Наиболее часто встраивающаяся варианта
В статистике модой называется величина признака (варианта), которая чаще всего встречается в данной совокупности.
Медианой в статистике называется варианта, которая находится в середине вариационного ряда. Медиана делит ряд пополам. Обозначают медиану символом.
Распределительные средние – мода и медиана, их сущность и способы исчисления.
Данные показатели относятся к группе распределительных средних и используются для формирования обобщающей характеристики величины варьирующего признака.
Мода  – это наиболее часто встречающееся значение варьирующего признака в вариационном ряду. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто, т.е. один из вариантов признака повторяется чаще, чем все другие. Для дискретного ряда (ряд, в котором значение варьирующего признака представлены отдельными числовыми показателями) модой является значение варьирующего признака обладающего наибольшей частотой. Для интервального ряда сначала определяется модальный интервал (т.е. содержащий моду), в случае интервального распределения с равными интервалами определяется по наибольшей частоте; с неравными интервалами – по наибольшей плотности, а определение моды требует проведения расчетов на основе следующих формул:
– это наиболее часто встречающееся значение варьирующего признака в вариационном ряду. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто, т.е. один из вариантов признака повторяется чаще, чем все другие. Для дискретного ряда (ряд, в котором значение варьирующего признака представлены отдельными числовыми показателями) модой является значение варьирующего признака обладающего наибольшей частотой. Для интервального ряда сначала определяется модальный интервал (т.е. содержащий моду), в случае интервального распределения с равными интервалами определяется по наибольшей частоте; с неравными интервалами – по наибольшей плотности, а определение моды требует проведения расчетов на основе следующих формул:

 — частота модального интервала;
— частота модального интервала;

Для определения медианы в дискретном ряду при наличии частот, сначала исчисляется полусумма частот, а затем определяется какое значение варьирующего признака ей соответствует. При исчислении медианы интервального ряда сначала определяются медианы интервалов, а затем определяется какое значение варьирующего признака соответствует данной частоте. Для определения величины медианы используется формула:

 — частота медианного интервала;
— частота медианного интервала;
Медианный интервал не обязательно совпадает с модальным.
Моду и медиану в интервальном ряду распределения можно определить графически. Мода определяется по гистограмме распределения. Для этого выбирается самый высокий прямоугольник, который в данном случае является модальным. Затем правую вершину модального прямоугольника соединяют с правым верхним углом предыдущего прямоугольника. А левую вершину модального прямоугольника – с левым верхним углом последующего прямоугольника. Далее из точки их пересечения опускают перпендикуляр на ось абсцисс.
7 базовых статистических понятий, необходимых дата-сайентисту
Даже если вы хорошо программируете, но слабо ориентируетесь в статистике, вероятность выжить в Data Science очень низка.


У статистики есть несколько различных определений. Одно из самых простых и точных — это «наука о сборе и классификации цифровых данных». А если добавить к нему немного о программировании и машинном обучении, то получится неплохое описание основ Data Science.

В самом деле, в Data Science трудно найти область, где нет статистики в том или ином виде. Она нужна для:
Мы выбрали семь базовых концепций, без которых в Data Science точно не обойтись. К счастью, они не слишком сложны.

С некоторых пор утверждает, что он data scientist. В предыдущих сезонах выдавал себя за математика, звукорежиссёра, радиоведущего, переводчика, писателя. Кандидат наук, но не точных. Бесстрашно пишет о Data Science и программировании на Python.
1. Меры описательной статистики
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, мерами центральной тенденции), — это:

Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, меры рассеяния. Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.
2. Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.
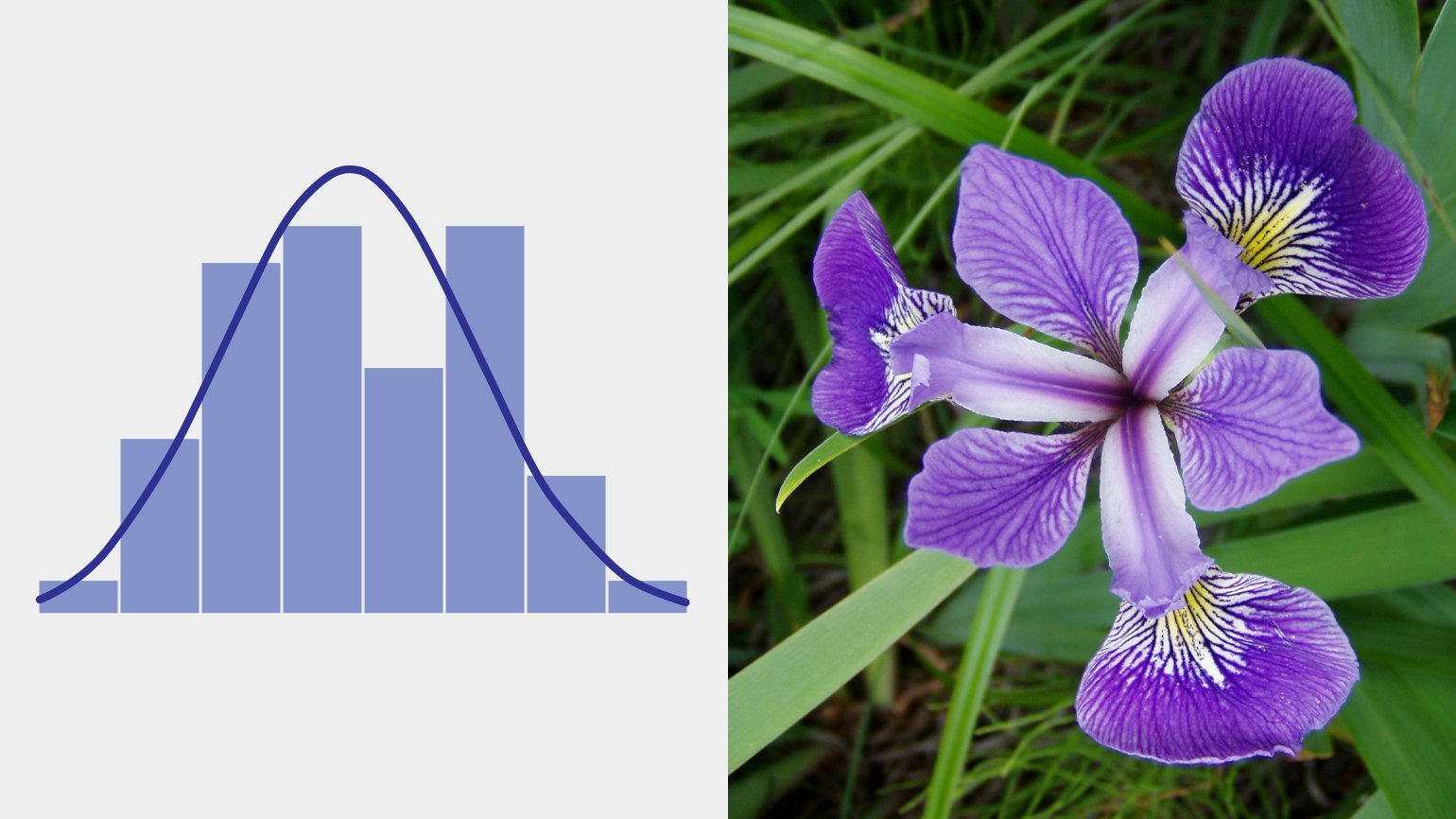
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.
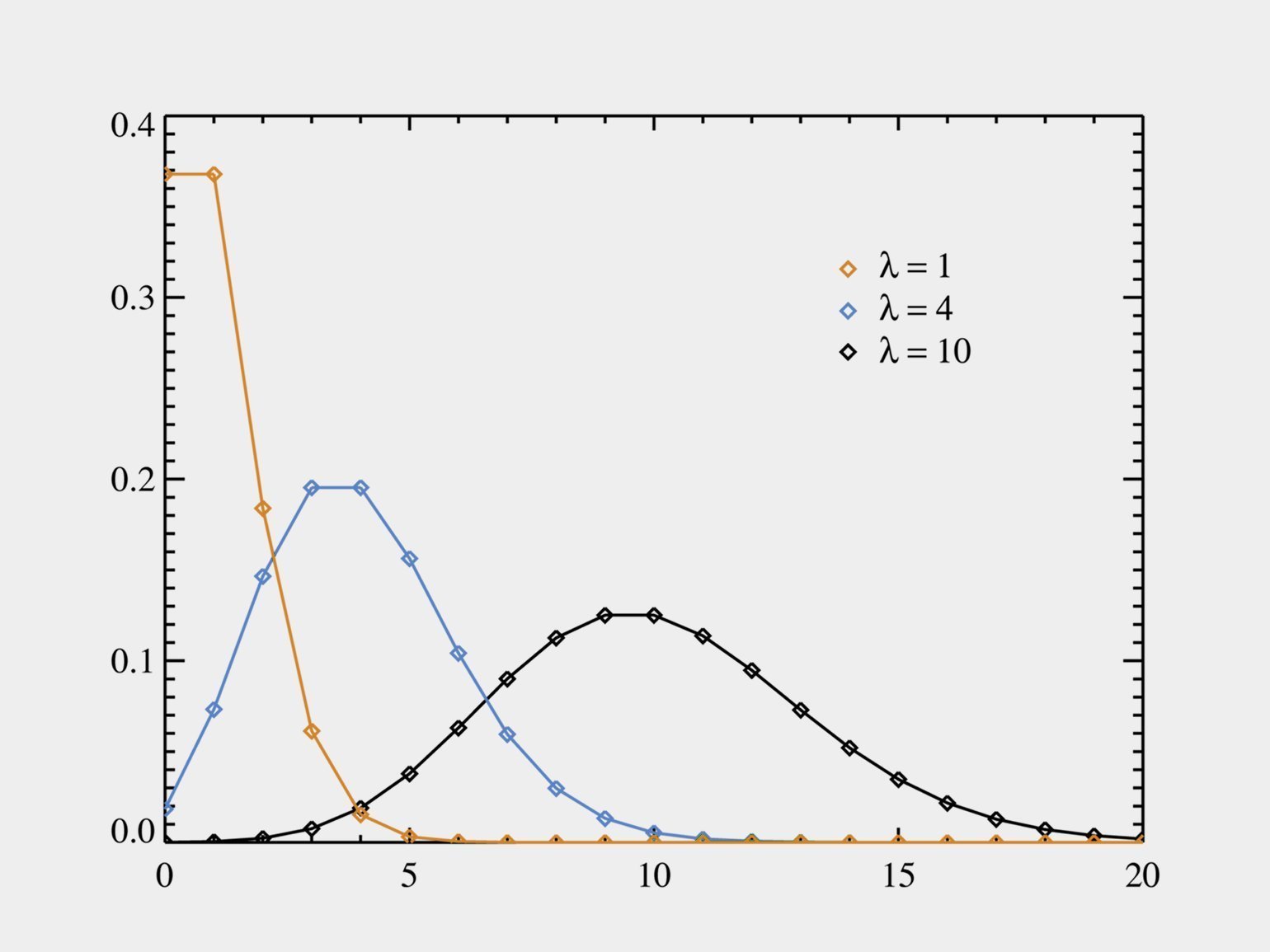
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и другие распределения, в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
3. Семплирование
Предположим, вам требуется решить важную задачу: выяснить среднюю ширину морды домашних котов нашей страны. Прямой способ, то есть измерение всех домашних питомцев, невозможен по ряду объективных причин. Придётся ограничиться выборкой — взять какое-то число животных, измерить морды именно им и сделать выводы по итогам только этих исследований.

Но тут сразу же возникают вопросы:
Семплирование — это группа статистических методов и приёмов, отвечающих на эти вопросы. С помощью семплирования мы формируем нашу выборку так, чтобы она наилучшим образом отражала свойства генеральной совокупности — то есть свойства всех котов страны.

Иными словами, вы не можете измерить N первых попавшихся котов и обобщить результат для остальных. Выборка должна хорошо «сидеть» во всей популяции кошек, чтобы можно было делать обоснованные выводы. Такую выборку называют релевантной.
Кстати, статистика и котики — близнецы-братья. После выхода одноимённой книги Владимира Савельева мы говорим «статистика», а подразумеваем «котики», и наоборот. И смело рекомендуем эту книгу всем, кто дочитал до этого места.
В Data Science методы семплирования применяются при разработке, подготовке и оценке датасетов, чтобы они одновременно и были упорядоченными, и соответствовали реальности.
4. Смещение
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».
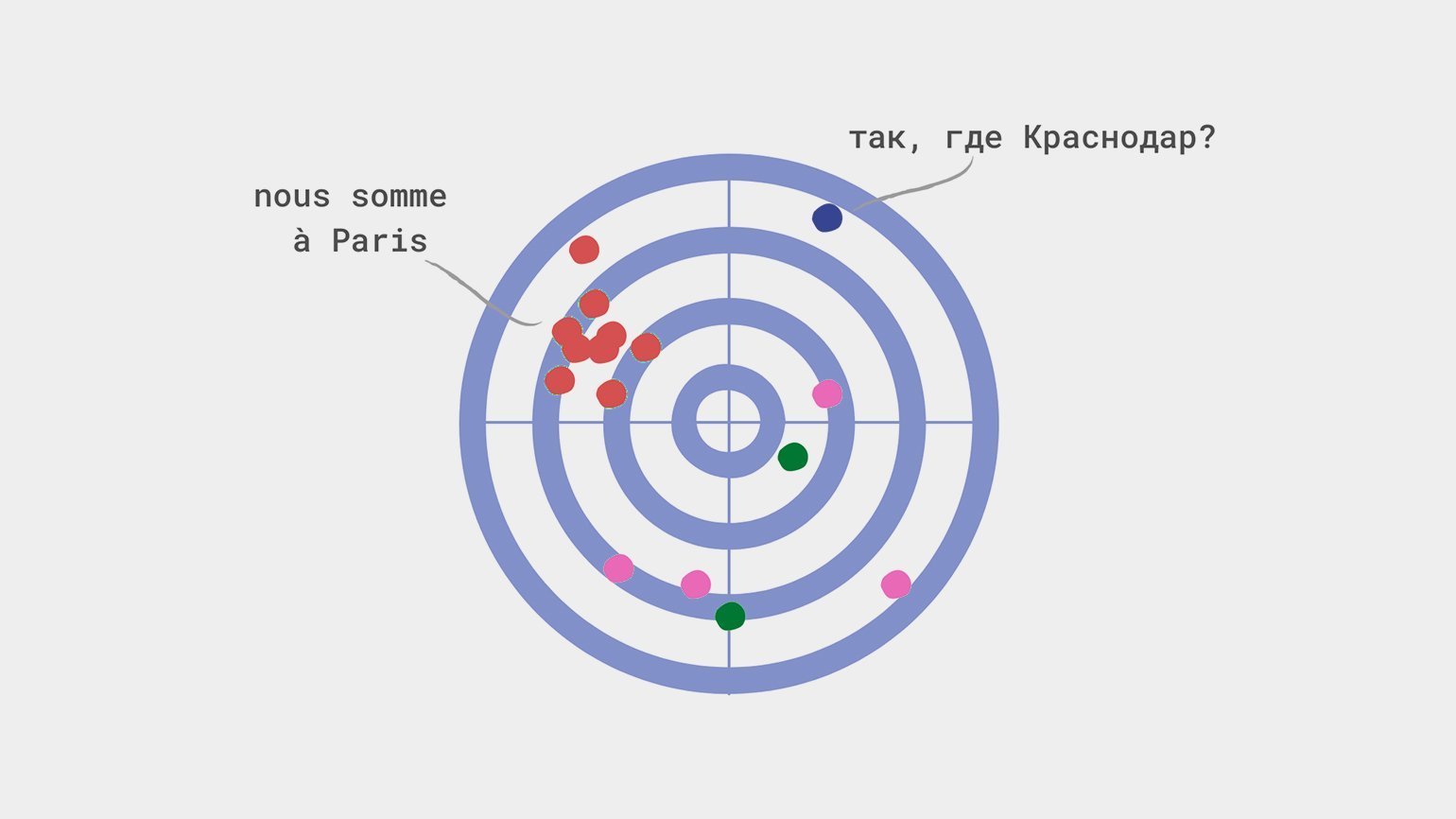
Чаще всего причиной смещения являются:
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.

Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
5. Дисперсия
Дисперсия — это величина, показывающая, как именно и насколько сильно разбросаны значения — например, предсказания модели машинного обучения или доход за рассматриваемый период. За точку, относительно которой эти значения разбросаны, берут истинное значение, целевую переменную или математическое ожидание, которое вычисляется теоретически и заранее.
Часто в качестве матожидания выступает обычное среднее арифметическое. Например, математическое ожидание количества очков при броске игрального кубика равно среднему арифметическому очков на всех гранях:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 21/6 = 3,5
Представьте себе тир, стрелка и мишень. Снайпер стреляет в стандартный круг, где попадание в центр даёт 10 баллов, в зависимости от удаления от центра количество баллов снижается, а крайние области дают всего 1 балл. Каждый выстрел стрелка — это случайное целое значение от 1 до 10.
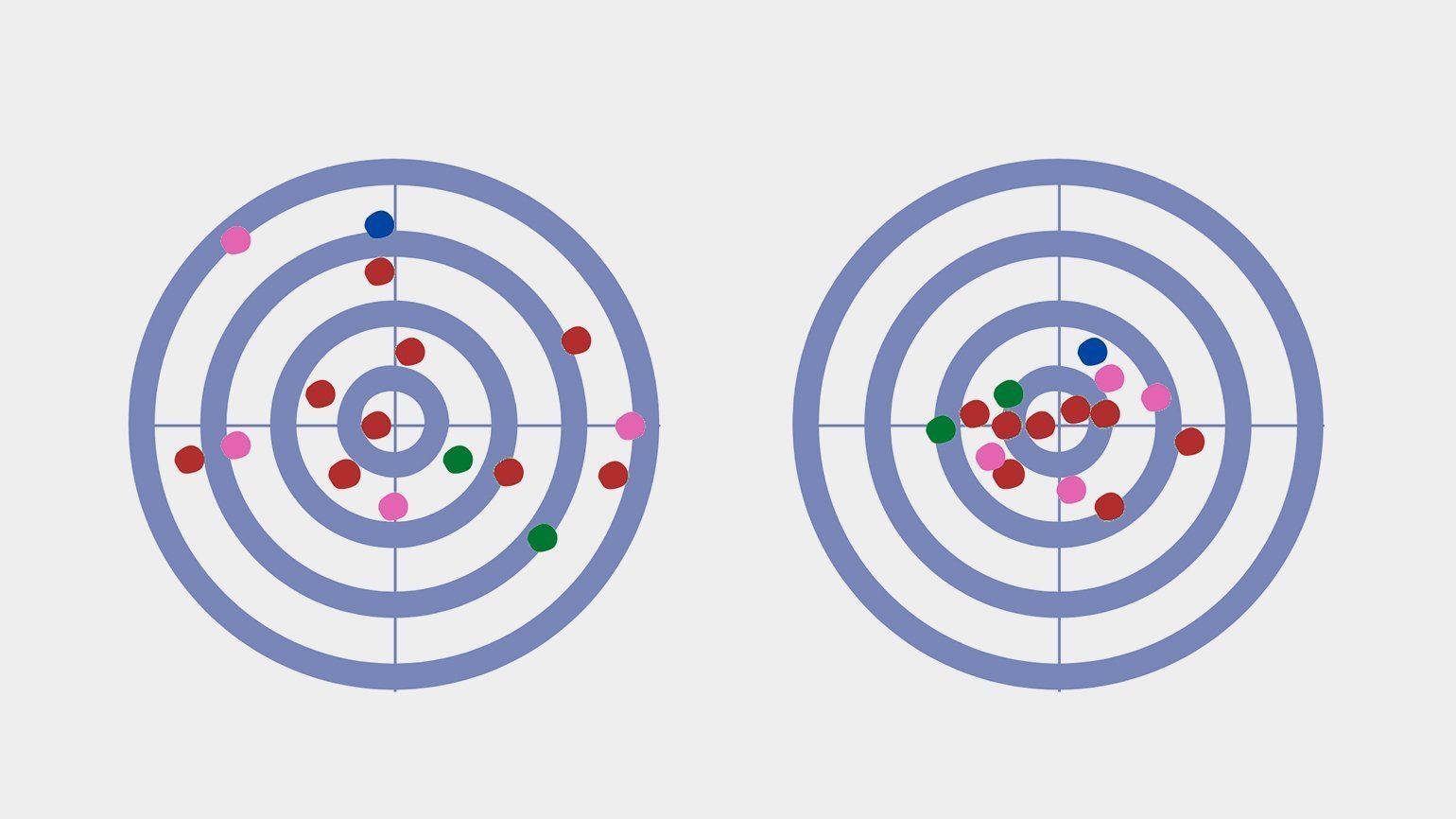
Изрешечённая пулями мишень — отличная иллюстрация распределения. Дисперсия здесь — величина, обратная кучности попаданий: хорошая кучность означает низкую дисперсию, и наоборот.
6. Дилемма (компромисс) смещения и дисперсии
Смещение и дисперсия вместе составляют итоговую ошибку предсказания модели машинного обучения. В идеальном мире и смещение маленькое, и дисперсия низкая. На практике это связано в дилемму: уменьшение одной из величин неизбежно приводит к росту другой.

Если не вдаваться в детали, обучение модели — это построение функции, график которой лучше всего ложится на точки из тренировочного набора данных.
Модель может нарисовать нам довольно сложную и заковыристую функцию, график, который хорошо охватывает все точки в тренировочных данных. Но если наложить этот график на новые точки (то есть дать функции новые данные), она сработает хуже — так и получается смещение.

С другой стороны, обучение на разных тренировочных наборах или даже разных датасетах с большой вероятностью даст разброс в предсказаниях, то есть высокую дисперсию.
Более сложные модели дают низкое смещение, но чувствительны к шуму и колебаниям в новых данных, поэтому их предсказания разбросаны. Если при обучении наш снайпер будет учитывать незначимые факторы (вроде цвета мишени или направления магнитного поля Земли), то в другом тире, с другой винтовкой или в другую погоду точность его стрельбы упадёт.
Простые модели, напротив, упускают важные параметры и «бьют кучно, но мимо». Как другой снайпер, не приученный обращать внимание на ветер и расстояние до мишени.
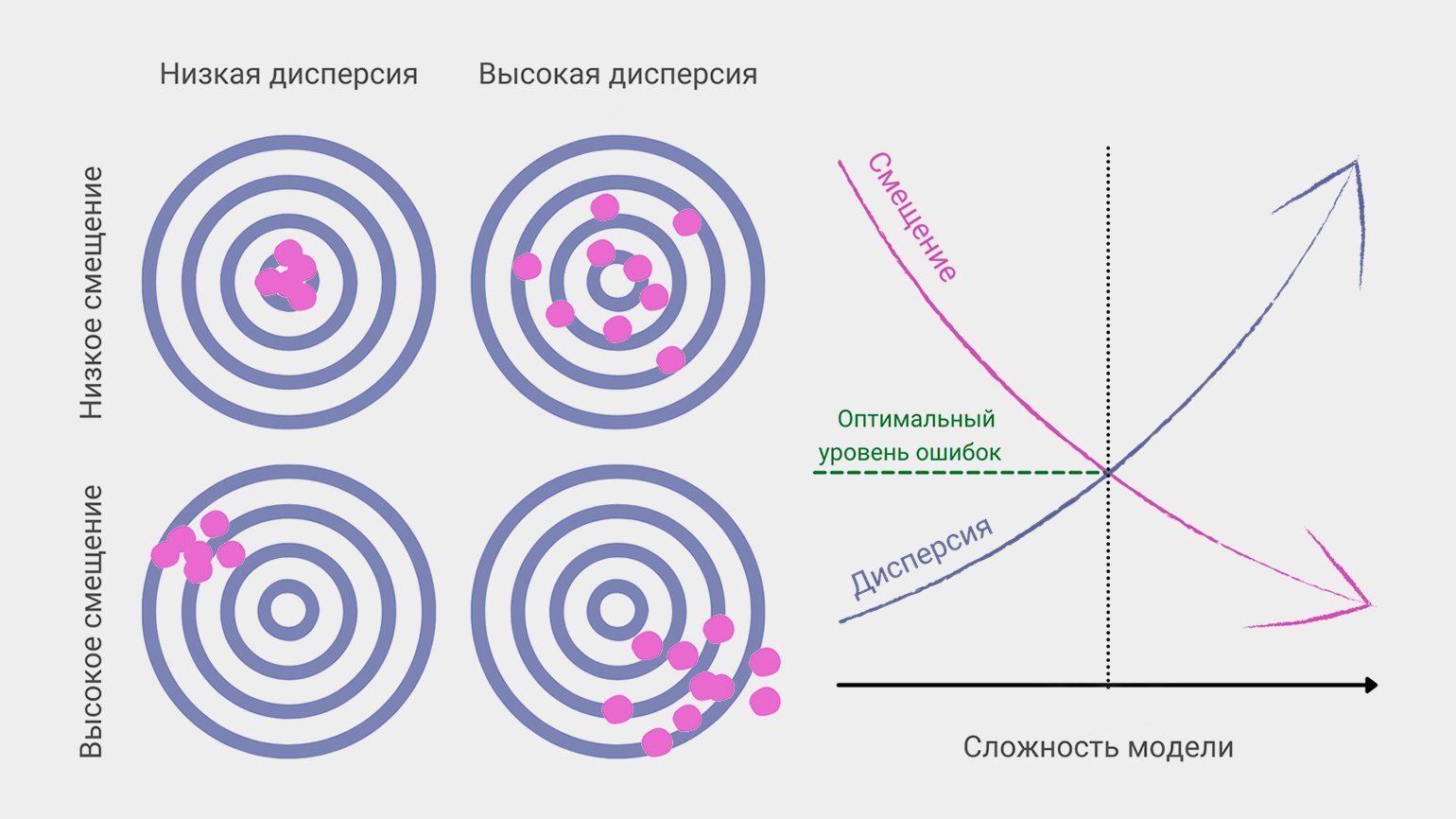
В процессе настройки модели машинного обучения дата-сайентист всегда ищет компромисс между смещением и дисперсией, чтобы уменьшить общую ошибку предсказания.
Кстати, эта дилемма встречается не только в статистике и машинном обучении, но и в обучении людей. В исследовании 2009 года утверждается, что люди используют эвристику «высокое смещение + низкая дисперсия»: мы заблуждаемся, зато очень уверенно.
Учтите это, если захотите сделать свой ИИ более похожим на человека.
7. Корреляция
Когда изменения одной величины сопутствуют изменениям другой, говорят о корреляции. Главное, что необходимо о ней знать: корреляция не означает причинно-следственную связь.
Линейная корреляция — это когда изменения одной величины пропорциональны изменениям другой. Она может быть:
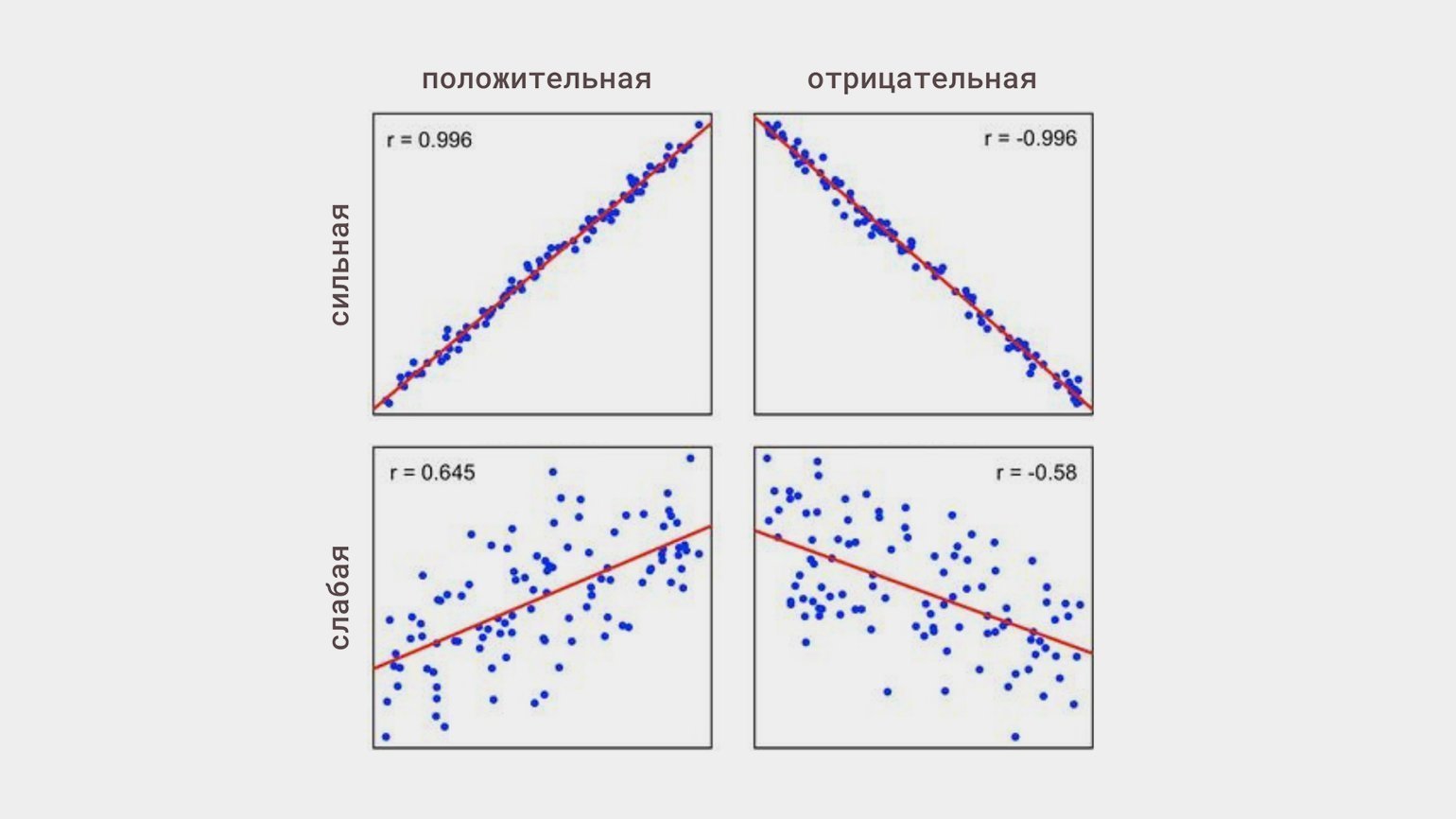
Статистическую связь между переменными исследуют с помощью корреляционного анализа. Его основная задача — оценить тесноту связи (это термин) между переменными, чтобы понять, какие переменные учитывать в модели, а какие нет.
И ещё раз, потому что действительно важно: корреляция ни в коем случае не означает причинно-следственную связь. Если два показателя скоррелированы, то далеко не факт, что они хоть как-то связаны.
Кстати, проект Spurious Correlations («Ложные корреляции») публикует графики корреляций между совершенно неожиданными статистическими показателями — например, количеством людей, утонувших в домашних бассейнах, и числом фильмов с участием Николаса Кейджа.
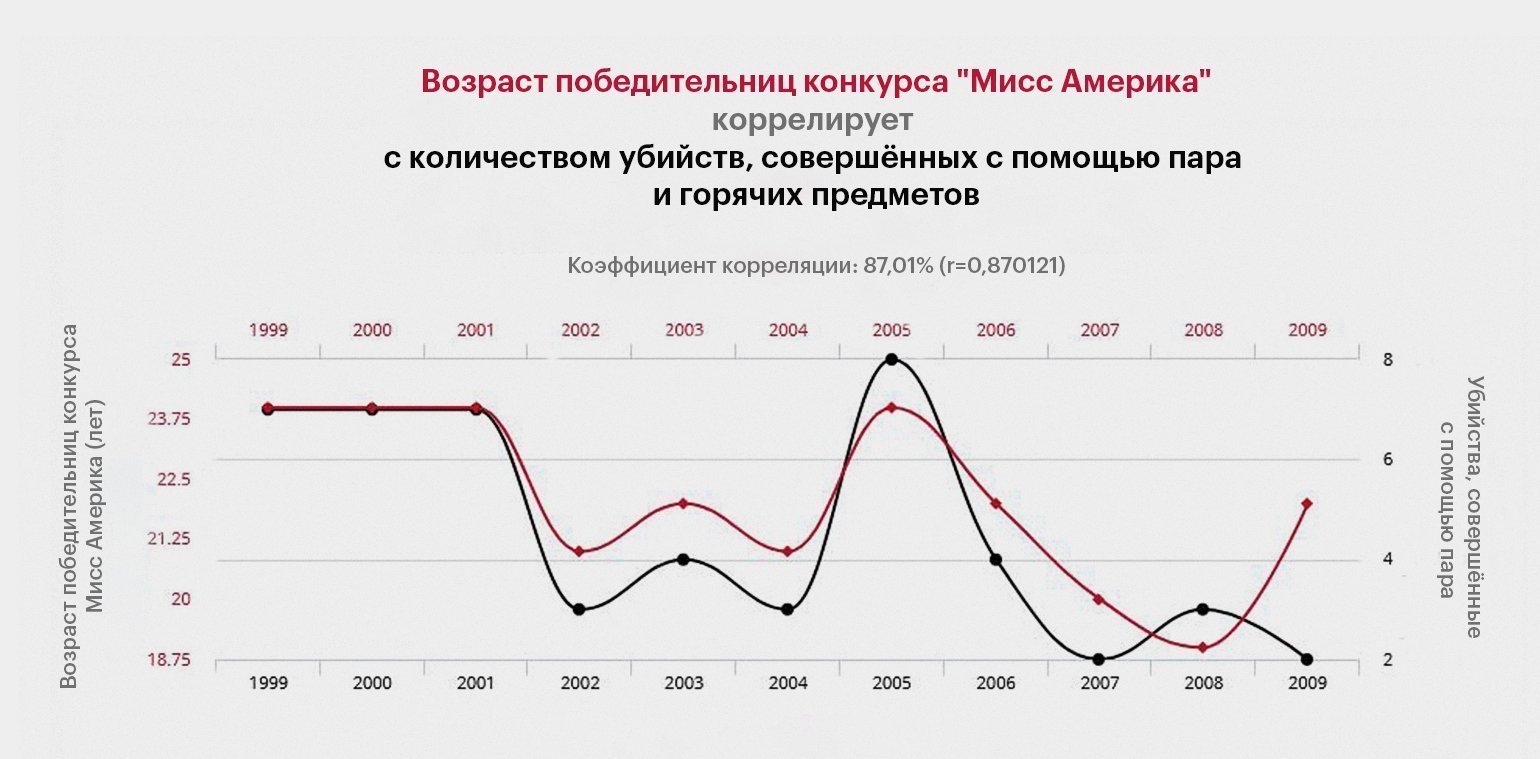
Имеет смысл время от времени заходить по этой ссылке с целью профилактики СПГС — синдрома поиска глубинной связи.
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании. Приходите!
Polina Vari для Skillbox
Для отличия статистического термина от терминов из других отраслей (музыки, биологии) часто пишут этот термин через «е», а не через «э».
Описательная статистика (англ. descriptive statistics) занимается обработкой опытных данных, их систематизацией, наглядным представлением в форме графиков и таблиц, а также их количественным описанием посредством основных статистических показателей.
Тренировочный набор, или обучающая выборка (англ. train set, training sample), — часть данных из датасета, по которой производится настройка или оптимизация модели машинного обучения.
Рекомендательные системы — программы, которые пытаются предсказать, какие объекты (фильмы, музыка, книги, новости, веб-сайты и др.) будут интересны пользователю.
Разницу между наблюдаемым значением и значением, предсказанным моделью.
4. Мода. Медиана. Генеральная и выборочная средняя
Мода на экране, медиана в треугольнике, а средние – это температура по больнице и в палате. Продолжаем наш практический курс занимательной статистики (Занятие 1) изучением центральных характеристик статистической совокупности, названия которых вы видите в заголовке. И начнём мы с его конца, поскольку о средних величинах речь зашла практически с первых же абзацев темы. Для подготовленных читателей оглавление:
ну а «чайникам» лучше ознакомиться с материалом по порядку:
Итак, пусть исследуется некоторая генеральная совокупность объёма 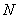 , а именно её числовая характеристика
, а именно её числовая характеристика 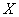 , не важно, дискретная или непрерывная (Занятия 2, 3).
, не важно, дискретная или непрерывная (Занятия 2, 3).
Генеральной средней называется среднее арифметическое всех значений этой совокупности: 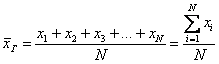
Если среди чисел 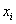 есть одинаковые (что характерно для дискретного ряда), то формулу можно записать в более компактном виде:
есть одинаковые (что характерно для дискретного ряда), то формулу можно записать в более компактном виде: 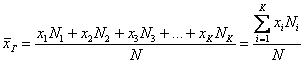 , где
, где
варианта 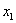 повторяется
повторяется 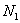 раз;
раз;
варианта 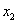 –
– 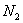 раз;
раз;
варианта 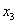 –
– 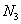 раз;
раз;
…
варианта 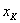 –
– 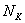 раз.
раз.
Живой пример вычисления генеральной средней встретился в Примере 2, но чтобы не занудничать, я даже не буду напоминать его содержание.
Далее. Как мы помним, обработка всей генеральной совокупности часто затруднена либо невозможна, и поэтому из неё организуют представительную выборку объема 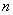 , и на основании исследования этой выборки делают вывод обо всей совокупности.
, и на основании исследования этой выборки делают вывод обо всей совокупности.
Выборочной средней называется среднее арифметическое всех значений выборки: 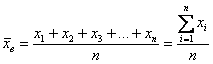
и при наличии одинаковых вариант формула запишется компактнее:
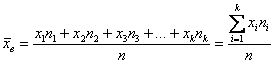 – как сумма произведений вариант
– как сумма произведений вариант 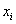 на соответствующие частоты
на соответствующие частоты 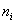 , делённая на объём совокупности.
, делённая на объём совокупности.
Выборочная средняя 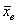 позволяет достаточно точно оценить истинное значение
позволяет достаточно точно оценить истинное значение 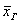 , чего вполне достаточно для многих исследований. При этом, чем больше выборка, тем точнее будет эта оценка.
, чего вполне достаточно для многих исследований. При этом, чем больше выборка, тем точнее будет эта оценка.
Практику начнём, а точнее продолжим, с дискретного вариационного ряда и знакомого условия:
По результатам выборочного исследования 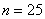 рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
Это числа из Примера 4 (см. по ссылке выше), но теперь нам требуется: вычислить выборочную среднюю, и, не отходя от станка, найти моду и медиану.
Как решать задачу? Если нам даны первичные данные (исходные необработанные значения), то их можно тупо просуммировать и разделить результат на объём выборки:
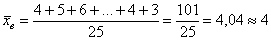 – среднестатистический квалификационный разряд рабочих цеха.
– среднестатистический квалификационный разряд рабочих цеха.
Но во многих задачах требуется составить вариационный ряд (см. Пример 4): 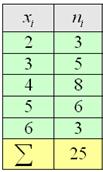
– или же этот ряд предложен изначально (что бывает чаще). И тогда, мы, конечно, используем «цивилизованную» формулу: 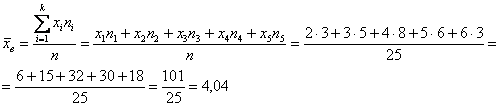
Далее. Мода и медиана. Эти понятия тоже вводятся как для генеральной, так и для выборочной совокупности, и определения я сформулирую в общем виде.
Мода. Мода 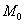 дискретного вариационного ряда – это варианта с максимальной частотой. В данном случае
дискретного вариационного ряда – это варианта с максимальной частотой. В данном случае 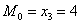 . Моду легко отыскать по таблице, и ещё легче на полигоне частот – это абсцисса самой высокой точки:
. Моду легко отыскать по таблице, и ещё легче на полигоне частот – это абсцисса самой высокой точки: 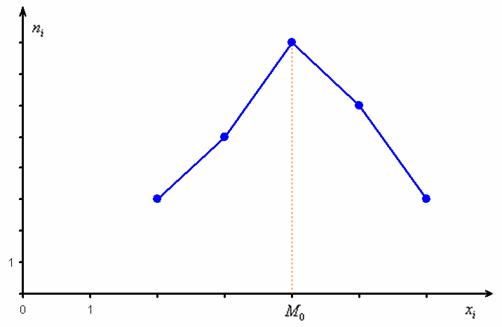
Иногда таковых значений несколько (с одинаковой максимальной частотой), и тогда модой считают каждое из них.
Если все или почти все варианты различны (что характерно для интервального ряда), то модальное значение определяется несколько другим способом, о котором во 2-й части урока.
Медиана. Медиана 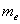 вариационного ряда* – это значение, которая делит его на две равные части (по количеству вариант).
вариационного ряда* – это значение, которая делит его на две равные части (по количеству вариант).
* не важно, дискретного или интервального, генеральной совокупности или выборочной.
Медиану можно отыскать несколькими способами.
Если даны первичные данные, то сортируем их по возрастанию либо убыванию (см. Задание 1) и находим середину ранжированного ряда: 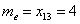 . Почему именно 13-е число? Потому что перед ним находится 12 чисел и после него тоже 12 чисел, таким образом, значение
. Почему именно 13-е число? Потому что перед ним находится 12 чисел и после него тоже 12 чисел, таким образом, значение 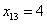 разделило ряд на две равные части, а значит, является медианой. Этот номер можно найти аналитически:
разделило ряд на две равные части, а значит, является медианой. Этот номер можно найти аналитически:
– если совокупность содержит нечётное количество чисел (наш случай), то делим её объём пополам: 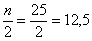 и округляем полученное значение в бОльшую сторону: 13 – получая тем самым срединный номер.
и округляем полученное значение в бОльшую сторону: 13 – получая тем самым срединный номер.
– если совокупность содержит чётное количество чисел, например, 20, то делаем то же самое: 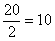 , и медианное значение здесь рассчитывается как среднее арифметическое 10-го и следующего числа:
, и медианное значение здесь рассчитывается как среднее арифметическое 10-го и следующего числа: 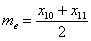 .
.
Напоминаю, что изложенная инструкция работает для упорядоченного (по возрастанию либо убыванию) ряда. Но есть и более быстрый путь, где ничего не нужно сортировать. Это использование стандартной функции Экселя:
– забиваем в любую свободную ячейку =МЕДИАНА(, выделяем мышью все числа, закрываем скобку ) и жмём Enter. Попробуйте самостоятельно. Этот способ удобен, когда вам дано много значений.
Следует отметить, что в Экселе существуют и отдельные функции для вычисления средней (=СРЗНАЧ), моды (=МОДА) и ещё много чего, но я против использования этих функций в учебном курсе, за исключением случаев, где это действительно целесообразно. …Почему против? Потому что они не помогают понять суть показателей и, более того, отупляют. Так, среднюю гораздо вразумительнее рассчитывать следующим образом:
=СУММ(выделяем мышью диапазон) / объем совокупности. Вычисления рекомендую опробовать лично (ссылка выше).
Ситуация вторая. Когда составлен либо изначально дан готовый дискретный ряд. Тут можно поступить «по любительски» – начать отсчитывать примерно равное количество чисел по краям ряда: 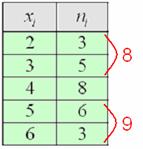
после чего мысленно либо на черновике их отбрасывать, в данном случае отбросим по 8 штук сверху и снизу: 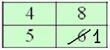
откуда становится ясно, что медианное значение: 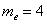
Второй способ более академичен, находим относительные накопленные частоты: 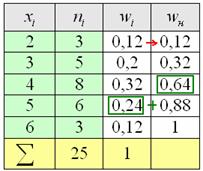
и то значение «икса», у которого 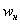 «переваливает» за отметку 0,5 (50% упорядоченной совокупности). Для 3-го разряда успело накопиться
«переваливает» за отметку 0,5 (50% упорядоченной совокупности). Для 3-го разряда успело накопиться 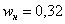 (32% совокупности), а вот для 4-го – уже
(32% совокупности), а вот для 4-го – уже 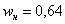 (64%). Таким образом, отметка в 50% пройдена именно здесь, и, стало быть, .
(64%). Таким образом, отметка в 50% пройдена именно здесь, и, стало быть, .
Запишем красивый ответ: 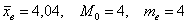
Полученные значения близки друг к другу, и это говорит о симметрии вариационного ряда относительно центра, что хорошо видно по полигону частот (см. чертёж выше). И с высокой вероятностью можно утверждать, что примерно так же распределена и вся генеральная совокупность (все рабочие цеха).
И тут возникает следующий закономерный вопрос: а зачем вообще нужна мода с медианой? – ведь есть средняя.
А дело в том, что в ряде случаев среднее значение неудовлетворительно характеризует центральную тенденцию статистической совокупности:
Известны результаты продаж пиджаков в универмаге города: 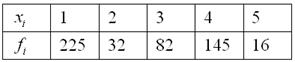
где, 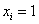 – количество пуговиц на пиджаке,
– количество пуговиц на пиджаке, 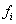 – число продаж, буква «эф» – это тоже достаточно популярная буква для обозначения частот, и она не должна вас смущать при встрече.
– число продаж, буква «эф» – это тоже достаточно популярная буква для обозначения частот, и она не должна вас смущать при встрече.
…ну, а если вам не нравятся пиджаки, то представьте какие-нибудь шляпки с цветочками 🙂
Также обратим внимание, что в условии задачи ничего не сказано о том, генеральная ли это совокупность или выборочная, и в подобной ситуации я не рекомендую ничего додумывать – среднюю просто обозначаем через 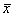 , без подстрочного индекса.
, без подстрочного индекса.
Вычислить среднюю – в экселевском файле уже забиты исходные данные и приведена краткая инструкция. Если под пальцами нет Экселя, то считаем на калькуляторе. Не ленимся! – заданий я предлагаю немного (у вас своих хватает :)), но прорешать их очень важно! Краткое решение для сверки в конце урока.
…какие мысли на счёт полученного значения 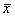 ? С такой статистикой магазин разорится.
? С такой статистикой магазин разорится.
И, конечно, важнейший показатель здесь мода: 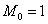 . Потому что такая мода 🙂 Более того, в прикладных исследованиях рассматривают несколько модальных значений (вроде даже в Экселе функция есть), в частности, ещё одной модой можно считать варианту
. Потому что такая мода 🙂 Более того, в прикладных исследованиях рассматривают несколько модальных значений (вроде даже в Экселе функция есть), в частности, ещё одной модой можно считать варианту 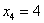 . Но это уже попсовая статистика, которую я не буду развивать в этом курсе.
. Но это уже попсовая статистика, которую я не буду развивать в этом курсе.
Ещё хуже (в содержательном плане) ситуация с медианой – продолжаем решать задачу в Экселе (ссылка выше) либо в тетради! Особо зоркие читатели медиану углядят и устно, и в конце урока я привёл способ, который просто бросился мне в глаза.
Теперь надеваем пиджаки / шляпы и возвращаемся на фабрику, где бухгалтер Петрова вычислила генеральную среднюю заработную плату рабочих: 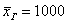 денежных единиц. Здесь мы плавно перешли к интервальному ряду, который целесообразно составлять для «денежных» показателей.
денежных единиц. Здесь мы плавно перешли к интервальному ряду, который целесообразно составлять для «денежных» показателей.
Что будет, если к совокупности добавить руководящий персонал и директора Петрова? Средняя зарплата немного увеличится: 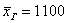 , и это уже будет несколько искажённая картина.
, и это уже будет несколько искажённая картина.
А вот если сюда добавить олигарха Петровского, то полученная средняя 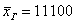 вообще вызовет широкое возмущение общественности.
вообще вызовет широкое возмущение общественности.
Поэтому, если в статистической совокупности есть «аномальные» отклонения в ту или иную сторону, то в качестве оценки центрального значения как нельзя лучше подходит медиана, которая в нашем условном примере будет равна, скажем, 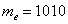 . Ниже этой планки зарабатывает ровно половина совокупности и выше – другая половина, включая Петрова и Петровского. …Главное только, чтобы они наняли правильного статистика 🙂
. Ниже этой планки зарабатывает ровно половина совокупности и выше – другая половина, включая Петрова и Петровского. …Главное только, чтобы они наняли правильного статистика 🙂
Как вычислить моду, медиану и среднюю интервального ряда?
Начнём опять с ситуации, когда нам даны первичные статические данные:
По результатам выборочного исследования цен на ботинки в магазинах города получены следующие данные (ден. ед.): 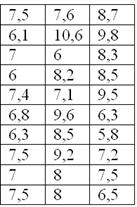
– это в точности числа из Примера 6 статьи об интервальном вариационном ряде.
Но теперь нам нужно найти среднюю, моду и медиану.
Решение: чтобы найти среднюю по первичным данным, нужно просуммировать все варианты и разделить полученный результат на объём совокупности:
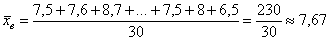 ден. ед.
ден. ед.
Эти подсчёты, кстати, займут не так много времени и при использовании оффлайн калькулятора. Но если есть Эксель, то, конечно, забиваем в любую свободную ячейку =СУММ(, выделяем мышкой все числа, закрываем скобку ), ставим знак деления /, вводим число 30 и жмём Enter. Готово.
Что касается моды, то её оценка по исходным данным, становится непригодна. Хоть мы и видим среди чисел одинаковые, но среди них запросто может найтись пять так шесть-семь вариант с одинаковой максимальной частотой, например, частотой 2. Кроме того, цены могут быть округлёнными. Поэтому модальное значение рассчитывается по сформированному интервальному ряду (о чём чуть позже).
Чего не скажешь о медиане: забиваем в Эксель =МЕДИАНА(, выделяем мышью все числа, закрываем скобку ) и жмём Enter: 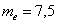 . Причём, здесь даже ничего не нужно сортировать.
. Причём, здесь даже ничего не нужно сортировать.
Но в Примере 6 была проведена сортировка по возрастанию (вспоминаем и сортируем – ссылка выше), и это хорошая возможность повторить формальный алгоритм отыскания медианы. Делим объём выборки пополам:
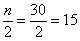 , и поскольку она состоит из чётного количества вариант, то медиана равна среднему арифметическому 15-й и 16-й варианты упорядоченного (!) вариационного ряда:
, и поскольку она состоит из чётного количества вариант, то медиана равна среднему арифметическому 15-й и 16-й варианты упорядоченного (!) вариационного ряда:
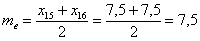 ден. ед.
ден. ед.
Ситуация вторая. Когда дан готовый интервальный ряд (типичная учебная задача).
Продолжаем анализировать тот же пример с ботинками, где по исходным данным был составлен ИВР. Для вычисления средней потребуются середины 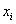 интервалов:
интервалов: 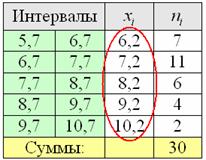
– чтобы воспользоваться знакомой формулой дискретного случая: 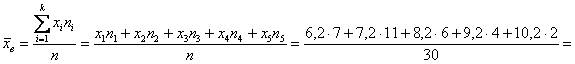
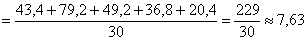 – отличный результат! Расхождение с более точным значением (
– отличный результат! Расхождение с более точным значением (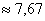 ), вычисленным по первичным данным, составляет всего 0,04.
), вычисленным по первичным данным, составляет всего 0,04.
По сути дела, здесь мы приблизили интервальный ряд дискретным, и это приближение оказалось весьма эффективным. Впрочем, особой выгоды тут нет, т.к. при современном программном обеспечении не составляет труда вычислить точное значение даже по очень большому массиву первичных данных. Но это при условии, что они нам известны 🙂
С другими центральными показателями всё занятнее.
Чтобы найти моду, нужно найти модальный интервал (с максимальной частотой) – в данной задаче это интервал 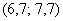 с частотой 11, и воспользоваться следующей страшненькой формулой:
с частотой 11, и воспользоваться следующей страшненькой формулой: 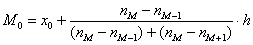 , где:
, где:
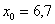 – нижняя граница модального интервала;
– нижняя граница модального интервала;
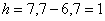 – длина модального интервала;
– длина модального интервала;
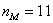 – частота модального интервала;
– частота модального интервала;
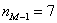 – частота предыдущего интервала;
– частота предыдущего интервала;
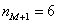 – частота следующего интервала.
– частота следующего интервала.
Таким образом:
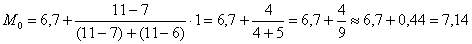 ден. ед. – как видите, «модная» цена на ботинки заметно отличается от средней арифметической
ден. ед. – как видите, «модная» цена на ботинки заметно отличается от средней арифметической 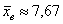 .
.
Не вдаваясь в геометрию формулы, просто приведу гистограмму относительных частот и отмечу  :
: 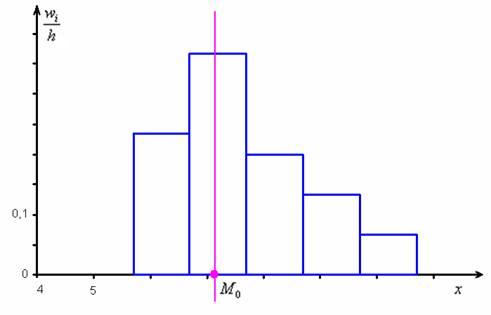
откуда хорошо видно, что мода смещена относительно центра модального интервала в сторону левого интервала с бОльшей частотой. Логично.
Справочно разберу редкие случаи:
– если модальный интервал крайний, то 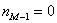 либо
либо 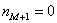 ;
;
– если обнаружатся 2 модальных интервала, которые находятся рядом, например, 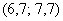 и
и 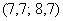 , то рассматриваем модальный интервал
, то рассматриваем модальный интервал 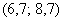 , при этом близлежащие интервалы (слева и справа) по возможности тоже укрупняем в 2 раза.
, при этом близлежащие интервалы (слева и справа) по возможности тоже укрупняем в 2 раза.
– если между модальными интервалами есть расстояние, то применяем формулу к каждому интервалу, получая тем самым 2 или бОльшее количество мод.
Вот такой вот депеш мод 🙂
И медиана. Если дан готовый интервальный ряд, то медиана рассчитывается чуть по менее страшной формуле, но сначала нудно (описка по Фрейду:)) найти медианный интервал – это интервал, содержащий варианту (либо 2 варианты), которая делит вариационный ряд на две равные части.
Выше я рассказал, как определить медиану, ориентируясь на относительные накопленные частоты 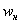 , здесь же сподручнее рассчитать «обычные» накопленные частоты
, здесь же сподручнее рассчитать «обычные» накопленные частоты 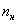 . Вычислительный алгоритм точно такой же – первое значение сносим слева (красная стрелка), и каждое следующее получается как сумма предыдущего с текущей частотой из левого столбца (зелёные обозначения в качестве примера):
. Вычислительный алгоритм точно такой же – первое значение сносим слева (красная стрелка), и каждое следующее получается как сумма предыдущего с текущей частотой из левого столбца (зелёные обозначения в качестве примера): 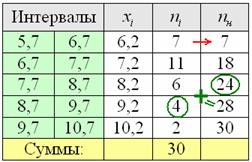
Всем понятен смысл чисел в правом столбце? – это количество вариант, которые успели «накопиться» на всех «пройденных» интервалах, включая текущий.
Поскольку у нас чётное количество вариант (30 штук), то медианным будет тот интервал, который содержит 30/2 = 15-ю и 16-ю варианту. И ориентируясь по накопленным частотам, легко прийти к выводу, что эти варианты содержатся в интервале 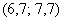 .
.
Формула медианы: 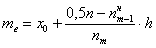 , где:
, где:
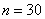 – объём статистической совокупности;
– объём статистической совокупности;
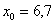 – нижняя граница медианного интервала;
– нижняя граница медианного интервала;
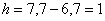 – длина медианного интервала;
– длина медианного интервала;
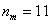 – частота медианного интервала;
– частота медианного интервала;
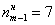 – накопленная частота предыдущего интервала.
– накопленная частота предыдущего интервала.
Таким образом:
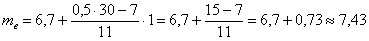 ден. ед. – заметим, что медианное значение, наоборот, оказалось смещено правее, т.к. по правую руку находится значительное количество вариант:
ден. ед. – заметим, что медианное значение, наоборот, оказалось смещено правее, т.к. по правую руку находится значительное количество вариант: 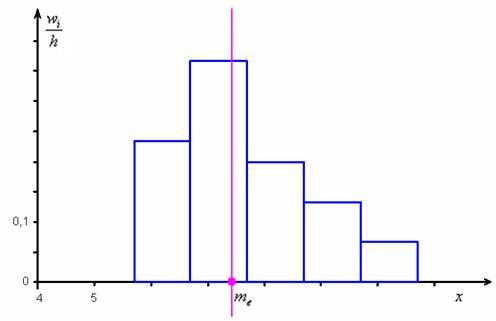
И справочно особые случаи:
– Если медианным является крайний левый интервал, то 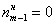 ;
;
– Если вариационный ряд содержит чётное количество вариант и две средние варианты попали в разные интервалы, то объединяем эти интервалы, и по возможности удваиваем предыдущий интервал
Ответ: 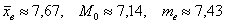 ден. ед.
ден. ед.
Здесь центральные показатели оказались заметно отличны друг от друга, и это говорит об асимметрии распределения, которая хорошо видна по гистограмме.
И задача для тренировки:
Для изучения затрат времени на изготовление одной детали рабочими завода проведена выборка, в результате которой получено следующее статистическое распределение: 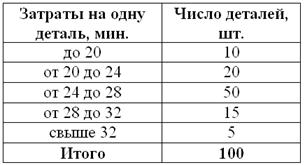
…да, тематичная у меня получилась статья 🙂
Найти среднюю, моду и медиану.
Это, кстати, уже каноничная «интервальная» задача, в которой исследуется непрерывная величина – время.
Решаем эту задачу в Экселе – все числа и инструкции уже там. Если нет Экселя, считаем на калькуляторе, что в данном случае может оказаться даже удобнее. Образец решения, как обычно, в конце урока.
Несмотря на разнообразия рассмотренных показателей, их всё равно бывает не достаточно. Существуют крайне неоднородные совокупности, у которых варианты «кучкуются» во многих местах, и по этой причине средняя, мода и медиана неудовлетворительно характеризуют центральную тенденцию.
В таких случаях вариационный ряд дробят с помощью квартилей, децилей, а в упоротых специализированных исследованиях – и с помощью перцентилей.
Квартили упорядоченного вариационного ряда – это варианты 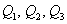 , которые делят его на 4 равные (по количеству вариант) части. Откуда автоматически следует, что 2-я квартиль – есть в точности медиана:
, которые делят его на 4 равные (по количеству вариант) части. Откуда автоматически следует, что 2-я квартиль – есть в точности медиана: 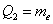 .
.
В тяжёлых случаях проводится разбиение на 10 частей – децилями 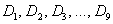 – это варианты, который делят упорядоченный вариационный ряд на 10 равных (по количеству вариант) частей.
– это варианты, который делят упорядоченный вариационный ряд на 10 равных (по количеству вариант) частей.
И в очень тяжелых случаях в ход пускается 99 перцентилей 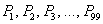 .
.
И после разбиения вариационного ряда каждый участок исследуется по отдельности – рассчитываются локальные средние показатели, локальные показатели вариации и т.д.
В учебном курсе квартили, децили, перцентили встречаются редко, и посему я оставляю этот материал (их нахождение) для самостоятельного изучения.
Ну а сейчас мы перейдём к рассмотрению другой группы статистических показателей – как раз к показателям вариации.
Пример 9. Решение: заполним расчётную таблицу: 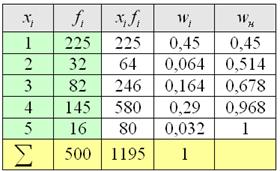
Вычислим среднюю:
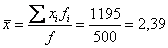 – две с половиной пуговицы, Карл!
– две с половиной пуговицы, Карл!
По правому столбцу определяем «иксовое» значение, которое делит совокупность на 2 равные части: 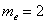 (именно здесь накопленная частота «перевалила» за 0,5).
(именно здесь накопленная частота «перевалила» за 0,5).
Кроме того, медиану легко усмотреть и устно – поскольку половина совокупности равна 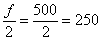 , а сумма первых двух частот
, а сумма первых двух частот 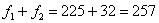 , то совершенно понятно, что 250-й и 251-й пиджак – двухпуговичные.
, то совершенно понятно, что 250-й и 251-й пиджак – двухпуговичные.
Пример 11. Решение: поскольку длина внутренних интервалов равна 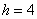 , то длины крайних интервалов полагаем такими же (см. конец статьи Интервальный вариационный ряд). Заполним расчётную таблицу:
, то длины крайних интервалов полагаем такими же (см. конец статьи Интервальный вариационный ряд). Заполним расчётную таблицу: 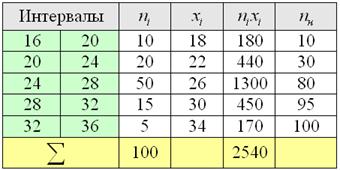
Вычислим выборочную среднюю:
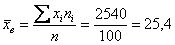 мин.
мин.
Моду вычислим по формуле 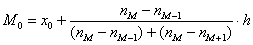 , в данном случае:
, в данном случае:
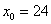 – нижняя граница модального интервала;
– нижняя граница модального интервала;
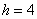 – длина модального интервала;
– длина модального интервала;
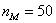 – частота модального интервала;
– частота модального интервала;
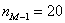 – частота предшествующего интервала;
– частота предшествующего интервала;
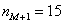 – частота следующего интервала.
– частота следующего интервала.
Таким образом:
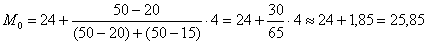 мин.
мин.
Анализируя накопленные частоты, приходим к выводу, что медианным является интервал 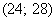 (именно он содержит 50-ю и 51-ю варианты, которые делят ряд пополам).
(именно он содержит 50-ю и 51-ю варианты, которые делят ряд пополам).
Медиану вычислим по формуле 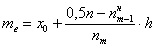 , в данном случае:
, в данном случае:
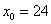 – нижняя граница медианного интервала;
– нижняя граница медианного интервала;
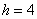 – длина этого интервала;
– длина этого интервала;
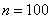 – объём статистической совокупности;
– объём статистической совокупности;
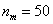 – частота медианного интервала;
– частота медианного интервала;
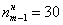 – накопленная частота предыдущего интервала.
– накопленная частота предыдущего интервала.
Таким образом:
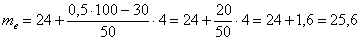 мин.
мин.
Ответ: среднее время изготовления детали характеризуется следующими центральными характеристиками: 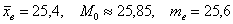
Автор: Емелин Александр
(Переход на главную страницу)
 Zaochnik.com – профессиональная помощь студентам
Zaochnik.com – профессиональная помощь студентам
cкидкa 15% на первый зaкaз, прoмoкoд: 5530-hihi5
Tutoronline.ru – онлайн репетиторы по математике и другим предметам