SQL-запросы по-быстрому: краткий и понятный гайд



SQL (Structured Query Language) — это язык структурированных запросов. Он позволяет читать, записывать, удалять, сортировать и фильтровать информацию в базе данных.
В SQL используется немного слов. Он напоминает человеческий язык и поэтому его легко изучить. С его помощью можно работать с реляционными базами данных: пользователь отправляет SQL-запрос к базе данных через систему управления базами данных (СУБД). Последняя обрабатывает запрос и отправляет полученные данные пользователю.
Структура SQL-запроса
Запрос на выборку данных выглядит вот так:
Рассмотрим подробнее, как производится выборка.
SELECT и FROM
SELECT и FROM — обязательные ключевые слова в этом запросе. С их помощью можно указать, откуда и какие данные можно выбрать:
Обратите внимание: имена столбцов указываются через запятую.
Для выборки всех столбцов применяется групповой символ «*». При его использовании столбцы будут возвращены, но иногда порядок может не соблюдаться.
Групповой символ упрощает запрос, но при этом снижает производительность. Поэтому лучше использовать его в редких случаях.
WHERE
Обычно нам нужна определенная информация из таблицы. Но как ее быстро найти? WHERE помогает извлечь информацию, отфильтровав ее по одному или нескольким условиям. Это очень удобно!
С WHERE применяются такие операции:
Фильтр по нескольким условиям
Данные можно фильтровать не только по одному, а и по нескольким условиям и значениям. Для этого используются операторы IN, NOT IN, AND, OR.
В результате этого запроса будут выбраны все сотрудники из подразделений ИТ и маркетинга.
Будут выбраны все сотрудники, кроме тех, кто работает в подразделениях ИТ и маркетинга.
GROUP BY
С помощью необязательного предложения GROUP BY создаются группы данных. Это удобно для получения итоговых значений. Например, нужно узнать, сколько человек работает в отделе продаж. Инструкция может выглядеть так:
Этот код возвращает названия подразделений и количество работников в каждом из них. Количество сотрудников помещается в столбец с псевдонимом cnt, который мы задали с помощью ключевого слова AS.
Предложение GROUP BY указывается после WHERE и перед ORDER BY.
В GROUP BY можно указать столько столбцов, сколько нужно. В результате группы вкладываются друг в друга.
При вложении данные будут суммироваться для последней заданной группы, а не для отдельно для каждого столбца.
В предложении GROUP BY можно указать только столбцы выборки или выражения. В нем не указывается функция группирования и не применяются псевдонимы.
Если в столбце, по которому производится группирование, встречается одна или несколько строк со значением NULL, они выделяются в отдельную группу.
HAVING
С помощью предложения GROUP BY можно также указывать, какие группы включить в результат, а какие — исключить из него. Для этого используется предложение HAVING. Оно очень напоминает WHERE, но фильтрует не строки, а группы.
HAVING можно использовать с любыми операторами. В этом предложении используется тот же синтаксис, что и в предложении WHERE:
Этот код похож на предыдущий, но возвращает только те группы, в которых найдены три или больше сотрудников. Фильтрация выполняется по итоговому значению группы. Этим HAVING отличается от WHERE, которое фильтрует по значениям строк.
Эти предложения можно использовать вместе. Например, можно узнать, сколько сотрудников в подразделениях со штатом более трех человек, получают более 1000:
Сначала выбираются все строки, где в столбце salary содержатся значения больше 1000. А затем выбираются только те группы, в которых не меньше трех записей.
ORDER BY
Предложение ORDER BY используется для сортировки результатов запроса. В нем указываются имена столбцов, по которым нужна сортировка.
Давайте отсортируем список фамилий сотрудников:
В предложении ORDER BY можно указывать и те столбцы, которые не выбраны в операторе SELECT:
Так список фамилий сотрудников будет отсортирован по размеру зарплаты.
Сортировку можно выполнять и по нескольким столбцам. Для этого имена столбцов указывают через запятую:
Так мы увидим список сотрудников, который сначала отсортирован по фамилии, а затем — по имени.
Вместо имен столбцов можно указать их порядковые номера в операторе SELECT:
Этот код также возвращает список сотрудников с сортировкой по фамилии, а затем — по имени.
Сортировка по убыванию
В предыдущих примерах мы сортировали по возрастанию (это делается по умолчанию). Но можно сортировать и по убыванию. Для этого укажем слово DESC:
Так мы отсортируем список с именами и фамилиями в обратном алфавитном порядке.
Если обратная сортировка выполняется по нескольким столбцам, укажите ключевое слово DESC после каждого из них.
Слово DESC — это сокращение от слова DESCENDING. В запросах можно использовать как полную, так и сокращенную форму. Для сортировки в порядке возрастания тоже существует ключевое слово. Его полная форма — ASCENDING, а сокращенная — ASC. Поскольку по умолчанию выполняется сортировка по возрастанию, то это слово не указывают.
Объединение таблиц
Иногда нам нужны данные из нескольких таблиц. Рассмотрим пример:
Этот код возвратит имена и фамилии сотрудников из таблицы Employees и номера заказов из таблицы Orders, которые выполнены соответствующими сотрудниками. В предложении WHERE имена столбцов указаны с именами соответствующих таблиц. Это необходимо, чтобы СУБД могла различать столбцы employee_id из разных таблиц.
Такое объединение называется внутренним. Для него можно использовать специальный синтаксис с ключевым словом INNER JOIN. Приведенный ниже код выдаст те же результаты, что и предыдущий фрагмент:
Вместо предложения WHERE используется предложение ON, синтаксис которого совпадает с синтаксисом WHERE.
Число объединяемых таблиц в SQL не ограничено, но может ограничиваться в разных СУБД. Обратите внимание: чем больше таблиц объединяется, тем ниже производительность. Поэтому не рекомендуем объединять таблицы без особой необходимости.
Вместо заключения
SQL — простой для освоения и при этом мощный язык. Он появился в 1970-х и до сих пор используется, хотя наряду с ним появляются новые похожие языки. Этот язык используется различными СУБД: MySQL, SQLite, Oracle Database, Microsoft Access, Microsoft SQL Server, dBASE, IBM DB2.
Сегодня SQL — не просто язык формирования запросов. С его помощью можно упорядочивать и изменять данные, делать выборки, управлять доступом к ним, совместно использовать информацию и обеспечивать ее целостность. Пользуйтесь!
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Как исправить ошибку доступа к базе 1045 Access denied for user
Основные понятия о шардинге и репликации
Примеры ad-hoc запросов и технологии для их исполнения
Настройка Master-Master репликации на MySQL за 6 шагов
Как создать и использовать составной индекс в Mysql
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Синтаксис и оптимизация Mysql LIMIT
Типы и способы применения репликации на примере MySQL
Настройка Master-Slave репликации на MySQL за 6 простых шагов
Check-unused-keys для определения неиспользуемых индексов в базе данных
Запрос для определения версии Mysql: SELECT version()
Правильная настройка Mysql под нагрузки и не только. Обновлено.
3 примера установки индексов в JOIN запросах
И как правильно работать с длительными соединениями в MySQL
Быстрый подсчет уникальных значений за разные периоды времени
Анализ медленных запросов с помощью EXPLAIN
Описание, рекомендации и значение параметра query_cache_size
Что значит и как это починить
Использование партиций для ускорения сложных удалений
Правила выбора типов данных для максимальной производительности в Mysql
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Как думать на SQL?
Если вы похожи на меня, то согласитесь: SQL — это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:

У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM — откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE — какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк, которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author — это “Dan Brown”.
3.3 SELECT — как показываем данные
Весь запрос можно визуализировать с помощью простой диаграммы:
4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
borrowings JOIN books ON borrowings.bookid=books.bookid — это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения bookid совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Результат соединения можно увидеть по ссылке.
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Каждая строка в результате представляет собой результат агрегирования каждой группы.

В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов — использовать подзапросы:
| author | sum |
|---|---|
| Robin Sharma | 4 |
6.2 Одномерный массив
Запросы, которые возвращают несколько строк одной колонки, можно использовать не только как двумерные таблицы, но и как массивы.
Допустим, мы хотим узнать названия и идентификаторы всех книг, написанных определенным автором, но только если в библиотеке таких книг больше трех. Разобьем это на два шага:
1. Получаем список авторов с количеством книг больше 3. Дополняя наш прошлый пример:
| author |
|---|
| Robin Sharma |
| Dan Brown |
Можно записать как: [‘Robin Sharma’, ‘Dan Brown’]
2. Теперь используем этот результат в новом запросе:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
Теперь, наконец, можно написать весь запрос:
Это то же самое, что:
| bookid | title | author | published | stock |
|---|---|---|---|---|
| 3 | Who Will Cry When You Die? | Robin Sharma | 2006-06-15 00:00:00 | 4 |
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT ‘ом, мы задаем знаения SET ‘ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:

7.2 Delete
7.3 Insert
8. Проверка
Вот он в более удобном для чтения виде:
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Обзор основных SQL запросов


Каждый сайт в Интернете, любой проект, обрабатывающий значительный объем информации, вынужден хранить эту информацию в тех или иных базах данных (БД). Подавляющее большинство проектов информацию сохраняют в БД реляционного типа, делая записи в различных подобиях таблиц. Как внесение новых записей, так и обращение к имеющимся, осуществляется с благодаря использованию запросов, составляемых конструкциями SQL (structured query language) – непроцедурного декларативного языка структурированных запросов. В нашем случае это подразумевает, что, используя конструкции SQL, мы будем обращаться к БД, сообщая что нужно сделать с данными, но не указывая способ, как именно это нужно сделать.
Основываясь на указанных стандартах языка SQL, ряд организаций выпустили свои, расширенные версии стандартов указанного языка. Подобные версии иногда называют диалектами SQL.
Варианты спецификаций SQL разрабатываются компаниями и сообществами и служат, соответственно, для работы с разными СУБД (Системами Управления Базами Данных) – системами программ, заточенных под работу с продуктами из своей инфраструктуры.
Наиболее применяемые на сегодня СУБД, использующие свои стандарты (расширения) SQL:
MySQL – СУБД, принадлежащая компании Oracle.
PostgreSQL – свободная СУБД, поддерживаемая и развиваемая сообществом.
Microsoft SQL Server – СУБД, принадлежащая компании Microsoft. Применяет диалект Transact-SQL (T-SQL).
Благодаря тому, что диалекты SQL что создаются, специфицируются и используются разными организациями, имеют как общие черты, так и ряд отличий в возможностях расширений.
Общими чертами диалектов являются основные конструкции, применимые практически без отличий во многих реляционных БД. Основные отличия диалектов состоят в различиях использованных типов данных, количеством, реализацией и детальными возможностями команд. Разные диалекты применяют как разные наборы зарезервированных слов, так и разные наборы команд.
Здесь мы будем рассматривать запросы, применяя конструкции из спецификаций диалекта T-SQL.
Коснемся классификации SQL запросов.
Выделяют такие виды SQL запросов:
DDL (Data Definition Language) — язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
Основные типы SQL запросов по их видам:
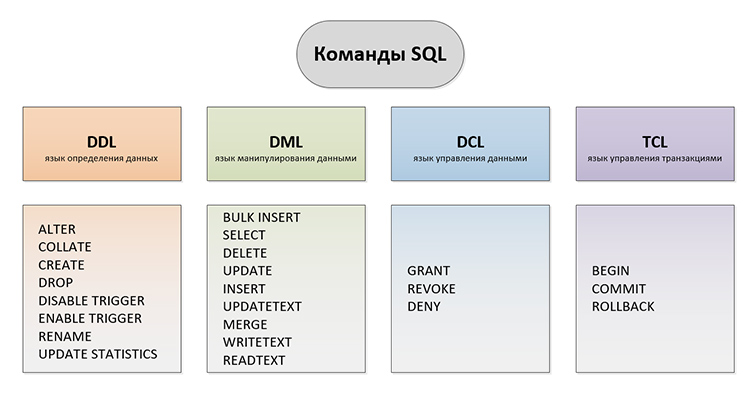
Ниже мы рассмотрим практические примеры применения SQL запросов для взаимодействия с БД используя запросы двух категорий – DDL и DML.
Тема связана со специальностями:
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
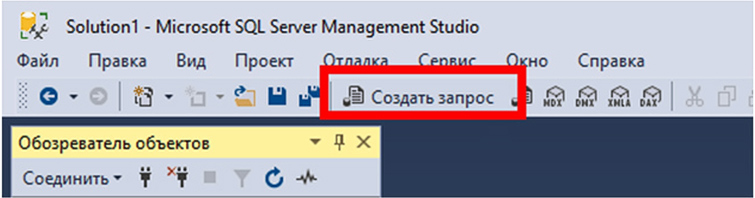
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
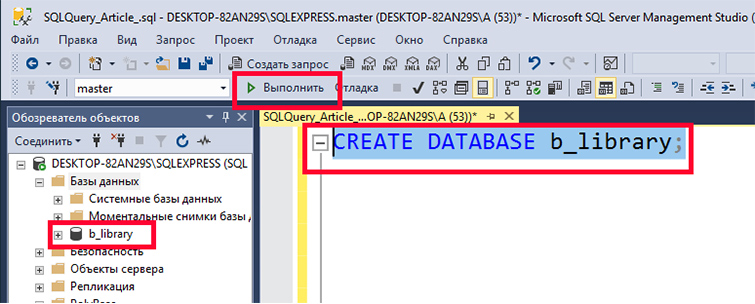
Создадим новую БД с именем «b_library» для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library».
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
В БД «b_library» создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
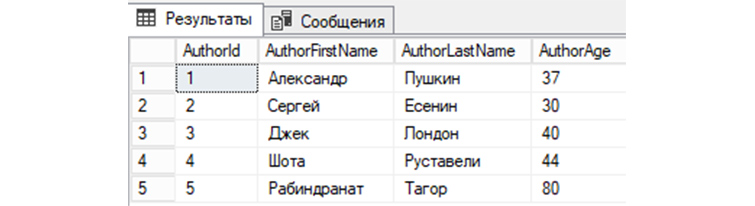
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
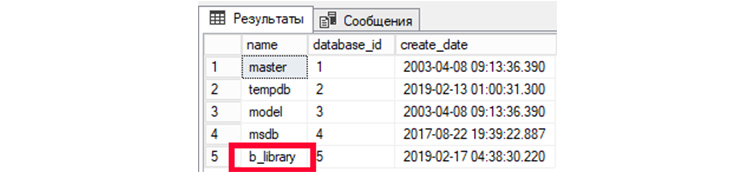
2) Выведем все таблицы в созданной нами ранее БД «b_library»:

3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
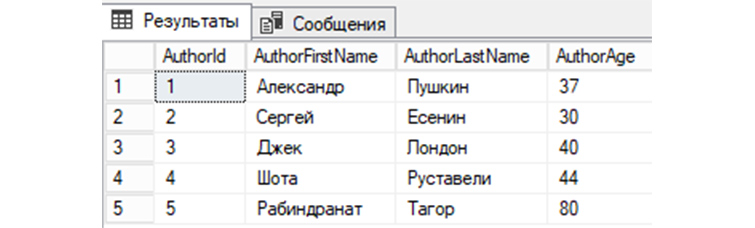
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:

5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):

6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
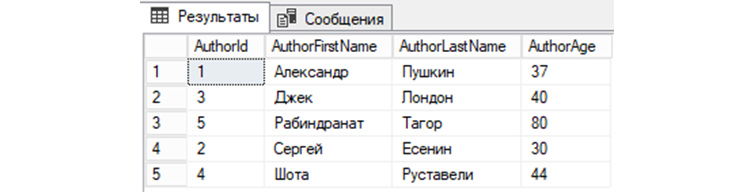
7) Выведем из «tAuthors» данные, предварительно по AuthorId отсортировав их по убыванию:
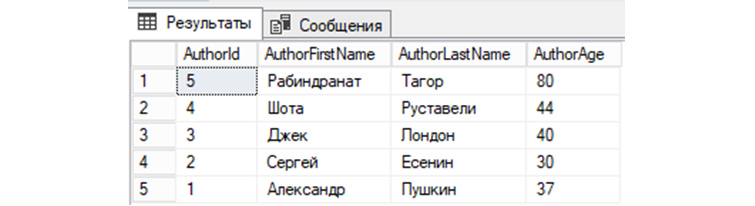
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:

9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:

10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
Видео курсы по схожей тематике:

SQL Базовый. Разбор ДЗ



11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:

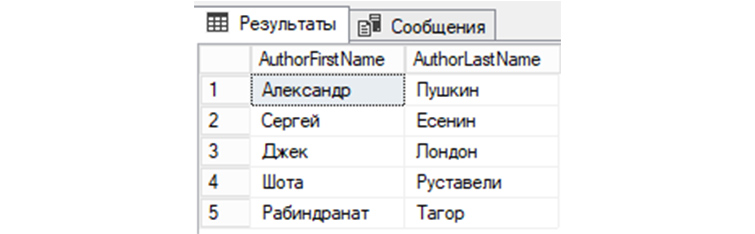
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
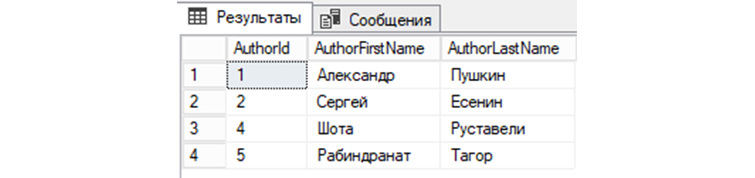
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
INSERT
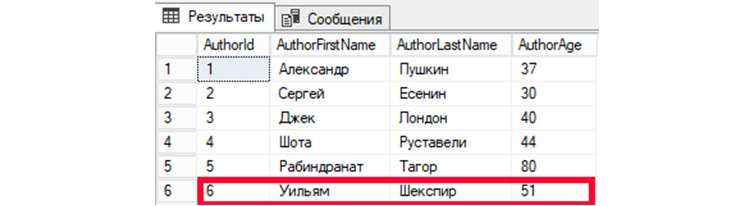
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД.
Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
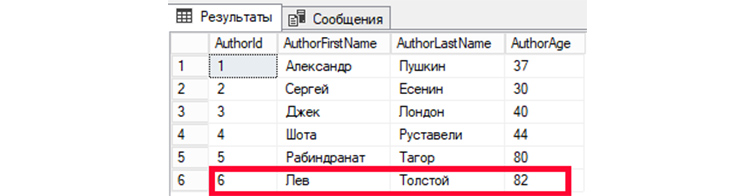
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
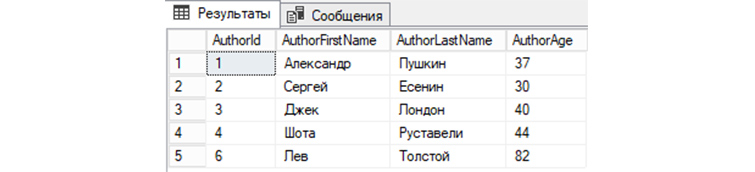
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors» целиком, выполнив простой SQL запрос:
Далее рассмотрим сложные запросы SQL.
Примеры сложных запросов к базе данных MS SQL
Сложные запросы SQL представляют из себя комбинации простых запросов. Выполняясь, простые запросы возвращают сгруппированные в промежуточные таблицы наборы данных. А сложный запрос уже манипулирует данными, полученными благодаря простым «подзапросам».
Рассмотрим в SQL примеры сложных запросов.
Заполним «tBooks» такими книгами:

2) Сделаем выборку данных из «tBooks» всех книг, авторами которых являются люди, с именами «Александр» или «Сергей»:
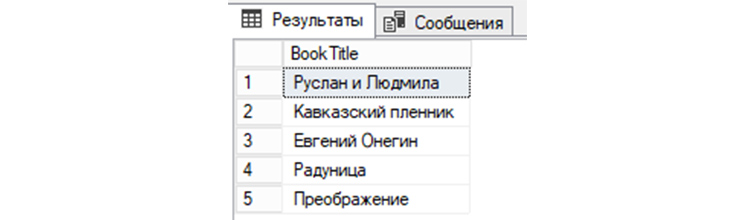
3) Сделаем выборку по книгам из таблицы «tBooks», у которых именами авторов являются НЕ «Сергей» и НЕ «Александр»:
Бесплатные вебинары по схожей тематике:

Основы реляционных баз данных и языка SQL

Хранение данных в Android

Как стать SQL разработчиком или Data инженером
4) Возьмем таблицу «tBooks» и сделаем из нее выборку всех книг с указанием как имен, так и фамилий авторов этих книг из «tAuthors»:
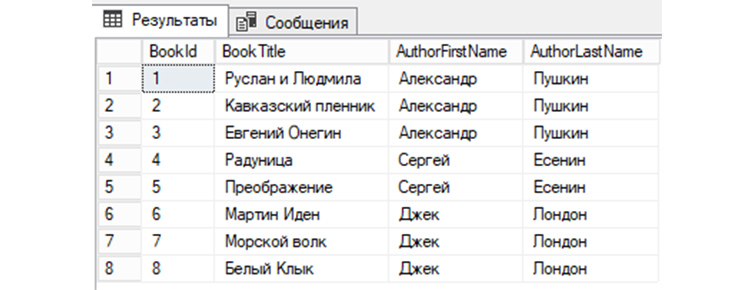
Выводы
Мы с вами рассмотрели несколько вариантов простых и сложных SQL запросов. Конечно эту статью не стоит рассматривать ни как учебное пособие, ни как исчерпывающий перечень возможностей запросов в T-SQL, и других диалектах. Скорее ее можно считать примером SQL запросов для начинающих. Однако она может послужить для Вас отправной точкой.