Язык SQL – объединение JOIN
Продолжаем изучать основы SQL, и пришло время поговорить о простых объединениях JOIN. И сегодня мы рассмотрим, как объединяются данные по средствам операторов LEFT JOIN, RIGHT JOIN, CROSS JOIN и INNER JOIN, другими словами, научимся писать запросы, которые объединяют данные, и как обычно изучать все это будем на примерах.

Объединения JOIN очень важны в SQL, так как без умения писать запросы с объединением данных разных объектов, просто не обойтись программисту SQL, да и просто админу который время от времени выгружает какие-то данные из базы данных, поэтому это относится к основам SQL и каждый человек, который имеет дело с SQL, должен иметь представление, что это такое.
Примечание! Все примеры будем писать в Management Studio SQL Server 2008.
Мы с Вами уже давно изучаем основы SQL, и если вспомнить начинали мы с оператора select, и вообще было уже много материала на этом сайте по SQL, например:
И много другого, даже уже рассматривали объединения union и union all, но, так или иначе, более подробно именно об объединениях join мы с Вами не разговаривали, поэтому сегодня мы восполним этот пробел в наших знаниях.
И начнем мы как обычно с небольшой теории.
Объединения JOIN — это объединение двух или более объектов базы данных по средствам определенного ключа или ключей или в случае cross join и вовсе без ключа. Под объектами здесь подразумевается различные таблицы, представления (views), табличные функции или просто подзапросы sql, т.е. все, что возвращает табличные данные.
Объединение SQL LEFT и RIGHT JOIN
LEFT JOIN – это объединение данных по левому ключу, т.е. допустим, мы объединяем две таблицы по left join, и это значит что все данные из второй таблицы подтянутся к первой, а в случае отсутствия ключа выведется NULL значения, другими словами выведутся все данные из левой таблицы и все данные по ключу из правой таблицы.
RIGHT JOIN – это такое же объединение как и Left join только будут выводиться все данные из правой таблицы и только те данные из левой таблицы в которых есть ключ объединения.
Теперь давайте рассматривать примеры, и для начала создадим две таблицы:
Вот такие простенькие таблицы, И я для примера заполнил их вот такими данными:
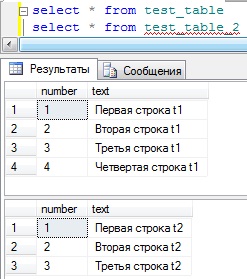
Теперь давайте напишем запрос с объединением этих таблиц по ключу number, для начала по LEFT:
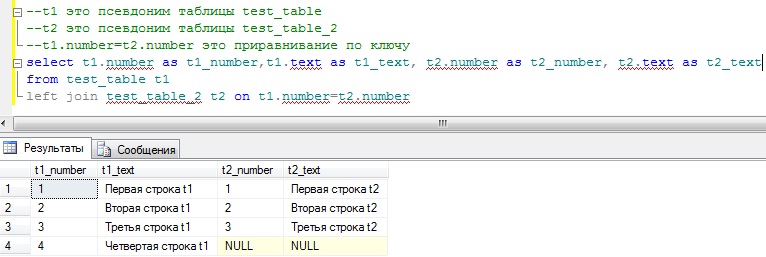
Как видите, здесь данные из таблицы t1 вывелись все, а данные из таблицы t2 не все, так как строки с number = 4 там нет, поэтому и вывелись NULL значения.
А что будет, если бы мы объединяли по средствам right join, а было бы вот это:
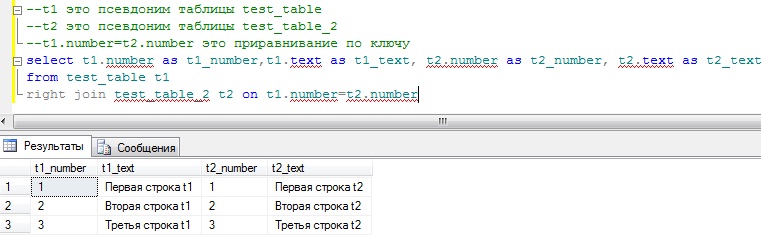
Другими словами, вывелись все строки из таблицы t2 и соответствующие записи из таблицы t1, так как все те ключи, которые есть в таблице t2, есть и в таблице t1, и поэтому у нас нет NULL значений.
Объединение SQL INNER JOIN
Inner join – это объединение когда выводятся все записи из одной таблицы и все соответствующие записи из другой таблице, а те записи которых нет в одной или в другой таблице выводиться не будут, т.е. только те записи которые соответствуют ключу. Кстати сразу скажу, что inner join это то же самое, что и просто join без Inner. Пример:
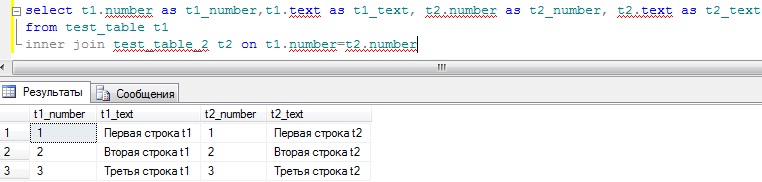
А теперь давайте попробуем объединить наши таблицы по двум ключам, для этого немного вспомним, как добавлять колонку в таблицу и как обновить данные через update, так как в наших таблицах всего две колонки, и объединять по текстовому полю как-то не хорошо. Для этого добавим колонки:
Обновим наши данные, просто проставим в колонку number2 значение 1:
И давайте напишем запрос с объединением по двум ключам:
И результат будет таким же, как и в предыдущем примере:
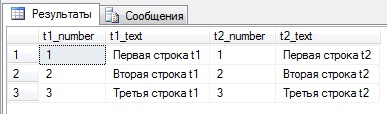
Но если мы, допустим во второй таблице в одной строке изменим, поле number2 на значение скажем 2, то результат будет уже совсем другой.
Запрос тот же самый, а вот результат:

Как видите, по второму ключу у нас одна строка не вывелась.
Объединение SQL CROSS JOIN
CROSS JOIN – это объединение SQL по которым каждая строка одной таблицы объединяется с каждой строкой другой таблицы. Лично у меня это объединение редко требуется, но все равно иногда требуется, поэтому Вы также должны уметь его использовать. Например, в нашем случае получится, конечно, не понятно что, но все равно давайте попробуем, тем более синтаксис немного отличается:
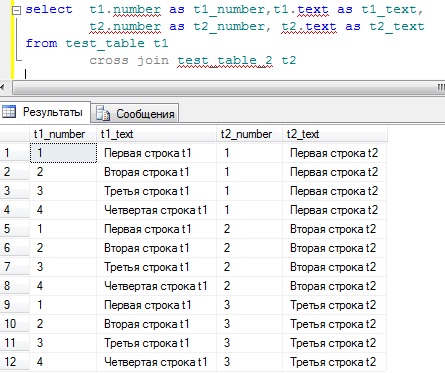
Здесь у нас каждой строке таблицы test_table соответствует каждая строка из таблицы test_table_2, т.е. в таблице test_table у нас 4 строки, а в таблице test_table_2 3 строки 4 умножить 3 и будет 12, как и у нас вывелось 12 строк.
И напоследок, давайте покажу, как можно объединять несколько таблиц, для этого я, просто для примера, несколько раз объединю нашу первую таблицу со второй, смысла в объединение в данном случае, конечно, нет но, Вы увидите, как можно это делать и так приступим:
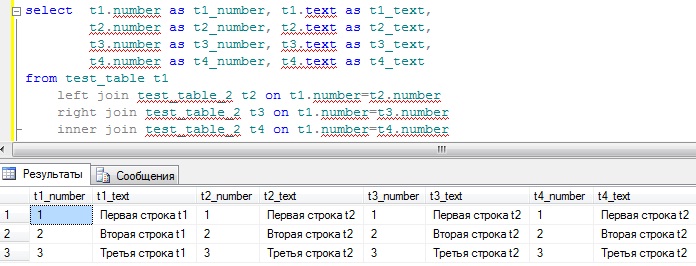
Как видите, я здесь объединяю и по left и по right и по inner просто, для того чтобы это было наглядно.
С объединениями я думаю достаточно, тем более ничего сложного в них нет. Но на этом изучение SQL не закончено в следующих статьях мы продолжим, а пока тренируйтесь и пишите свои запросы. Удачи!
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Crossjoin (многомерные выражения)
Возвращает перекрестное произведение двух или нескольких наборов.
Синтаксис
Аргументы
Set_Expression1
Допустимое многомерное выражение, возвращающее набор.
Set_Expression2
Допустимое многомерное выражение, возвращающее набор.
Remarks
Функция с перекрестным соединением Возвращает перекрестное произведение двух или более заданных наборов. Порядок кортежей в результирующем наборе зависит от порядка соединяемых наборов и от порядка их элементов. Например, если первый набор состоит из
Если наборы в перекрестном соединении состоят из кортежей из различных иерархий атрибутов одного измерения, функция вернет только те кортежи, которые действительно существуют. Дополнительные сведения см. в разделе Основные понятия в многомерных выражениях (Analysis Services).
Примеры
В следующем запросе показаны простые примеры использования функции Crossjoin по осям Columns и Rows запроса:
FROM [Adventure Works]
WHERE Measures.[Internet Sales Amount]
В следующем примере показана автоматическая фильтрация, которая выполняется при перекрестном соединении различных иерархий из одного измерения:
Measures.[Internet Sales Amount]
//Only the dates in Calendar Years 2003 and 2004 will be returned here
FROM [Adventure Works]
В следующих трех примерах возвращается одинаковый результат — значение меры Internet Sales Amount по штатам в США. В первых двух примерах используются два синтаксиса перекрестного соединения, а в третьем демонстрируется применение предложения WHERE для извлечения тех же сведений.
CROSS JOIN (U-SQL)
Summary
A cross join returns the Cartesian product of rows from the rowsets in the join. In other words, it will combine each row from the first rowset with each row from the second rowset.
Note that this is potentially an expensive and dangerous operation since it can lead to a large data explosion. It is best used in scenarios where a normal join cannot be used and very selective predicates are being used in the WHERE clause to limit the number of produced rows.
Examples
Basic Example
Using the input rowsets
| EmpName | DepID |
|---|---|
| Rafferty | 31 |
| Jones | 33 |
| Heisenberg | 33 |
| Robinson | 34 |
| Smith | 34 |
| Williams | null |
| DeptID | DepName |
|---|---|
| 31 | Sales |
| 33 | Engineering |
| 34 | Clerical |
| 35 | Marketing |
the following cross join
produces this rowset
| EmpName | DepName |
|---|---|
| Rafferty | Engineering |
| Jones | Engineering |
| Heisenberg | Engineering |
| Robinson | Engineering |
| Smith | Engineering |
| Williams | Engineering |
Note that without the filter on the DepName, the resulting rowset would have produced 6×4=24 rows.
Осмысляем работу джойнов в SQL: от реляционной алгебры до наглядных картинок
Выбираем, какие фильмы посмотреть, с помощью соединения данных в SQL.

Опять эта проблема — выбрать кино на вечер. Благодаря стриминговым сервисам доступны едва ли не все фильмы мира: это бесконечное полотно с постерами и фильтры, фильтры, фильтры…

МОЗГ: Поставлю-ка я фильтр по стране: пусть будет Дания, и добавлю ограничение по жанру — триллер… Ну вот — другое дело, относительно небольшой список.
— Мозг, а знаешь почему? Да потому что здесь только фильмы, которые сняты в Дании И помечены как триллеры.
— Да не знаю я, как задать такие критерии в этом сервисе. Вот если бы можно было писать на SQL — тут бы решение нашлось для любой комбинации признаков.
— Легко! Ещё и картинки будут. У меня и база фильмов уже спарсена — тренируйся не хочу.

Фулстек-разработчик. Любимый стек: Java + Angular, но в хорошей компании готова писать хоть на языке Ада.
Договоримся об обозначениях
Назовём множество датских фильмов — D, а множество триллеров — T. У каждого фильма будет уникальный номер, он же ключ. Раз ключ — пусть зовётся Key.
Заодно вспомним, как на SQL пишется простой запрос для связывания данных из двух таблиц:
INNER JOIN
Если не уточнить тип соединения ( JOIN), то по умолчанию применяется INNER JOIN — как раз тот вариант, который сработал в нашем кинофильтре. Это он выбирает и триллеры, и датские фильмы одновременно.
SQL JOIN: руководство по объединению таблиц
Перевод первой части статьи «SQL Joins Tutorial: Cross Join, Full Outer Join, Inner Join, Left Join, and Right Join».
Операции объединения в SQL позволяют нашим реляционным базам данных быть… хм… реляционными (англ. relational — «относительный»). Они дают нам возможность реконструировать наши отдельные базы данных с учетом отношений между ними, а это важно для наших приложений.
В этой статье вы рассмотрим все виды JOIN в SQL и расскажем, как ими пользоваться.
В первой части статьи:
(Спойлер: мы рассмотрим пять разных видов объединений, но на самом деле вам нужно знать только два из них!)
Что такое JOIN?
JOIN это операция объединения двух строк в одну. Эти строки обычно бывают из двух разных таблиц, но это не обязательно.
Прежде чем мы разберем, как писать JOIN-ы, давайте посмотрим, как выглядит объединение таблиц.
Возьмем для примера систему, в которой хранится информация о пользователях и их адресах.
Таблица, хранящая информацию о пользователях, может выглядеть следующим образом:
А таблица с адресами может быть такой:
Чтобы получить информацию и о пользователе, и о его адресе, мы можем написать два разных запроса. Но в идеале можно написать один запрос и получить все необходимые сведения в одном ответе.
Именно для этого, собственно, и нужны операции объединения!
Чуть позже мы рассмотрим, как составлять подобные запросы, а пока взгляните, как может вы глядеть результат объединения таблиц:
Мы видим всех наших пользователей сразу с их адресами.
Но операции объединения позволяют не просто выводить такие вот комбинированные сведения. У них есть еще одна важная функция: с их помощью можно получать отфильтрованные результаты.
Теперь, когда вы поняли, для чего вообще нужны операции объединения, давайте приступим к написанию запросов!
Настройка базы данных
Прежде чем писать какие-либо запросы, нужно настроить базу данных.
Для примеров в этой статье будет использоваться PostgreSQL, но запросы и концепции, показанные здесь, легко применимы в любой другой современной СУБД (MySQL, SQL Server и т. д.).
Для работы с нашей базой данных PostgreSQL мы будем пользоваться интерактивной cli-программой psql. Если у вас установлен другой клиент, вы прекрасно можете работать с ним!
Теперь давайте воспользуемся интерактивной консолью (запустив команду psql ) и подключимся к только что созданной базе данных при помощи команды \c :
Примечание: в примерах я подчистил вывод, чтобы их было легче читать. Поэтому не волнуйтесь, что показанный здесь output не в точности совпадает с тем, что вы видите в своем терминале.
Я советую вам прорабатывать запросы, которые мы будем составлять, писать их вместе со мной и запускать. Работая с примерами, вы поймете и запомните куда больше, чем если будете просто читать.
CROSS JOIN (перекрестное объединение)
Самое простое объединение, которое мы можем сделать, это CROSS JOIN (перекрестное объединение) или «декартово произведение».
При этом объединении мы берем каждую строку одной таблицы и соединяем ее с каждой строкой другой таблицы.
Каждое значение из первого списка соединено с каждым значением второго списка.
Давайте перепишем этот пример в виде SQL-запроса.
Для начала создадим две очень похожих таблицы и внесем в них данные:
Наши таблицы letters и numbers имеют по одному столбцу с простыми текстовыми полями.
Теперь давайте объединим эти таблицы, используя CROSS JOIN:
Хотя этот пример часто упоминается как чисто учебный, и для него есть практическое применение: покрытие диапазона дат.
CROSS JOIN с диапазонами дат
Хороший вариант использования CROSS JOIN — брать каждую строку таблицы и объединять ее с каждым днем из диапазона дат.
Скажем, вы создаете приложение, которое должно отслеживать ежедневную рутину (чистка зубов, завтрак, душ).
Если вы хотите генерировать запись для каждой задачи за каждый день прошлой недели, вы можете использовать CROSS JOIN с диапазоном дат.
Чтобы создать диапазон дат, мы можем воспользоваться функцией generate_series:
Функция generate_series принимает три параметра.
Второй параметр — текущая дата ( CURRENT_DATE ).
Третий параметр — шаг. То есть, на сколько мы хотим инкрементировать значение. Поскольку это ежедневные задачи, мы устанавливаем в качестве интервала один день ( INTERVAL ‘1 day’ ).
Все вместе генерирует серию дат, начиная с даты пятидневной давности и заканчивая сегодняшним днем, по дню за раз.
Результат запроса за последние пять дней плюс сегодняшний:
Возвращаемся к нашему примеру с ежедневными задачами. Давайте создадим простую таблицу, в которой будут содержаться наши задачи (и добавим несколько):
В нашей таблице tasks есть только один столбец — name — в который мы добавили несколько задач.
Теперь давайте осуществим перекрестное объединение наших задач с запросом на генерацию дат:
(Поскольку наш запрос для генерации дат по сути не является таблицей, мы просто написали его в виде подзапроса).
В результате мы получаем название задачи и день. Выглядит это следующим образом:
Как и ожидалось, мы получили по строке для каждой задачи на каждый день из нашего диапазона дат.
CROSS JOIN это простейшее объединение. Дальнейшие примеры потребуют более «жизненной» настройки таблиц.
Создание таблиц directors и movies
Чтобы проиллюстрировать следующие виды объединений, мы воспользуемся примером с фильмами (movies) и режиссерами (movie directors).
Каждый фильм имеет режиссера, но это не является обязательным условием. Может быть ситуация, когда фильм уже анонсировали, но режиссер еще не выбран.
В нашей таблице directors будут храниться имена всех режиссеров, а в таблице movies — названия фильмов, а также отсылка к режиссеру (если он известен).
Давайте создадим эти таблицы и внесем в них необходимые данные:
У нас есть пять режиссеров и пять фильмов, причем для трех фильмов указаны режиссеры. У режиссера с ID 1 есть два фильма, а у режиссера с ID 2 — один фильм.
FULL OUTER JOIN (полное внешнее объединение)
Теперь у нас есть данные, с которыми можно работать, так что переходим к следующему виду объединения — FULL OUTER JOIN.
FULL OUTER JOIN похоже на CROSS JOIN, но имеет важные отличия.
Первое отличие состоит в том, что для FULL OUTER JOIN требуется условие объединения.
Это условие определяет, как именно связаны строки разных таблиц и по какому критерию они должны объединяться.
Вот как это выглядит в коде:
Наш результат выглядит, как некое странное декартово произведение:
Сначала идут несколько строк с фильмами, для которых указаны режиссеры: здесь наше условие явно соблюдается.
Но после мы видим оставшиеся строки из каждой таблицы, но со значениями NULL в тех местах, где в другой таблице не нашлось совпадений.
Примечание: если вы не знакомы со значениями NULL, объяснение можно почитать здесь.
Здесь мы также видим второе различие между перекрестным и полным внешним объединением. FULL OUTER JOIN соединяет одну строку первой таблицы с определенной строкой второй таблицы, а при CROSS JOIN каждая строка одной таблицы соединяется с каждой строкой другой.
INNER JOIN
Следующий вид объединения — внутреннее, INNER JOIN. Внутреннее объединение является наиболее используемым.
INNER JOIN возвращает только те строки, где соблюдается условие объединения.
Если брать наш пример с таблицами movies и directors, внутреннее объединение вернет только те записи, где у фильма есть указанный режиссер.
Синтаксис практически тот же:
В результирующую выборку попали только фильмы с режиссерами:
Поскольку внутреннее объединение дает нам только те строки, для которых соблюдается условие объединения, порядок указания таблиц не имеет значения.
Если мы поменяем местами названия таблиц в запросе, результат будет тот же:
Единственное отличие в том, что поскольку мы выбрали все столбцы ( SELECT * ) и сначала указали таблицу directors, то в результате первыми будут идти данные из этой таблицы, а дальше — из таблицы movies. Но данные, попавшие в выборку, те же.
Это полезное свойство операции внутреннего объединения: не у всех видов объединений оно есть.
Конец первой части. Читайте во второй части: