Работа с базой данных TEMPDB
TEMPDB представляет собой системную базу данных Microsoft SQL Server, в которой хранятся временные таблицы созданные как самим сервером, так и пользователями. Эта база данных создается заново при каждом перезапуске Microsoft SQL Server. По умолчанию размер этой базы данных неограничен и увеличение его осуществляется при необходимости автоматически, порциями по 10% от текущего размера TEMPDB, однако эти параметры могут быть переопределены пользователем. По умолчанию, минимальный размер этой базы данных, который устанавливается при старте Microsoft SQL Server, определяется размером системной базы данных MODEL. Очистка журнала транзакций в этой базе данных производится автоматически, при этом удаляются только неактивные записи журнала транзакций.
Проблема
Причина
Причиной увеличения размера базы данных TEMPDB, как правило, является невозможность автоматической очистки журнала транзакций и повторного использования свободного пространства в базе данных TEMPDB из-за наличия активных транзакций, использующих объекты этой базы данных. Основные причины, вызывающие длительную блокировку работы этих механизмов базы данных TEMPDB, заключаются в следующем:
Решение
Уменьшить размер базы данных TEMPDB до требуемой величины можно следующими способами:
В этом случае размер базы данных TEMPDB будет установлен по умолчанию или, если эта величина переопределена пользователем, размер будет установлен в соответствии с заданными параметрами.
DBCC SHRINKDATABASE (TEMPDB)
DBCC SHRINKFILE ( Имя_Файла_Данных, Желаемый_Размер_Файла_Данных )
go
DBCC SHRINKFILE ( Имя_Файла_Журнала_Транзакций, Желаемый_Размер_Файла_Журнала_Транзакций )
go
Следует отметить, что эти команды рекомендуется выполнять в период наименьшей активности пользователей, и для их выполнения необходимо обладать правами администратора.
Более подробное описание и рекомендации по использованию этих команд можно найти в документации по Microsoft SQL Server.
Пошаговые руководства, шпаргалки, полезные ссылки.
Инструменты пользователя
Инструменты сайта
Боковая панель
Файлы системной базы данных tempdb
Системная база данных tempdb активно используется базами данных 1С:Предприятие 8.3 для хранения временных таблиц, промежуточных расчетов, версий строк при использовании режима версионирования и прочих временных данных. То есть для задач 1С:Предприятие интенсивность обращений к базе tempdb находится на высоком уровне, поэтому нужно подумать о размещении этой базы на выделенном быстром дисковом устройстве.Подходящими кандидатами на роль диска под tempdb будут выделенные быстрые дисковые RAID-группы уровня RAID1, выделенные накопители SSD или вообще RAM-диск.
В большинстве сценариев рекомендуется разбивать базу tempdb на несколько файлов данных с одинаковом начальным размером (Initial size) от 1GB и больше и увеличенным показателем прироста, например, в 512MB.
При определении количества файлов можно руководствоваться принципом: количество процессорных ядер = количество файлов данных tempdb, но при этом стоит помнить о том, что использование более 8 файлов (даже при количестве ядер более 8) далеко не всегда может иметь положительный эффект. Возможно по этой причине в инсталляторе SQL Server 2016 даже при большом количестве процессорных ядер по умолчанию предлагается 8 файлов tempdb.
Относительно 1С:Предприятие 8.3 можно встретить рекомендацию о том, что общий размер Initial size для всех файлов БД tempdb должен быть от 25% до 40% от размера рабочей БД 1С:Предприятие.
Рассмотрим частный пример распределения файлов tempdb по разным дисковым томам, имеющим разные показатели производительности. В нашем примере имеется два тома NTFS:
Часть файлов данных в файловой группе tempdb, а также файл лога размещены на быстром диске. Файлы данных, расположенные на быстром диске установлены фиксированного размера без возможности авторасширения (исключением здесь является только файл лога). Другая часть файлов данных размещена на менее производительном дисковом томе, но при этом для файлов включено авторасширение.
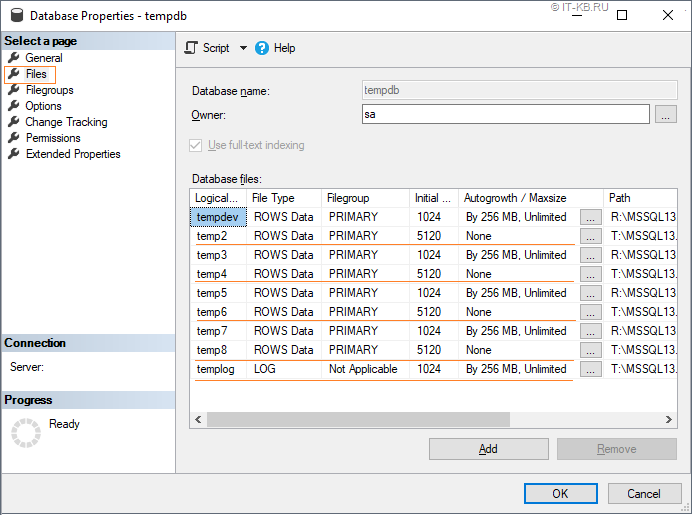
В результате такой конфигурации, файлы tempdb в нашем случае будут распределены по дисковым томам следующим образом: 4 файла данных и лог tempdb окажутся на быстром томе T:
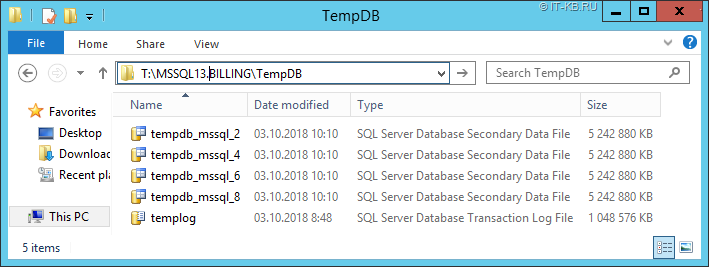
Другие 4 файла данных tempdb окажутся на менее производительном дисковом томе R:
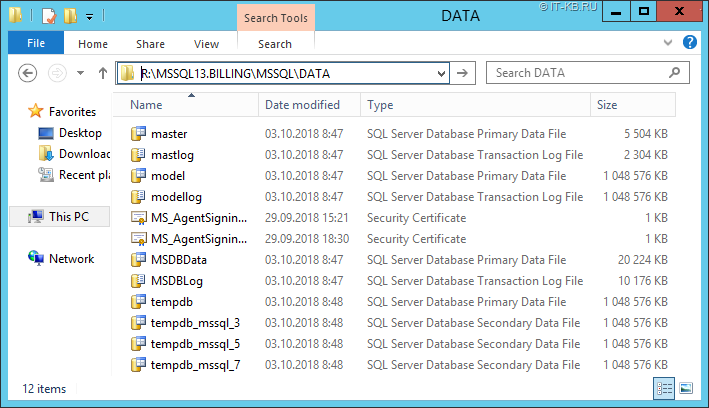
В случае если в ходе работы экземпляра SQL Server потребуется дополнительное расширение ёмкости tempdb, то файлы начнут прирастать на меньшем по производительности, но большем по объёму дисковом томе R.
К операциям, которые могут вызвать бурный рост tempdb при работе БД 1С:Предприятие 8.3 можно отнести, например, регламентные процедуры с конфигурацией 1С, выполняемые из конфигуратора (обновление конфигурации, перерасчёт итогов и т.п.). Кроме того, активный рост tempdb может вызвать построение в 1С каких-то тяжёлых отчётов с большим количеством данных и за длительные периоды при условии, что код отчётов неоптимален или вообще содержит ошибки. В практической среде при размере БД около 170GB во время построения подобного отчёта мы наблюдали рост tempdb до 350GB. Учитывая эти моменты стоит подумать о полной изоляции файлов tempdb на выделенных дисковых томах, чтобы их возможный бурный рост не смог нарушить функционирования других БД SQL Server.
Используемый в нашем примере дисковый том T: представляет собой RAM-диск, подключенный к серверу SQL Server по методике, описанной в отдельной статье нашего Блога : Организуем RAM-диск для кластера Windows Server с помощью Linux-IO FC Target
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Освоение TempDB: основы
Я регулярно отправляю презентацию под названием «Освоение TempDB». Я писала, что она представляет собой основы того, что я хотела бы знать о TempDB в начале своей карьеры в качестве администратора SQL Server. Это действительно раскладка того, что такое TempDB, как она используется, какие проблемы действительно возникают в ней, и как её лучше сконфигурировать. По совету коллег я решила разложить все по полочкам здесь в образовательных целях.
Что такое TempDB?
TempDB является глобальным ресурсом, который используется всеми и каждым внутри SQL Server. Думайте об этом как о свалке для всего, что не помещается в памяти. Это всегда database_id номер два в sys.databases.
Она недолговечна, что означает, что база данных создается заново всякий раз, когда стартует сервис SQL. Всякий раз воссоздается новый набор файлов данных и журналов. И что это означает для вас? Во-первых, вы не можете поместить какие-либо объекты в базу данных TempDB, которые требуют постоянного хранения. Не используйте TempDB как базу данных для разработки (за исключением, возможно, кратковременных тестов, поскольку после перезапуска сервиса вы потеряете всю свою работу.
TempDB работает в круговой манере, известной как пропорциональное наполнение; Данные записываются во все файлы в соответствии с наличием свободного места в каждом файле, и файлы переключаются в поисках наилучшего места для работы. Я расскажу об этом более подробно ниже в этой статье. TempDB по большей части похожа на другие пользовательские базы данных, за исключением журнализации и надежности. Журнализация выполняется в минимальном объеме. Журнал транзакций имеется, но он используется только для отката транзакций, а не для восстановления. TempDB ненадежна, поскольку её не требуется восстанавливать, т.к. она всякий раз обновляется.
TempDB должна находиться в быстром хранилище с низким временем задержки. Из-за постоянно высокой степени конкурентности транзакций, которые пишут данные в TempDB, необходимо размещать её на самом быстром из имеющихся дисков. Кроме того, в качестве лучшей рекомендации я советую размещать файлы данных и файл журнала на собственных отдельных дисках.
Что хранится в TempDB?
Временные объекты, которые пользователь создает явно
Внутренние объекты
Рабочие таблицы для сохранения промежуточных результатов
Рабочие файлы для хэш-соединений или операций хэш-агрегирования
Промежуточные операции сортировки
Хранение версий
Группы доступности (Availability Groups)
Реплики групп доступности используют по умолчанию изоляцию снимка, которая использует версии строк каждой транзакции. Эти транзакции записываются в хранилище версий (Version Store) в TempDB. Они выполняются на вторичных репликах, чтобы избежать блокировок, которые могут препятствовать применению транзакций из первичной реплики. Однако блокирование все же может стать проблемой для длительных транзакций, которые приводят к блокировке процесса очистки хранилища версий и, возможно, к заполнению вашей TempDB. Если это происходит, вы не сможете выполнить аварийное переключение. Убедитесь, что вы знаете как это все работает. Вот отличная ссылка.
При использовании вторичной реплики только на чтение оптимизатор запросов создает также временную статистику в TempDB. Статистика из первичной базы данных реплицируется во вторичную. SQL Server требуется также статистика по данным только на чтение, на основе запросов, которые выполняются на вторичной. Вы обнаружите её внутри TempDB с суффиксом _readonly_database_statistics. Оптимизатор запросов использует эту статистику для оптимизации рабочей нагрузки на вторичной реплике.
Что вызывает проблемы в TempDB?
Pam Lahoud имеет фантастический блог по этому поводу, где она подробно описывает эти конфликты; не забудьте почитать.
Как решить проблемы с конфликтами?
Надлежащая конфигурация
Чтобы получить выгоду от круговой обработки TempDB, существенно иметь множество файлов данных с тем, чтобы рабочая нагрузка равномерно распределялась между ними. Чтобы это гарантировать, вы должны убедиться, что ваши файлы также имеют одинаковые размеры и автоматический прирост. Если у вас один файл больше другого, вы получите конфликт. Система разместит всю работу в самый большой файл, полагая, что он имеет больше всего свободного пространства. Кроме того, при добавлении нового файла запланируйте перезапуск. Хотя вам не требуется перезапуск для добавления нового файла, так или иначе движок будет использовать новый файл только потому, что теперь в нем больше всего свободного места. Переустановка TempDB с помощью перезапуска вызвана желанием убедиться, что поддерживается пропорциональное использование файлов. Я регулярно использовала это на практике для проверки, что все они выровнены.
Помимо обеспечения надлежащего использования круговой логики, добавление большего числа файлов дает вам большее число этих специальных страниц для работы с ними. С добавлением каждого файла данных вы получаете одну страницу GAM и одну страницу SGAM на каждые 4Гб пространства, выделенного для этих файлов. Мне всегда задают вопрос, как узнать какого размера должны быть файлы, чтобы гарантировать оптимальное число таких страниц. К сожалению, здесь нет однозначного ответа. Нет ни скрипта, ни алгоритма, который я могла бы вам предложить для вычисления магического числа для вашей среды. Как и со многими другими установками, вам потребуется знать свою рабочую нагрузку, чтобы это определить. Я настоятельно советую вам мониторить использование TempDB и скорость роста, как начальную точку. Есть еще один отличный инструмент, который мне нравится использовать, чтобы следить за виртуальными файлами журнала (vlf) как индикатором этих событий. Вот блог, чтобы лучше узнать об этих вещах.
Новые версии SQL Server упрощают нам это. Во время установки нам помогают определить число необходимых файлов и позволяют создать их в процессе установки.
Наконец, как вы конфигурируете диск? Обработка TempDB происходит в реальном диске, а не в памяти для большинства операций. Поскольку TempDB высоко конкурентен и используется интенсивно движком, критичным является размещение его на наиболее быстром диске из имеющихся. Если можете, используйте флэш-накопители. Имеются высокоскоростные накопители с энергонезависимой памятью; вы можете найти информацию о них по ключевым словам NVMe, Non-volatile Memory Express. Это SSD, твердотельные накопители. Нужно только иметь в виду, что NVMe являются SSD, но не все SSD являются NVMe, т.к. имеются другие типы SSD. Не важно, какого уровня будет тип SSD, они отлично подходят для рабочих нагрузок TempDB. Если вы хотите больше узнать о типах накопителей и что спросить у своего администратора при определении лучшей конфигурации вашей TempDB в SQL Server, посетите мой блог о накопителях для начинающих.
Флаги трассировки
До версии SQL 2016 использование флагов трассировки 1118 и 1117 помогало снизить конфликты, обеспечивая одновременный рост всех файлов, если возрастал один из них, а также измерение алгоритма смешанных экстентов, который уменьшал конфликты с SGAM-страницами. Включение 1118 не имеет недостатков. Что касается 1117, то следует иметь в виду, что этот флаг применяется ко всем файловым группам, а не только к TempDB. При включенном флажке 1117, если у вас имеются другие файловые группы в ваших базах данных, и если один из этих файлов растет, он включает событие роста для всех остальных файлов в этой файловой группе и этой базе данных. Если вы используете более старую версию SQL Server, я НАСТОЯТЕЛЬНО рекомендую добавить их. Это настолько важно, что теперь принимается по умолчанию.
Накопительные обновления
SQL Server 2019
TempDB был удостоен некоторого внимания в SQL Server 2019. Были внесены улучшения в кэширование временных таблиц, конкурентное обновление PFS-страниц и введены две захватывающие новые возможности In-Memory OLTP TempDB Metadata (метаданные TempDB для OLTP таблиц, размещаемых в памяти) и Table Variable Deferred Compilation (отложенная компиляция табличных переменных). Как и с другими новыми возможностями, имеются некоторые проблемы с системными таблицами, размещаемыми в памяти, поэтому проверьте, чтобы у вас был установлен 2019 CU2, который исправляет некоторые конфликты, связанные с этой функциональностью.
Чтобы воспользоваться новой возможностью Memory OLTP TempDB Metadata, её нужно включить:
Как увидеть, что происходит в TempDB?
Решения для базы данных tempdb в SQL Server
Рекомендации по настройке tempdb, количеству и размерам файлов, выбор хранилища для tempdb и пример из практики
Tempdb — критически важная системная база данных в Microsoft SQL Server. Ее уникальная особенность состоит в том, что это общий ресурс, к которому обращаются все пользователи экземпляра SQL Server для размещения временных объектов пользователя, таких как таблицы, переменные таблицы, временные индексы, курсоры и результаты функции с табличным значением. Кроме того, она используется для размещения внутренних системных объектов для рабочих таблиц, хешей, сортировки, временного хранилища больших объектов, операций объединения и хеш-соединения, а также других нужд системы. Интенсивность использования базы данных tempdb в SQL Server (https://docs.microsoft.com/en-us/sql/relational-databases/databases/tempdb-database?view=sql-server-2017) может быть крайне низкой или постоянно высокой. Это зависит от многих факторов, в частности от размера базы данных, качества и эффективности программного кода приложения и базы данных, структуры таблиц, использования временных таблиц или табличных переменных, применения курсоров и функций с табличным значением и от нагрузки. Как бы то ни было, ответственные за построение и администрирование среды SQL Server сотрудники должны постараться сделать tempdb как можно более производительной, учитывая особенности разработки, факторы масштабирования, бюджета и предполагаемого использования. Ключевое условие при этом — обеспечить приемлемые характеристики хранилища.
Во многих случаях администраторы баз данных, обязанные поддерживать оптимальный уровень производительности SQL Server,не те специалисты, которые подготовили серверы. При благоприятном раскладе у них будет достаточно влияния, чтобы предложить рекомендации относительно уровней загрузки процессора, оперативной памяти и хранилища данных. Возможно, к их мнению прислушаются даже при выборе оборудования. Однако, по мере того как все больше рабочих нагрузок перемещается на «облачные» платформы, такие как Microsoft Azure и Amazon AWS, большинство ключевых решений инфраструктуры уходит из компетенции администратора баз данных. Эта статья должна послужить напоминанием о том, что при принятии решения о переходе в «облако» нельзя полностью игнорировать инфраструктурные соображения. В компаниях по-прежнему остаются вопросы по инфраструктуре, критически важные даже при работе в «облачной» среде, где варианты ограничены.
Рекомендации по настройке tempdb
Очевидно, что чрезвычайно важно иметь правильно настроенную базу данных tempdb в SQL Server с той минуты, когда завершена установка SQL Server. Tempdb активно используется в операциях сортировки, хеширования и слияния. Она также задействована в любом процессе с временными объектами, поэтому представляет собой узкое место для значительного числа приложений SQL Server. Требуется подготовить нужное количество файлов соответствующего размера, причем на самом быстром из имеющихся дисков. Все эти факторы нетрудно настроить или скорректировать, особенно в «облачных» реализациях. Не забудьте, что tempdb всегда необходимо располагать на собственном выделенном диске.
Рекомендации по количеству файлов tempdb
Решение относительно количества файлов данных, подготавливаемых для базы данных tempdb в SQL Server, зависит от числа логических ядер процессора. Для экземпляров SQL Server, работающих менее чем с восемью логическими ядрами (если такие еще существуют), должно быть соотношение 1:1 между числом логических ядер и файлами данных, размещенных в tempdb. Когда имеется восемь или более логических ядер, поначалу следует подготовить восемь файлов данных. Если в tempdb отмечается конкуренция за выделенные ресурсы (она проявляется в увеличении значения параметра PAGELATCH_UP для ресурса ожидания, размещенного в tempdb), то добавляйте по четыре файла данных, пока это не прекратится.
Рекомендации по размерам файлов
Размер базы данных tempdb в SQL Server зависит от многих факторов, в частности таких, как размер баз данных пользователя, эффективность программного кода и реляционная модель. Также необходимо учитывать и другие факторы, такие как сортировка перестроенных индексов в tempdb, использование хранилища версий в целях уменьшения конкуренции и применение функций определенных типов.
В первую очередь важно настроить все файлы данных на увеличение с одинаковым интервалом. В процессе разработки и тестирования вы сможете собрать метрики, характеризующие предполагаемое использование tempdb, и реализовать их при внедрении базы данных в производство. Определить размеры файлов tempdb поначалу немного труднее, но возможности «облачной» подготовки упрощают задачу, так как подготовка хранилища обычно представляет собой интерактивный процесс в «облаке». Если нужно больше места, его можно выделить без обязательного простоя. Моя основная цель при определении размера файла для tempdb (и большинства других баз данных) — попытаться заранее довести свои файлы данных и журналов до максимальной прогнозируемой величины. Я не полагаюсь на автоматическое увеличение, но предусматриваю этот вариант, обеспечивая дополнительное пространство или выдачу предупреждений таким образом, чтобы иметь большой запас времени для выделения пространства по требованию.
Выбор хранилища для tempdb
Остается принять решение относительно класса хранилища для базы данных tempdb в SQL Server. Об этом решении проще всего забыть, особенно для «облачных» экземпляров SQL Server. Большинство поставщиков «облака» предоставляют хранилища с различными уровнями производительности. Например, у Microsoft Azure и Amazon AWS есть многочисленные варианты с дисками SSD наряду с жесткими дисками. Для большинства «облачных» экземпляров существует два варианта достижения целевого показателя операций ввода-вывода в секунду (IOPS). В зависимости от поставщика, вы можете подготовить класс накопителя с показателем IOPS в зависимости от размера диска в гигабайтах или приобрести класс накопителя, обеспечивающий определенный минимальный уровень IOPS. Предусмотрено также увеличение показателя IOPS, если выбранный уровень неприемлем для рабочего приложения, это еще одно достоинство «облачных» экземпляров SQL Server. Большинство изменений хранилища, связанных с коррекцией показателя IOPS для SQL Server, представляют собой интерактивные операции. Корректировка заданного показателя IOPS вверх или вниз обычно не влечет за собой перезапуска службы или перезагрузки сервера.
Пример из практики
Недавно один из моих клиентов столкнулся с рядом проблем производительности в производственной среде, размещенной в AWS. Технических недостатков было много, и для их устранения потребовались бы месяцы работы. Однако в процессе поиска неисправностей я обратил внимание на характеристику, способную принести быстрый выигрыш: задержку tempdb. Задержка показывает, на сколько запаздывают входящие и исходящие вызовы дисковой подсистемы. В сущности, задержка — это время в миллисекундах (мс) между отправкой запроса к элементу данных на диске и получением этого элемента данных. Задержка влияет на пропускную способность, достигаемую данным классом хранилищ, в зависимости от модели или настроек, а также количества запросов в очереди на доступ к объектам на диске.
На экране 1 приводятся данные по задержке диска, полученные в ходе начальной оценки экземпляра SQL.
.jpg) |
| Экран 1. Начальная задержка диска SQL Server |
Мною был сделан ряд выводов относительно элементов данных, просто на основании показателей задержки, полученных в результате одного запроса к динамическому объекту управления sys.dm_io_virtual_file_stats:
Задержка операций чтения основного файла данных (32,0 мс на диске D по сравнению с 20 мс для любых файлов данных tempdb на диске E) вызывала вопросы, пока я не учел количество операций чтения и записи. Число операций чтения для основной пользовательской базы данных в 11 раз меньше аналогичного показателя для tempdb за тот же период времени. Операции записи для той же базы данных составляли половину таких операций для tempdb. Учтите также фактор оперативной памяти: пользовательская база данных может 10 раз разместиться в буферном пуле. Основная часть страниц пользовательской базы данных считывается в буфер один раз, и многократные циклы ввода-вывода обращены лишь к «грязным» страницам. Картина доступа к tempdb совершенно иная и менее постоянная из-за особенностей использования tempdb. Показатели задержки для пользовательской базы данных не соответствуют заданной мною целевой величине IOPS для оптимально функционирующего сервера (не более 5 мс), но их улучшение далеко не так критично, как корректировка характеристик tempdb.
При ближайшем рассмотрении я обнаружил, что клиент подготовил все свои диски в универсальном хранилище AWS gp2 и игнорировал хранилище io1, предназначенное для критически важных бизнес-приложений, в частности баз данных. Пятиминутная операция по преобразованию диска в io1, без внесения любых других настроек в клиентскую среду, привела к изменениям задержки, показанным на экране 2.
.jpg) |
| Экран 2. Оптимизация задержки только благодаря изменению типа диска |
Изменив лишь класс накопителя и установив более высокий уровень IOPS и интенсивность пакетной передачи, мы смогли улучшить показатели задержки чтения и записи более чем на 60% на томе tempdb. Это привело к общему уменьшению блокировок из-за запросов с зависимостями от операций с участием tempdb.
Готовы ли вы выделить время для анализа характеристик tempdb? Возможно, в вашем случае тоже существуют простые и быстрые пути решения проблем.
Поделитесь материалом с коллегами и друзьями