поля на основе интеллектуальной обработки данных в режиме реального времени. При этом возможно выявление связей и отношений между персонами и компаниями, отслеживание особенностей отображения ситуации отдельными источниками или авторами. Система позволяет отслеживать десятки типов связей (партнер, конкурент, акционер, друг) и взаимоотношений (контакты, финансовые отношения, конфликты) между объектами.
Результаты запросов к системе представлены в форме интуитивно понятной деловой графики. Для изучения регионального распределения информации используется геоинформационная карта РФ. Специальные «семантические карты» служат для визуализации связей объекта. Все виды представления в системе «Медиалогия» интерактивны. Цветовая разметка текстов сообщений позволяет свободно ориентироваться в тексте.
В системе также хранятся материалы в оригинальных форматах.
Источники информации проходят тщательный отбор — в базу «Медиалогии» попадают только наиболее значительные в своих областях СМИ.
Программа позволяет рассчитать так называемый индекс информационного благоприятствования — расчетный показатель, который дает возможность оценить качественную составляющую информационной ситуации, сложившейся вокруг персоны, компании или бренда.