7 полезных операций в Pandas при работе с DataFrame

Apr 27 · 7 min read

Абстракция датафрейма является одной из наиболее полезных концепций в современной экосистеме управления данными. Вращается она главным образом вокруг табличных структур, которые имеют повышенную производительность при обновлении и запросе данных различными способами. Сериализация/десериализация этих структур из/в различные форматы файлов упрощает работу с данными. Более того, возможность производить различные SQL-подобные операции, такие как объединение, наряду с выполнением математических вычислений в самом датафрейме существенно расширяет возможности программиста.
Эта статья подчеркивает некоторые на и более полезные операции, которые можно выполнять с помощью абстракции датафрейма. Реализовывать мы их будем через библиотеку Pandas. Постараюсь представить материал в интуитивно понятной форме, чтобы в дальнейшем вы могли применить эти знания в других случаях или при работе с другими фреймворками.
1. Конкатенация DataFrame
Если требуется конкатенировать их вдоль x, то вызов API будет таким:
Если же вдоль y, то таким:
Применение
Вариант с axis = 0 используется нечасто, но его можно применять в сценариях, когда нужно обработать массивы данных, собранных с упорядочиванием. То есть, когда последовательность данных соответствует последовательности других массивов данных. В таком случае эти массивы можно объединить вдоль оси x, получив более объемное и значительное представление в табличном формате. Затем к полученной структуре можно применять операции, использующие все типы данных в ее столбцах.
2. Разделение DataFrame
Датафрейм можно разделить множеством способов, и выбор техники полностью зависит от цели этого разделения. Рассмотрим ряд случаев.
Просмотр сведений
Исключение столбцов
Этот метод разделяет датафрейм вдоль оси y, то есть просто выбрасывает из него часть столбцов. Используется данный метод в типичном сценарии, когда нам не нужно, чтобы конечный DataFrame содержал эти столбцы, или когда мы предполагаем, что при дальнейшем обновлении структура станет занимать слишком много памяти.
Удаление датафреймов друг из друга
Применение
Предположим, что столбец A — это определенный вид ID сведений о работнике. К примеру, датафрейм X состоит из всех данных о работниках, а датафрейм Y содержит данные (с той же структурой) о работниках, не разбирающихся в Python. Нам нужно отфильтровать сведения о сотрудниках, которые не знакомы с Python.
Определение дельты записей на основе столбца
Применение
Взгляните на эту таблицу:

Эти пары могли быть сгенерированы, например, из двух журналов: старого и нового. Нам нужно найти пары ID, принадлежащие одному и тому же человеку. Предположим, что ваш отдел кадров неожиданно заявляет, что определенный список ( hr_list ) сотрудников с ID_1 больше в компании не работает. Как удалить их из этого датафрейма?
Разделение на основе значений столбцов
Датафрейм можно фильтровать на основе значений столбца. В этом случае критерий отбора может включать несколько выражений при условии, что они будут возвращать логические значения.
Это простейший пример.
3. Подсчет записей в столбце
Это эффективный способ определения количества различных элементов в столбце.

Ответ на приведенный выше запрос можно получить следующим подходом:
4. Чтение фрагментов DataFrame
В некоторых случаях будет более эффективно считывать только части датафрейма, особенно при его больших размерах. Обратите внимание, что каждый датафрейм является индексированной табличной структурой, находящейся в памяти, а значит потребляющей пространство, потенциально нужное другим структурам данных. В связи с этим при работе с большими массивами информации всегда лучше считывать только ее нужную часть.
Более того, можно считывать большие файлы в отдельные фрагменты и маршалировать их в датафреймы.
5. Применение функций к строкам
Есть и альтернативный метод. Его можно использовать, когда функцию f() требуется применить только к одному столбцу.
6. Объединение двух датафреймов
Однако стоит заметить, что операция merge является дорогостоящей, в связи с чем перед слиянием больших датасетов стоит проявлять особое внимание. В случаях, когда датасеты слишком велики, рекомендуется использовать методы группировки (англ.), чтобы избежать перегрузки памяти и связанных с этим проблем производительности.
7. Переименование столбцов
Переименовывать столбцы особенно полезно перед сериализацией файла или перед внедрением стороннего хранилища данных.
Как отфильтровать датафрейм Pandas за 3 минуты

В Pandas есть много способов отфильтровать DataFrame. Я познакомлю вас с наиболее важными вариантами с помощью Симпсонов.
Логическое индексирование
Пример 1. Выбор строк с определенным значением.
Давайте найдем все записи для Барта, чтобы мы могли переслать их его менеджеру:
На съемочной площадке дошли слухи, что мы являемся экспертами в области данных, а партнеры по рекламе хотят знать, что именно показывают дети в рекламных целях:
Мы увидим саксофон, автомобили и рогатки в телевизионной рекламе.
Также Симпсоны должны экономить деньги. Новые правила:
2) можно заказывать не более 3 предметов на человека
Я надеюсь, что Гомер и Барт останутся с нами и не покинут шоу в ярости…
К сожалению, звезды сериала не в восторге от этих сокращений, поэтому первые спонсоры выступают, чтобы помочь:
Позиционная индексация
Иногда вы не хотите фильтровать в соответствии с определенным условием, но выбираете определенные строки DataFrame в зависимости от их положения. В этом случае мы используем нарезку, чтобы получить нужные строки.
Новый стажер в вашем отделе не должен работать напрямую со всем набором данных, ему нужны только первые три записи:
У вас много работы, и вы получите другого стажера. Чтобы оба слушателя работали над своими задачами независимо, теперь вы сохраняете последние три строки записи:
Вывод
Мы можем выбрать любую конкретную строку из нашего набора данных в соответствии с ее значениями или положением. Pandas предлагает простые способы учета нескольких значений при формулировании условия. Списки и условия могут быть легко связаны друг с другом.
7 полезных операций в Pandas при работе с DataFrame

Абстракция датафрейма является одной из наиболее полезных концепций в современной экосистеме управления данными. Вращается она главным образом вокруг табличных структур, которые имеют повышенную производительность при обновлении и запросе данных различными способами. Сериализация/десериализация этих структур из/в различные форматы файлов упрощает работу с данными. Более того, возможность производить различные SQL-подобные операции, такие как объединение, наряду с выполнением математических вычислений в самом датафрейме существенно расширяет возможности программиста.
Эта статья подчеркивает некоторые наиболее полезные операции, которые можно выполнять с помощью абстракции датафрейма. Реализовывать мы их будем через библиотеку Pandas. Постараюсь представить материал в интуитивно понятной форме, чтобы в дальнейшем вы могли применить эти знания в других случаях или при работе с другими фреймворками.
1. Конкатенация DataFrame
Если требуется конкатенировать их вдоль x, то вызов API будет таким:
Если же вдоль y, то таким:
Применение
Вариант с axis = 0 используется нечасто, но его можно применять в сценариях, когда нужно обработать массивы данных, собранных с упорядочиванием. То есть, когда последовательность данных соответствует последовательности других массивов данных. В таком случае эти массивы можно объединить вдоль оси x, получив более объемное и значительное представление в табличном формате. Затем к полученной структуре можно применять операции, использующие все типы данных в ее столбцах.
2. Разделение DataFrame
Датафрейм можно разделить множеством способов, и выбор техники полностью зависит от цели этого разделения. Рассмотрим ряд случаев.
Просмотр сведений
Исключение столбцов
Этот метод разделяет датафрейм вдоль оси y, то есть просто выбрасывает из него часть столбцов. Используется данный метод в типичном сценарии, когда нам не нужно, чтобы конечный DataFrame содержал эти столбцы, или когда мы предполагаем, что при дальнейшем обновлении структура станет занимать слишком много памяти.
Удаление датафреймов друг из друга
Применение
Предположим, что столбец A — это определенный вид ID сведений о работнике. К примеру, датафрейм X состоит из всех данных о работниках, а датафрейм Y содержит данные (с той же структурой) о работниках, не разбирающихся в Python. Нам нужно отфильтровать сведения о сотрудниках, которые не знакомы с Python.
Определение дельты записей на основе столбца
Применение
Взгляните на эту таблицу:
Эти пары могли быть сгенерированы, например, из двух журналов: старого и нового. Нам нужно найти пары ID, принадлежащие одному и тому же человеку. Предположим, что ваш отдел кадров неожиданно заявляет, что определенный список ( hr_list ) сотрудников с ID_1 больше в компании не работает. Как удалить их из этого датафрейма?
Разделение на основе значений столбцов
Датафрейм можно фильтровать на основе значений столбца. В этом случае критерий отбора может включать несколько выражений при условии, что они будут возвращать логические значения.
Это простейший пример.
3. Подсчет записей в столбце
Это эффективный способ определения количества различных элементов в столбце.
Ответ на приведенный выше запрос можно получить следующим подходом:
4. Чтение фрагментов DataFrame
В некоторых случаях будет более эффективно считывать только части датафрейма, особенно при его больших размерах. Обратите внимание, что каждый датафрейм является индексированной табличной структурой, находящейся в памяти, а значит потребляющей пространство, потенциально нужное другим структурам данных. В связи с этим при работе с большими массивами информации всегда лучше считывать только ее нужную часть.
Более того, можно считывать большие файлы в отдельные фрагменты и маршалировать их в датафреймы.
5. Применение функций к строкам
Есть и альтернативный метод. Его можно использовать, когда функцию f() требуется применить только к одному столбцу.
6. Объединение двух датафреймов
Однако стоит заметить, что операция merge является дорогостоящей, в связи с чем перед слиянием больших датасетов стоит проявлять особое внимание. В случаях, когда датасеты слишком велики, рекомендуется использовать методы группировки (англ.), чтобы избежать перегрузки памяти и связанных с этим проблем производительности.
7. Переименование столбцов
Переименовывать столбцы особенно полезно перед сериализацией файла или перед внедрением стороннего хранилища данных.
Python 3 Pandas: Объекты Series и DataFrame. Построение Index

Что такое Pandas DataFrame?
Pandas — более новый пакет, надстройка над библиотекой NumPy, обеспечивающий эффективную реализацию класса DataFrame.
Объекты DataFrame — многомерные массивы с метками для строк и столбцов, а также зачастую с неоднородным типом данных и/или пропущенными данными.
Помимо удобного интерфейса для хранения маркированных данных, библиотека Pandas реализует множество операций для работы с данными хорошо знакомых пользователям фреймворков баз данных и электронных таблиц.
Импорт библиотек NumPy и Pandas
На самом примитивном уровне объекты библиотеки Pandas можно считать расширенной версией структурированных массивов библиотеки NumPy, в которых строки и столбцы идентифицируются метками, а не простыми числовыми индексами. Библиотека Pandas предоставляет множество полезных утилит, методов и функциональности в дополнение к базовым структурам данных, но все последующее изложение потребует понимания этих базовых структур. Позвольте познакомить вас с тремя фундаментальными структурами данных библиотеки Pandas: классами Series, DataFrame и Index.
Начнем наш сеанс программирования с обычных импортов библиотек NumPy и Pandas:
Объект Series библиотеки Pandas
Объект Series библиотеки Pandas — одномерный массив индексированных данных. Его можно создать из списка или массива следующим образом:
Результат:

Как мы видели из предыдущего результата, объект Series служит адаптером как для последовательности значений, так и последовательности индексов, к которым можно получить доступ посредством атрибутов values и index. Атрибут values представляет собой массив NumPy:
Результат:
Index — массивоподобный объект типа pd.Index:
Результат:
Аналогично массивам библиотеки NumPy, к данным можно обращаться по соответствующему им индексу посредством нотации с использованием квадратных скобок языка Python:
Результат:
Однако объект Series библиотеки Pandas намного универсальнее и гибче, чем эмулируемый им одномерный массив библиотеки NumPy.
Объект Series как обобщенный массив NumPy
Может показаться, что объект Series и одномерный массив библиотеки NumPy взаимозаменяемы. Основное различие между ними — индекс. В то время как индекс массива NumPy, используемый для доступа к значениям, — целочисленный и описывается неявно, индекс объекта Series библиотеки Pandas описывается явно и связывается со значениями.
Явное описание индекса расширяет возможности объекта Series. Такой индекс не должен быть целым числом, а может состоять из значений любого нужного типа. Например, при желании мы можем использовать в качестве индекса строковые значения:
Результат:
При этом доступ к элементам работает обычным образом:
Результат:
Объект Series как специализированный словарь
Объект Series библиотеки Pandas можно рассматривать как специализированную разновидность словаря языка Python. Словарь — структура, задающая соответствие произвольных ключей набору произвольных значений, а объект Series — структура, задающая соответствие типизированных ключей набору типизированных значений.
Типизация важна: точно так же, как соответствующий типу специализированный код для массива библиотеки NumPy при выполнении определенных операций делает его эффективнее, чем стандартный список Python, информация о типе в объекте Series библиотеки Pandas делает его намного более эффективным для определенных операций, чем словари Python.
Можно сделать аналогию «объект Series — словарь» еще более наглядной, сконструировав объект Series непосредственно из словаря Python.
По умолчанию при этом будет создан объект Series с полученным из отсортированных ключей индексом. Следовательно, для него возможен обычный доступ к элементам, такой же, как для словаря. Объект Series поддерживает операции «срезы».
Результат:
Создание объектов Series
Мы уже изучили несколько способов создания объектов Series библиотеки Pandas с нуля.
Все они представляют собой различные варианты следующего синтаксиса Pandas Series (общий вид синтаксиса):
где index — необязательный аргумент, а data может быть одной из множества сущностей.
Например, аргумент data может быть списком или массивом NumPy. В этом случае index по умолчанию будет целочисленной последовательностью:
Результат:
Аргумент data может быть скалярным значением, которое будет повторено нужное количество раз для заполнения заданного индекса:
Результат:
Аргумент data может быть словарем, в котором index по умолчанию является отсортированными ключами этого словаря:
Результат:
В каждом случае индекс можно указать вручную, если необходимо получить другой результат:
Результат:
Обратите внимание, что объект Series заполняется только заданными явным образом ключами.
Объект DataFrame библиотеки Pandas
Следующая базовая структура библиотеки Pandas — объект DataFrame. Как и объект Series, объект DataFrame можно рассматривать или как обобщение массива NumPy, или как специализированную версию словаря Python. Изучим оба варианта.
DataFrame как обобщенный массив NumPy
Если объект Series — аналог одномерного массива с гибкими индексами, объект DataFrame — аналог двумерного массива с гибкими индексами строк и гибкими именами столбцов. Аналогично тому, что двумерный массив можно рассматривать как упорядоченную последовательность выровненных столбцов, объект DataFrame можно рассматривать как упорядоченную последовательность выровненных объектов Series. Под «выровненными» имеется в виду то, что они используют один и тот же индекс.
Чтобы продемонстрировать это, сначала создадим новый объект Series, содержащий площадь каждого из пяти упомянутых в предыдущем разделе штатов:
Результат:
Воспользовавшись объектом population класса Series, сконструируем на основе словаря единый двумерный объект, содержащий всю эту информацию:
Результат:
Аналогично объекту Series у объекта DataFrame имеется атрибут index, обеспечивающий доступ к меткам индекса. Еще у объекта DataFrame есть атрибут columns, представляющий собой содержащий метки столбцов объект Index.
Результат:
Таким образом, объект DataFrame можно рассматривать как обобщение двумерного массива NumPy, где как у строк, так и у столбцов есть обобщенные индексы для доступа к данным.
Объект DataFrame как специализированный словарь
DataFrame можно рассматривать как специализированный словарь. Если словарь задает соответствие ключей значениям, то DataFrame задает соответствие имени столбца объекту Series с данными этого столбца. Например, запрос данных по атрибуту ‘area’ приведет к тому, что будет возвращен объект Series, содержащий площади штатов:
Результат:
Создание объектов DataFrame
Существует множество способов создания объектов DataFrame библиотеки Pandas. Вот несколько примеров.
Из одного объекта Series
Объект DataFrame — набор объектов Series.
DataFrame, состоящий из одного столбца, можно создать на основе одного объекта Series:
Результат:
Из списка словарей
Любой список словарей можно преобразовать в объект DataFrame. Мы воспользуемся простым списковым включением для создания данных:
Результат:
Даже если некоторые ключи в словаре отсутствуют, библиотека Pandas просто заполнит их значениями NaN (то есть Not a number — «не является числом»):
Результат:
Из словаря объектов Series
Объект DataFrame также можно создать на основе словаря объектов Series (этот пример был приведен ранее):
Результат:
Из двумерного массива NumPy
Если у нас есть двумерный массив данных, мы можем создать объект DataFrame с любыми заданными именами столбцов и индексов. Для каждого из пропущенных значений будет использоваться целочисленный индекс:
Результат:
Из структурированного массива NumPy
Объект DataFrame библиотеки Pandas ведет себя во многом аналогично структурированному массиву библиотеки NumPy и может быть создан непосредственно из него:
Результат:
Объект Index библиотеки Pandas
Как объект Series, так и объект DataFrame содержат явный индекс, обеспечивающий возможность ссылаться на данные и модифицировать их.
Объект Index можно рассматривать или как неизменяемый массив (immutable array), или как упорядоченное множество (ordered set) (формально мультимножество, так как объекты Index могут содержать повторяющиеся значения). Из этих способов его представления следуют некоторые интересные возможности операций над объектами Index. В качестве простого примера создадим Index из списка целых чисел:
Результат:
Объект Index как неизменяемый массив
Объект Index во многом ведет себя аналогично массиву. Например, для извлечения из него значений или срезов можно использовать стандартную нотацию индексации языка Python. У объектов Index есть много атрибутов.
Результат:
Одно из различий между объектами Index и массивами NumPy — неизменяемость индексов, то есть их нельзя модифицировать стандартными средствами:
Результат:
Неизменяемость делает безопаснее совместное использование индексов несколькими объектами DataFrame и массивами, исключая возможность побочных эффектов в виде случайной модификации индекса по неосторожности.
Выбор подмножеств данных в Pandas
Анатомия Python Pandas DataFrame — Column, Index, Data
Рассмотрим изображение контейнера данных DataFrame (библиотеки Pandas):

Три компонента DataFrame:
Индекс — это последовательность значений в левой части DataFrame. Каждое отдельное значение индекса называется index label, Иногда индекс упоминается как заголовки строк. В приведенном выше примере метки строк не очень интересны и представляют собой целые числа, начиная с 0 до n-1, где n — количество строк в таблице.
Столбцы представляют собой последовательность значений в самой верхней части DataFrame.
Все остальное является данными или значениями. Иногда вы будете слышать, как датафреймы называют табличными данными. Это просто еще одно имя для данных прямоугольной таблицы со строками и столбцами.
Каждая строка имеет метку, каждая колонка имеет метку
Основной вывод из анатомии DataFrame заключается в том, что каждая строка имеет метку, каждый столбец имеет метку. Эти метки используются для ссылки на конкретные строки или столбцы в DataFrame.
Что такое выбор подмножества?
Прежде чем мы начнем делать выбор подмножества, было бы хорошо определить, что это такое. Выбор подмножества — это просто выбор определенных строк и столбцов данных из DataFrame (или Series). Это может означать выбор всех строк и некоторых столбцов, некоторых строк и всех столбцов или некоторых строк и столбцов.
Выбор при помощи []
Загружаем данные из CSV в Pandas DataFrame (Python 3)
Скачать файл для использования в примерах:
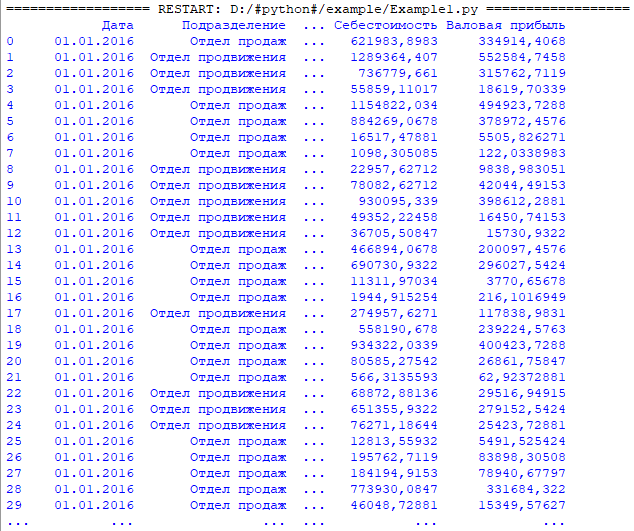
Код загрузки данных из csv в Pandas DataFrame:
Результат:
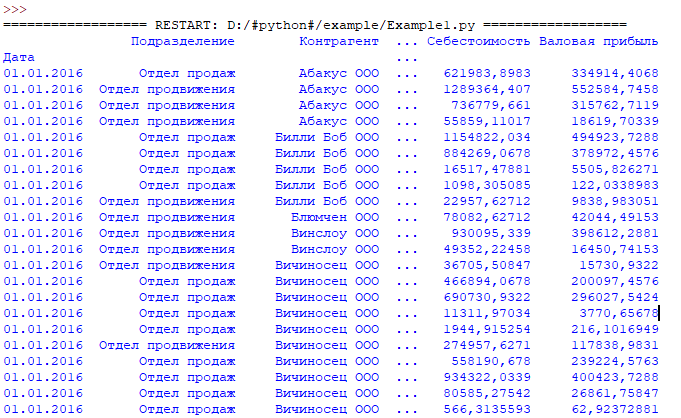
Вариант 2 загрузки данных из CSV (Index генерируется самостоятельно)
Результат:
Извлечение отдельных компонентов DataFrame
Ранее мы упоминали три компоненты DataFrame. Индекс, столбцы и данные (значения). Мы можем извлечь каждый из этих компонентов в свои переменные. Давайте сделаем это, а затем осмотрим их:
Результат:

Типы данных компонентов
Давайте выведем тип каждого компонента, чтобы точно понять, что это за объект.
Результат:
Понимание этих типов
Интересно, что и индекс, и столбцы имеют одинаковый тип. Они оба Index- объект Pandas. Этот объект сам по себе довольно мощный, но сейчас вы можете думать о нем как о последовательности меток для строк или столбцов.
Pandas построен непосредственно поверх NumPy, и именно этот массив отвечает за большую часть рабочей нагрузки.
Выбор одного столбца как серии
Чтобы выбрать один столбец данных, просто поместите имя столбца в скобках. Давайте выберем столбец Подразделение:
Результат:
Анатомия Series, возвращаемой при выборе 1 столбца
Выбор одного столбца данных возвращает другой контейнер данных Pandas Series.
Визуальное отображение Series — это просто текст, в отличие от красиво оформленной таблицы для DataFrames.
Вы также заметите две дополнительные части данных в нижней части Series.
Name из Series становится старое имя колонки. Вы также увидите тип данных или dtype серии. Вы можете игнорировать оба этих элемента на данный момент. А также количество элементов Length.
Выбор нескольких столбцов с помощью оператора индексации
Можно выбрать несколько столбцов только с помощью оператора индексации, передав ему список имен столбцов. Давайте выберем ‘Подразделение’, ‘Менеджер’, ‘Номенклатура’, ‘Продажи’
Результат:
Выбор нескольких столбцов возвращает DataFrame
Выбор нескольких столбцов возвращает DataFrame. На самом деле вы можете выбрать один столбец как DataFrame со списком из одного элемента:
Результат:
Хотя это напоминает Series, технически это DataFrame, другой объект.
Порядок столбцов не имеет значения
При выборе нескольких столбцов вы можете выбрать их в любом порядке по вашему выбору. Это не должен быть тот же самый порядок как оригинальный DataFrame.
Например, давайте выберем Номенклатура, Подразделение:
Результат:
Исключения, при выполнении скрипта
Есть несколько общих исключений, которые возникают при выполнении выборок только с помощью оператора индексации.
.loc — Индексатор возвращает одну строку в серии, когда указали одну метку строки (один индекс).
Результат:
Теперь у нас есть Series, где старые имена столбцов теперь являются индексными метками.
Результат:
Результат:
.loc включает в себя последнее значение из обозначения среза
Обратите внимание, что строка с пометкой 139 в примере без шага была выведена. В других контейнерах данных, таких как списки Python, последнее значение исключается.
Выведем тот же самый результат, только будем выводить каждый второй элемент из среза:
Результат:
Пример скрипта Python 3 для вывода 139 первых строк из Pandas DataFrame:
Результат:
Тот же самый пример, но выведем с шагом 25:
Результат выполнения выборки данных из Pandas DataFrame:
Полный код вывода данных из Pandas DataFrame:
Результат запроса к DataFrame:
Пример запроса на Python 3:
Результат:
Выбор строки или столбца может быть совершен любым из следующих способов:
Пример 1 «Выборка данных из Pandas DataFrame»:
Результат:
Выбор строк и столбцов через переменные
Результат:
Пример параметризации с slice:
Результат:
Код запроса:
Результат:
Используйте список целых чисел, чтобы выбрать несколько строк:
Результат:
Выберем две строки и два столбца:
Осуществим выборку строк и столбцов с помощью среза:
Выберем 1 значение из столбца и указанной колонки:
Результат:
Доступ к строкам и колонкам по индексу возможен несколькими способами:



Как выбрать строки из Pandas DataFrame по условию
Собираем тестовый набор данных для иллюстрации работы выборки по условию
| Color | Shape | Price |
| Green | Rectangle | 10 |
| Green | Rectangle | 15 |
| Green | Square | 5 |
| Blue | Rectangle | 5 |
| Blue | Square | 10 |
| Red | Square | 15 |
| Red | Square | 15 |
| Red | Rectangle | 5 |
Пишем скрипт:
Синтаксис выборки строк из Pandas DataFrame по условию
Вы можете использовать следующую логику для выбора строк в Pandas DataFrame по условию:
А вот полный код Python для нашего примера:
Результат:
Выберем строки, где цена равна или больше 10
Чтобы получить все строки, где цена равна или больше 10, Вам нужно применить следующее условие:
Результат:
Выберем строки, в которых цвет зеленый, а форма — прямоугольник
Теперь цель состоит в том, чтобы выбрать строки на основе двух условий:
Мы будем использовать символ & для применения нескольких условий. В нашем примере код будет выглядеть так:
Полный код примера Python для выборки Pandas DataFrame:
Результат:
Выберем строки, где цвет зеленый ИЛИ форма прямоугольная
Для достижения этой цели будем использовать символ | следующим образом:
Полный код Python 3:
Выберем строки, где цена не равна 15
Полный код Pandas DF на питоне:
Результат работы скрипта Python:
Data Wrangling with Pandas
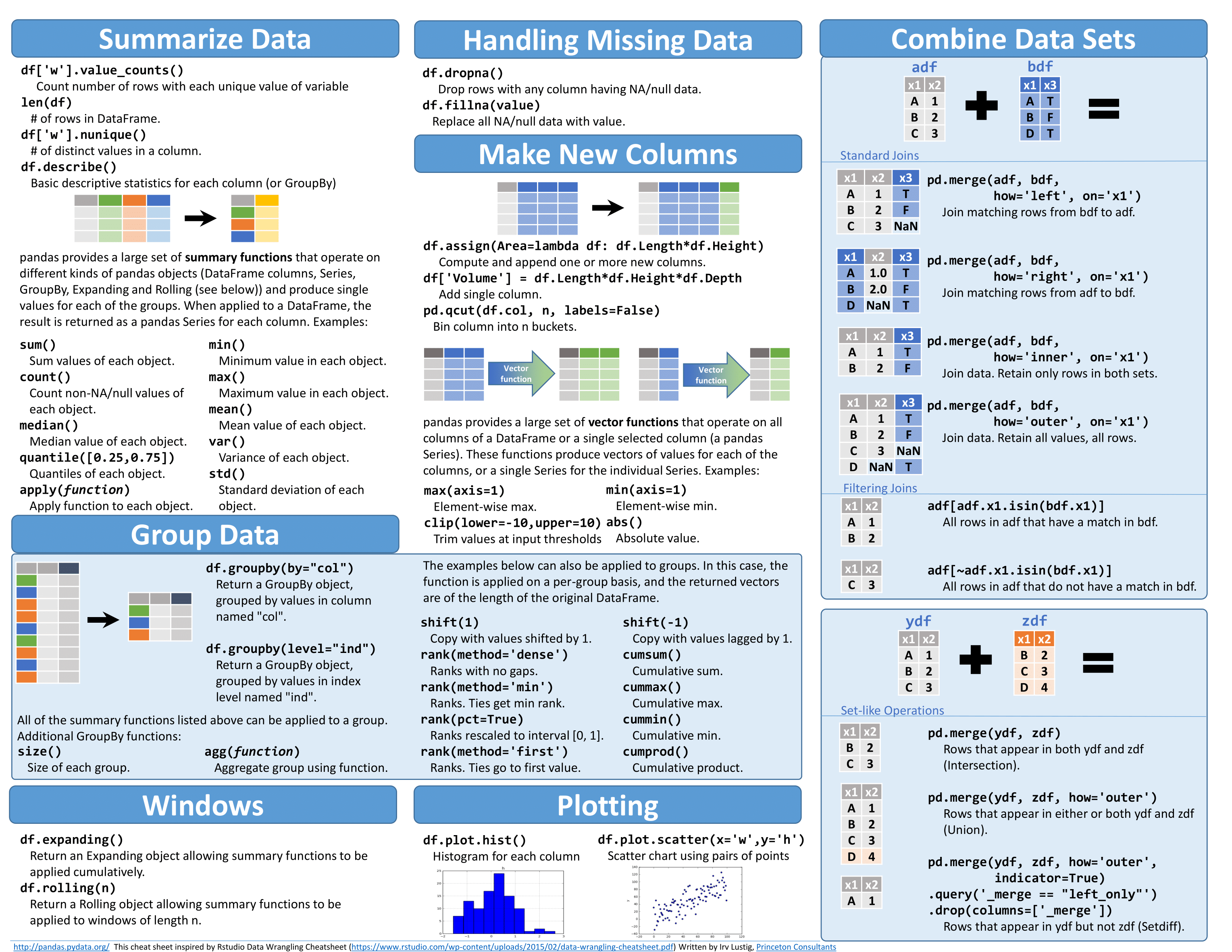
Обработка данных с помощью Pandas ( Data Wrangling )
Обработка данных является одной из важнейших задач в data science и анализе данных, которая включает такие операции, как:
Concatenation DataFrame
Joining DataFrame
Merging DataFrame
Pivot & Melt (Unpivot) DataFrame
GroupBy Операции
Применение Lambda функции в DataFrame
10 трюков Python Pandas, которые сделают вашу работу более эффективной
Pandas — это широко используемый пакет Python для структурированных данных.
read_csv
Все знают эту команду. Но данные, которые вы пытаетесь прочитать, велики, попробуйте добавить этот аргумент: nrows = 5, чтобы загружать только часть данных. Тогда вы можете избежать ошибки, выбрав неправильный разделитель (он не всегда может быть разделен запятой).
Затем вы можете извлечь список столбцов, используя df.columns.tolist() для извлечения всех столбцов, а затем добавить аргумент usecols = [‘c1’, ‘c2’,…], чтобы загрузить нужные вам столбцы.
Кроме того, если вы знаете типы данных нескольких определенных столбцов, вы можете добавить аргумент dtype = <‘c1’: str, ‘c2’: int,…>, чтобы он загружался быстрее.
Еще одно преимущество этого аргумента в том, что если у вас есть столбец, который содержит как строки, так и числа, рекомендуется объявить его тип строковым, чтобы не возникало ошибок при попытке объединить таблицы, используя этот столбец в качестве ключа.
select_dtypes
Если предварительная обработка данных должна выполняться в Python, эта команда сэкономит вам время. После чтения в таблице типами данных по-умолчанию для каждого столбца могут быть bool, int64, float64, object, category, timedelta64 или datetime64. Вы можете сначала проверить распределение по
чтобы узнать все возможные типы данных вашего DataFrame
выбрать sub-dataframe только с числовыми характеристиками.
Это важная команда, если вы еще не слышали о ней. Если вы выполните следующие команды:
Вы обнаружите, что df1 изменен. Это потому, что df2 = df1 не делает копию df1 и присваивает ее df2, но устанавливает указатель, указывающий на df1. Таким образом, любые изменения в df2 приведут к изменениям в df1. Чтобы это исправить, вы можете сделать либо
Это классная команда для простого преобразования данных. Сначала вы определяете словарь, в котором «ключами» являются старые значения, а «значениями» являются новые значения.
Некоторые примеры:
True, False до 1, 0 (для моделирования); определение уровней; определяемые пользователем лексические кодировки.
apply or not apply?
Если мы хотим создать новый столбец с несколькими другими столбцами в качестве входных данных, функция apply иногда будет весьма полезна.
В приведенных выше кодах мы определяем функцию с двумя входными переменными и используем функцию apply, чтобы применить ее к столбцам ‘c1’ и ‘c2’.
но вы найдете это намного медленнее, чем эта команда:
Вывод : не используйте apply, если вы можете выполнить ту же работу с другими встроенными функциями (они часто быстрее). Например, если вы хотите округлить колонку «с» целыми числами, делать
Вместо использования функции применяются:
value counts
Это команда для проверки распределения значений. Например, если вы хотите проверить возможные значения и частоту для каждого отдельного значения в столбце «c», вы можете сделать
Есть несколько полезных трюков / аргументов:
number of missing values — количество пустых значений
При построении моделей может потребоваться исключить строку со слишком большим количеством пропущенных значений / строки со всеми пропущенными значениями. Вы можете использовать .isnull() и .sum() для подсчета количества пропущенных значений в указанных столбцах.
выбрать строки с конкретными идентификаторами (select rows with specific IDs)
В SQL мы можем сделать это, используя SELECT * FROM … WHERE ID in (‘A001’, ‘C022’, …), чтобы получить записи с конкретными идентификаторами. Если вы хотите сделать то же самое с Pandas, вы можете сделать
Процентильные группы (Percentile groups)
У вас есть числовой столбец, и вы хотите классифицировать значения в этом столбце по группам, скажем, верхние 5% в группе 1, 5–20% в группе 2, 20–50% в группе 3, нижние 50% в группе 4 Конечно, вы можете сделать это с помощью pandas.cut, но я бы хотел предоставить здесь другую опцию:
который быстро запускается (не применяется функция apply).
to_csv
Опять же, это команда, которую все будут использовать. Я хотел бы указать на две уловки здесь. Первый
Вы можете использовать эту команду, чтобы распечатать первые пять строк того, что будет записано в файл точно.