10 структур данных, которые вы должны знать (+видео и задания)
Бо Карнс – разработчик и преподаватель расскажет о наиболее часто используемых и общих структурах данных. Специально для вас мы перевели его статью.
Связные списки
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки. 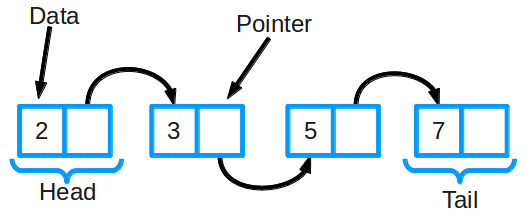
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности. Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке.
Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
Реализация на JavaScript
Задания с freeCodeCamp:
Стеки
Задания с freeCodeCamp:
Очереди
Вы можете думать об этой структуре, как об очереди людей в продуктовом магазине. Стоящий первым будет обслужен первым. Также как очередь.

Если рассматривать очередь с точки доступа к данным, то она является FIFO (First In First Out). Это означает, что после добавления нового элемента все элементы, которые были добавлены до этого, должны быть удалены до того, как новый элемент будет удален.
В очереди есть только две основные операции: enqueue и dequeue. Enqueue означает вставить элемент в конец очереди, а dequeue означает удаление переднего элемента.
Задания с freeCodeCamp:
Множества
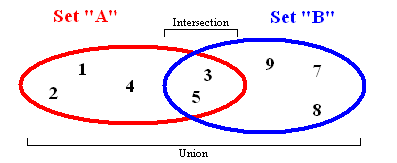
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно.
Задания с freeCodeCamp:
Задания с freeCodeCamp:
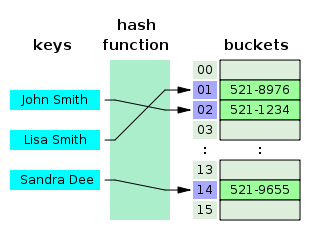
Хэш-таблицы
Задания с freeCodeCamp:
Двоичное дерево поиска
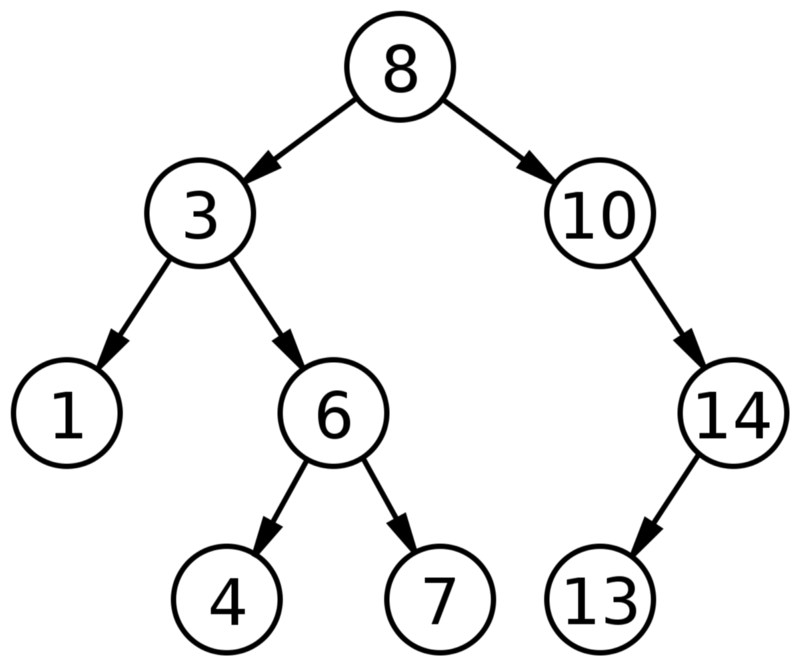
Двоичное дерево поиска имеет + две характеристики:
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Способ их настройки означает, что в среднем каждое сравнение позволяет операциям пропускать половину дерева, так что каждый поиск, вставка или удаление занимает время, пропорциональное логарифму количества элементов, хранящихся в дереве.
Задания с freeCodeCamp:
Префиксное дерево
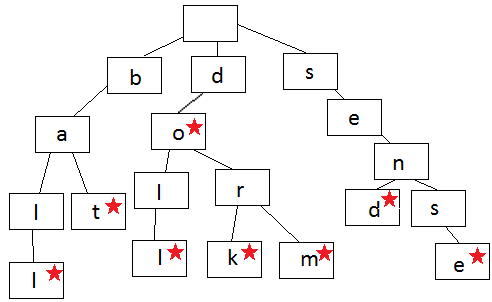
Каждый узел в префиксном дереве содержит одну букву слова. Вы следуете ветвям дерева, чтобы записать слово, по одной букве за раз. Шаги начинают расходиться, когда порядок букв отличается от других слов в дереве или, когда заканчивается слово. Каждый узел содержит букву (данные) и логическое значение, указывающее, является ли узел последним узлом в слове.
Посмотрите на изображение, и вы можете создавать слова. Всегда начинайте с корневого узла вверху и двигайтесь вниз. Показанное здесь дерево содержит слово ball, bat, doll, do, dork, dorm, send, sense.
Задания с freeCodeCamp:
Двоичная куча
Задания с freeCodeCamp:
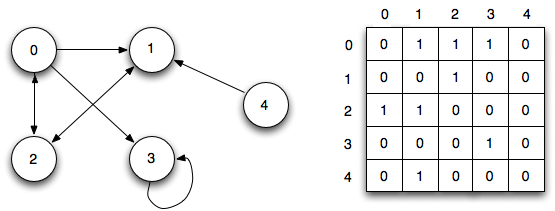
Графы
Задания с freeCodeCamp:
Если хотите узнать больше:
Основные структуры данных. Матчасть. Азы
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
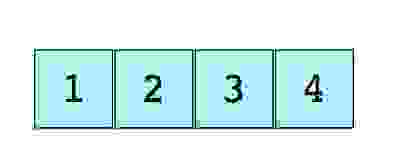
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
Вопросы
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
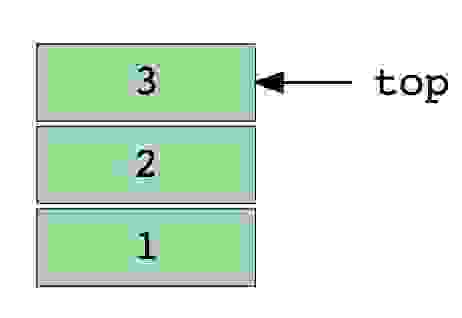
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
Основные операции
Вопросы
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
Вопросы
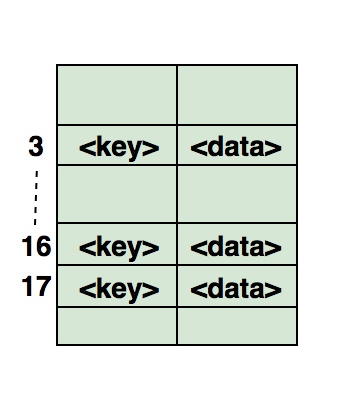
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
Вопросы
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
Общие алгоритмы обхода графа
Вопросы
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
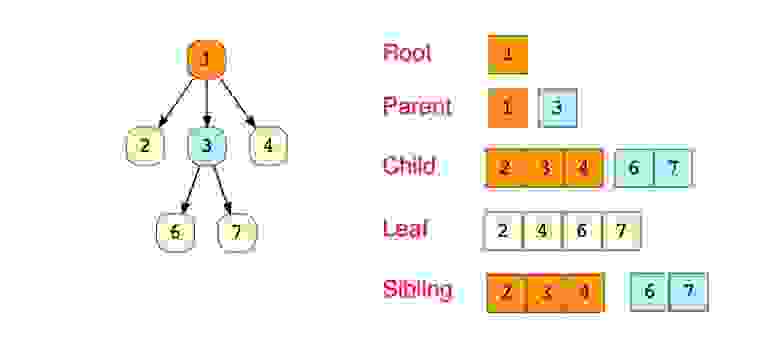
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
Вопросы
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
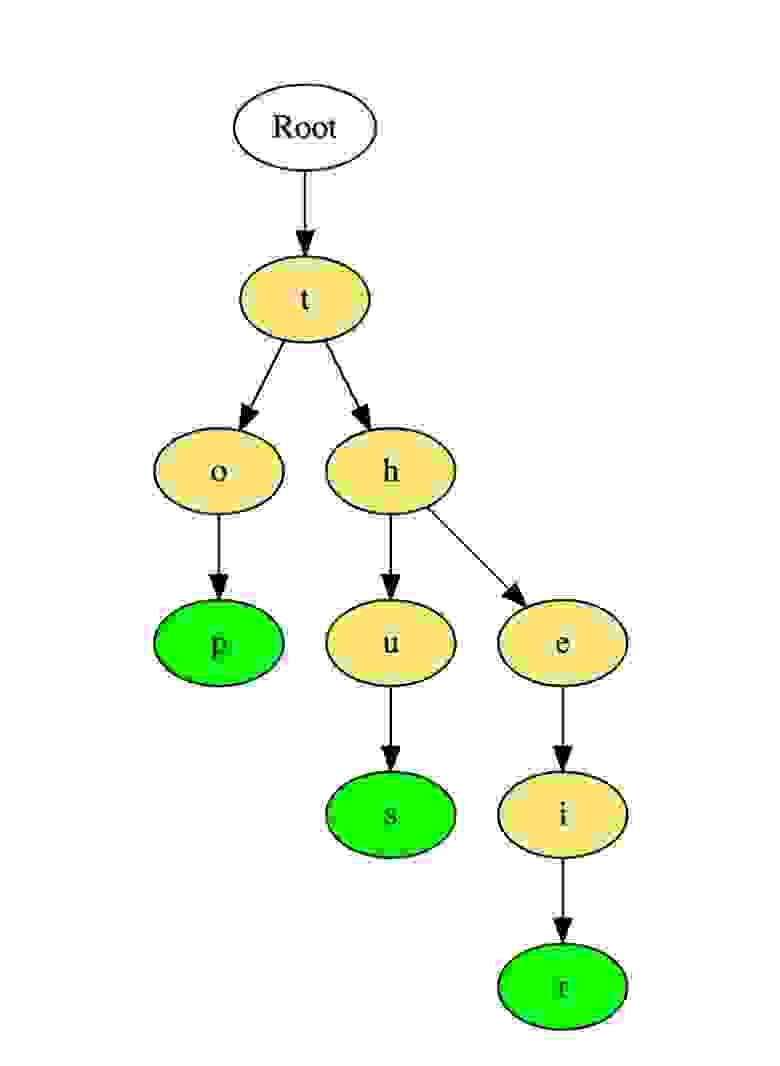
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
Вопросы
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
8 известных структур данных, о которых спросят на собеседовании
Кратко разбираем 8 основных структур данных, в которых должен разбираться каждый разработчик. Проверьте свои теоретические знания.

Никлаус Вирт, швейцарский информатик, написал в 1976 году книгу под названием «Алгоритмы + структуры данных = программы».
Больше сорока лет спустя это уравнение все еще верно. Почти все задачи программирования требуют от разработчика глубокого понимания структур данных. Вопросы на эту тему обязательно встречаются на любом IT-собеседовании.
Иногда в этих вопросах явно упоминается искомая структура, например, «дано двоичное дерево». В других случаях это не столь очевидно, например, «мы хотим отслеживать количество книг, связанных с каждым автором».
Изучение структур данных имеет важное значение, даже если вы не ищете новую работу, а просто хотите улучшить текущую. Давайте начнем с понимания основ.
Что такое структуры данных?
Простыми словами, структура данных – это контейнер, который хранит информацию в определенном виде. Из-за такой «компоновки» она может быть эффективной в одних операциях и неэффективной в других. Цель разработчика – выбрать из существующих структур оптимальный для конкретной задачи вариант.
Зачем нужны структуры данных?
Данные являются самой важной сущностью в информатике, а структуры позволяют хранить их в организованной форме.
Какую бы проблему вы не решали, вам приходится иметь дело с данными — будь то зарплата сотрудника, цены на акции, список покупок или даже простой телефонный справочник.
В зависимости от ситуации данные должны храниться в некотором определенном формате. Структуры данных предлагают несколько вариантов таких размещений.
8 часто используемых структур
Давайте сначала перечислим наиболее часто используемые структуры данных, а затем рассмотрим их одну за другой:
Массивы
Массив – это самая простая и наиболее широко используемая из структур. Стеки и очереди являются производными от массивов.
Вот изображение простого массива размером 4, содержащего элементы (1, 2, 3 и 4).
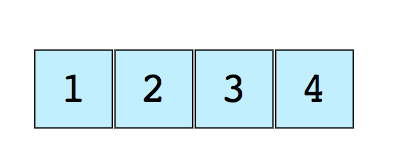
Каждому из них присваивается неотрицательное числовое значение – индекс, который соответствует позиции этого элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Существует два типа массивов:
Основные операции с массивами
Частые вопросы о массивах
Стеки
Мы все знакомы с опцией Отменить (Undo), которая присутствует практически в каждом приложении. Вы когда-нибудь задумывались, как это работает?
Для этого вы сохраняете предыдущие состояния приложения (определенное их количество) в памяти в таком порядке, что последнее сохраненное появляется первым. Это не может быть сделано только с помощью массивов. Здесь на помощь приходит стек.
Пример стека из реальной жизни – куча книг, лежащих друг на друге. Чтобы получить книгу, которая находится где-то в середине, вам нужно удалить все, что лежит сверху. Так работает метод LIFO (Last In First Out, последним пришел – первым ушел).
Вот изображение стека, содержащего три элемента (1, 2 и 3). Элемент 3 находится сверху и будет удален первым:
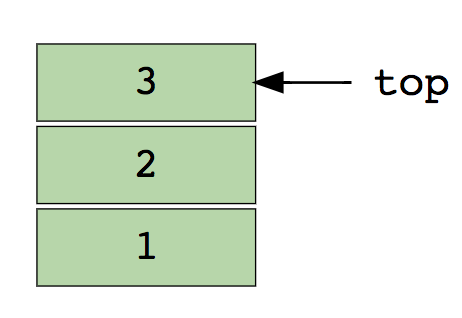
Основные операции со стеками
Часто задаваемые вопросы о стеках
Очереди
Как и стек, очередь – это линейная структура данных, которая хранит элементы последовательно. Единственное существенное различие заключается в том, что вместо использования метода LIFO, очередь реализует метод FIFO (First in First Out, первым пришел – первым ушел).
Идеальный пример этих структур в реальной жизни – очереди людей в билетную кассу. Если придет новый человек, он присоединится к линии с конца, а не с начала. А человек, стоящий впереди, первым получит билет и, следовательно, покинет очередь.
Вот изображение очереди, содержащей четыре элемента (1, 2, 3 и 4). Здесь 1 находится вверху и будет удален первым:
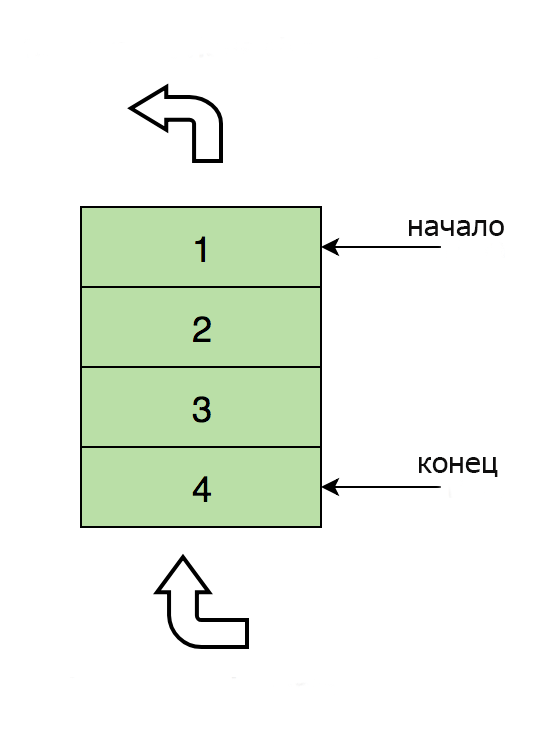
Основные операции с очередями
Часто задаваемые вопросы об очередях
Связный список
Еще одна важная линейная структура данных, которая на первый взгляд похожа на массив, но отличается распределением памяти, внутренней организацией и способом выполнения основных операций вставки и удаления.
Связный список – это сеть узлов, каждый из которых содержит данные и указатель на следующий узел в цепочке. Также есть указатель на первый элемент – head. Если список пуст, то он указывает на null.
Связные списки используются для реализации файловых систем, хэш-таблиц и списков смежности.
Вот визуальное представление внутренней структуры связного списка:

Основные операции со связными списками
Часто задаваемые вопросы о связных списках
Графы
Граф представляет собой набор узлов, соединенных друг с другом в виде сети. Узлы также называются вершинами. Пара (x, y) называется ребром, которое указывает, что вершина x соединена с вершиной y. Ребро может содержать вес/стоимость, показывая, сколько затрат требуется, чтобы пройти от x до y.
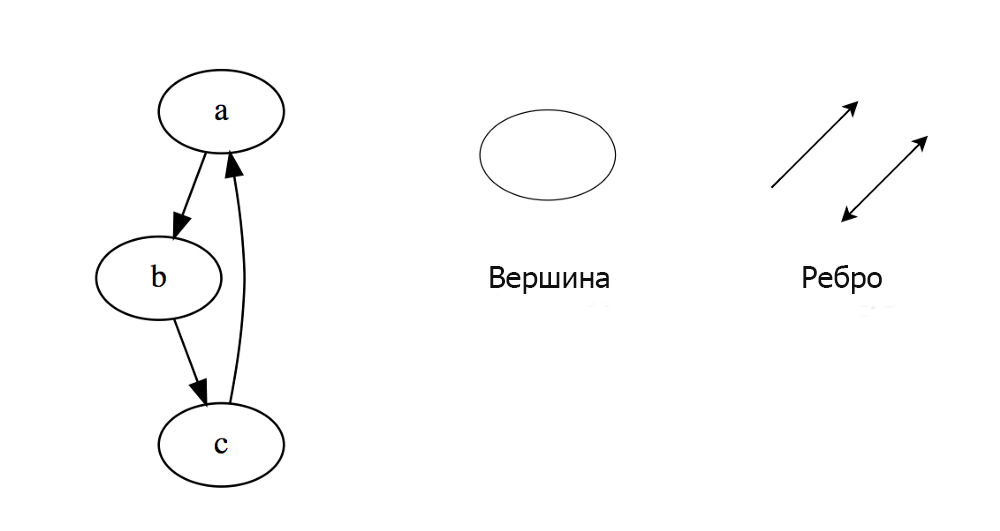
В языке программирования графы могут быть представлены в двух формах:
Часто задаваемые вопросы о графах
Деревья
Дерево – это иерархическая структура данных, состоящая из вершин (узлов) и ребер, соединяющих их. Они похожи на графы, но есть одно важное отличие: в дереве не может быть цикла.
Деревья широко используются в искусственном интеллекте и сложных алгоритмах для обеспечения эффективного механизма хранения данных.
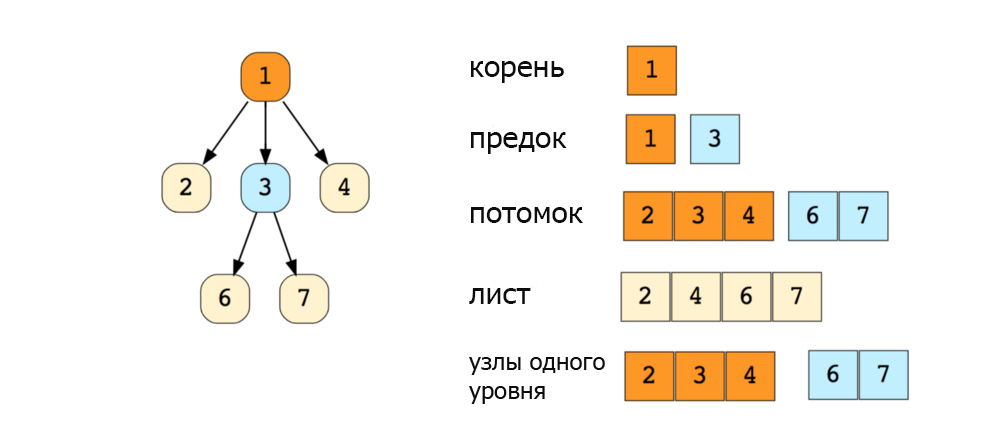
Вот изображение простого дерева, и основные термины:
Из всех типов чаще всего используются бинарное дерево и бинарное дерево поиска.
Часто задаваемые вопросы о деревьях
Префиксное дерево
Префиксные деревья (tries) – древовидные структуры данных, эффективные для решения задач со строками. Они обеспечивают быстрый поиск и используются преимущественно для поиска слов в словаре, автодополнения в поисковых системах и даже для IP-маршрутизации.
Вот иллюстрация того, как три слова top, thus и their хранятся в префиксном дереве:
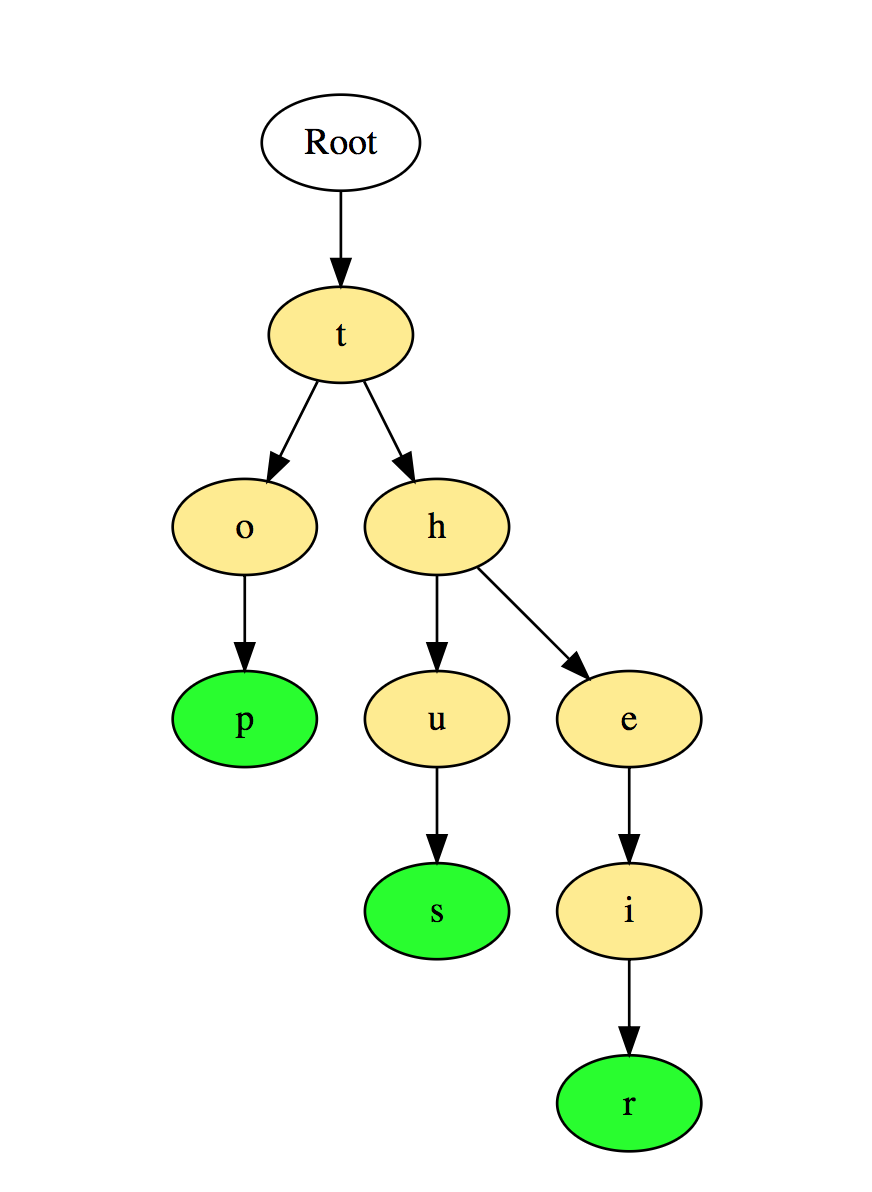
Слова размещаются сверху вниз. Выделенные зеленым элементы показывают конец каждого слова.
Часто задаваемые вопросы о префиксных деревьях
Хеш-Таблица
Хеширование – это процесс, используемый для уникальной идентификации объектов и хранения каждого из них в некотором предварительно вычисленном уникальном индексе – ключе. Итак, объект хранится в виде пары ключ-значение, а коллекция таких элементов называется словарем. Каждый объект можно найти с помощью его ключа. Существует несколько структур, основанных на хешировании, но наиболее часто используется хеш-таблица, которая обычно реализуется с помощью массивов.
Производительность структуры зависит от трех факторов:
Вот иллюстрация того, как хэш отображается в массиве. Индекс вычисляется с помощью хеш-функции.
Часто задаваемые вопросы о хеш-таблицах
Теперь вы знаете 8 основных структур данных любого языка программирования. Можете смело отправляться на IT-собеседование.
Самые популярные структуры данных
Что такое структура данных?
Проще говоря, структура данных — это контейнер, в котором хранятся данные в определенной компоновке (формате, или способе организации их в памяти). Эта «компоновка» позволяет структуре данных быть эффективной в одних операциях и неэффективной в других. Ваша цель — понять структуры данных, чтобы вы могли выбрать структуру данных, наиболее оптимальную для рассматриваемой проблемы.
Зачем нам нужны структуры данных?
Поскольку структуры данных используются для хранения данных в организованном виде, и поскольку данные являются наиболее важным элементом компьютерной науки, истинная ценность структур данных очевидна.
Независимо от того, какую проблему вы решаете, вам так или иначе приходится иметь дело с данными — будь то зарплата сотрудника, цены на акции, список покупок или даже простой телефонный справочник.
Исходя из разных сценариев, данные должны храниться в определенном формате. У нас есть несколько структур данных, которые покрывают потребность хранить данные в разных форматах.
Arrays — Массивы
Массив — это самая простая и наиболее широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Вот изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).

Каждому элементу данных присваивается положительное числовое значение, называемое индексом, которое соответствует позиции этого элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Основные операции над массивами
Вставить (Insert) — вставляет элемент по указанному индексу
Получить (Get) — возвращает элемент по указанному индексу
Удалить (Delete) — удаляет элемент по указанному индексу
Размер (Size) — получить общее количество элементов в массиве
Для самостоятельного изучения:
1. Найти второй минимальный элемент массива.
2. Первые неповторяющиеся целые числа в массиве.
3. Объединить два отсортированных массива.
4. Переставить положительные и отрицательные значения в массиве.
Stacks (Стеки)
Мы все знакомы со знаменитой опцией Undo (Отмена), которая присутствует практически в каждом приложении. Когда-нибудь задумывались, как это работает? Суть механизма в том, что вы сохраняете предыдущие состояния вашей работы (которые ограничены определенным числом) в памяти в таком порядке, что последнее действие появляется первым. Это не может быть сделано только с помощью массивов. Вот где стек и пригодится!
Реальным примером стека может быть стопка книг, расположенных в вертикальном порядке. Чтобы получить книгу, которая находится где-то посередине, вам нужно удалить все книги, помещенные поверх нее. Вот как работает метод LIFO (Last In First Out).
Вот изображение стека, содержащего три элемента данных (1, 2 и 3), где 3 вверху и будет удалено первым:
Основные операции со стеками:
Протолкнуть (Push) — вставляет элемент сверху других.
Вытащить (Pop) — возвращает верхний элемент после удаления из стека.
Пустой? (IsEmpty) — возвращает истина (true), если стек пуст.
Верхний (Top) — возвращает верхний элемент без удаления из стека.
Для самостоятельного изучения:
1. Оцените постфиксное выражение, используя стек.
2. Сортировка значений в стеке.
3. Проверьте сбалансированные скобки в выражении.
Queues (Очереди)
Подобно стеку, очередь — это еще одна линейная структура данных, в которой элементы хранятся последовательно. Единственное существенное различие между стеком и очередью состоит в том, что вместо использования метода LIFO в Queue реализован метод FIFO, который является сокращением от First in First Out.
Прекрасный реальный пример очереди: ряд людей, ожидающих у билетной кассы. Если приходит новый человек, он присоединяется к линии с конца, а не с начала — и человек, стоящий впереди, первым получит билет и, следовательно, покинет линию.
Вот изображение очереди, содержащей четыре элемента данных (1, 2, 3 и 4), где 1 находится вверху и будет удалено первым:
Основные операции с очередью:
Вочередить (Enqueue) — вставляет элемент в конец очереди.
Выочередить (Dequeue) — удаляет элемент из начала очереди.
Пустой? (IsEmpty) — возвращает истина (true), если очередь пуста.
Верхний (Top) — возвращает первый элемент очереди.
Для самостоятельного изучения:
1. Реализация стека с использованием очереди.
2. Обратные первые k элементы очереди.
3. Генерация двоичных чисел от 1 до n с использованием очереди.
Связанный список (Linked List)
Связанный список — это еще одна важная линейная структура данных, которая на первый взгляд может выглядеть аналогично массивам, но отличается распределением памяти, внутренней структурой и тем, как выполняются основные операции вставки и удаления.
Связанный список подобен цепочке узлов, где каждый узел содержит такую информацию, как данные, и указатель на последующий узел в цепочке. Есть указатель заголовка, который указывает на первый элемент связанного списка, и если список пуст, то он просто указывает на ноль или ничего.
Связанные списки используются для реализации файловых систем, хеш-таблиц и списков смежности.
Вот визуальное представление внутренней структуры связанного списка:
Основные операции над связанным списком
ВставитьВКонец (InsertAtEnd) — вставляет элемент в конец связанного списка.
ВставитьВНачало (InsertAtHead) — вставляет элемент в начало связанного списка.
Удалить (Delete) — удаляет данный элемент из связанного списка.
УдалитьВНачале (DeleteAtHead) — удаляет первый элемент связанного списка.
Search (Поиск) — возвращает найденный элемент из связанного списка.
Пустой? (IsEmpty) — возвращает истина (true), если связанный список пуст.
Для самостоятельного изучения:
1. Перевернуть связанный список (Обратить, реверсировать, отобразить задом наперёд).
2. Определить цикл в связанном списке.
3. Вернуть N-й узел с конца в связанном списке.
4. Удалить дубликаты из связанного списка.
Graphs (Графы)
Графы — это набор узлов, которые связаны друг с другом в форме сети. Узлы также называются вершинами. Пара (x, y) называется ребром, что указывает на то, что вершина x связана с вершиной y. Ребро может содержать вес / стоимость, показывая, сколько затрат требуется для перехода от вершины x к y.
Ниже приведен пример смежного списка Adjacency List (ненаправленный граф).
Для самостоятельного изучения:
1. Реализация Breadth and Depth First поиска
2. Проверка если граф дерево или нет.
3. Подсчет количества ребер в графе.
4. Найти кратчайший путь между вершинами.
Trees (Деревья)
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья похожи на графы, но ключевой момент, который отличает дерево от графа, состоит в том, что цикл не может существовать в дереве. Дерево — это разорваный граф.
Деревья широко используются в искусственном интеллекте и сложных алгоритмах, чтобы обеспечить эффективный механизм хранения для алгоритмов решения проблемы.
Вот изображение простого дерева и основные термины, используемые в древовидной структуре данных:
Имеются типы деревьев:
Из вышеперечисленного Бинарное дерево и Бинарное поисковое дерево являются наиболее часто используемыми деревьями.
Для самостоятельного изучения:
1. Найти высоту бинарного дерева.
2. Найти k-е максимальное значение в двоичном поисковом дереве.
3. Найти узлы на расстоянии «k» от корня.
4. Найти предков данного узла в двоичном дереве.
1. Facebook: Каждый пользователь представляет собой вершину, и два человека являются друзьями, когда имеется ребро между двумя вершинами. Так же и рекомендации в друзья — расчитываются на основаниитеории графов.
2. Карты Google: Различные локации представлены вершинами и дороги представлены ребрами, теория графов используется для нахождения кратчайшего пути между двумя вершинами.
3. Транспортные сети: в них вершины это пересечения дорог и рёбра — это дорожные сегменты между их пересечениями.
4. Представление молекулярных структур где вершины это молекулы и рёбра — это связи между молекулами.
6. Эмпирические наблюдения показывают, что большинство генов регулируются небольшим количеством других генов, обычно менее десяти. Следовательно, генетическая сеть может рассматриваться как разреженный граф, то есть граф, в котором узел связан с несколькими другими узлами. Если ориентированные (ациклические) графы или неориентированные графы насыщены вероятностями, то результатом являются вероятностно ориентированные графические модели и вероятностные неориентированные графические модели соответственно.
7. Теория расширение кластера Майера функции летучести газа (Z) в термодинамике требует вычисления двух, трех, четырёх условий и так далее. Существует систематический способ сделать это комбинаторно с диаграммами, и это помогает узнать связность таких диаграмм. Знание теории графов может быть полезным, когда вы хотите суммировать подмножество этих диаграмм.
8. Раскраска карты: знаменитая теорема о четырех цветах утверждает, что всегда можно правильно раскрасить регионы карты так, чтобы никаким двум смежным регионам не был назначен один и тот же цвет, используя не более четырех разных цветов. В этой модели регионы с цветами — это узлы, а смежность — ребра графа.
9. Задача с тремя коттеджами — это хорошо известная математическая головоломка. Ее можно сформулировать так: Три коттеджа на плоскости (или сфере), каждый из которых должен быть подключен к газовым, водопроводным и электрическим компаниям. Задача решается при помощи графа на плоскости.
10. Поиск центра графа: Для каждой вершины найдите длину кратчайшего пути к самой дальней вершине. Центром графа является вершина, для которой это значение минимально. Это важно для архитектурного планирования населенных пунктов, в которых больница, пожарная служба или отделение полиции должны быть расположены в так, чтобы самая дальняя точка была как можно ближе.
Для любителей С#, как я, линк с примерами кода построения графов на C# тут. Для самых продвинутых библиотека с реализацией графов на C++ тут. Для фанатов AI и Skynet топать сюда.
Очередности (Trie)
Очередности, также известные как деревья с префиксами (Prefix Trees), представляют собой древовидную структуру данных, которая оказывается достаточно эффективной для решения проблем, связанных со строками. Они обеспечивают быстрый поиск и, в основном, используются для поиска слов в словаре, автоматического предложения в поисковой системе и даже для IP-маршрутизации.
Вот иллюстрация того, как три слова «top», «thus», и «their» хранятся в Очередности:
Слова хранятся сверху вниз, где зеленые узлы “p”, “s” и “r” указывают на конец “top”, “thus”, и “their” соответственно.
Для самостоятельного изучения:
1. Подсчитать общее количество слов в Очередности.
2. Распечатать все слова, хранящиеся в Очередности.
3. Сортировка элементов массива с использованием Очередности.
4. Формируйте слова из словаря, используя Очередности.
5. Создайте словарь T9.
Практические примеры использования:
1. Выбор из словаря или завершение при наборе слова.
2. Поиск в контактах в телефоне или телефонном словаре.
Hash Table (Хеш-таблица)
Хеширование — это процесс, используемый для уникальной идентификации объектов и сохранения каждого объекта по некоторому предварительно рассчитанному уникальному индексу, называемому его «ключом». Таким образом, объект хранится в форме пары «ключ-значение», а коллекция таких элементов называется «словарь». Каждый объект может быть найден с помощью этого ключа.
Существуют разные структуры данных, основанные на хешировании, но наиболее часто используемой структурой данных является хеш-таблица. Хэш-таблица используется, когда вам нужно получить доступ к элементам с помощью ключа, и вы можете определить полезное значение ключа.
Хеш-таблицы обычно реализуются с использованием массивов.
Вот иллюстрация того, как хэш отображается в массиве. Индекс этого массива вычисляется с помощью хэш-функции.
Для самостоятельного изучения:
1. Найти симметричные пары в массиве.
2. Проследить полный путь путешествия.
3. Найти, если массив является подмножеством другого массива.
4. Проверьте, являются ли данные массивы непересекающимися.
1. Игра «Жизнь». В ней хэш — это набор координат каждой живой клетки.
2. Примитивный вариант поисковой системы Google мог бы картировать все существующие слова в набор URL где они встречаются. В этом случае, хэштаблицы используются дважды: в первый раз для картирования слов в наборы URLs, и, во второй раз, для сохранения каждого набора URLs.
3. При имплементации структуры/алгоритма многонаправленного дерева (multiway tree) хэштаблицы могут использоваться для быстрого доступа к любому дочернему элементу внутреннего узла.
4. При написании программы для игры в шахматы, очень важно отслеживать позиции оцененные ранее, так что можно было бы вернуться, когда понадобится к ним снова при необходимости.
5. Любой язык программирования нуждается в картировании имени переменной ее адресу в памяти. Фактически, в скриптовых языках как Javascript и Perl, поля могут быть добавлены в объекту динамически, это означает, что объекты сами по себе как хэш-карты.