Синтетическое резервное копирование (Synthetic Backup) – альтернативный прием эффективной защиты данных

![]()
Количество данных на предприятиях, больших и малых, с годами растет в геометрической прогрессии. Защита данных становится очень сложной задачей, а требования доступности растут с каждым днем. Учитывая, что защита данных является задачей первостепенной важности для предприятий любых размеров, эта задача требует значительных вложений (в зависимости от размера компании) и, определенно, является содействующим фактором в прибыльности компании. При тщательно продуманном планировании развертывания инфраструктуры ИТ и использовании только лучших приемов для содержания корпоративных данных, например планирование Disaster Recovery (DR) [1] для защиты и безопасности данных, компании смогут значительно сэкономить и увеличить границы своей прибыли. Синтетическое резервное копирование является одним из таких самых лучших DR приемов, который обеспечивает эффективную защиту данных при низкой стоимости работ. Оно также предлагает традиционные приемы резервного копирования файловой системы во время ее восстановления.
Что такое синтетическое резервное копирование?
Синтетическое резервное копирование является альтернативой создания полных резервных копий из периодических инкрементальных копий. Она состоит из одной обычной полной резервной копии (при первом создании), после создания которой, все последующие изменения вносятся в нее в виде периодических инкрементальных копий (periodic incremental [2] backups). Поскольку такой тип копирования синтезируется из полного резервного копирования, отсюда он и получил свое название.
Слово «синтетический» в данном контексте означает, что составной файл не является непосредственной копией любого (созданного в данный момент или ранее) единичного файла. Вместо этого, синтетический файл объединяется или «синтезируется» специальным приложением из оригинального файла и одной или большего количества его модификаций.
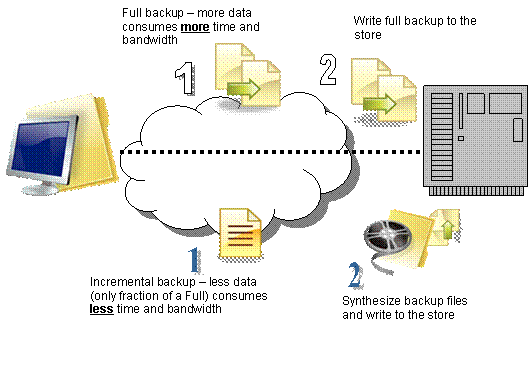
Рисунок 1: Концептуальное представление синтетического и полного резервного копирования
Эта процедура резервного копирования называется синтетической, поскольку копия создается не из оригинального файла данных. На рисунке 1 показаны шаги, из которых состоит традиционное полное резервное копирование и синтетическое. При синтетическом копировании меньше данных будет передаваться по каналам сети, что означает меньший объем сетевого трафика. Это происходит благодаря тому факту, что при традиционном создании резервных копий всего тома требуется передача всех используемых блоков данных из этого тома в хранилище резервных копий. А при синтетическом резервном копировании система использует лишь инкрементные изменения, передает их по каналам сети и после этого запускает специальную программу [3] в хранилище для применения этих изменений к предыдущей резервной копии (полной или синтетической). Суть заключается в том, что после первого создания полной резервной копии вам нужно будет использовать только инкрементные копии, а не полные резервные копии каждый раз. Каждая новая инкрементная копия будет синтезироваться и обновлять полную резервную копию.
Почему именно синтетическое резервное копирование?
Синтетическое резервное копирование – это не просто еще один способ создания резервных копий, это более удобная альтернатива. Наличие полной резервной копии и отдельных инкрементных составляющих не дает тех же преимуществ, которые предлагает синтетическое резервное копирование. В первом случае системному администратору пришлось бы иметь дело с большим количеством отдельных инкрементных файлов при восстановлении системы с их помощью. Во втором случае (при синтетическом резервном копировании) один единственный файл будет содержать все изменения с момента создания последнего инкрементного элемента.
Этот тип создания резервных копий подходит для корпоративного окружения, где пропускная способность сети имеет повышенное качество и ее нелегко масштабировать. Такие модели бизнеса как Application Service Providers являются типичными примерами, когда сотни гигабайт данных передаются по общим каналам, в большинстве случаев по линиям T1 или T3. Даже при использовании линии T3 создание резервных копий 20-30 серверов с 150 GB данных в среднем на каждом потребует серьезных вложений на оплату пропускной способности сети и соответствующих затрат на содержание линии. Более того, потребуются огромные ресурсы места для хранения всего объема периодических полных резервных копий.
Синтетическое резервное копирование лучше всего использовать, когда временные или системные требования не позволяют использовать полное резервное копирование. Некоторые ключевые преимущества:
Соответствующие пользователи (Featured Users)
Некоторые типичные пользователи синтетического резервного копирования:
Провайдеры сервисов приложений (Application Service Providers)
Application Service Providers (ASP) поставляют ПО от централизованных банков данных, через платный доступ выделенных, высокоскоростных сетей или Интернет. Службы приложений варьируются от систем планирования ресурсов предприятий (Enterprise Resource Planning (ERP)), решений управления взаимоотношениями потребителей (Customer Relationship Management (CRM)) и вертикальных приложений до ПО для рабочих групп, пакетов персональной производительности и полных сервисов десктопов и печати. Для того чтобы обеспечить защиту данных, провайдеры этих решений сталкиваются с проблемой создания со временем резервных копий этих важных данных, используя арендованные сети, например T1. Это довольно дорогая операция и требует значительных вложений, чтобы оплатить расходы аренды сетей и сетевой трафик.
Усовершенствованные приемы создания резервных копий, такие как синтетическое копирование, позволяют ASP значительно снижать стоимость этих операций (учитывая множитель), а также пользоваться преимуществом экономии времени и места, которое дает синтетический способ создания резервных копий.
Провайдеры Managed Service Providers
Провайдеры managed service provider (MSP) – это компании, которые управляют сервисами ИТ других компаний через Интернет. MSP – это компания, предлагающая продолжительный аутсорсинг ИТ функции. MSP обеспечивает техническую поддержку для данного сервера, включая обновление ПО, резервных копий, физических устройств, пропускной способности сети, брандмауэров и других технических вопросов. Учитывая ценовую эффективность и оптимизацию времени и места, которой обладает синтетическое резервное копирование, модель бизнеса MSP может со временем достичь значительного увеличения прибыли.
Предприятия малых и средних размеров (SMB)
Данные представляют собой важную интеллектуальную собственность любой компании, будь то ISV, страховая компания, банк, розничная торговая точка, компания разработки ПО, ASP/MSP, и т.д. Синтетический способ создания резервных копий гарантирует оптимальную работу касаемо требований времени на создание копий и места хранения копий. С меньшей нагрузкой на ресурсы производственной системы этот способ может создавать прерывистые синтезированные полные резервные копии с минимальным воздействием на общие и раздельные приложения, запущенные на этих производственных системах, включая файловые серверы, серверы базы данных и/или серверы печати. Еще одним преимуществом этого способа является меньшее количество времени, затрачиваемого на восстановление системы с помощью таких файлов. В отличие от множества традиционных инкрементных файлов, этот способ предполагает только одну резервную копию, содержащую все изменения, которые записывались в течение времени в каждом инкрементном файле.
Заключение
Эта статья дает технический обзор синтетического способа создания резервных копий системы. Воспринимайте его как лучший способ восстановления системы после сбоев DR, нацеленный на обеспечение эффективного в ценовом плане и сильного решения по защите данных. Благодаря его оптимальным параметрам времени и места, он поможет компаниям с огромными объемами важных данных эффективно справляться с резервным копированием томов и хранением этих копий. Вкратце, такой способ позволит обслуживать эффективное в ценовом плане хранилище данных и обеспечит оптимальные параметры создания резервных копий.
О Sonasoft
Sonasoft Corp. автоматизирует создание резервных копий с диска на диск и процесс восстановления для Microsoft Exchange, SQL и Windows Servers с помощью решений SonaSafe Point-Click Recovery. SonaSafe является единственным продуктом, обеспечивающим интегрированные решения по созданию резервных копий, восстановлению и репликации данных для серверов Exchange и SQL. Решения SonaSafe, созданные для упрощения и исключения возможных ошибок в процессе создания резервных копий и восстановления данных из-за человеческого фактора, также концентрируют процесс управления несколькими серверами и обеспечивают надежную дешевую стратегию восстановления данных после сбоев для компаний всех размеров. Для дополнительной информации перейдите по ссылке http://www.sonasoft.com/.
[1] Восстановление в случае сбоев (Disaster Recovery) – это важный момент в области управления жизненным циклом информации (Information Lifecycle Management), который подготавливает компанию к катастрофе и обеспечивает спокойствие ее сотрудникам.
[2] Относится к резервной копии, содержащей изменения на жестком диске (томе) с момента последнего создания резервной копии.
[3] Как правило это приложение работает на той же системе с Network Attached Storage (NAS). Либо оно может работать на любой другой машине, входящей в ту же подсеть с NAS.
Планируем ресурсы для Veeam Backup & Replication 8.0: расчет требуемого места в репозитории
Чтобы при планировании ресурсов для Veeam Backup & Replication люди могли прикинуть, сколько места потребуется в репозитории для бэкапа виртуальной машины, в свое время был создан калькулятор-симулятор точек восстановления Restore Point Simulator (RPS).

Но поскольку периодически приходится слышать от пользователей «А почему\зачем здесь это значение?», то сегодня я дам несколько пояснений насчет параметров ввода и расскажу, откуда взялись значения по умолчанию.
За подробностями добро пожаловать под кат.
Расчетная формула на бумаге и в калькуляторе
Формула, которую используют для расчета размера бэкапа, получающегося за один проход задания резервного копирования, имеет вид:
Размер бэкапа (Backup Size) = C x (F x Data + R x D x Data)
То есть, говоря по-русски:
Размер бэкапа = С x (общий объем данных на входе)
Из нее видно, что при умножении на C значение Total Data In изменяется пропорционально, давая нам Backup Size. Значит, коэффициент сжатия C показывает, на сколько (в %) уменьшился объем входящих данных, точнее, сколько осталось от первоначального объема после сжатия. Так, например, если выставить его в 40% (40/100) и принять объем входящих данных за 100 единиц, то размер бэкапа составит, очевидно, (40/100)*100=40 единиц. Если же выставить его в 60%, то получится, что вы ожидаете меньшего эффекта от сжатия, ибо согласно формуле получится, что размер бэкапа составит (60/100)*100=60 единиц. Итог: чем меньше значение коэффициента сжатия, тем лучше работает компрессия.
Кому-то это покажется интуитивно понятным, а кому-то привычнее видеть коэффициент сжатия «в 2 раза» или «в 3 раза». Это легко преобразовать – получится 1/N x 100%, то есть для «в два раза» будет 1/2 x 100%= 50%.
Подставим это значение в нашу формулу и получим: 50 backup size = 50% x (100 total data in)
Примечание: Если вы планируете вовсе отключить сжатие данных, установите значение этого коэффициента в 100%.
Про точки восстановления и политику хранения
У нас остались еще два параметра из формулы — F и R. Эти значения указывают, сколько вы хотите иметь полных бэкапов (Fulls) или инкрементальных бэкапов (incRements). С режимами Reverse incremental / Forever incremental все очевидно — для них будет:
F = 1
и
R = rps (общее число точек восстановления) — F
А если нужны weekly synthetics или active fulls? Тут все становится несколько сложнее, ибо нужно принимать во внимание настройки политики хранения. Например, если вам нужно строить инкрементальную цепочку forward incremental, делая вдобавок раз в неделю weekly full, а при этом политика предписывает хранить 2 точки восстановления (restore points), то у вас в какой-то момент может оказаться 9 точек – а все из-за зависимостей между инкрементами и полными бэкапами. Понятие «точка восстановления» нужно трактовать буквально (что и делает Veeam Backup & Replication) – это точка, из которой можно восстановиться. Если не будет полного бэкапа – «фундамента», от которого строится цепочка инкрементов-«этажей», то ни из какого инкремента-«этажа» восстановить машину («дом») будет нельзя.
Калькулятор-симулятор тоже иллюстрирует эту зависимость: после того, как вы выберете режим, введете предписанное политикой число точек в поле Retention points и укажете другие параметры, а затем нажмете Simulate, то в секции результатов в колонке Retention вы увидите пару чисел N1 (N2). Это означает, что точка восстановления номер N1 будет храниться (не будет удалена), т.к. от нее зависит другая точка (N2).
Если считать на бумажке или на обычном калькуляторе, то формула будет выглядеть так:
F = (число недель) + 1
R = (F x 7 x число ежедневных бэкапов — F)
Например, если надо хранить 14 точек, а бэкап запускать ежедневно, то получится:
F = 2+1 =3
R = 3 x 7 x 1 — 3 = 21 — 3 = 18
Другая тонкость состоит в понимании того, сколько места будет занимать еженедельный бэкап, а сколько ежемесячный. Помните, что ежемесячный бэкап может иметь цепочку и из 30 точек. Если же настроить еженедельный weekly full, то цепочка составит максимум 7 дней, т.е. места на СХД понадобится меньше. Однако если настроить политику на хранение, скажем, 60 точек, то ежемесячный monthly full может оказаться выгоднее еженедельного.
Вводная часть закончена, переходим к вводу
Как вы уже заметили, некоторые поля калькулятора соответствуют полям интерфейса Veeam Backup & Replication 8; на картинках показаны оба UI – для наглядности и еще большей убедительности.
Итак, определяемся с политикой хранения точек восстановления. Если вам нужно хранить ежедневные бэкапы (по одному в день) в количестве 14 штук, то в поле Retention points укажите 14, а в поле Interval укажите Daily.
Важно! Помните, что в определенные моменты времени хранимых точек будет больше, чем вы указали – поскольку в расчет принимается не только выставленное вами значение, но и зависимости между инкрементами и полными бэкапами. Поэтому не рвитесь редактировать эти значения только из-за того, что вам кажется излишками – а лучше еще раз внимательно перечитайте предыдущий раздел про F и R.
Количество задаваемых параметров зависит также и от того, что в нашем калькуляторе носит название Style (стиль, или способ создания точки восстановления, для которого нужно выполнить оценочные вычисления). Тут все аналогично консоли Veeam Backup & Replication. Например, возьмем «стиль» Backup Copy Job – очевидно, что если вы хотите сделать расчет для такого варианта, то будут использованы те же настройки, что вы задаете и при конфигурации Backup Copy Job в консоли Veeam:
Для других «стилей», названных Incremental и Reverse, параметры калькуляции будут соответствовать настройкам задания резервного копирования Backup Job (за исключением Retention Points):
Примечание: Если вы выберете Incremental вовсе без полных бэкапов (active fulls или synthetic fulls), вы получите бесконечную цепочку инкрементов.
Обращаю ваше внимание на различия в UI:
Пример №1: инкрементный бэкап с еженедельным synthetic full
В этом случае настройки должны быть аналогичны тем, что на этой картинке (слева то, что вы указали бы в консоли Veeam, справа то, что нужно указать в калькуляторе):
Примечание: Опцию “Transform” калькулятор не воспроизводит одной по простой причине – пока что о ней автора никто не просил :).
Пример №2: инкрементный бэкап с ежемесячным active full
Для расчета по сценарию с ежемесячным active full настройки должны быть такие, как на этой картинке:
Важно! Помните, что для задания бэкапа Backup Job нет схемы хранения GFS – такая схема может быть задана только в заданиях переноса резервных копий Backup Copy Job. (Один пользователь попробовал зачекать в задании бэкапа только январь, поскольку мечтал «иметь годовой бэкап для архива» — естественно, он был весьма удивлен, увидев, что получилось в результате его настроек. Разумеется, был сделан расчет по цепочке длиной в целый год, с созданием следующего полного бэкапа в январе).
Пример №3: реверсивный инкрементный бэкап
Для расчета же по Reverse incremental настройки должны быть такие:
А долгосрочные прогнозы делаете?
Осталось разъяснить только сову одну опцию – симуляцию растущего объема данных Time Growth Simulator. Это недавнее и, по-моему, довольно полезное изобретение. Суть его в том, что если вы хотите, скажем, сделать расчет прироста объема данных на 3 года вперед, и при этом известно, что объем данных на входе растет на 10% в год, то вам просто нужно зачекать галку рядом с Time Growth Simulator и указать этот период и эти %, выбрав нужные значения из выпадающих списков.
Калькулятор берет значение Used Size GB (о нем говорилось выше) и рассчитывает ежедневный прирост объема данных по формуле:
Future Used Data = Used Size x ( 1 + 10% ) ^ (Day N/365)
Таким образом, на последний рассчитываемый день (через 3 года) получится:
Future Used Data = Used Size x ( 1 + 10%) ^ (1095/365)
Пример №4
Предположим, что вы выбрали метод бэкапа Reverse incremental, хотите рассчитать требуемый объем на 3 года вперед, учитывая ежегодный рост объема данных на 10%, а изначальный объем Used Size у вас равен 1000GB (для простоты коэффициент сжатия учитывать не будем).
Рассчитаем по формуле Future Used Data через 3 года:
Future Used Data=1000 x (1+10%)^(1095/365) = 1000 x (110%)^3 = 1000 x (1,10)^3 = 1000 x 1,10 x 1,10 x 1,10 = 1331
Проверим наш расчет с помощью калькулятора-симулятора:
Кстати, заметьте, что у инкрементального бэкапа, который представляет точку восстановления, созданную за 2 дня до истечения 3-летнего срока, размер Future Used Data будет меньше – согласно все той же формуле:
Future Used Data = 1000 x (1+10%)^(1093/365) =
Для стандартных заданий резервного копирования разница не очень-то велика, но если делать расчеты, скажем, для задания Backup Copy Job с политикой хранения GFS, то можно увидеть более значительный прирост.
Ну и в завершение пара слов о Quick Presets – это типовые сценарии, которые чаще всего берутся для расчета. Например, сценарий Incremental Monthly Active Full рассчитает вам все ровно так же, как если бы вы выбрали Incremental в списке Style и зачекали все 12 месяцев в Active Full Monthly. Вот и все.
Синтетическое резервное копирование
Синтетическое резервное копирование Arcserve Backup
Современные программы бэкапа используют синтетическое резервное копирование. Давайте познакомимся с ним ближе
Это давало существенное сокращение времени и места хранения резервных копий, но приводило к большому проигрышу при восстановлении данных.
А как раз время восстановления и является критически важным. Как говорится, когда «земля горит под ногами. «.
Этот недостаток традиционных систем резервного копирования был преодолен с разработкой алгоритмов синтетического резервного копирования.
Этот алгоритм несет свои преимущества как при выполнении резервного копирования, так и при выполнении восстановления информации.
Синтетическая резервная копия при копировании
 При выполнении резервного копирования синтетический бэкап выглядит аналогично традиционному копированию. Но это только внешне. По факту, вы можете делать только одну, первую полную резервную копию. Далее достаточно выполнять только резервное копирование изменений. Программа бэкапа самостоятельно будет синтезировать полные резервные копии.
При выполнении резервного копирования синтетический бэкап выглядит аналогично традиционному копированию. Но это только внешне. По факту, вы можете делать только одну, первую полную резервную копию. Далее достаточно выполнять только резервное копирование изменений. Программа бэкапа самостоятельно будет синтезировать полные резервные копии.
Как это работает
F – полная резервная копия, созданная при первом запуске задания.
I4 – это традиционные инкрементные резервные копии.
I5 – это тоже инкрементная резервная копия, в которую выродилась идущая по графику полная. Эта сессия создаст полный каталог – каталог измененных файлов и неизмененных файлов..
Задание SFB соберет данные из сессий F, I1
I5 и синтезирует полную сессию F’.
Активирование синтетического резервного копирования

Активировать синтетическое резервное копирование в программе Arcserve Backup можно на этапе создания задания.
Далее определяются политики синтетического резервного копирования

Вы можете определить два очень важных параметра:
Подробная информация о программе для резервного копирования Arcserve Backup может быть найдена в статье » Arcserve Backup для Windows, Linux, UNIX, MacOS и FreeBSD » на этом сайте.
Преимущества нового метода резервного копирования виртуальных машин перед классическими схемами
Обычный прямой инкрементный метод, как правило, установлен по умолчанию, и потому чаще используется. Он основан на том, что при первом прогоне создается полная резервная копия и далее сохраняется цепь последующих инкрементов. Для того, чтобы повысить надежность такой цепочки резервных копий и сократить время восстановления (оно будет линейно расти по мере роста числа созданных инкрементов), периодически необходимо создавать либо новую полную копию, либо синтетическую. Количество инкрементов, через которое нужно заново создавать полную резервную копию указывается в параметрах схемы резервного копирования. Схематично процесс выглядит вот так:
Прямой метод обеспечивает высокую скорость обработки данных (I/O), так как требуется всего одна операция чтения/записи на каждый сохраняемый блок данных. Время создания инкремента и время «жизни» снапшота виртуальной машины невелико, что минимизирует нагрузку на продакшн. Однако, расход емкости СХД будет значительным, из-за хранения избыточного количества данных. Почему?
Избежать перерасхода дискового пространства позволяет реверсивный инкрементный метод. Механизм создания таких резервных копий немного сложнее: «свежие» инкременты внедряются в первоначально созданный полный бекап, а замещенные таким образом блоки данных из полной копии сохраняются как предшествующие ей.
Реверсивный инкрементный метод, во-первых, позволяет увеличить эффективность использования системы хранения за счет того, что в наличии всегда есть одна полная резервная копия и цепочка предшествующих ей инкрементов (при этом «лишние» инкременты регулярно удаляются согласно установленному сроку хранения). Во-вторых, время восстановления данных из резервной копии, созданной реверсивным методом, минимально, так как полная копия содержит наиболее актуальную версию данных и не нужно тратить время на анализ инкрементов.
Впрочем, и в этом алгоритме есть своё «но»: снижается скорость обработки данных и увеличивается время существования снапшота. На каждый сохраняемый блок данных требуется 3 операции чтения/записи: прочитать вытесняемый блок данных из полной копии, записать этот блок на СХД в виде реверсивного инкремента, и затем вписать в полную копию новый блок изменившихся данных. В результате, если система хранения не поддерживает такой уровень производительности, процесс резервного копирования будет займет много времени, а снапшот увеличит нагрузку на производственную среду.
Как избежать компромиссов
В Veeam Backup & Replication v8 реализован метод «прямого инкрементно-бесконечного» резервного копирования, который объединяет сильные стороны алгоритмов, рассмотренных выше, и позволяет получить сразу и скорость копирования данных, и быстрое восстановление, и экономное использование СХД.
При прямом инкрементно-бесконечном методе создается полная копия и цепочка последующих инкрементов, которые хранятся до тех пор, пока не будет достигнут установленный срок хранения (пусть будет N дней). В день N записывается последний инкремент цепочки, и на следующем прогоне задания резервного копирования произойдет следующее:
С течением времени подобная операция будет повторяться раз за разом по мере добавления новых инкрементов в цепочку.
Общее количество циклов чтения/записи останется таким же, как при реверсивном инкрементном резервном копировании, однако, важно то как именно будет проходить обработка данных. Для создания инкремента потребуется только одна операция I/O, а значит, снапшот виртуальной машины будет открыт меньше времени. Оставшиеся 2 операции чтения/записи нужны для того, чтобы обновить файл полной резервной копии, и снапшот при этом уже не задействован. Кроме того, процесс создания новой полной синтетической резервной копии сведется к добавлению одного инкремента, вместо объединения целой цепочки инкрементов, как это происходило бы в случае создания «прямого инкрементного» с полными синтетическими копиями. Процедура «схлопывания» самого древнего инкремента с полной копией будет происходить уже вне окна резервного копирования без нагрузки на производственную среду, а значит, «в окне» можно успеть сделать больше резервных копий (в синтетическом бэкапе объединение блоков происходит в одном окне с созданием резервных копий).