Speech dispatcher что это
Common interface to speech synthesis
This is the Speech Dispatcher project (speech-dispatcher). It is a part of the Free(b)soft project, which is intended to allow blind and visually impaired people to work with computer and Internet based on free software.
Speech Dispatcher project provides a high-level device independent layer for access to speech synthesis through a simple, stable and well documented interface.
Complete documentation may be found in doc directory: the speech dispatcher documentation: doc/speech-dispatcher.html, the spd-say documentation: doc/spd-say.html, and the SSIP protocol documentation: doc/ssip.html.
Read doc/README for more information.
The key features and the supported TTS engines, output subsystems, client interfaces and client applications known to work with Speech Dispatcher are listed in overview of speech-dispatcher as well as voices settings and where to look at in case of a sound or speech issue.
There is a public mailing-list speechd-discuss for this project.
This list is for Speech Dispatcher developers, as well as for users. If you want to contribute the development, propose a new feature, get help or just be informed about the latest news, don’t hesitate to subscribe. The communication on this list is held in English.
Various versions of speech-dispatcher can be downloaded from the project archive.
Bug reports, issues, and patches can be submitted to the github tracker.
The source code is freely available. It is managed using Git. You can use the GitHub web interface or clone the repository from:
A Java library is currently developed separately. You can use the GitHub web interface or clone the repository from:
To build and install speech-dispatcher and all of it’s components, read the file INSTALL.
Speech Dispatcher is being developed in closed cooperation between the Brailcom company and external developers, both are equally important parts of the development team. The development team also accepts and processes contributions from other developers, for which we are always very thankful! See more details about our development model in Cooperation. Bellow find a list of current inner development team members and people who have contributed to Speech Dispatcher in the past:
Copyright (C) 2001-2009 Brailcom, o.p.s Copyright (C) 2018-2020 Samuel Thibault samuel.thibault@ens-lyon.org Copyright (C) 2018 Didier Spaier didier@slint.fr
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details (file COPYING in the root directory).
You should have received a copy of the GNU General Public License along with this program. If not, see https://www.gnu.org/licenses/.
The speech-dispatcher server (src/server/ + src/common/) contains GPLv2-or-later and LGPLv2.1-or-later source code, but is linked against libdotconf, which is LGPLv2.1-only at the time of writing.
The speech-dispatcher modules (src/modules/ + src/common/ + src/audio/) contain GPLv2-or-later, LGPLv2.1-or-later, and LGPLv2-or-later source code, but are also linked against libdotconf, which is LGPLv2.1-only at the time of writing.
The spd-conf tool (src/api/python/speechd_config/), spd-say tool (src/clients/say), and spdsend tool (src/clients/spdsend/) are GPLv2-or-later.
The C API library (src/api/c/) is LGPLv2.1-or-later
The Common Lisp API library (src/api/cl/) is LGPLv2.1-or-later.
The Guile API library (src/api/guile/) contains GPLv2-or-later and LGPLv2.1-or-later source code.
The Python API library (src/api/python/speechd/) is LGPLv2.1-or-later.
All tests in src/tests/ are GPLv2-or-later.
Speech
Содержание
Речевые технологии [ править ]
На этой странице рассматриваются основные вопросы работы с речевыми синтезаторами с точки зрения их применения как средства вывода информации при работе на компьютере без зрительного контроля. Сейчас подготовлены к работе следующие синтезаторы:
Не все из приведённых синтезаторов удовлетворяют описанной ниже схеме.
Механизм унифицированной работы с речевыми синтезаторами [ править ]
Идея унифицированного вызова речевых синтезаторов заключается в том, чтобы перенаправлять речевую информацию от всех программ источников не напрямую в синтезатор, а в некоторое промежуточное программное обеспечение для предварительной обработки. Такой подход даёт возможность модифицировать порядок вызова синтезаторов и распространить изменения на все источники речи в системе. Также это позволяет исключить наложение звука при одновременном воспроизведении от разных программ.
При рассмотрении вопросов речевого вывода уделяется особое внимание:
Речевой сервер VoiceMan [ править ]
В ALT Linux вывод речи выполняет речевой сервер VoiceMan. Этот речевой сервер разрабатывался с 2003г. непосредственно для применения в среде ALT Linux. В него периодически вносятся изменения для более детальной интеграции в общий механизм вывода речи. Тем не менее, он не содержит каких-либо зависимостей на компоненты ALT Linux и может использоваться в любом дистрибутиве.
Конфигурационный файл может быть собран автоматически при каждом запуске сервера из фрагментов, сохранённых в специальной директории. Это очень важная особенность, плотно используемая в общей системе управления синтезаторами.
VoiceMan не занимается самостоятельно выводом звука. Другими словами, в нём нет кода, для обращения к какой-либо звуковой библиотеке. Вывод звука выполняет внешняя программа. Вызов каждого синтезатора заключается в порождении новой группы процессов, и передаче главному процессу текста на поток стандартного ввода. Описание внутреннего устройства VoiceMan можно прочитать в документе с описанием архитектуры вывода речи на его основе.
В настоящий момент VoiceMan имеет следующие недостатки:
Возможно, это будет не нужно, т. к. PulseAudio способен выполнять перехват вывода от ALSA нна системном уровне.
Speech Dispatcher и другие варианты речевых серверов [ править ]
Речевой сервер VoiceMan не единственный вариант приложения, который способен решать описанные задачи. Также для этих задач может применяться известная разработка Speech Dispatcher. Существует возможность распространить приводимую концепцию и на Speech Dispatcher, если конфигурационные возможности сервера окажутся достаточно гибкими, чтобы удовлетворять схеме, описанной ниже.Speech DispatcherБ упакован и помещён в репозиторий. Любые предложения по его поддержки принимаются и будут рассмотрены. Это утверждение также справедливо и для сервера multispeech.
ПВ вопросах применения различных серверов речи существует только одно ограничение: VoiceMan предпочтительно оставить сервером по умолчанию для программ-чтецов. Это связано с тем, что при установки пользователь должен получать максимально подготовленную и согласованную среду. В настоящий момент этому вопросу уделяется серьёзное внимание.
Как это устроено? [ править ]
Директория /etc/tts.d [ править ]
Ключевую роль в описываемой схеме играет директория /etc/tts.d. Предполагается, что каждый пакет с речевым синтезатором будет добавлять в эту директорию один или несколько файлов, достаточных, чтобы организовать взаимодействие с этим синтезатором каких-либо речевых серверов.
Рассмотрим пример : мы хотим установить синтезатор espeak. В пакете этого синтезатора присутствуют два файла:
Эти файлы содержат необходимую конфигурационную информацию для работы с английским и русским языком в сервере VoiceMan. Расширение .voiceman обозначает, что конфигурация предназначена именно для сервера VoiceMan. Допускается, чтобы в пакете также поставлялась конфигурационная информация и для других серверов. Например, файлы для Speech Dispatcher должны иметь расширение .spd.
Содержимое директории /etc/tts.d фактически показывает, какие синтезаторы способны работать с какими речевыми серверами. Содержимое файлов для VoiceMan будет приведено ниже.
Использование файлов из директории /etc/tts.d [ править ]
Как указывалось выше, сервер VoiceMan имеет единый конфигурационный файл, который при запуске составляется из фрагментов. В частности, директория /etc/voiceman.d содержит фрагменты, которые будут пристыкованы к главному файлу конфигурации при каждом запуске сервера.
Директория /etc/voiceman.d должна содержать символьные ссылки на файлы директории /etc/tts.d, указывающие, какие именно синтезаторы должны быть использованы в работе сервера. Манипулируя этими ссылками можно получить желаемое сочетание синтезаторов для работы с английским и русским языками. Эти ссылки не нужно создавать вручную. Доступны пять команд, для работы с ними:
При помощи этих команд можно выполнить манипуляции, и новая конфигурация будет задействована при следующем старте сервера.
Установка речевых компонентов на систему ALT Linux [ править ]
Для установки речевого вывода на систему ALT Linux в репозитории 4.1/branch доступны следующие пакеты:
Установка любого из этих пакетов выполнит все необходимые конфигурационные операции, которые требуются для работы программ-чтецов. Эти пакеты также можно ставить один поверх другого, как средство изменения конфигурации. В этом случае пакет, который был установлен системе, будет удалён автоматически. Эта операция совершенно безопасна, но изменение конфигурации при помощи средств VoiceMan предпочтительнее.
Как упаковать речевой синтезатор в пакет RPM? [ править ]
В этом разделе приводится сводка требований, которые нужны для правильной упаковки речевого синтезатора. Предположим, что мы упаковываем синтезатор с именем ttsname.
Остановимся на содержимом файла /etc/tts.d/ttsname.voiceman. Он должен содержать следующий текст (пример взят из синтезатора espeak):
Параметры name и type должны быть все одинаковые и иметь значение из примера. Параметр lang указывает язык и должен быть eng или rus.
Параметр command содержит текст команды, которую нужно вызвать, чтобы выполнить произношение текста. Предполагает, что сам текст поступит на поток стандартного ввода. В тексте команды могут присутствовать три подстановки : %v, %p и %r. На месте этих подстановок будут вставлено значения соответственно громкости, высоты и скорости речи.
Внутренние операции с этими параметрами сервер выполняет в диапазоне от 0 до 100. Перед вызовом команды текущее значение отображается в числовой диапазон, подходящий для конкретного синтезатора, а затем оставляется нужное количество десятичных знаков после запятой. Диапазон и количество знаков после запятой указываются тремя последующими параметрами из примера, где через двоеточие перечисляется количество знаков, нижняя граница и верхняя граница.
Последний параметр caplist содержит пары подстановок, где на первом месте стоит некоторая буква, а за ней следует короткая строка, которая должна быть озвучена в том случае, если была получена команда прочитать только эту букву. Эта возможность бывает очень полезна, т. к. не все синтезаторы выполняют разборчивое произношение отдельных букв.
Пакет: speech-dispatcher (0.10.2-3)
Ссылки для speech-dispatcher
Ресурсы Debian:
Исходный код speech-dispatcher:
Сопровождающие:
Внешние ресурсы:
Подобные пакеты:
общий интерфейс речевых синтезаторов
Speech Dispatcher (речевой диспетчер) предоставляет независимую от устройства прослойку для речевого синтеза. В качестве движка он поддерживает различные программные и аппаратные речевые синтезаторы и предоставляет общую прослойку для синтеза речи и воспроизведения данных в приложениях в формате PCM через эти движки.
Реализованы вне зависимости от устройств различные высокоуровневые концепции, такие как очереди или прерывания речи и специфичные для приложений пользовательские настройки. Таким образом программист освобождается от необходимости ещё раз изобретать колесо.
Данный пакет содержит сам Speech Dispatcher.
Теги: Поддержка общедоступности: Синтез речи, Пользовательский интерфейс: Демон, Сеть: network::server, role::program, Работает с: Аудио
Другие пакеты, относящиеся к speech-dispatcher
Загрузка speech-dispatcher
| Архитектура | Размер пакета | В установленном виде | Файлы |
|---|---|---|---|
| alpha (неофициальный перенос) | 2 291,6 Кб | 17 958,0 Кб | [список файлов] |
| amd64 | 2 300,3 Кб | 17 877,0 Кб | [список файлов] |
| arm64 | 2 297,0 Кб | 17 885,0 Кб | [список файлов] |
| armel | 2 281,0 Кб | 17 828,0 Кб | [список файлов] |
| armhf | 2 283,6 Кб | 17 756,0 Кб | [список файлов] |
| hppa (неофициальный перенос) | 2 289,3 Кб | 17 840,0 Кб | [список файлов] |
| i386 | 2 307,0 Кб | 17 924,0 Кб | [список файлов] |
| ia64 (неофициальный перенос) | 2 308,0 Кб | 18 182,0 Кб | [список файлов] |
| m68k (неофициальный перенос) | 2 292,3 Кб | 17 860,0 Кб | [список файлов] |
| mips64el | 2 276,9 Кб | 17 907,0 Кб | [список файлов] |
| mipsel | 2 283,3 Кб | 17 890,0 Кб | [список файлов] |
| ppc64 (неофициальный перенос) | 2 298,5 Кб | 18 194,0 Кб | [список файлов] |
| ppc64el | 2 310,5 Кб | 18 193,0 Кб | [список файлов] |
| riscv64 (неофициальный перенос) | 2 284,7 Кб | 17 778,0 Кб | [список файлов] |
| s390x | 2 291,1 Кб | 17 885,0 Кб | [список файлов] |
| sh4 (неофициальный перенос) | 2 309,4 Кб | 17 856,0 Кб | [список файлов] |
| sparc64 (неофициальный перенос) | 2 282,1 Кб | 17 880,0 Кб | [список файлов] |
| x32 (неофициальный перенос) | 2 294,1 Кб | 17 848,0 Кб | [список файлов] |
Эта страница также доступна на следующих языках (Как установить язык по умолчанию):
Чтобы сообщить о проблеме, связанной с веб-сайтом, отправьте сообщение (на английском) в список рассылки debian-www@lists.debian.org. Прочую контактную информацию см. на странице Debian Как с нами связаться.
Пакет: speech-dispatcher (0.10.2-3)
Ссылки для speech-dispatcher
Ресурсы Debian:
Исходный код speech-dispatcher:
Сопровождающие:
Внешние ресурсы:
Подобные пакеты:
общий интерфейс речевых синтезаторов
Speech Dispatcher (речевой диспетчер) предоставляет независимую от устройства прослойку для речевого синтеза. В качестве движка он поддерживает различные программные и аппаратные речевые синтезаторы и предоставляет общую прослойку для синтеза речи и воспроизведения данных в приложениях в формате PCM через эти движки.
Реализованы вне зависимости от устройств различные высокоуровневые концепции, такие как очереди или прерывания речи и специфичные для приложений пользовательские настройки. Таким образом программист освобождается от необходимости ещё раз изобретать колесо.
Данный пакет содержит сам Speech Dispatcher.
Теги: Поддержка общедоступности: Синтез речи, Пользовательский интерфейс: Демон, Сеть: network::server, role::program, Работает с: Аудио
Другие пакеты, относящиеся к speech-dispatcher
Загрузка speech-dispatcher
| Архитектура | Размер пакета | В установленном виде | Файлы |
|---|---|---|---|
| alpha (неофициальный перенос) | 2 291,6 Кб | 17 958,0 Кб | [список файлов] |
| amd64 | 2 300,3 Кб | 17 877,0 Кб | [список файлов] |
| arm64 | 2 297,0 Кб | 17 885,0 Кб | [список файлов] |
| armel | 2 281,0 Кб | 17 828,0 Кб | [список файлов] |
| armhf | 2 283,6 Кб | 17 756,0 Кб | [список файлов] |
| hppa (неофициальный перенос) | 2 289,3 Кб | 17 840,0 Кб | [список файлов] |
| i386 | 2 307,0 Кб | 17 924,0 Кб | [список файлов] |
| ia64 (неофициальный перенос) | 2 308,0 Кб | 18 182,0 Кб | [список файлов] |
| m68k (неофициальный перенос) | 2 292,3 Кб | 17 860,0 Кб | [список файлов] |
| mips64el | 2 276,9 Кб | 17 907,0 Кб | [список файлов] |
| mipsel | 2 283,3 Кб | 17 890,0 Кб | [список файлов] |
| ppc64 (неофициальный перенос) | 2 298,5 Кб | 18 194,0 Кб | [список файлов] |
| ppc64el | 2 310,5 Кб | 18 193,0 Кб | [список файлов] |
| riscv64 (неофициальный перенос) | 2 284,7 Кб | 17 778,0 Кб | [список файлов] |
| s390x | 2 291,1 Кб | 17 885,0 Кб | [список файлов] |
| sh4 (неофициальный перенос) | 2 309,4 Кб | 17 856,0 Кб | [список файлов] |
| sparc64 (неофициальный перенос) | 2 282,1 Кб | 17 880,0 Кб | [список файлов] |
| x32 (неофициальный перенос) | 2 294,1 Кб | 17 848,0 Кб | [список файлов] |
Эта страница также доступна на следующих языках (Как установить язык по умолчанию):
Чтобы сообщить о проблеме, связанной с веб-сайтом, отправьте сообщение (на английском) в список рассылки debian-www@lists.debian.org. Прочую контактную информацию см. на странице Debian Как с нами связаться.
Как сделать говорящую программу на Python самостоятельно?


Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.
Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:

В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64. » или еще что-то. Если не уверены, воспользуйтесь поиском:
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.

Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
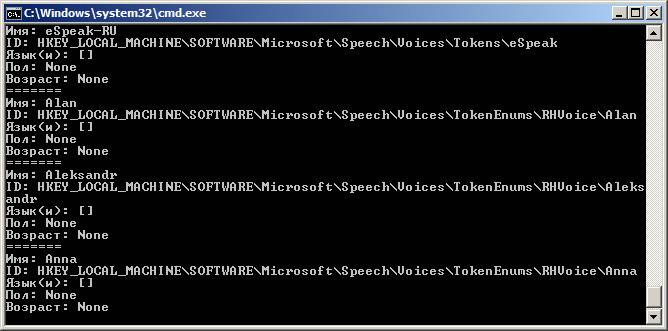
Результат будет примерно таким:
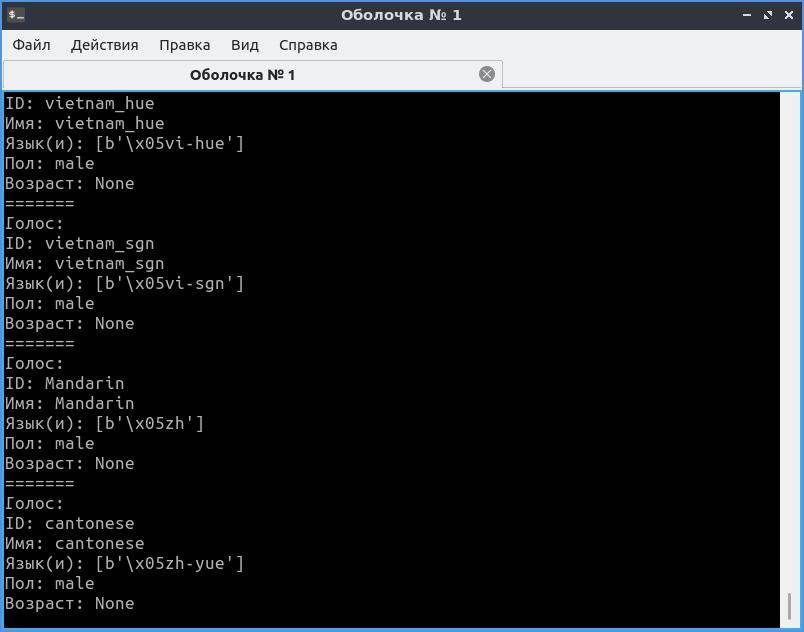
В Linux картина будет похожей, но с другими идентификаторами.
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
# Задать голос по умолчанию
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
# Использовать английский голос
tts.say(«Can you hear me say it’s a lovely day?»)
tts.say(«А напоследок я скажу»)
Как озвучить системное время в Windows и Linux

Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
for voice in voices:
if voice.name == ‘Aleksandr’:
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета

Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA

Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
Теперь эту заготовку можно применить в коде основной программы:
# … другие реплики или сон
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?
Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.
Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64. » или еще что-то. Если не уверены, воспользуйтесь поиском:
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.
Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:
В Linux картина будет похожей, но с другими идентификаторами.
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
# Задать голос по умолчанию
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
# Использовать английский голос
tts.say(«Can you hear me say it’s a lovely day?»)
tts.say(«А напоследок я скажу»)
Как озвучить системное время в Windows и Linux
Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
for voice in voices:
if voice.name == ‘Aleksandr’:
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA
Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
Теперь эту заготовку можно применить в коде основной программы:
# … другие реплики или сон
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?