SVM регрессия (пример)
Материал из MachineLearning.
SVM (Support Vector Machine, машина опорных векторов) — это особый класс алгоритмов, который характеризуется использованием ядер, отсутствием локальных минимумов, и используется для решения задач классификации и регрессии. В этой статье рассматривается пример использования метода опорных векторов в задачах регрессии.
Содержание
Постановка задачи
Алгоритм
Тогда функционал примет вид:

В предположении что
Для этого вводятся обозначение и дополнительные переменные и :
Геометрический смысл и :
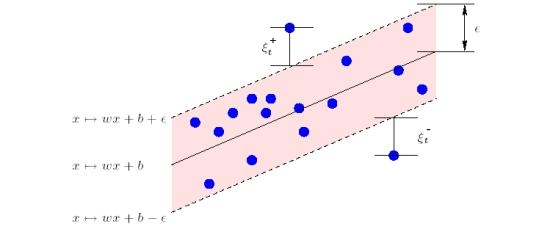
Далее решается задача квадратичного программирования:
Таким образом, мы свели задачу к задаче квадратичного программирования.
В нашем примере значения С, и порождающие функции задаются экспертом.
Вычислительный эксперимент
Вычислительный эксперимент состоит из трех основных частей:
Генерация данных
Нормальное распределение
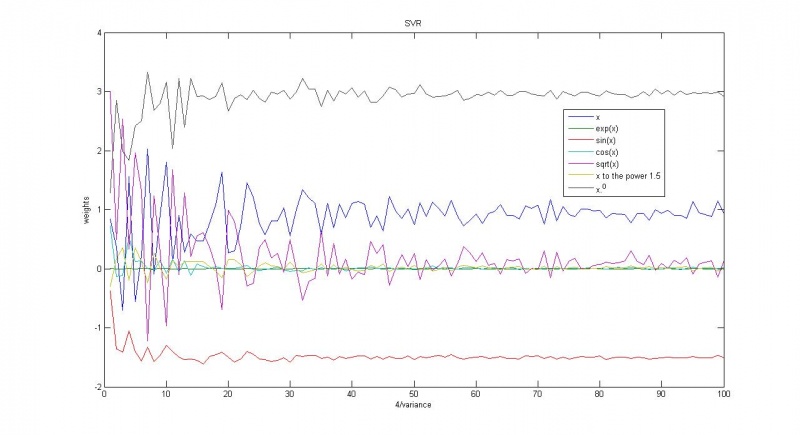
Зависимость весов соответствующих функций от обратной дисперсии
Пуассоновское распределение
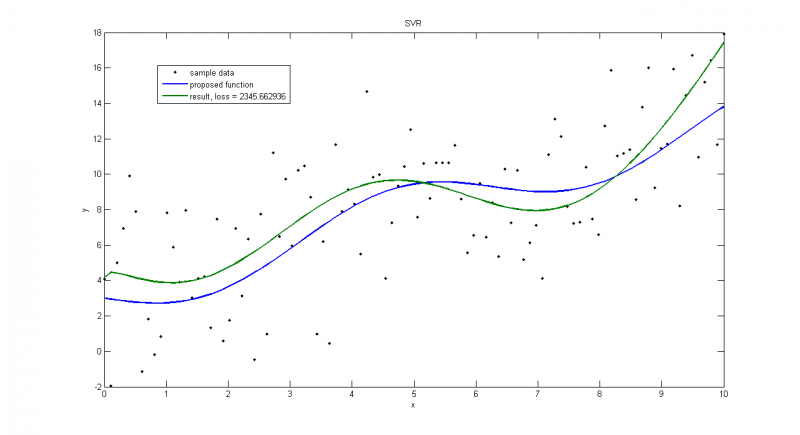
Пуассоновское распределение с большой дисперсией
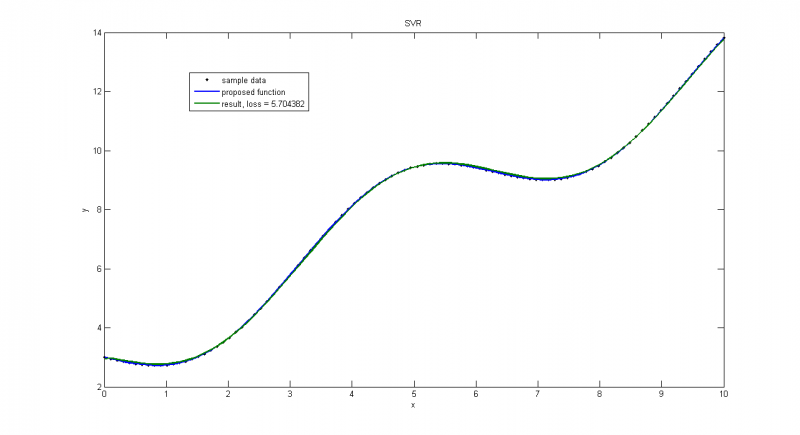
Пуассоновское распределение с малой дисперсией, получаем почти точное решение
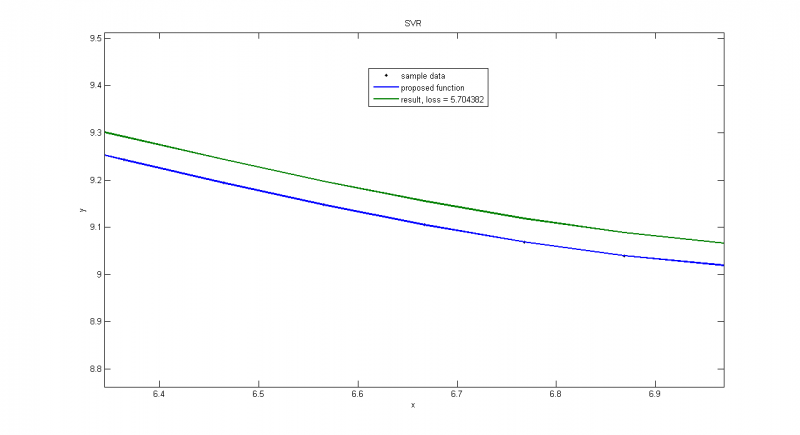
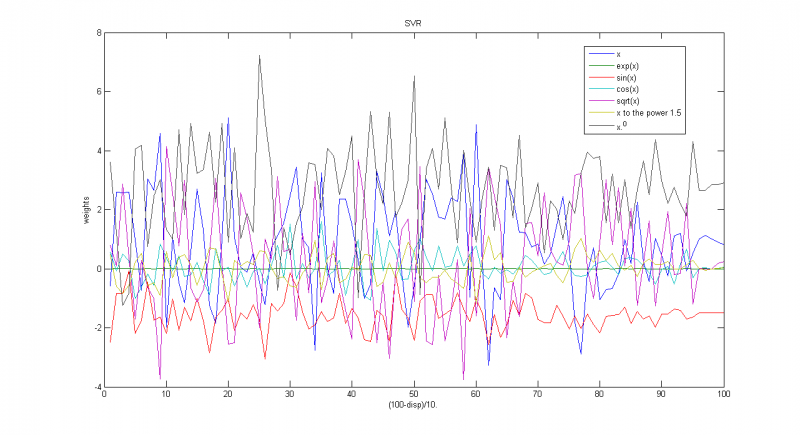
Зависимость весов соответствующих функций от параметра
Равномерное распределение
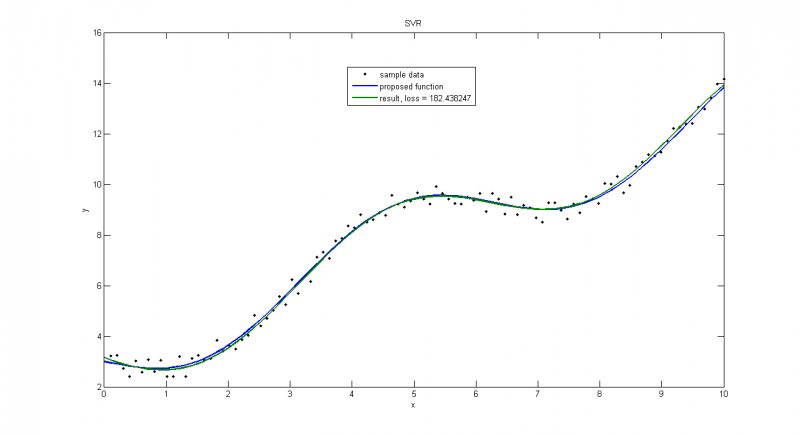
Работа алгоритма на примере с равномерным шумом. На этом графике шум равномерно распределен на отрезке
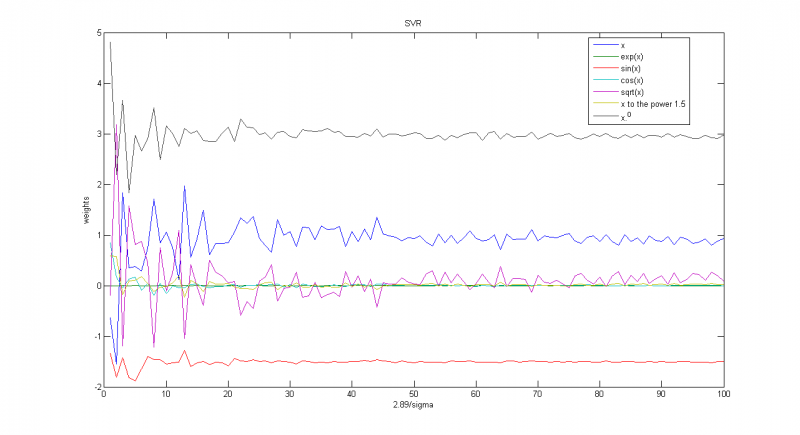
Зависимость весов соответствующих функций от параметра
Распределение sin(unif)
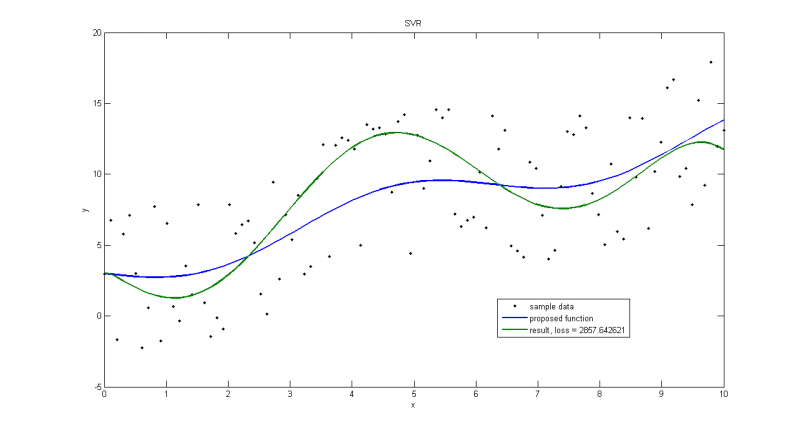
Если выбрать большую амплитуду(=5), решение может сильно отличаться от верного
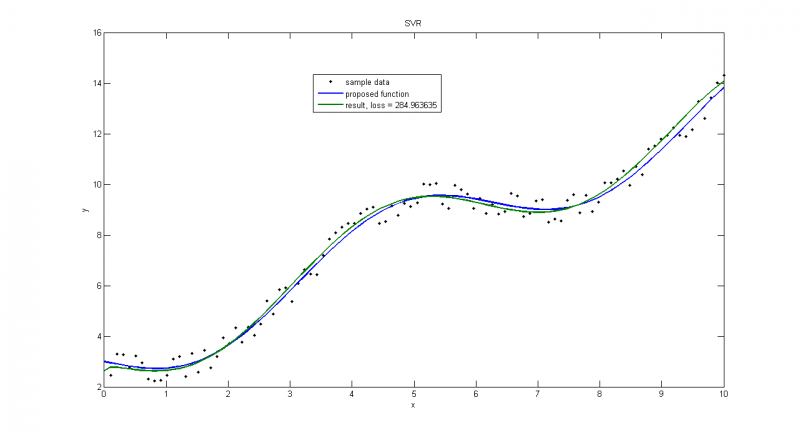
При малых(=0.5) такого не наблюдается.
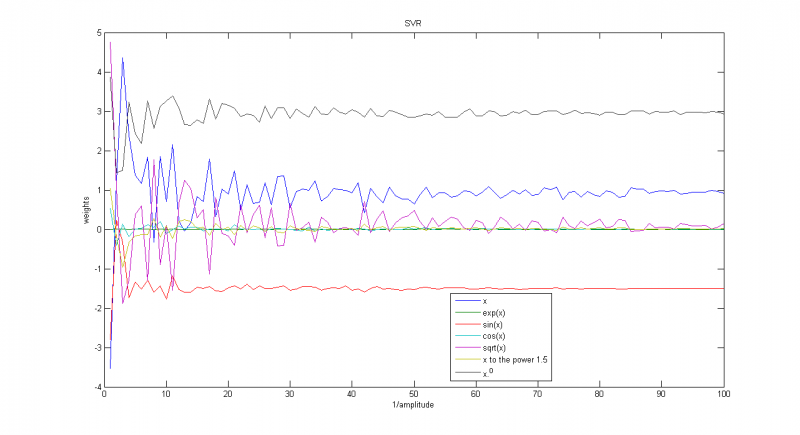
Зависимость весов соответствующих функций от параметра
Реальные данные
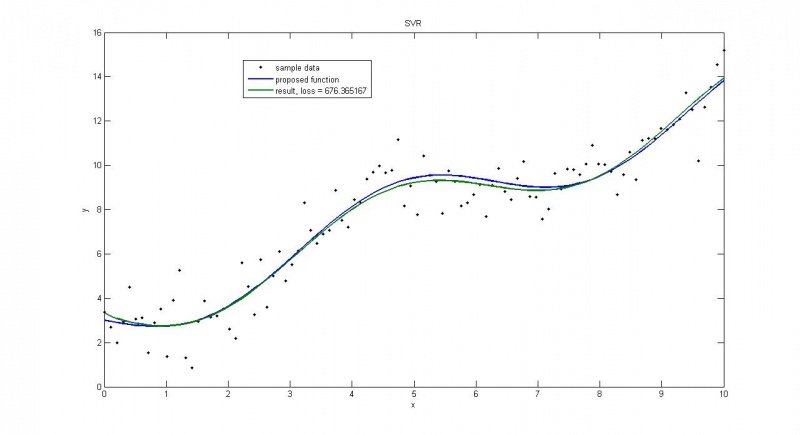
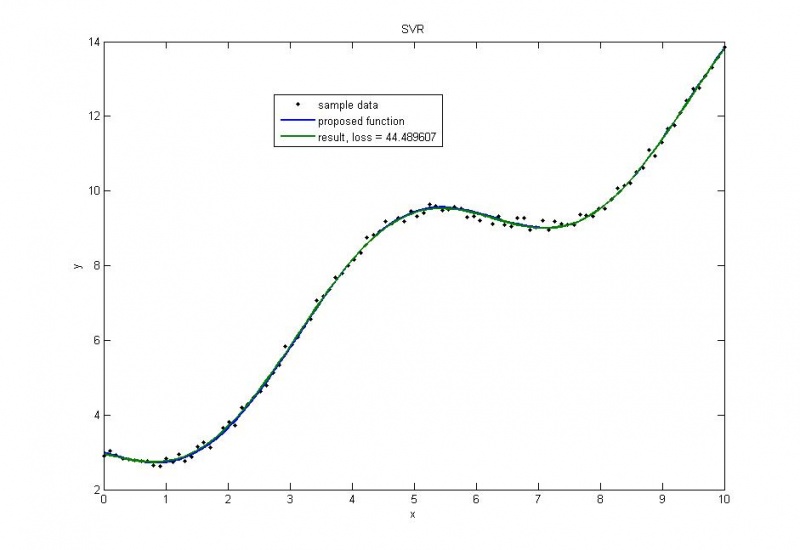
Пример взят из Репозитория UCI. В этом примере рассматриваются автомобили 1970-1973 года выпуска. Строится зависимость мощности автомобиля [л.с.] от веса [кг]
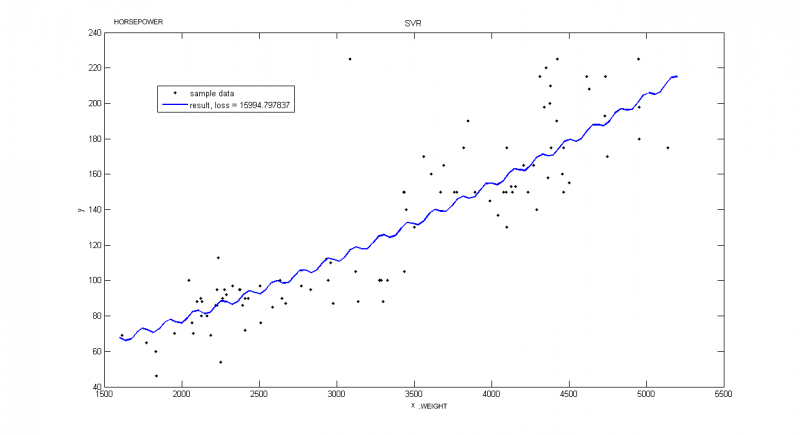
Пример иллюстрирует, что очень важно правильно выбирать порождающие функции. Хотя потери меньше, чем на следующем графике, такое решение не является достаточно точным.
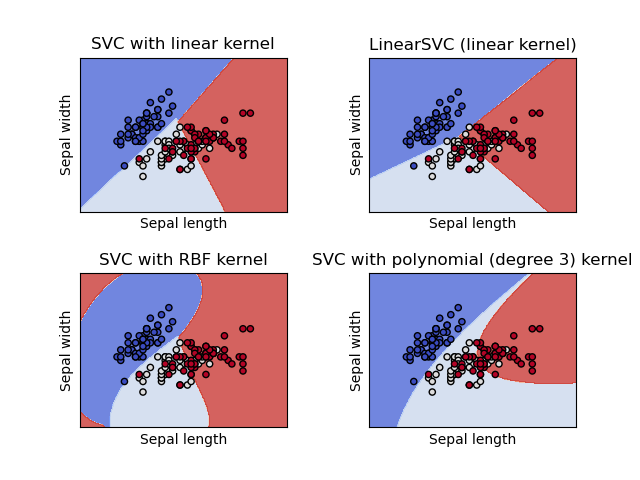
Метод опорных векторов (SVM)
Метод опорных векторов (англ. support vector machine, SVM) — один из наиболее популярных методов обучения, который применяется для решения задач классификации и регрессии. Основная идея метода заключается в построении гиперплоскости, разделяющей объекты выборки оптимальным способом. Алгоритм работает в предположении, что чем больше расстояние (зазор) между разделяющей гиперплоскостью и объектами разделяемых классов, тем меньше будет средняя ошибка классификатора.
Содержание
Метод опорных векторов в задаче классификации [ править ]
Разделяющая гиперплоскость [ править ]
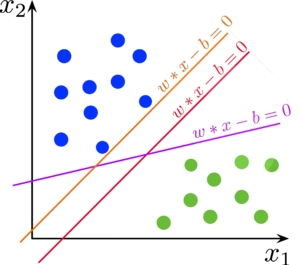
Линейно разделимая выборка [ править ]
Но для двух линейно разделимых классов возможны различные варианты построения разделяющих гиперплоскостей. Метод опорных векторов выбирает ту гиперплоскость, которая максимизирует отступ между классами:
Если выборка линейно разделима, то существует такая гиперплоскость, отступ от которой до каждого объекта положителен:
Мы хотим построить такую разделяющую гиперплоскость, чтобы объекты обучающей выборки находились на наибольшем расстоянии от неё.
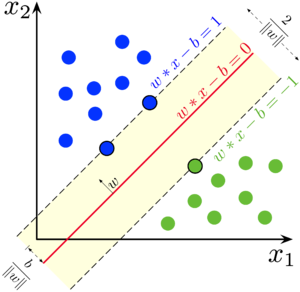
Заметим, что мы можем упростить постановку задачи:
Получим эквивалентную задачу безусловной минимизации:
Теперь научимся её решать.
| Теорема (Условия Каруша—Куна—Таккера): | ||||||||||||||||||||




| $\alpha^<0>_<0,1>$ | $\alpha^<0>_<0,2>$ | Коэффициенты для КА класса 0 |
| $\alpha^<1>_<0,1>$ | $\alpha^<1>_<0,2>$ | Коэффициенты для КА класса 0 |
| $\alpha^<2>_<0,1>$ | $\alpha^<2>_<0,2>$ | Коэффициенты для КА класса 0 |
| $\alpha^<0>_<1,0>$ | $\alpha^<0>_<1,2>$ | Коэффициенты для КА класса 1 |
| $\alpha^<1>_<1,0>$ | $\alpha^<1>_<1,2>$ | Коэффициенты для КА класса 1 |
| $\alpha^<0>_<2,0>$ | $\alpha^<0>_<2,1>$ | Коэффициенты для КА 2 класса |
| $\alpha^<1>_<2,0>$ | $\alpha^<1>_<2,1>$ | Коэффициенты для КА 2 класса |
1.4.1.2. Результаты и вероятности
Перекрестная проверка, связанная с масштабированием Platt, — дорогостоящая операция для больших наборов данных. Кроме того, оценки вероятности могут не соответствовать оценкам:
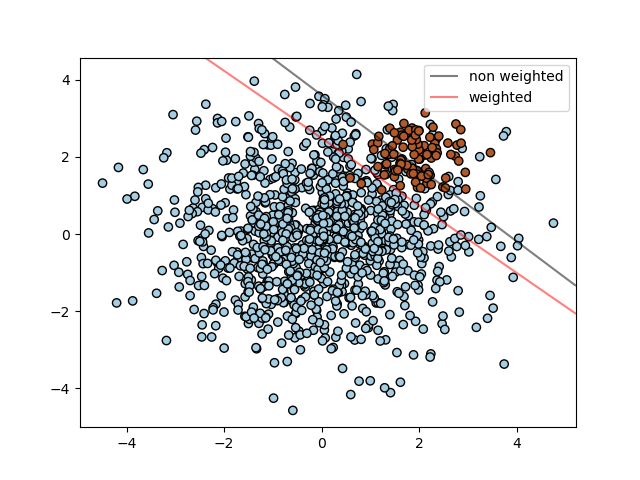
1.4.1.3. Несбалансированные проблемы
SVC (но не NuSVC ) реализует параметр class_weight в fit методе. Это словарь формы , где значение — это число с плавающей точкой number > 0, которое устанавливает С для параметра класса class_label значение C * value. На рисунке ниже показана граница решения несбалансированной проблемы с поправкой на вес и без нее.
1.4.2. Регрессия
Метод классификации опорных векторов может быть расширен для решения задач регрессии. Этот метод называется регрессией опорных векторов.
Модель, созданная с помощью классификации опорных векторов (как описано выше), зависит только от подмножества обучающих данных, потому что функция затрат для построения модели не заботится о точках обучения, которые лежат за пределами поля. Аналогичным образом модель, созданная с помощью регрессии опорных векторов, зависит только от подмножества обучающих данных, поскольку функция стоимости игнорирует образцы, прогноз которых близок к их целевому значению.
Как и в случае с классами классификации, метод соответствия будет принимать в качестве аргументов векторы X, y, только в этом случае ожидается, что y будет иметь значения с плавающей запятой вместо целочисленных значений:
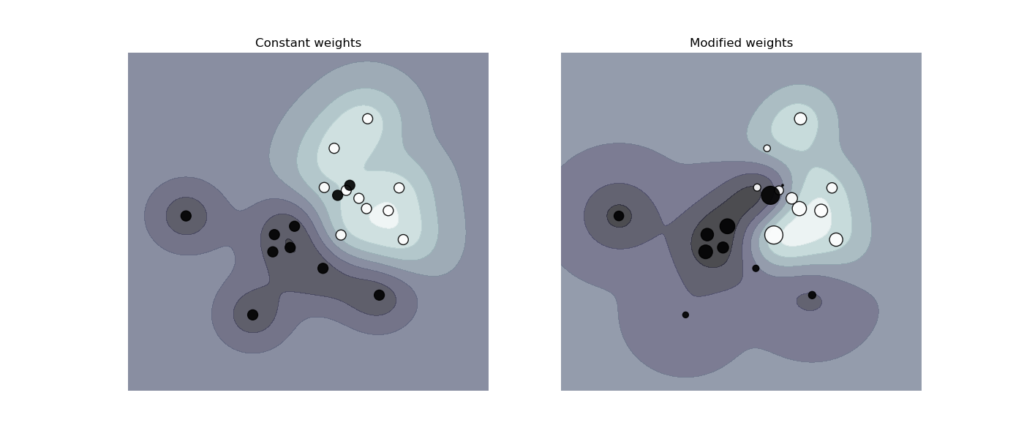
1.4.3. Оценка плотности, обнаружение новизны
Класс OneClassSVM реализует одноклассную SVM, которая используется для обнаружения выбросов.
См. Раздел Обнаружение новинок и выбросов для описания и использования OneClassSVM.
1.4.4. Сложность
1.4.5. Советы по практическому использованию
См. Раздел « Предварительная обработка данных» для получения более подробной информации о масштабировании и нормализации.
1.4.6. Функции ядра
Функция ядра может быть любой из следующих:
Разные ядра задаются kernel параметром:
1.4.6.1. Параметры ядра RBF
Правильный выбор C и gamma имеет решающее значение для производительности SVM. Рекомендуется использовать GridSearchCV с C и gamma экспоненциально далеко друг от друга, чтобы выбрать хорошие значения.
1.4.6.2. Пользовательские ядра
Вы можете определить свои собственные ядра, указав ядро как функцию Python или предварительно вычислив матрицу Грама.
Классификаторы с пользовательскими ядрами ведут себя так же, как и любые другие классификаторы, за исключением того, что:
1.4.6.2.1. Использование функций Python в качестве ядер
Вы можете использовать собственные определенные ядра, передав функцию kernel параметру.
Ваше ядро должно принимать в качестве аргументов две матрицы формы (n_samples_1, n_features), (n_samples_2, n_features) и возвращает матрицу ядра в форме (n_samples_1, n_samples_2)
Следующий код определяет линейное ядро и создает экземпляр классификатора, который будет использовать это ядро:
1.4.6.2.2. Используя матрицу Грама
Вы можете передать предварительно вычисленные ядра, используя kernel=’precomputed’ параметр. Затем вы должны передать матрицу Грама вместо X к fit и predict методам. Должны быть предоставлены значения ядра между всеми обучающими векторами и тестовыми векторами:
1.4.7. Математическая постановка
Машина опорных векторов конструирует гиперплоскость или набор гиперплоскостей в пространстве большой или бесконечной размерности, которые можно использовать для классификации, регрессии или других задач. Интуитивно хорошее разделение достигается за счет гиперплоскости, которая имеет наибольшее расстояние до ближайших точек обучающих данных любого класса (так называемый функциональный запас), поскольку, как правило, чем больше запас, тем ниже ошибка обобщения классификатора. На рисунке ниже показана функция решения для линейно разделяемой задачи с тремя образцами на границах запаса, называемыми «векторами поддержки»:
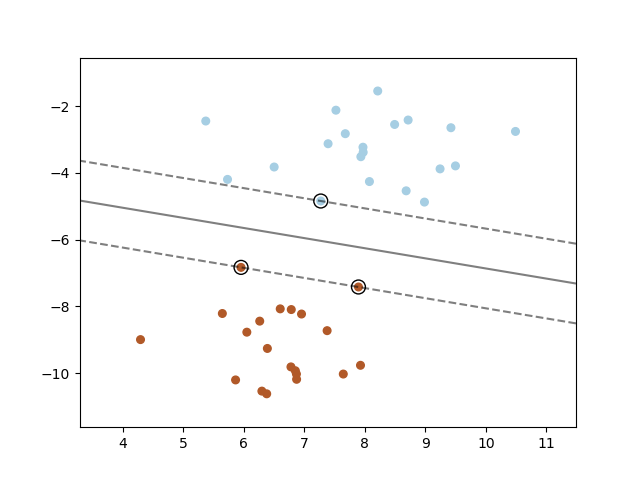
В общем, когда проблема не является линейно разделимой, опорные векторы являются выборками в пределах границ поля.
Мы рекомендуем 13 и 14 как хорошие справочные материалы по теории и практике SVM.
1.4.7.1. SVC
SVC решает следующую основную проблему:
$$\min_
$$\textrm
$$\zeta_i \geq 0, i=1, …, n$$
Двойственная проблема первобытного:
$$\min_ <\alpha>\frac<1> <2>\alpha^T Q \alpha — e^T \alpha$$
$$\textrm
$$0 \leq \alpha_i \leq C, i=1, …, n$$
Как только проблема оптимизации решена, выходные данные функции решения для данной выборкиx становится:
$$\sum_
1.4.7.2. LinearSVC
Первичную задачу можно эквивалентно сформулировать как
$$\min_
1.4.7.3. NuSVC
1.4.7.4. SVR
Двойная проблема:
$$\min_ <\alpha, \alpha^*>\frac<1> <2>(\alpha — \alpha^*)^T Q (\alpha — \alpha^*) + \varepsilon e^T (\alpha + \alpha^*) — y^T (\alpha — \alpha^*)$$
$$\textrm
$$0 \leq \alpha_i, \alpha_i^* \leq C, i=1, …, n$$
Прогноз такой:
$$\sum_(\alpha_i — \alpha_i^*) K(x_i, x) + b$$
1.4.7.5. LinearSVR
Первичную задачу можно эквивалентно сформулировать как
$$\min_
1.4.8. Детали реализации
Внутри мы используем libsvm 12 и liblinear 11 для обработки всех вычислений. Эти библиотеки обернуты с использованием C и Cython. Описание реализации и детали используемых алгоритмов см. В соответствующих документах.
Краткий обзор алгоритма машинного обучения Метод Опорных Векторов (SVM)
Предисловие

В данной статье мы изучим несколько аспектов SVM:
Как известно, задачи машинного обучения разделены на две основные категории — классификация и регрессия. В зависимости от того, какая из этих задач перед нами стоит, и какой у нас имеется датасет для этой задачи, мы выбираем какой именно алгоритм использовать.
Метод Опорных Векторов или SVM (от англ. Support Vector Machines) — это линейный алгоритм используемый в задачах классификации и регрессии. Данный алгоритм имеет широкое применение на практике и может решать как линейные так и нелинейные задачи. Суть работы “Машин” Опорных Векторов проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы.
Теория
Основной задачей алгоритма является найти наиболее правильную линию, или гиперплоскость разделяющую данные на два класса. SVM это алгоритм, который получает на входе данные, и возвращает такую разделяющую линию.
Рассмотрим следующий пример. Допустим у нас есть набор данных, и мы хотим классифицировать и разделить красные квадраты от синих кругов (допустим позитивное и отрицательное). Основной целью в данной задаче будет найти “идеальную” линию которая разделит эти два класса.

Найдите идеальную линию, или гиперплоскость, которая разделит набор данных на синий и красный классы.
На первый взгляд, не так уж и сложно, правда?
Но, как вы можете заметить, нет одной, уникальной, линии, которая бы решала такую задачу. Мы можем подобрать бесконечное множество таких линий, которые могут разделить эти два класса. Как же именно SVM находит “идеальную” линию, и что в его понимании “идеальная”?
Взгляните на пример ниже, и подумайте какая из двух линий (желтая или зеленая) лучше всего разделяет два класса, и подходит под описаниие “идеальной”?
Какая линия лучше разделяет набор данных по вашему мнению?
Если вы выбрали желтую прямую, я вас поздравляю: это та самая линия, которую бы выбрал алгоритм. В данном примере мы можем интуитивно понять что желтая линия разделяет и соответственно классифицирует два класса лучше зеленой.
В случае с зеленой линией — она расположена слишком близко к красному классу. Несмотря на то, что она верно классифицировала все объекты текущего набора данных, такая линия не будет генерализованной — не будет так же хорошо вести себя с незнакомым набором данных. Задача нахождения генерализованной разделяющей двух классов является одной из основных задач в машинном обучении.
Как SVM находит лучшую линию
Алгоритм SVM устроен таким образом, что он ищет точки на графике, которые расположены непосредственно к линии разделения ближе всего. Эти точки называются опорными векторами. Затем, алгоритм вычисляет расстояние между опорными векторами и разделяющей плоскостью. Это расстояние которое называется зазором. Основная цель алгоритма — максимизировать расстояние зазора. Лучшей гиперплоскостью считается такая гиперплоскость, для которой этот зазор является максимально большим.
Довольно просто, не так ли? Рассмотрим следующий пример, с более сложным датасетом, который нельзя разделить линейно.
Очевидно, что этот набор данных нельзя разделить линейно. Мы не можем начертить прямую линию, которая бы классифицировала эти данные. Но, этот датасет можно разделить линейно, добавив дополнительное измерение, которое мы назовем осью Z. Представим, что координаты на оси Z регулируются следующим ограничением:

Таким образом, ордината Z представлена из квадрата расстояния точки до начала оси.
Ниже приведена визуализация того же набора данных, на оси Z.
Теперь данные можно разделить линейно. Допустим пурпурная линия разделяющая данные z=k, где k константа. Если
, то следовательно и

— формула окружности. Таким образом, мы можем спроэцировать наш линейный разделитель, обратно к исходному количеству измерений выборки, используя эту трансформацию.
В результате, мы можем классифицировать нелинейный набор данных добавив к нему дополнительное измерение, а затем, привести обратно к исходному виду используя математическую трансформацию. Однако, не со всеми наборами данных можно с такой же легкостью провернуть такую трансформацию. К счастью, имплементация этого алгоритма в библиотеке sklearn решает эту задачу за нас.
Гиперплоскость
Теперь, когда мы ознакомились с логикой алгоритма, перейдем к формальному определению гиперплоскости
Гиперплоскость — это n-1 мерная подплоскость в n-мерном Евклидовом пространстве, которая разделяет пространство на две отдельные части.
Например, представим что наша линия представлена в виде одномерного Евклидова пространства (т.е. наш набор данных лежит на прямой). Выберите точку на этой линии. Эта точка разделит набор данных, в нашем случае линию, на две части. У линии есть одна мера, а у точки 0 мер. Следовательно, точка — это гиперплоскость линии.
Для двумерного датасета, с которым мы познакомились ранее, разделяющая прямая была той самой гиперплоскостью. Проще говоря, для n-мерного пространства существует n-1 мерная гиперплоскость, разделяющая это пространство на две части.
Точки представлены в виде массива X, а классы к которому они принадлежат в виде массива y.
Теперь мы обучим нашу модель этой выборкой. Для данного примера я задал линейный параметр “ядра” классификатора (kernel).
Предсказание класса нового объекта
Настройка параметров
Параметры — это аргументы которые вы передаете при создании классификатора. Ниже я привел несколько самых важных настраиваемых параметров SVM:
Данный параметр помогает отрегулировать ту тонкую грань между “гладкостью” и точностью классификации объектов обучающей выборки. Чем больше значение “С” тем больше объектов обучающей выборки будут правильно классифицированы.
В данном примере есть несколько порогов принятия решений, которые мы можем определить для этой конкретной выборки. Обратите внимание на прямую (представлена на графике в виде зеленой линии) порога решений. Она довольно таки проста, и по этой причине, несколько объектов были классифицированы неверно. Эти точки, которые были классифицированы неправильно называются выбросами в данных.
Мы также можем настроить параметры таким образом, что в конечном итоге получим более изогнутую линию (светло-голубой порог решений), которая будет классфицировать асболютно все данные обучающей выборки правильно. Конечно, в таком случае, шансы того, что наша модель сможет генерализовать и показать столь же хорошие результаты на новых данных, катастрофически мала. Следовательно, если вы пытаетесь достигнуть точности при обучении модели, вам стоит нацелиться на что-то более ровное, прямое. Чем выше число “С” тем более запутанная гиперплоскость будет в вашей модели, но и выше число верно-классифицированных объектов обучающей выборки. Поэтому, важно “подкручивать” параметры модели под конкретный набор данных, чтобы избежать переобучения но, в то же время достигнуть высокой точности.
В официальной документации библиотека SciKit Learn говорится, что гамма определяет насколько далеко каждый из элементов в наборе данных имеет влияние при определении “идеальной линии”. Чем ниже гамма, тем больше элементов, даже тех, которые достаточно далеки от разделяющей линии, принимают участие в процессе выбора этой самой линии. Если же, гамма высокая, тогда алгоритм будет “опираться” только на тех элементах, которые наиболее близки к самой линии.
Если задать уровень гаммы слишком высоким, тогда в процессе принятия решения о расположении линии будут учавствовать только самые близкие к линии элементы. Это поможет игнорировать выбросы в данных. Алгоритм SVM устроен таким образом, что точки расположенные наиболее близко относительно друг друга имеют больший вес при принятии решения. Однако при правильной настройке «C» и «gamma» можно добиться оптимального результата, который построит более линейную гиперплоскость игнорирующую выбросы, и следовательно, более генерализуемую.
Заключение
Я искренне надеюсь, что эта статья помогла вам разобраться в сути работы SVM или Метода Опорных Векторов. Я жду от вас любых комментариев и советов. В последующих публикациях я расскажу о математической составляющей SVM и о проблемах оптимизации.