Модели знаний




![]()
![]()
Знания – это выявленные закономерности предметной области (принципы, связи, законы), позволяющие решать задачи в этой области. Для хранения знаний используются базы знаний.
Знания могут быть классифицированы по следующим категориям:
— поверхностные – знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области;
— глубинные – абстракции, аналогии, схемы, отражающие структуру и процессы в предметной области.
Существуют десятки моделей представления знаний для различных предметных областей. Большинство из них может быть сведено к следующим классам:
— формальные логические модели.
Продукционная модель, или модель, основанная на правилах, позволяет представить знания в виде предложений типа: Если (условие), то (действие).
Под условием понимается некоторое предложение-образец, по которому осуществляется поиск в базе знаний, а под действием — действия, выполняемые при успешном исходе поиска (они могут быть промежуточными, выступающими далее как условия, и терминальными или целевыми, завершающими работу системы).
При использовании продукционной модели база знаний состоит из набора правил. Программа, управляющая перебором правил, называется машиной вывода. Чаще всего вывод бывает прямой (от данных к поиску цели) или обратный (от цели для ее подтверждения — к данным). Данные — это исходные факты, на основании которых запускается машина вывода — программа, перебирающая правила из базы.
Продукционная модель чаще всего применяется в промышленных экспертных системах. Она привлекает разработчиков своей наглядностью, высокой модульностью, легкостью внесения дополнений и изменений и простотой механизма логического вывода.
Семантическая сеть — это ориентированный граф, вершины которого — понятия, а дуги — отношения между ними.
Понятиями обычно выступают абстрактные или конкретные объекты, а отношения — это связи типа: «это» («is»), «имеет частью» («has part»), «принадлежит», «любит». Характерной особенностью семантических сетей является обязательное наличие трех типов отношений:
— класс — элемент класса;
— пример элемента класса.
Выделяют несколько классификаций семантических сетей:
— по количеству типов отношений (однородные – с единственным типом отношений; неоднородные – с различными типами отношений);
— по типам отношений (бинарные – в которых отношения связывают два объекта; n-арные – отношения, связывающие более двух понятий).
Наиболее часто в семантических сетях используются следующие отношения:
— связи типа “часть-целое”;
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, соответствующей поставленному вопросу.
Основное преимущество этой модели – в соответствии современным представлениям об организации долговременной памяти человека. Недостаток модели – сложность поиска вывода на семантической сети.
Под фреймом понимается абстрактный образ или ситуация. В психологии и философии известно понятие абстрактного образа. Например, слово «комната» вызывает у слушающих образ комнаты: «жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, площадью 6-20 м 2 «. Из этого описания ничего нельзя убрать (например, убрав окна, мы получим уже чулан, а не комнату), но в нем есть «дырки», или «слоты», — это незаполненные значения некоторых атрибутов — количество окон, цвет стен, высота потолка, покрытие пола и др.
В теории фреймов такой образ называется фреймом. Фреймом называется также и формализованная модель для отображения образа.
Структуру фрейма можно представить так:
(имя 1-го слота: значение 1-го слота),
(имя 2-го слота: значение 2-го слота),
(имя N-ro слота: значение N-ro слота).

Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о мире через:
— фреймы-структуры, для обозначения объектов и понятий (заем, залог, вексель);
— фреймы-роли (менеджер, кассир, клиент);
— фреймы-сценарии (банкротство, собрание акционеров, празднование именин);
— фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Важнейшим свойством теории фреймов является заимствованное из теории семантических сетей наследование свойств.
Основным преимуществом фреймов как модели представления знаний является способность отражать концептуальную основу организации памяти человека, а также ее гибкость и наглядность.
В представлении знаний выделяют формальные логические модели, основанные на классическом исчислении предикатов I порядка, когда предметная область или задача описывается в виде набора аксиом. Эта логическая модель применима в основном в исследовательских «игрушечных» системах, так как предъявляет очень высокие требования и ограничения к предметной области. В промышленных же экспертных системах используются различные ее модификации и расширения.
Модели знаний – продукционная, фреймовая, семантических сетей – обладают практически равными возможностями представления знаний. Дополнительно каждая модель знаний обладает следующими свойствами:
— продукционная модель позволяет легко расширять и усложнять множество правил вывода;
— фреймовая модель позволяет усилить вычислительные аспекты обработки знаний за счет расширения множества присоединенных процедур;
— модель семантических сетей позволяет расширять список отношений между вершинами и дугами сети, приближая выразительные возможности сети к уровню естественного языка.
9.4. Экспертная система «ДА» фирмы «Контекст»
Что обеспечивает ДА-система?
1. Обработка данных:
— создание Словаря переменных;
— ввод данных из документов, лабораторных журналов и т.д.;
— ввод данных, записанных на гибких дисках в форматах других систем;
— обмен данными с другими системами;
— добавление новых данных в процессе анализа;
— корректировка введенных данных.
— построение таблиц распределений;
— поиск и анализ правил (детерминаций);
— построение таблиц правил (детерминаций);
— конструирование вторичных переменных;
— анализ в произвольных контекстах;
— оценивание статистических ошибок;
— расчеты с учетом весовых показателей.
— оформление результатов в виде отчетов;
— перенос таблиц, графиков, других материалов и результатов анализа в Word, WordPad, Excel.
Применение ДА-системы дает наилучший результат:
— если Вас интересует поиск и анализ правил, объясняющих то или иное явление;
— если при этом Вам приходится конструировать новые признаки из уже имеющихся, чтобы более четко ставить и решать интересующие Вас задачи;
— если Вам необходимо вести анализ в разнообразных контекстах и в процессе анализа быстро переходить из одного контекста в другой;
— при обработке и анализе неколичественных (качественных) данных;
— при совместном анализе количественных и неколичественных данных;
— когда не выполнены (или под вопросом) условия применимости классических статистических методов анализа количественных данных.
В области маркетинговой деятельности ДА-система может быть использована для:
— планирования отношений с клиентами;
— планирования торговой политики и товарооборота;
— планирования загрузки складских помещений;
— планирования использования торговых площадей;
— регулирования занятости персонала;
— планирования рекламных кампаний;
— работы по созданию необходимого имиджа фирмы.
ДА-система может применяться для обработки данных, которые представляют деятельность фирмы и ее филиалов, отношения с поставщиками и клиентами, а также результаты обследований потенциальных поставщиков и клиентов. Это клиентские счета, накладные, сводки о результатах работы фирмы за день, неделю, месяц, данные опросов потенциальных поставщиков и клиентов, данные маркетинговых исследований по группам производителей товаров и т.д. С помощью ДА-системы, обрабатывая внутренние документы фирмы, а также данные маркетинговых опросов клиентов, производителей и поставщиков можно оперативно получать следующие типы результатов
Признаки-аутсайдеры и признаки-форварды, определяющие привлекательность (непривлекательность) товаров и услуг среди различных групп клиентов.
Применение ДА-системы эффективно для решения следующего круга задач:
— динамика выручки (когда, в какие месяцы, сезоны, годы, дни выручка наибольшая либо наименьшая и почему);
— ценовая политика (как влияет на суммарную выручку ценовая политика фирмы);
— объемы партий товара (как зависит суммарная выручка от ориентация на мелко, средне-, и крупнооптовую торговлю);
— товарооборот, его влияние на суммарную выручку;
— какие товары и услуги приносят наибольшую (наименьшую) выручку;
— какие товары и услуги дают наибольший (наименьший) вклад в товарооборот;
— какие клиенты дают наибольшую выручку и по каким признакам они выделяются из общего состава клиентов;
— по каким территориальным единицам выручка наибольшая, и по каким признакам эти территориальные единицы выделяются на фоне других;
— деловая активность при разных объемах выручки;
— оценить, что выгоднее: мелкооптовые, среднеоптовые или крупнооптовые сделки;
— какие товары показали себя наиболее выгодными в розничгной, мелкооптовой, среднеоптовой и крупнооптовой торговле;
— какие клиенты показали себя наиболее выгодными в розничной, мелкооптовой, среднеоптовой и крупнооптовой торговле.
— влияние рекламы, выставок и других мероприятий на величину выручки и товарооборота;
— учет клиентов по видам их деятельности (для более эффективной работы с клиентами);
— отслеживание каналов, по которым клиенты получают информацию о фирме (для более целенаправленной работы с рекламой и эффективного формирования благоприятного имиджа фирмы).
После определения словаря данных выполняется ввод исходных данных, которые необходимо подвергнуть анализу. Для всех групп изделий вводим их цены, реализованное количество продукции, производительность и все остальные значения.
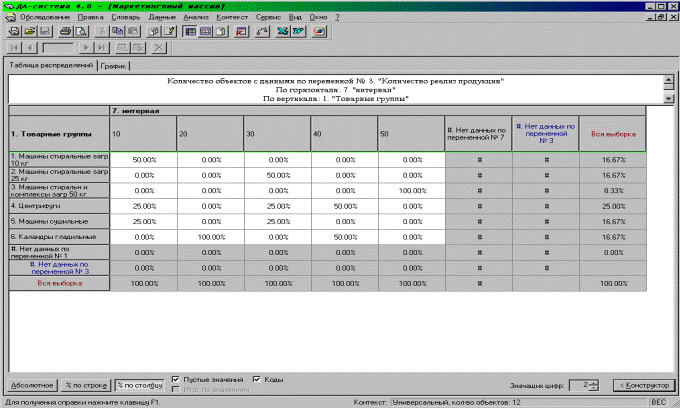
После того, как введены значения анализируемых переменных, определяется весовая переменная (в нашем случае это цена изделия) и выполняется анализ количественных значений с помощью режима «Таблица распределений». В этом режиме выполняем анализ зависимости реализованной продукции по каждой товарной группе и по определённым диапазонам (переменная «Диапазон», которая принимает список значений <10, 20, 30, 40, 50>от её цены, производительности и затрат на эксплуатацию. Система «ДА» выполняет обработку данных, причём можно указать вид статистики, которую необходимо вычислить при этом.
После того, как введены значения анализируемых переменных, определяется весовая переменная (в нашем случае это цена изделия) и выполняется анализ количественных значений с помощью режима «Таблица распределений». В этом режиме выполняем анализ зависимости реализованной продукции по каждой товарной группе и по определённым диапазонам (переменная «Диапазон», которая принимает список значений <10, 20, 30, 40, 50>от её цены, производительности и затрат на эксплуатацию. Система «ДА» выполняет обработку данных, причём можно указать вид статистики, которую необходимо вычислить при этом.
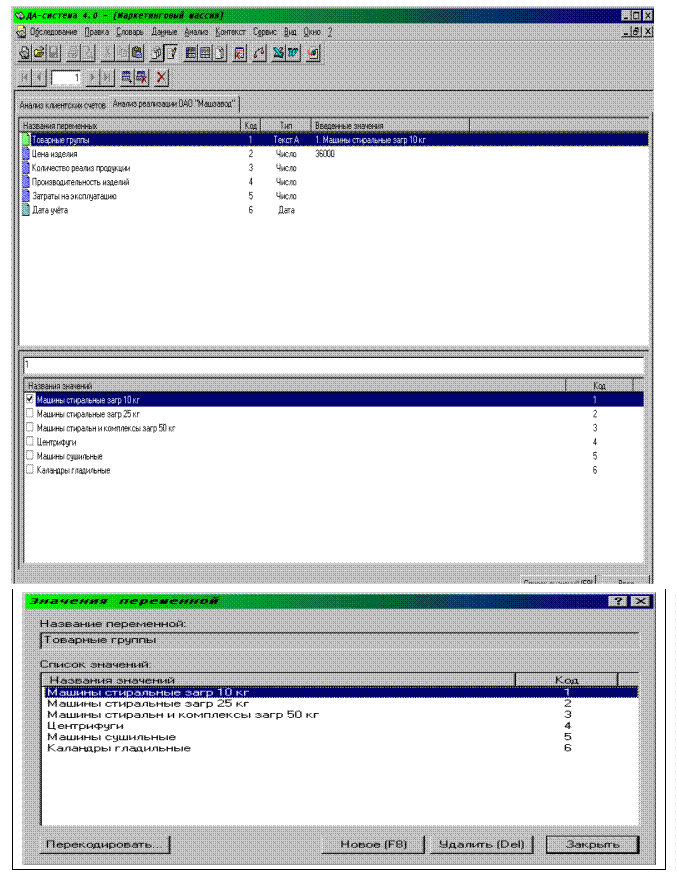
Система включает конструктор отчётов для построения таблиц распределений, а в нём имеется соответствующая кнопка, именуемая «Статистика». Значения в таблице распределений могут быть представлены в виде количества значений, попадаемых в исследуемый интервал, или в % выражении. По таблице распределений система «ДА» строит диаграмму.
|
|
По представленной диаграмме видно, что наибольшей популярностью среди потребителей продукции ОАО «Вяземский машиностроительный завод» пользуются стиральные машины загрузочной массой 10 кг и 25 кг, хотя именно это оборудование требует больших затрат при эксплуатации, чем другие виды, но по своим функциональным возможностям оно наиболее необходимо всем потребителям, поэтому конструкторам, технологам и другим специалистам ОАО «Вяземский машиностроительный завод» имеет смысл в первую очередь работать над технологическим совершенствованием стиральных машин, снижением их себестоимости, улучшением их качества, дизайна, увеличения сроков службы прачечного оборудования за счёт применения новейших материалов, лаков, красок и более долговечных механических комплектующих изделий.
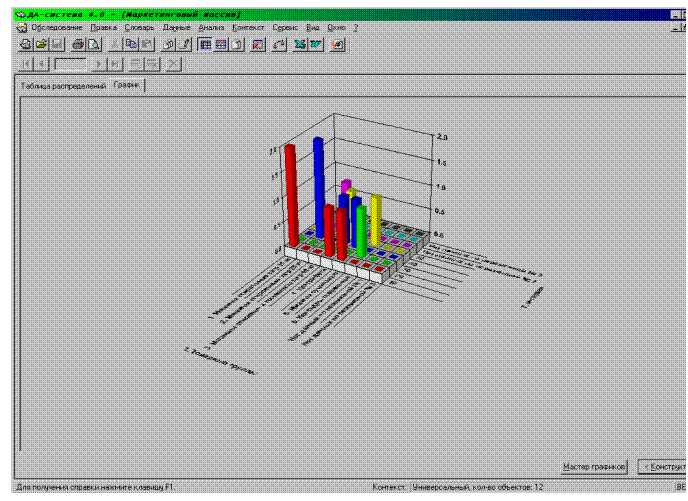
Рис. 9.5. Диаграмма результатов исследования
Пример модели знаний о требованиях
Зачем нужна модель знаний
За уже несколько десятков лет существования индустрии информационных технологий создана значительная теоретическая база. Множеством ассоциаций и организаций разработаны своды знаний и методологии в различных областях.
Вот некоторые из них:
Эти документы не сложно найти на просторах интернета, однако, чтобы изучить их потребуется значительное количество времени. Сотни страниц сухого текста: определения, классификации, зачастую, отсутствует русский перевод — все это препятствует усвоению ценного материала, изложенного в источниках. Для систематизации и использования в работе такого объема информации требуется представление знаний в более удобном для восприятия и сжатом виде.
На текущий момент существует множество способов представления знаний: семантические сети, фреймы, языки и нотации и др. (Википедия).
Один из этих способов можно было бы использовать для конспектирования изученного материала в виде модели знаний с целью:
извлечь существенные понятия о концепциях, описанных в своде знаний
получить структурированное системное представление о связях между концепциями
обеспечить быстрый доступ к изученной информации, чтобы в дальнейшем быстро и удобно использовать ее в работе.
Что должна включать модель знаний
Cводы знаний и методологии инженерии требований и системного анализа описывают процессы, техники и подходы, применяемые в проектировании и создании информационных систем.
ключевые принципы, на которых базируются активности
ключевые свойства и аспекты активностей
определения и факты, связанные с процессами
Кроме того, между концептами системы важно отразить связи:
Archimate для представления знаний
Для практической реализации модели потребуется простой и удобный в использовании инструмент, который смог бы визуально (в графической форме) представить выявленные концепции, определения и связи.
Далее описана попытка представить методологию инженерии требований сообщества IREB в виде модели знаний в нотации ArchiMate.
Нотация ArchiMate предназначена для описания архитектуры информационных систем, имеет собственное бесплатное кросс-платформенное программное обеспечение и описывает широкий спектр аспектов информационных систем на различных слоях (уровнях абстракции) системы: стратегия, бизнес, приложения, технологии, производство, реализация и переходы, мотивация. Позволяет описать пассивную и активную структуру системы, ее поведение, различные типы связей между элементами.
Некоторые примеры описания модели знаний элементами нотации Archimate:
1. Активности, группы активностей и связи между ними
С помощью элемента слоя реализации «Пакет работ» (Work Package) можно отразить активности и техники используемые в процессах.
Связь «Композиция» (Composition) отражает то, что одна активность является частью более крупной группы активностей. Связь «Триггер» (Triggering) позволяет отобразить последовательность выполнения активностей.
Например, процесс организации работы с требованиями включает в себя активность по управлению жизненным циклом, которая состоит из последовательности этапов: Определение моделей жизненного цикла → Контроль переходов и т.д.

Элемент «Ценность» (Value) позволяет указать ценность или преимущества использования активности в общем процессе и ответить на вопрос модели «Зачем?».
2. Результаты активностей
Результаты активностей описываются элементом «Поставляемые результаты» (Deliverable).
Например, результатом активности по выявлению заинтересованных сторон являются списки заинтересованных сторон, которые поступают на вход активности по выявлению требований. Кроме того, активность по выявлению требований использует информацию о потребности к изменениям.
3. Свойства активностей
Цель описания: отразить основные принципы, свойства, ограничения и аспекты активностей, а так же определения, связанные с ними.
Используя элементы слоя мотивации ArchiMate можно описать ключевые свойства, аспекты, определения и ограничения, связанные с активностями и поставляемыми результатами системы.
С помощью элемента «Требование» (Requirement) описываются свойства или аспекты, связанные с активностью или поставляемыми результатами процесса. Элемент «Принцип» (Principle) позволяет описать ключевые принципы, связанные с активностью. Элемент «Понятие» (Meaning) можно использовать для описания ключевых понятий и определений.
С помощью связи «Ассоциация» (Association) описанные артефакты связываются с активностями и поставляемыми результатами.
Например, процесс инженерии требований имеет «Ключевые аспекты процесса RE» (декомпозируются в отдельном представлении) и основывается на девяти ключевых принципах. «Принцип 4. Контекст» связан с концептом «Контекст» (само определение дано в описании элемента).
Факторы, каким то образом ограничивающие пространство свойств или оказывающие влияние на свойство отражаются элементом «Ограничение» (Constraint), а само влияние отражается связью «Влияние» (Influence).
4. Взаимосвязи между активностями и выполняющими их сущностями: роль или актор являются ответственными или выполняют некоторые активности
Элемент «Роль» (Business Role) позволяет отразить набор компетенций или зону ответственности, связанных с активностью. Элемент «Актор» (Business Actor) представляет бизнес-сущность, выполняющую активность. Это может быть как конкретное лицо, так и структурные единицы, например, подразделения.
С помощью связи «Назначение» (Assignment) устанавливается связь между соответствующим активным элементом и активностью, им выполняемой.
Например, «Заинтересованные стороны» формируют «Потребность в изменениях», запускающую процесс инженерии требований, который выполняет роль «Инженер по требованиям», обладающая некоторым набором компетенций (указаны в описании).
5. Структурные связи между сущностями. Обобщение и специализация
С помощью связи «Агрегация» (Aggregation) однотипные элементы могут быть объединены в группы, организованные в сложные иерархии. На схеме элементы могут отражаться как отдельные элементы, связанные между собой, так и располагаться в границах родительского элемента. Например, в группу ключевых аспектов процесса инженерии требований входит аспект «Требование и время», который, в свою очередь, включает аспект «Спецификация, ориентированная на риск».
С использованием связи «Композиция» (Composition) отображаются случаи, когда один элемент является неотъемлемой частью другого (не может существовать без него). Например, активность по обучению пользователей является частью процесса выбора CASE-инструмента.
Отразить связь между абстрактным концептом и его конкретными реализациям позволяет связь «Специализация» (Specialization). Например, к концепту «Модель» относятся модели системного контекста, которые в свою очередь могут быть реализованы как DFD-диаграммы или UML-варианты использования.
6. Что еще может Archi
К каждому элементу может быть составлено описание или дано текстовое уточнение.
В состав ArchiMate входит инструмент для просмотра всех связей выбранного элемента. Глубина связей может настраиваться.
В состав Archi входит плагин, который позволяет выгрузить модель в html-формат для размещения на сайте с минимальными доработками. В формате реализована навигация по модели: переходы от представления к представлению по щелчку на ссылку представления, отображение описания по выбранным элементам.
Заключение
Методология инженерии требований сообщества IREB описана моделью представления знаний в формате ArchiMate. Результат здесь:
в графической форме представить знания об инженерии требований
выделить основные концепции, связи между ними и зафиксировать описание ключевых определений
реализовать простой и удобный доступ к модели в интернете.
Какие остались вопросы:
для описания активностей и поставляемых результатов использованы элементы реализации, что ограничивает применение типов связей между элементами схемы; возможно было бы лучше использовать элементы для описания бизнес-процессов
возможность описания в одной модели нескольких сводов и методологий; например, в описанной методологии не выделен отдельно процесс анализа требований, что ограничивает возможность совместить эту модель с областью знаний о системном анализе в целом.
Модели представления знаний
Физико-математические науки
Похожие материалы
Информация, с которой имеют дело ЭВМ, разделяется на процедурную и декларативную. Процедурная информация овеществлена в программах, которые выполняются в процессе решения задач, декларативная — в данных с которыми эти программы работают. Стандартной формой представления информации в ЭВМ является машинное слово, состоящее из определенного для данного типа ЭВМ числа двоичных разрядов — битов. Однако в ряде случаев машинные слова разбиваются на группы по восемь двоичных разрядов которые называются байтами.
Параллельно с развитием структуры ЭВМ происходило развитие информационных структур для представления данных. Появились способы описания данных в виде векторов и матриц, возникли списочные структуры, иерархические структуры. В настоящее время в языках программирования высокого уровня используются абстрактные типы данных, структура которых задается программистом. Появление баз данных (БД) знаменовало собой еще один шаг на пути организации работы с декларативной информацией. В базах данных могут одновременно хранится большие обьемы информации, а специальные средства образующие систему управления базами данных (СУБД), позволяют эффективно манипулировать с данными, по необходимости извлекать их из базы данных и записывать их в нужном порядке в базу.
По мере развития исследований в области ИС возникла концепция знаний, которая объединила в себе многие черты процедурной и декларативной информации.
Итак, что же такое представление информации? В рамках этого направления решаются задачи, связанные с формализацией и представлением знаний в памяти интеллектуальной системы (ИС). Для этого разрабатываются специальные модели представления знаний, выделяются различные типы знаний. Изучаются источники, из которых ИС может черпать знания, и создаются процедуры и приемы с помощью которых возможно приобретение знаний для ИС. Проблема представления знаний для ИС чрезвычайно актуальна, так как ИС — это система, функционирование которой опирается на знания о предметной области, которые хранятся в её памяти.
Представление знаний — это одно из направлений в исследованиях по искусственному интеллекту. Другие направления это — манипулирование знаниями, общение, восприятие, обучение и поведение.
Особенности знаний
Существует ряд особенностей, присущих различным формам представления знаний в ЭВМ.
Внутренняя интерпретируемость
Каждая информационная единица должна иметь уникальное имя, по которому ИС находит её, а также отвечает на запросы, в которых это имя упомянуто. Когда данные, хранящиеся в памяти, были лишены имен, то отсутствовала возможность их идентификации системой. Данные могла идентифицировать лишь программа, извлекающая их из памяти по указанию программиста, написавшего программу. Что скрывается за тем или иным двоичным кодом машинного слова, системе было неизвестно.
Структурированность
Информационные единицы должны были обладать гибкой структурой. Для них должен выполняться «принцип матрешки», т.е. рекурсивная вложенность одних информационных единиц в другие. Каждая информационная единица может быть включена в состав любой другой, и из каждой единицы можно выделить некоторые её составляющие. Другими словами должна существовать возможность произвольного установления между отдельными информационными единицами отношений типа «часть — целое»,» род — вид» или «элемент — класс».
Связность
В информационной базе между информационными единицами должна быть предусмотрена возможность установления связей различного типа. Прежде всего эти связи могут характеризовать отношения между информационными единицами. Например: две или более информационные единицы могут быть связаны отношением «одновременно», две информационные единицы — отношением «причина — следствие» или отношением «быть рядом». Приведенные отношения характеризуют декларативные знания. Если между двумя информационными единицами установлено отношение «аргумент — функция», то он характеризует процедурное знание, связанное с вычислением определенных функций. Существуют — отношения структуризации, функциональные отношения, каузальные отношения и семантические отношения. С помощью первых задаются иерархии информационных единиц, вторые несут процедурную информацию, позволяющие вычислять (находить) одни информационные единицы через другие, третьи задают причинно следственные связи, четвертые соответствуют всем остальным отношениям.
Перечисленные три особенности знаний позволяют ввести общую модель представления знаний, которую можно назвать семантической сетью, представляющей собой иерархическую сеть в вершинах которой находятся информационные единицы.
Семантическая метрика
На множестве информационных единиц в некоторых случаях полезно задавать отношение, характеризующее информационную близость информационных единиц, т.е. силу ассоциативной связи между информационными единицами. Его можно было бы назвать отношением релевантности для информационных единиц. Такое отношение дает возможность выделять в информационной базе некоторые типовые ситуации (например «покупка», «регулирование движения»). Отношение релевантности при работе с информационными единицами позволяет находить знания близкие к уже найденным.
Активность
С момента появления ЭВМ и разделения используемых в ней информационных единиц на данные и команды создалась ситуация, при которой данные пассивны, а команды активны. Все процессы, протекающие в ЭВМ, инициируются командами, а данные используются этими командами лишь в случае необходимости. Для ИС эта ситуация неприемлема. Как и у человека, в ИС актуализации тех или иных действий способствуют знания, имеющиеся в системе. Таким образом, выполнение программ в ИС должно инициироваться текущим состоянием информационной базы. Появление в базе фактов или описание событий, установление связей может стать источником активности системы.
Перечисленные пять особенностей информационных единиц определяют ту грань, за которой данные превращаются в знания, а базы данных перерастают в базы знаний (БЗ). Совокупность средств, обеспечивающих работу со знаниями, образуют систему управления базой знаний (СУБЗ). В настоящее время не существует баз знаний, в которых в полной мере были бы реализованы перечисленные выше особенности [1].
Модели представления знаний
Во многих случаях для принятия решений в той или иной области человеческой деятельности неизвестен алгоритм решения, т.е. отсутствует четкая последовательность действий, заведомо приводящих к необходимому результату. Например:
При принятии решения в таких случаях необходимо иметь некоторую сумму знаний о самой этой области. Например: при выборе наилучшего хода в конкретной шахматной позиции необходимы знания о правилах игры, силе шахматных фигур, стратегии и тактике и многое другое. Под знаниями понимается то, что стало известно после изучения. Совокупность знаний, нужных для принятия решений, принято называть предметной областью или знаниями о предметной области.
В любой предметной области есть свои понятия и связи между ними, своя терминология, свои законы, связывающие между собой объекты данных предметной области, свои процессы и события. Кроме того, каждая предметная область имеет свои методы решения задач.
Решая задачи такого вида на ЭВМ используют ИС, ядром которых являются базы знаний, содержащие основные характеристики предметных областей [2].
При построении баз знаний традиционные языки, основанные на численном представлении данных, являются неэффективными. Для этого используются специальные языки представления знаний, основанные на символьном представлении данных. Они делятся на типы по формальным моделям представления знаний. Различные авторы по-разному эти модели классифицируют. Основные модели знаний представлены на рисунке 1.

Рисунок 1. Основные модели знаний
Продукционная модель знаний
Продукционные модели можно считать наиболее распространенными моделями представления знаний. Продукционная модель — это модель, основанная на правилах, позволяющая представить знание в виде предложений типа:
«ЕСЛИ условие, ТО действие»
Продукционная модель обладает тем недостатком, что при накоплении достаточно большого числа (порядка нескольких сотен) продукций они начинают противоречить друг другу.
Системы обработки знаний, использующие продукционную модель получили название «продукционных систем». В состав экспертных систем продукционного типа входят база правил (знаний), рабочая память и интерпретатор правил (решатель), реализующий определенный механизм логического вывода. Любое продукционное правило, содержащееся в базе знаний, состоит из двух частей: антецендента и консеквента. Антецедент представляет собой посылку правила (условную часть) и состоит из элементарных предложений, соединенных логическими связками «и», «или». Консеквент (заключение) включает одно или несколько предложений, которые выражают либо некоторый факт, либо указание на определенное действие, подлежащее исполнению. Продукционные правила принято записывать в виде антецедент-консеквент.
Примеры продукционных правил:
ЕСЛИ «двигатель не заводится» И «стартер двигателя не работает»
ТО «неполадки в системе электропитания стартера»
Основные достоинства систем, основанных на продукционных моделях:
К недостаткам таких систем можно отнести следующее:
При разработке небольших систем (десятки правил) проявляются в основном положительные стороны продукционных моделей знаний, однако при увеличении объёма знаний более заметными становятся слабые стороны.
Логическая модель знаний
Основная идея при построении логических моделей знаний заключается в следующем — вся информация, необходимая для решения прикладных задач, рассматривается как совокупность фактов и утверждений, которые представляются как формулы в некоторой логике. Знания отображаются совокупностью таких формул, а получение новых знаний сводится к реализации процедур логического вывода.
Основные достоинства логических моделей знаний:
В логических моделях знаний слова, описывающие сущности предметной области, называются термами (константы, переменные, функции), а слова, описывающие отношения сущностей — предикатами.
Предикат — логическая N-арная пропозициональная функция, определенная для предметной области и принимающая значения либо истинности, либо ложности. Пропозициональной называется функция, которая ставит в соответствие объектам из области определения одно из истинностных значений («истина», «ложь»). Предикат принимает значения «истина» или «ложь» в зависимости от значений входящих в него термов [3].
Способ описания предметной области, используемый в логических моделях знаний, приводит к потере некоторых нюансов, свойственных естественному восприятию человека, и поэтому снижает описательную возможность таких моделей.
Сложности возникают при описании «многосортных» миров, когда объекты не являются однородными. Так, высказывания:
имеют одно и то же значение «истина», но разный смысл. С целью преодоления сложностей и расширения описательных возможностей логических моделей знаний разрабатываются псевдофизические логики, т.е. логики, оперирующие с нечеткостями, обеспечивающие индуктивные (от частного к общему), дедуктивные (от общего к частному) и традуктивные (на одном уровне общности) выводы. Такие расширенные модели, объединяющие возможности логического и лингвистического подходов, принято называть логико-лингвистическими моделями предметной области.
Сетевая модель знаний
Однозначное определение семантической сети (сетевой модели знаний) в настоящее время отсутствует. В инженерии знаний под ней подразумевается граф, отображающий смысл целостного образа. Узлы графа соответствуют понятиям и объектам, а дуги — отношениям между объектами.
Семантическая сеть как модель наиболее часто используется для представления декларативных знаний. С помощью этой модели реализуются такие свойства системы знаний, как интерпретируемость и связность. За счет этих свойств семантическая сеть позволяет снизить объем хранимых данных, обеспечивает вывод умозаключений по ассоциативным связям.
Одной из первых известных моделей, основанных на семантической сети, является TLC-модель (Teachaple Languge Comprehender — доступный механизм понимания языка), разработанная в 1968 году. Модель использовалась для представления семантических отношений между концептами (словами) с целью описания структуры долговременной памяти человека в психологии.
Как правило, различают экстенсиональные и интенсиональные семантические сети. Экстенсиональная семантическая сеть описывает конкретные отношения данной ситуации. Интенсиональная — имена классов объектов, а не индивидуальные имена объектов. Связи в интенсиональной сети отражают те отношения, которые всегда присущи объектам данного класса.
Фреймовая модель знаний
Фреймовая модель основана на концепции Марвина Мински (Marvin Minsky) — профессора Массачусетского технологического института, основателя лаборатории искусственного интеллекта, автора ряда фундаментальных работ. Фреймовая модель представляет собой систематизированную психологическую модель памяти человека и его сознания.
Фрейм — это минимально возможное описание сущности какого-либо события, ситуации, процесса или объекта. Существует и другое понимание фрейма — это ассоциативный список атрибутов. Понятие «минимально возможное» означает, что при дальнейшем упрощении описания теряется его полнота, и оно перестает определять ту единицу знаний, для которой было предназначено. Представление знаний с помощью фреймов понимается как один из способов представления знаний о ситуациях. Фрейм имеет имя (название) и состоит из слотов.
Слоты — это незаполненные (нулевые) позиции фрейма. Если у фрейма все слоты заполнены — это описание конкретной ситуации. В переводе с английского слово «фрейм» означает «рамка», а слово «слот» — «щель». В отличие от моделей других типов во фреймовых моделях фиксируется жесткая структура информационных единиц, которая называется протофреймом. В общем виде структура информационных единиц выглядит следующим образом:
Значением слота может быть практически что угодно (числа, математические соотношения, тексты на естественном языке или на языке программ, ссылки на другие слоты данного фрейма). Значением слота может выступать и отдельный фрейм, что является очень удобным для упорядочивания знаний по степени общности. Исключение из фрейма любого слота делает его неполным, а иногда и бессмысленным.
При конкретизации фрейма ему и слотам приписываются конкретные имена и происходит заполнение слотов. Таким образом из протофреймов получаются фреймы — экземпляры. Переход от исходного протофрейма к фрейму — экземпляру может быть многошаговым, за счет постепенного уточнения значений слотов [4].
Рассмотрим некоторый протофрейм:
Если в качестве значений слотов использовать конкретные данные, то получим фрейм — экземпляр:
Связи между фреймами задаются значениями специального слота с именем «связь».
Фреймы подразделяются на:
Заключение
Модели представления знаний — это одно из важнейших направлений исследований в области искусственного интеллекта. Без знаний искусственный интеллект не может существовать. Действительно, представьте себе человека, который абсолютно ничего не знает. Например, он не знает даже таких элементарных вещей как: для того, чтобы не было обезвоживания, необходимо периодически пить.
Таких примеров удастся привести еще много, но уже сейчас можно легко ответить на следующий вопрос: «Поведение такого человека может считаться разумным?». Конечно же, нет. Именно поэтому, при создании систем искусственного интеллекта особенное внимание уделяется моделям представления знаний.
На сегодняшний день разработано уже достаточное количество моделей. Каждая из них обладает своими плюсами и минусами, и поэтому для каждой конкретной задачи необходимо выбрать именно свою модель. От этого будет зависит не столько эффективность выполнения поставленной задачи, сколько возможность ее решения вообще.
Список литературы
Завершение формирования электронного архива по направлению «Науки о Земле и энергетика»
Создание электронного архива по направлению «Науки о Земле и энергетика»
Электронное периодическое издание зарегистрировано в Федеральной службе по надзору в сфере связи, информационных технологий и массовых коммуникаций (Роскомнадзор), свидетельство о регистрации СМИ — ЭЛ № ФС77-41429 от 23.07.2010 г.
Соучредители СМИ: Долганов А.А., Майоров Е.В.