Работа с большими объектами в PL/SQL (BFILE, LOB, SecureFiles)

 Тема работы с большими объектами весьма объемна, поэтому мы не сможем рассмотреть все ее аспекты. Данную статью блога следует рассматривать как введение в программирование больших объектов для разработчиков PL/SQL. Мы познакомимся с некоторыми нюансами, которые необходимо учитывать, и рассмотрим примеры важнейших операций. Хочется надеяться, что представленный материал станет хорошей основой для ваших дальнейших исследований в этой области.
Тема работы с большими объектами весьма объемна, поэтому мы не сможем рассмотреть все ее аспекты. Данную статью блога следует рассматривать как введение в программирование больших объектов для разработчиков PL/SQL. Мы познакомимся с некоторыми нюансами, которые необходимо учитывать, и рассмотрим примеры важнейших операций. Хочется надеяться, что представленный материал станет хорошей основой для ваших дальнейших исследований в этой области.
Прежде чем переходить к основному материалу, необходимо указать, что все примеры данного раздела основаны на следующем определении таблицы (см. файл source_code.sql):

Рис. 1. Водопад Драйер-Хоуз возле Мунисинга (штат Мичиган)
Таблица содержит информацию о водопадах, расположенных в северной части штата Мичиган. На рис. 1 изображен водопад Драйер-Хоуз возле Мунисинга; в замерзшем состоянии его часто посещают альпинисты.
Понятие локатора LOB
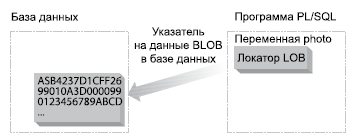
Рис. 2. Локатор LOB указывает на объект в базе данных
Этот механизм в корне отличается от того, как работают другие типы данных. Переменные и значения в столбцах LOB содержат локаторы больших объектов, которые идентифицируют реальные данные, хранящиеся в другом месте базы данных или вне ее. Для работы с данными типа LOB нужно сначала извлечь локатор, а затем с помощью встроенного пакета DBMS_LOB получить и/или модифицировать реальные данные. Так, для получения двоичных данных фотографии, локатор которой хранится в столбце BLOB из приведенной ранее таблицы, необходимо выполнить следующие действия:
Не все эти действия являются обязательными; не огорчайтесь, если что-то пока остается непонятным. Далее все эти операции будут описаны более подробно.
LOB-ДАННЫЕ В ДОКУМЕНТАЦИИ ORACLE
Если вам часто приходится работать с большими объектами, настоятельно рекомендуем ознакомиться со следующими документами Oracle:
Большие объекты — пустые и равные NULL
Очень важно понимать это различие, потому что у типов LOB способ проверки наличия либо отсутствия данных получается более сложным, чем у скалярных типов. Для традиционных скалярных типов достаточно простой проверки IS NULL :
Итак, проверять нужно два условия вместо одного.
Для создания пустого объекта BLOB используется функция EMPTY_BLOB (). Для типов CLOB и NCLOB используется функция EMPTY_CLOB ().
Запись данных в объекты LOB
Чтение данных из объектов LOB
В результате выполнения этого кода выводится следующий текст:
Особенности типа BFILE
Как упоминалось ранее, типы данных BLOB, CLOB и NCLOB представляют внутренние большие объекты, хранящиеся в базе данных, в то время как BFILE является внешним типом. Между объектами BFILE и внутренними LOB существуют три важных различия:
Создание локатора BFILE
Локатор BFILE — всего лишь комбинация псевдонима каталога и имени файла. Реальный файл и каталог даже не обязаны существовать. Иначе говоря, Oracle позволяет создавать псевдонимы для несуществующих каталогов, а BFILENAME — локаторы для несуществующих файлов. Иногда это бывает удобно.
Доступ к данным BFILE
Результат выполнения этого кода:
Использование BFILE для загрузки столбцов LOB
Не путайте предупреждения с ошибками PL/SQL; загрузка все равно будет выполнена в соответствии с запросом.
Следующий пример SQL*Plus демонстрирует загрузку данных из внешнего файла с использованием LOADCLOBFROMFILE :
SecureFiles и BasicFiles
По данным тестирования Oracle, повышение быстродействия от использования SecureFiles составляет от 200 до 900%. В простом тесте с загрузкой файлов PDF на сервер Microsoft Windows я наблюдал снижение времени загрузки от 80 до 90% от 169 секунд до 20–30 секунд (в зависимости от конфигурации и количества загрузок). В системе x86 Linux выигрыш был более скромным. Возможно, в вашей ситуации цифры будут другими, но ускорение будет наверняка!
Если вы не уверены относительно базы данных, обратитесь за помощью к администратору.
Устранение дубликатов
Сжатие
Чтобы включить режим устранения дубликатов одновременно со сжатием, укажите соответствующие параметры в определении LOB :
При включении обоих режимов сначала выполняется устранение дубликатов, а затем сжатие.
Шифрование
Созданный бумажник необходимо открывать заново после каждого перезапуска экземпляра. Открытие и закрытие бумажника выполняется следующим образом:
Временные объекты LOB
Создание временного объекта LOB
Другой способ создания временного объекта LOB основан на объявлении переменной LOB в коде PL/SQL и присваивании ей значения. Например, следующий фрагмент создает временные объекты BLOB и CLOB :
Освобождение временного объекта LOB
Процедура DBMS_LOB.FREETEMPORARY освобождает временный объект типа BLOB или CLOB в текущем временном табличном пространстве. Заголовок процедуры:
В следующем примере сначала создаются, а затем освобождаются два временных объекта LOB :
После вызова FREETEMPORARY освобожденный локатор LOB ( lob_loc ) помечается как недействительный. Если присвоить его другому локатору с помощью обычного оператора присваивания PL/SQL, то и этот локатор будет освобожден и помечен как недействительный.
PL/SQL неявно освобождает временные объекты LOB при выходе за пределы области действия блока.
Проверка статуса объекта LOB
Функция ISTEMPORARY позволяет определить, является ли объект с заданным локатором временным или постоянным. Она возвращает целочисленный код: 1 для временного объекта, 0 для постоянного.
Управление временными объектами LOB
Временные большие объекты обрабатываются не так, как обычные постоянные. Для них не поддерживаются транзакции, операции согласованного чтения, откаты и т. д. Такое сокращение функциональности имеет ряд следствий:
Встроенные операции LOB
Семантика SQL
Возможности, упомянутые в предыдущем разделе, Oracle называет «поддержкой семантики SQL для LOB ». С точки зрения разработчика PL/SQL это означает, что с LOB можно работать на уровне встроенных операторов (вместо отдельного пакета).
Следующий пример демонстрирует некоторые возможности семантики SQL:
Маленький фрагмент кода в этом примере содержит несколько интересных моментов:
Семантика SQL может создавать временные объекты LOB
Чтобы получить описание местонахождения водопада в верхнем регистре, сохранив возможность обновления исходного описания, необходимо получить два локатора LOB :
Влияние семантики SQL на быстродействие
А теперь представьте, сколько времени потребуется для создания копии каждого объекта CLOB для его преобразования к верхнему регистру, для выделения и освобождения пространства временных объектов CLOB во временном пространстве и для посимвольного поиска данных в CLOB средним объемом в 1 Гбайт. Конечно, такие запросы навлекут на вас гнев администратора базы данных.
Oracle Text и семантика SQL
За дополнительной информацией о CONTAINS и индексах Oracle Text, игнорирующих регистр символов, обращайтесь к документации Oracle Text Application Developer’s Guide.
Функции преобразования объектов LOB
Oracle предоставляет в распоряжение программиста несколько функций преобразования больших объектов. Перечень этих функций приведен в табл. 2.
Работа с объектами большого объема в MS SQL и ADO
Работа с данными типа image и text
Автор: Алексей Ширшов
The RSDN Group
Источник: RSDN Magazine #4-2003
Опубликовано: 21.03.2004
Исправлено: 10.12.2016
Версия текста: 1.0

Введение
Эта статья появилась на свет только благодаря вашим не перестающим появляться вопросам типа: «Кто-нибудь может привести пример кода для работы с полями базы, содержащими картинки…используя ADO и Visual C++…», и тому, что мне лень на них отвечать.
Работа в MS SQL
Давайте сначала разберемся, как работать с большими объектами (LOB – large objects) на уровне базы данных. MS SQL Server поддерживает следующие типы больших объектов:
Для хранения данных всех этих типов и низкоуровневой работы с ними SQL Server использует один и тот же механизм.
Физическое размещение больших объектов
MS SQL Server 2000 поддерживает два метода хранения больших объектов: первый метод оставлен ради совместимости со старыми версиями и не обеспечивает должной производительности в определенных случаях, по сравнению с новым методом. По умолчанию сервер работает в старом режиме.
При использовании старого метода сервер всегда размещает данные в отдельных страницах, а указатель на первую из них хранит непосредственно в строке данных.
| ПРИМЕЧАНИЕ Точнее, в строке данных хранится указатель на корень B-tree, а не на какие-либо таблицы данных. Подробнее об этом, см. следующий раздел. Используя новую стратегию, сервер может хранить часть данных непосредственно в строке таблицы. Это приводит к экономии памяти и увеличению производительности для LOB-ов небольшого размера. Стратегия размещения по умолчаниюВ качестве структуры хранения данных используется B-tree. В строке данных хранится 16-байтный указатель на корень дерева – структуру размером 84 байта. Если размер данных не превышает 32 Кб, в корневой структуре хранятся ссылки на блоки данных, расположенных на этой же или других страницах. Большие объекты хранятся на специальных страницах, на которых нельзя размещать никакие другие данные, кроме image, text и ntext. Однако данные этих типов из разных таблиц могут быть размещены на одной странице. Если общий размер данных не больше 64 байт, все данные сохраняются в корневой структуре. Если размер данных больше 32 Кб, корень дерева ссылается на промежуточные узлы. Промежуточные узлы располагаются на отдельных страницах, которые не могут содержать какие-либо другие данные, или промежуточные узлы других таблиц или даже других колонок данной таблицы. Улучшенная стратегияВ SQL Server 2000 появилась возможность использовать новый метод хранения больших объектов. В нем отсутствует 16-байтный указатель. В строке данных (data row) могут находиться как сами данные (в случае, если они меньше заданной величины), так и корень B-tree. Для каждой таблицы размер хранимых больших объектов можно задавать индивидуально с помощью процедуры sp_tableoption. Проверить режим размещения можно с помощью инструкции objectproperty с параметром TableTextInRowLimit. В следующем скрипте создается таблица (которую мы будем использовать на протяжении всей статьи) blob_test, затем проверяется режим размещения данных в этой таблице, и, наконец, устанавливается размер данных в строке (350 байт), что автоматически задает улучшенную стратегию размещения больших объектов в таблице. Вместо размера больших объектов в процедуру sp_tableoption можно было передать значение On. В этом случае размер устанавливается равным 250 байтам. Отключить размещение данных в строке можно, задав в качестве параметра значение 0 или Off. Максимальный размер данных в строке равен 7000 байт. Следующий рисунок иллюстрирует схему распределения данных при размере, превышающем 350 байт (для нашей таблицы). Если в строке данных присутствует расширяемое поле типа varchar или varbinary, то при его расширении, если общий размер строки превысит 8060 байт, часть данных из строки может быть выгружена на дополнительные страницы. Другими словами, остальные поля имеют приоритет перед LOB при нехватке пространства в строке данных. Вернем нашу таблицу в начальное состояние, так как следующие примеры рассчитаны на режим по умолчанию: После перевода таблицы в режим «данные в строке» сами данные в строку не переносятся, однако обратное действие вызывает немедленную операцию по переносу данных на отдельные страницы. При этом вся таблица полностью блокируется, а при большом количестве переносимых данных операция может занять длительное время. Работа с большими даннымиВ работе с бинарными данными на уровне сервера большого смысла нет. Поэтому большинство примеров использует текстовые данные, хотя описываемые процедуры вполне сгодятся и для бинарных данных. При работе с LOB можно использовать обычные операторы SQL (select, insert). Но иногда может понадобиться работать не с LOB целиком, а с его частями. Операторы работы с такими небольшими порциями довольно необычны для SQL тем, что в них используются указатели, смещения и другие низкоуровневые понятия. Указатель представляет собой 16-байтовую переменную типа binary или varbinary. Это абстракция, указывающая на данные в конкретной колонке конкретной строки. Указатель получается путем вызова функции textptr, куда передается имя колонки. Он может быть равен NULL в том случае, если данных не существует. Если указатель равен NULL, вы не можете использовать функции READTEXT, WRITETEXT и UPDATETEXT. Указатель должен содержать какое-либо значение, поэтому для правильной работы этих функций в колонке изначально должны содержаться данные. Для простоты мы запишем туда следующие значения: Значения для колонки типа image должны указываться в шестнадцатеричном формате, а для типов text и ntext это должны быть строки. Для всех операторов DML, изменяющих данные, предыдущее значение всей строки сбрасывается в лог транзакций, однако для операторов WRITETEXT и UPDATETEXT это зависит от модели восстановления базы данных. Для модели Bulk logged данные не записываются в лог транзакций, вместо этого измененные страницы помечаются особым образом и записываются в архив лога транзакций при вызове соответствующей операции архивирования. READTEXTЭтот оператор предназначен для блочного чтения больших текстовых и бинарных данных: Для поиска определенного текстового фрагмента нужно воспользоваться функцией PATINDEX. Она не так удобна, как хотелось бы (например, отсутствует возможность искать, начиная с определенной позиции), но вполне подходит для простых операций. В следующем примере выводится весь текст после слова is. Здесь хочется отметить две особенности: patindex возвращает смещение относительно начала строки в символах, считая от единицы, тогда как readtext воспринимает смещение от нуля, а datalength возвращает длину данных в байтах, так что для типа ntext мы должны поделить ее на два. Давайте задумаемся, что произойдет, если кто-либо попытается изменить данные между операциями получения указателя и его использования. Ничего особенного, просто SQL Server выдаст ошибку 7123, говорящую, что была попытка использовать недействительный указатель. Одной проверки на NULL оказывается недостаточно. Для проверки указателя на действительность нужно воспользоваться функцией textvalid. Однако эта проверка не избавляет нас от проблемы, а лишь помогает выявить ее. Нам нужно, чтобы для данного указателя соблюдалось условие повторяемого чтения. Этого проще всего добиться, использовав в запросе хинт REPEATABLEREAD. Перепишем пример следующим образом: Теперь код написан «по всем правилам»: Функция READTEXT не вернет вам всего объема данных. Размер максимально доступных данных, которые можно получить с помощью этой функции, равен @@textsize. По умолчанию это значение равно 4 Кб. Увеличить его можно с помощью функции set textsize. Для сброса переменной в значение по умолчанию установите размер, равный нулю. WRITETEXTЭта функция оставлена только для совместимости. Ее заменила более мощная UPDATETEXT, которую я рассмотрю позднее. Вот синтаксис функции WRITETEXT: WRITETEXT полностью перезаписывает содержимое колонки. Для операции обновления также актуальна проблема действительности указателя. Но здесь уже недостаточно просто установить коллективную блокировку на обновляемую строку, так как это может привести к взаимоблокировке, например, если две транзакции одновременно получают коллективную блокировку и пытаются сконвертировать ее в монопольную. Для предотвращения подобной ситуации необходимо наложить блокировку обновления. В следующем примере производится обновление бинарных данных в первой строке: Более подробно механизм блокировок в MS SQL Server и понятие уровней изоляции транзакций рассмотрены в предыдущем номере журнала. UPDATETEXTЭта более мощная функция обновления данных, чем WRITETEXT. Она также позволяет копировать данные из другой колонки (правда, нельзя указать размер копируемых в этом случае данных). Вот ее синтаксис: Следующие два вызова аналогичны: Давайте рассмотрим пример. Предположим, я ошибся, набирая имя своей жены, и мне его сейчас необходимо заменить: Пожалуй, это все. Осталось еще одна тонкость. Данные в строкеЧитая Books Online, я наткнулся на такое предложение: After you have turned on the text in row option, you cannot use the READTEXT, UPDATETEXT or WRITETEXT statements, to read or modify parts of any text, ntext, or image value stored in the table. Вот это да! Т.е. я не могу пользоваться функциями, приведенными выше, если таблица находится в режиме «данные в строке»? Это неправда. Хотя вот такой пример может убедить кого угодно: You cannot use a text pointer for a table with option ‘text in row’ set to ON. Дело в том, что в режиме «данные в строке» указатель становить неверным сразу же по окончании транзакции. Так как SQL Server по умолчанию находится в режиме автоматического подтверждения транзакции (auto commit), указатель перестает быть действительным сразу после выполнения запроса. Чтобы наш пример заработал, необходимо включить обе операции (получение указателя и его использование) в одну транзакцию. Кроме этого, SQL Server автоматически устанавливает коллективную блокировку в момент получения указателя для данных в строке, так что не нужно прибегать к каким-либо хинтам. Эта блокировка снимется после того, как указатель станет недействительным. Как я сказал, это происходит в конце транзакции или при использовании следующих команд: Можно и вручную сделать указатель недействительным с помощью вызова функции sp_invalidate_textptr. Если транзакция выполняется на уровне изоляции READ UNCOMMITTED, полученный указатель можно использовать только в операциях чтения. Операция обновления закончится ошибкой 7106: You cannot update a blob with a read-only text pointer. Работа с ADOВ этом разделе я приведу примеры работы с большими объектами, используя ADO.NET и ADO. Начнем с простого. Чтение изображения и вывод на экран с помощью VB6Хотя VB6 уже не так популярен, как несколько лет назад, на нем все же очень удобно писать определенного вида программы. Я иногда просто удивляюсь, как много VS.NET переняла из среды VB6, вплоть до иконок. Программируя на C#, вы по прежнему в меню Project можете найти пункт References, а в списке событий формы – события OnLoad. Очень удобная технологий DataBinding, которую я и буду использовать в примерах, также благополучно перекочевала в дотнет. На самом деле, очень много знаний из «прежней жизни» вы можете использовать в новой среде. Вот только я не понимаю, почему совместимости в ADO.NET уделено меньше всего внимания. Например, тот же самый DataBinding не работает со старым ADO. Вместо этого нужно «заливать» ADO-шный Recordset в DataSet, и использовать уже его. Ну, хватит лирики, давайте перейдем к предмету разговора. Алгоритм вывода изображения на экран из БД может быть таким: Вот фрагменты кода из демонстрационного приложения, реализующие этот алгоритм. Если нужно просто сохранить графический объект в файл на диске, алгоритм несколько меняется. Вместо связывания данных нужно открыть файл на запись и записать в него данные. Однако все не так просто: В этом примере мне пришлось скопировать данные во временный буфер, так как инструкция Put добавляет к некоторым типам, экземпляры которых вы хотите сохранить, разные заголовки. Зачем это сделано, мне не совсем понятно; видимо разработчики хотели упростить реализацию сохранения/восстановления состояния переменных программы, однако это у них не очень хорошо получилось – для объектов эта инструкция не поддерживается. В случае сохранения таким образом: в файл запишется одному лишь богу известный заголовок, который будет мешать воспринимать этот файл как нормальный bmp. Поэтому я вынужден копировать данные в дополнительный массив байтов и сохранять уже его. Для чтения графической информации из файла можно воспользоваться инструкцией Get. Все идет хорошо до тех пор, пока не понадобится читать/писать бинарные данные небольшими блоками. Здесь на помощь приходят следующие методы: Эти два метода позволяют работать с порциями (chunks) данных. Например, вот такой код позволяет считать всего лишь первые 100 байт данных: Это все замечательно, но как же рекомендации MSDN использовать более гибкий объект Stream? Сейчас мы и до него доберемся. Работа с изображением с помощью Stream на С++Я выбрал С++, так как с VB6 мы уже поработали (хорошего помаленьку), и потому, что большинство вопросов касается именно С++. (На RSDN ходят настоящие индейцы.) Алгоритм действий примерно тот же, что и в предыдущем примере: Код реализации алгоритма приведен далее, а сейчас я бы хотел остановиться на шестом пункте, так как он выглядит слишком расплывчато, а мы, программисты, чужды неопределенности. Объект Stream (поток) предназначен специально для работы с нереляционными и двоичными данными. Его возможности очень велики. Для иллюстрации работы с объектом Stream приведу-таки пример на VB6, который сохраняет изображение в файл без использования инструкции Put: Но хватит БЕЙСИКа (по крайней мере, VB6 в этой статье больше не встретится), перейдем к реализации описанного выше алгоритма. Для того чтобы подобный код работал, необходимо подключить заголовочный файл adoint.h. Можно было воспользоваться директивой import для генерирования удобных оберток над соответствующими объектами и методами ADO. Пример получился бы проще, но тогда вы могли упустить кое-какие детали. В примере производится загрузка изображения из базы данных в объект, поддерживающий интерфейс IPicture. Этот интерфейс позволит вам в дальнейшем выводит (рендерить) изображение или сохранять его на диск в различных форматах. Вывод изображения на экран делается примерно так (обработчик WM_PAINT): Загружать файл в базу на С++ примерно так же просто, как и получать: Чтобы максимально упростить пример, я использовал исключения вместо анализа кодов ошибок и стандартный класс _com_error, который определен в файле comutil.h. Кроме этого, в примере нет кода открытия соединения, так как предполагается, что в момент вызова этой функции соединение с БД уже открыто (глобальная переменная conn). При чтении данных типа text или ntext, тип варианта будет VT_BSTR. Я не думаю, что с ним могут возникнуть какие-либо проблемы.
|

