Что такое артефакт?
Есть довольно много вопросов и ответов, которые упоминают « артефакт ».
Мои вопросы :
Бинарный репозиторий является естественным расширением репозитория исходного кода в том смысле, что он будет хранить результаты вашего процесса сборки, часто обозначаемые как артефакты. В большинстве случаев бинарный репозиторий можно использовать не напрямую, а через менеджер пакетов, который поставляется с выбранной технологией.
В большинстве случаев они будут хранить отдельные компоненты приложения, которые впоследствии могут быть собраны в полноценный продукт, что позволит разбить сборку на более мелкие фрагменты, более эффективно использовать ресурсы, сократить время сборки, улучшить отслеживание бинарных отладочных баз данных и т. Д.
Вот некоторые из наиболее популярных менеджеров пакетов, которыми можно управлять с помощью бинарного репозитория:
Этот список далеко не полный, просто дает представление о том, что там.
Бинарный репозиторий может позволить разместить все это под одной крышей, что значительно упрощает их управление для команд. Обратите внимание, что вам не нужна очень большая команда, чтобы начать получать выгоды от управления бинарными пакетами. Первоначальные инвестиции не очень велики, и выгоды ощущаются сразу. Особенно сейчас, когда все больше платформ, сред и языков интегрируют это управление зависимостями непосредственно в них. Однако самое большое их преимущество, которое я обнаружил, заключалось в том, чтобы создать среду, которую ваши программисты найдут естественной и комфортной, что сделает ее необходимой. Это помогает вам, как разработчикам, создать прочную цепочку инструментов, и помогает им сделать общий опыт естественным образом подходящим для их стека.
Мое личное мнение состоит в том, что бинарные репозитории являются столь же важной частью хорошо спроектированной установки devops, как репозиторий исходного кода или непрерывная интеграция.
Артефакты

Что такое артефакты?
Артефакт — это специальный образ, используемый в других артефактах или отдельных образах, описанных в конфигурации. Артефакт предназначен преимущественно для отделения ресурсов инструментов сборки от процесса сборки образа приложения. Примерами таких ресурсов могут быть — программное обеспечение или данные, которые необходимы для сборки, но не нужны для запуска приложения, и т.п.
Используя артефакты, вы можете собирать неограниченное количество компонентов, что позволяет решать, например, следующие задачи:
Импортирование ресурсов из артефактов указывается с помощью директивы import в конфигурации в секции образа или секции артефакта.
Конфигурация
Конфигурация артефакта похожа на конфигурацию обычного образа. Каждый артефакт должен быть описан в своей секции конфигурации.
Инструкции, связанные со стадией from (инструкции указания базового образа и монтирования), а также инструкции импорта точно такие же как и при описании образа.
Стадия добавления инструкций Docker ( docker_instructions ) и соответствующие директивы не доступны при описании артефактов. Артефакт — это инструмент сборки, и все что от него требуется, это — только данные.
Остальные стадии и инструкции описания артефактов рассматриваются далее подробно.
Именование
Добавление исходного кода из git-репозиториев

В отличие от обычных образов, у конвейера стадий артефактов нет стадий gitCache и gitLatestPatch.
В werf для артефактов реализована необязательная зависимость от изменений в git-репозиториях. Таким образом, по умолчанию werf игнорирует какие-либо изменения в git-репозитории, кэшируя образ после первой сборки. Но вы можете определить зависимости от файлов и папок, при изменении в которых образ артефакта будет пересобираться
Читайте подробнее про работу с git-репозиториями в соответствующей статье.
Запуск инструкций сборки

У артефактов точно такое же как и у обычных образов использование директив и пользовательских стадий — beforeInstall, install, beforeSetup и setup.
Если в директиве stageDependencies в блоке git для пользовательской стадии не указана зависимость от каких-либо файлов, то образ кэшируется после первой сборки, и не будет повторно собираться пока соответствующая стадия находится в stages storage.
Если необходимо повторно собирать артефакт при любых изменениях в git, нужно указать stageDependency **/* для соответствующей пользовательской стадии. Пример для стадии install:
Читайте подробнее про работу с инструкциями сборки в соответствующей статье.
Использование артефактов
В отличие от обычного образа, у образа артефакта нет стадии git latest patch. Это сделано намеренно, т.к. стадия git latest patch выполняется обычно при каждом коммите, применяя появившиеся изменения к файлам. Однако артефакт рекомендуется использовать как образ с высокой вероятностью кэширования, который обновляется редко или нечасто (например, при изменении специальных файлов).
Пример: нужно импортировать в артефакт данные из git, и пересобирать ассеты только тогда, когда изменяются влияющие на сборку ассетов файлы. Т.е. в случае, изменения каких-либо других файлов в git, ассеты пересобираться не должны.
Конечно, существуют случаи когда необходимо включать изменения любых файлов git-репозитория в образ артефакта (например, если в артефакте происходит сборка приложения на Go). В этом случае необходимо указать зависимость относительно стадии (сборку которой необходимо выполнять при изменениях в git) с помощью git.stageDependencies и * в качестве шаблона. Пример:
В этом случае любые изменения файлов в git-репозитории будут приводить к пересборке образа артефакта, и всех образов, в которых определен импорт этого артефакта.
Версионирование артефактов сборки в Gradle используя git имена тегов, бранчей и коммитов
С переездом из SVN на GIT и gitlab (плюс переезд из Jenkins на Gitlab-CI, но его использование также упомянём), встал вопрос версионирования получаемых артефактов сборки приложения.
В SVN был всем привычный номер ревизии, монотонно увеличивающийся с каждым коммитом. Его было удобно добавлять в номер версии, и это решало большинство проблем. Но git конечно предоставляет множество плюшек, и стоило убеждать руководство и всё команду перевести проект на него…
Зато пришлось отстроить заново процесс версионирования получаемых артефактов сборки.
В итоге остановились на очень хорошем Gradle плагине github.com/nemerosa/versioning, о его использовании я и собираюсь рассказать.
Проблема
У нас в приложении Gradle используется давно, и для SVN просто использовалась наколенная функция, доставшаяся по наследству, написанная прямо в файле build.gradle. Благо, среди других достоинств Gradle можно упомянуть что это прекрасный язык Groovy, и он ничем вас не ограничивает в написании логики билда — подключил необходимые библиотеки из Java мира, и вперёд, хоть всё приложение перепиши в одном файле!
Впрочем, вы же понимаете пагубность такого подхода? Если логика получения номера версии занимает больше 5-10 строчек, а также если мы будем по любому поводу городить свой костыль, то поддерживать это будет просто невозможно очень скоро…
Подобные «решения» ручного парсинга вы можете увидеть например в статье Jenkins для Android на чистой системе и без UI или Через тернии к сборке где предлагается вызывать вручную git describe и парсить вывод регулярными выражениями…
Хотелось чего-то более простого, надёжного и изначально рабочего.
Наш workflow и хотелки
В нашем приложении собирается парочка jar файлов, 3 war артефакта, 3 RPM их включающих, и в конце Docker образ приложения, с установленными RPM, который после автоматического тестирования тут же на gitlab-ci отправляется в приватный репозиторий.
Предлагаемое решение: Gradle plugin net.nemerosa:versioning
Посмотрев вокруг на имеющиеся плагины для gradle, нашёл вот такой прекрасный вариант: github.com/nemerosa/versioning
Его документация сразу подкупает — всё просто, логично и понятно для чего сделано.
Плюс ко всему семантическое разделение на release, feature
Попробуем в деле
Итак подключить к проекту очень просто, следуем инструкции:
Всё, в большинстве случаев уже можно использовать версию в своих билд-скриптах далее, где она нужна:
Ну или ближе к делу, скажем в имени war артефакта:
После сборки из бранча feature-1 мы получим файл приблизительно следующего именования: portal-api##feature-1.3e46dc.war (в примере используется именование в стиле Tomcat). Варианты настройки и парсинга значений для более интересных ситуаций разберём далее.
Сразу же доступно 2 задачи:
versionDisplay — показывающую информацию и версиях и выводит на консоль. Очень удобно в отладке и versionFile — создающая файл build/version.properties с готовыми переменными, для импорта в bash скрипты вовне:
Кастомная логика парсинга версий
Сразу хочется заметить, что имеется множество опций как парсить имена, обрабатывать префиксы, суффиксы, трактовать версии. Там же есть и поддержка SVN к слову. В общем вам в раздел customisation.
Однако, тут не без ложки дёгтя. На момент когда я начинал им пользоваться, документация выглядела иначе.
Да, можно задать своё замыкание как трактовать имя бранча (например ‘release/1’ считать релизным, а ‘qa/0.1’ иначе):
Это всё здорово, но мы-то хотим тег вместо бранча, если он есть!?
Я не хотел отказываться от этой идеи. Разумеется запилил временный воркараунд, но автору создал реквест сделать логику парсинга более общей: github.com/nemerosa/versioning/issues/32
Damien Coraboeuf, являющийся автором этого плагина, оказался очень отзывчивым, и оперативным исправив оперативно пару мелких вещей.
В общем же, как это часто бывает, предложил реализовать мне самому, то что я предлагаю.
Я последовал его совету — быстренько сварганил pull request.
Теперь, после его принятия, мы получаем объект информации о коммите SCM (SVN или GIT) и вольны в выборе способа, как нам формировать версию. Например, тот же самый, код что приведён выше, может быть реализован так:
То же самое в замыкании full.
Что нам это даёт? Ну например, как описано было в требованиях, мы используем это для того чтобы брать в одном случае имя бранча, а в другом имя тега, а не ограничены только строковым представлением имени бранча. У нас это сейчас выглядит примерно так:
К нижнему регистру приводится для использования в тегах Docker образов.
Как я упоминал, опции этим не исчерпываются, мы также контролируем dirty-суффикс, а также время сборки добавляем в этот же объект, используя meta-магию Groovy…
Интеграция с CI
Ну и раз уж я взялся рассказывать про удобную интеграцию, сразу стоит обратить внимание на один подводный камень, о который я тоже споткнулся. А в этом плагине уже позаботились!
Указанный код работал прекрасно, был протестирован, закоммичен. Но первый же пуш и билд на CI принесли странный результат — именем бранча стало нечто вроде HEAD.
В самом деле причина простая, если посмотрим что делает билдер он же собирает не ветку, а конкретный коммит. На момент сборки, в этой же ветке могут будь уже другие. Поэтому, он всегда делает checkout по имени хеша коммита. Таким образом, мы получаем git репозиторий в состоянии detached head.
Как я, забегая вперёд уже сказал, эта ситуация нормальная и большинство работают так, а в данном плагине просто нужно прописать одну строчку, с указанием имени внешней переменной или переменных, из которых нужно взять настоящее имя бранча, для gitlab-ci мне нужно было просто добавить:
В Jenkins такие переменные также были добавлены достаточно давно по запросу JENKINS-30252. Так, если вы хотите поддержать сразу обе системы, вы можете просто написать:
Я надеюсь вам станет удобнее работать с версиями в gradle. Да, и всячески рекомендую ставить баги или писать реквесты автору — он очень оперативно на них отвечает. Хорошего кодинга!
Артефакты для UX-ёров и команды: что это, зачем нужны и как выбрать

Зачем нужно это знать?
Я UX-дизайнер в большой продуктовой компании, и я очень не люблю правки, а вы уже пролистываете дальше, потому что «так нельзя, ты не художник» и «ничего нового, никто не любит». Я ценю своих коллег, заказчиков и пользователей. Но 10 этапов согласования макетов, где каждый участник высказывается о том, что ему не нравится в дизайне — это не только сложно, но и нерезультативно. Вместо того, чтобы обсуждать продукт, почему им будут пользоваться, а почему — нет, что важно для пользователя, а что — наши собственные домыслы, мы часто уходим в холивары и обсуждение наших вкусов и предпочтений. Это нормальная история для больших компаний: заинтересованных в продукте лиц много, все хотят сделать что-то достойное или принять участие.
Как при этом дизайнеру выдать качественный результат, не растягивать сроки, не обозлиться на весь мир и не сойти с ума?
Мне помогают эвристики Нильсена, пользовательские исследования, интервьюирование заказчика и UX-артефакты. Об артефактах я вам и расскажу. Мой путь скорее подойдёт UX-ёрам в продуктовых компаниях с большим количеством стейкхолдеров, чем веб-дизайнерам из маленьких студий.
В работе над продуктом у нас участвует от 8 до 20 человек: заказчик (часто несколько представителей клиента), продакт оунер, руководитель проекта, бизнесовый и системный аналитики, верстальщик, фронтэнд и бэкэнд разработчики, тестировщики. Все они имеют свой взгляд на то, над чем они работают: хотят сделать как-то классно (у разных людей понятие «классно» отличается), руководители проектов хотят выдержать сроки и бюджет проекта, продакт оунеры хотят повышения всех метрик сразу, разработчики — писать чистый код.
Какова вероятность, что ваше видение продукта совпадёт с видением всех этих людей? Нулевая.
Если вы думаете, что вы дизайнер, и внешний вид продукта — это только ваша вотчина, вы ошибаетесь. Пара неудачных проектов и проблем в общении с командами и заказчиками приведут вас в чувство или помогут понять, что лучше применить свои навыки в какой-то другой сфере.
В нашей компании обязанность дизайнера — удостовериться, что команда и клиент договорились об ожиданиях. Желательно сделать это до того, как появятся макеты. По макетам разбираться в том, как должен выглядеть и работать продукт бывает уже поздно и больно.
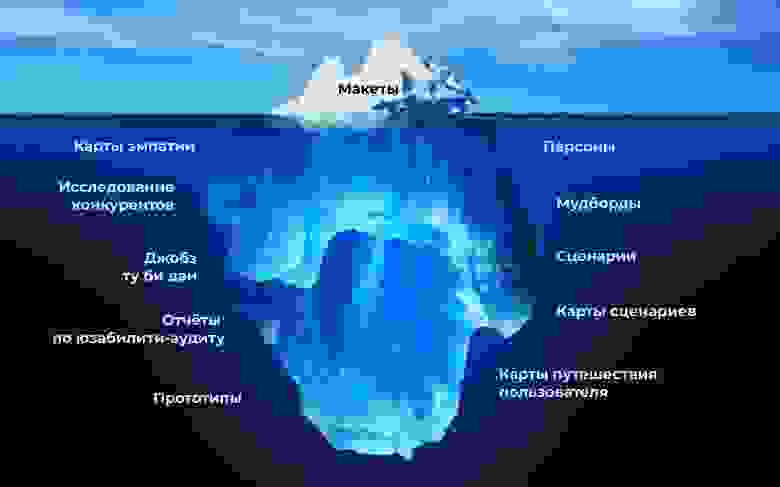
Макеты — это всего лишь вершина айсберга и часть работы дизайнера. За ними лежит ещё очень много вопросов, о которых нужно договориться всей команде.
Артефакты — это решение проблемы: с их помощью мы обсуждаем бизнес-цели и пользовательский опыт, дизайнер может опираться на них при защите проекта как на зафиксированные договорённости. По артефактам могут работать другие дизайнеры и члены команды, потому что в основном артефакты говорят на понятном, человеческом языке, а не на языке графики, бизнес-аналитики или кода. Я изучала артефакты в БВШД и по блогу UX-дизайнера Насти Щебровой (спасибо, Настя!) и активно применяю их в своей работе. Их использование спасло мне много нервов и ускорило разработку многих продуктов (хотя кажется, что должно быть наоборот).
Что такое артефакт?
Артефакт — описание продукта с определённой точки зрения по заданному формату. Он помогает договориться всем участникам процесса, но его не увидит конечный пользователь.
Какие бывают артефакты?
Не все артефакты генерирует дизайнер: часть артефактов делает продакт оунер или другие члены команды. Всё, что не является готовым продуктом, — это артефакт, в том числе и макеты в Фигме, и ТЗ.

Хороший UX-ёр работает с такими артефактами
Не все существующие артефакты могут и должны применяться на проекте. Задача в том, чтобы затратив минимум усилий, максимально прояснить картину для всех участников проекта. С опытом вы сможете оценить, какие артефакты нужно использовать для конкретной задачи. Классно попробовать все: вы поймёте, с чем вам комфортно работать, сколько времени и сил занимает составление того или иного артефакта.
Тем, кто пока не сталкивался с артефактами, я предлагаю схему, которую разработала для себя: составляю персонажа или карту эмпатии, прописываю его сценарии, объединяю сценарии в карты сценариев (если продукт новый) или раскладываю на карте путешествия пользователя (если продуктом уже пользуются). По ним рисуем прототипы, тестируем их, снова прототипируем и тестируем до тех пор, пока не будем довольны результатом.
Персонажи
Описывать персонажей можно по-разному, но как правило они состоят из:
Персонажей делают, чтобы:
Как создать персонаж:
Сколько времени занимает
Если вам удастся быстро собрать респондентов и провести с ними интервью, то на это уйдёт 1-2 рабочих дня дизайнера.
Подводные камни
Есть проекты, которые направлены на очень широкую аудиторию. Тогда у них либо слишком много персонажей, либо их сложно выделить. Для таких проектов лучше использовать карту эмпатии или джобз ту би дан (дальше расскажу, чем они отличаются).
Метод персонажей хорошо работает, когда вы работаете с понятной аудиторией и рынком. Но когда нужно придумать передовой продукт, открывать новые рынки и делать то, что до вас ещё не делали, метод персонажей приведёт вас к созданию более быстрых лошадей вместо автомобиля.
Если вы не проверяете персонажей и другие свои гипотезы, вы рискуете очень сильно просчитаться. Помните, что любая непроверенная гипотеза — это лишь плод вашего воображения.
«Мужчины и женщины от 16 до 65 с высоким достатком, которым непременно нужен наш продукт» — это не персонаж, это копипаста плохого маркетолога.
Джобз ту би дан
Невозможно строить продукты будущего, ориентируясь только на запросы и ожидания пользователей от существующего продукта. Хорошие метрики и продажи — это лишь состояние рынка на текущий момент. На какие цифры смотрела компания Эпл, когда убирала кнопки клавиатуры со своих телефонов? На что опирался Генри Форд, когда захотел сделать автомобиль в то время, когда все вокруг просили быстрых лошадей? Люди любили лошадей и кнопочные телефоны, но они больше никому не нужны. Чтобы искать прорывные решения, можно использовать джобз ту би дан.
Что такое джобз ту би дан
В джобз ту би дан не думают о пользователях и их желаниях, не проводят ретроспективные исследования. Это проверка бизнес-гипотезы: сейчас этого нет, мы создаём новый рынок. Продукт, который вы создаёте, решает проблему пользователя — «выполняет работу». Пользователи покупают, то есть «нанимают на работу» ваш продукт, чтобы он сделал их жизнь немного счастливее. Условный Иван Васильевич покупает не телефон с кнопками, а возможность быть на связи с близкими, если копнуть поглубже — то и со всем внешним миром.
Зачем нужны джобз ту би дан:
Формула джобз ту би дан:
Когда (описание ситуации),
Я хочу (мотивация),
Чтобы (результат).
Пример джобз ту би дан
Познакомьтесь с Олегом Ивановым. Ему 28 лет, он один из двух дизайнеров мобильных приложений под Айос в небольшой продуктовой компании. Каждое утро он пьёт кофе, садится за свой Макбук и делает макеты (хотя сначала, конечно, продумывает персон). Иногда работает в кофейне, 3 раза в год ездит в отпуск. Он знает основы Свифта, учился в Британке. Носит крутые свитшоты и цветные носки, ходит на митапы, а по выходным занимается каллиграфией.
И вот Олег покупает себе Фигму для макетов и Миро для дорожной карты продукта. Почему именно такой набор? Почему не Фотошоп или Скетч плюс Люсидчарт? Повлияла ли на его выбор любовь к кофе, цветным носкам и митапам? Нет, скорее повлияло то, что в Фигме и Миро можно работать командно вместе с коллегой. Вот это «работать командно и одновременно онлайн» — и есть джоб ту би дан.
Если мыслить глобальнее, то дизайнер Олег Иванов покупает себе не просто возможность работать командно над макетами и дорожной картой, а возможность быстро получать обратную связь от коллег и работать удалённо из любой точки мира, а не в офисе — то есть более удобные условия работы.

Пример джоб ту би дан
Как создать джобз ту би дан
Так же, как персонажей:
Подводные камни
Джоб ту би дан лучше всего делать на инноваторских продуктах, когда у них есть большая степень неизвестности, или когда персонажей не удаётся выделить или их слишком много.
Карта эмпатии
Карта эмпатии — инструмент визуализации идей, позволяющий поставить себя на место пользователя, взглянуть на проблему его глазами.
Может быть использован как в качестве альтернативы персонажам, так и как дополнение к ним. Карта эмпатии представляет собой схему, в центре которой размещается представитель определенного пользовательского сегмента, по разные стороны от него — 4 блока («думаю и чувствую», «говорю и делаю», «вижу», «слышу»). Выводы приводятся в двух дополнительных блоках: «проблемы и болевые точки» и «ценности и достижения».

Пример карты эмпатии
Зачем использовать
Как создать карту эмпатии
Выводы
Буду очень рада, если вы попробуете поработать с артефактами на практике и поделитесь со мной своими результатами в комментариях.
Круговорот артефактов в Agile
Доброго времени суток.
В этой статье я хочу продолжить рассказ о «прагматическом» Agile процессе разработки ПО. На суд Читателя предлагается иная перспектива обзора этого процесса — с точки зрения создания и эволюции артефактов (Artifact Flow) в ходе развития проекта. А также мы рассмотрим практический подход для работы с артефактом «Коллекция Требований» с использованием Google Wave и Google Docs.
Артефакт — это рукотворный объект. В первом приближении артефактами можно назвать и код программы, и документы написанные программистами. При более тщательном подходе мы можем значительно расширить круг примеров и отнести к артефактам электронные письма, фрагменты чатов и даже наброски фламастером на доске.
На самом деле последовательность создания/модификации артефактов и их содержание имеет критическое значение для здоровья проекта. Особое значение, с моей точки зрения, имеют коллективно созданные артефакты.
Диаграммы потоков артефактов.
Дальше я предлагаю взглянуть на зарисовки жизненного цикла артефактов на трех разных этапах развития Agile проекта. При этом мы будем использовать такие обозначения:
Где Person и Group — создатели артефактов, Communication и Development — процессы, в которых рождаются артефакты, и, собственно сами артефакты. Обратите внимание, что в Communication процессах рождаются коллективные артефакты, а при Development — персональные.
Почему я акцентирую на важности коллективных артефактов? Потому что они являются каналами связи и синхронизаторами информации между заказчик(ом)(ами) и исполнител(ем)(ями) проекта. При отсутствии таких каналов связи проект будет протекать по «законам здравого смысла», которые весьма субъективны, и в результате заказчик «не узнает» в готовой системе ту «картинку» которая у него в голове. В итоге неизбежен конфликт.
Итак, посмотрим «слайды»…
Этап начала проекта (Project Initiation Artifact Flow).
Сценарий здесь такой: Sales сделали свою часть работы и у нас появился потенциальный клиент. На этом этапе в компании выделяется человек, который будет начинать общение с клиентом на технические темы. Роль этого человека можно назвать по-разному — аналитик, консультант, владелец проекта (Product Owner). Мы будем использовать последнее название.
Во время первой (реальной или виртуальной) беседы владельца проекта с заказчиком формируется самый первый из коллективных артефактов — Vision & User Story titles. Это текстовый документ где описывается основная идея проекта и его функциональность в виде коротких Историй Пользователя.
Затем следует внутренний митинг где встречаются владелец проекта и менеджер проекта. Задача этой встречи — принять решение о составе команды разработчиков и исходя из ее возможностей построить оценочный или предварительный план (Preliminary Plan). К примеру, в нашей команде мы «моделируем» выполнение Историй Пользователя с помощью Гантта с ресурсами.
Этап заканчивается согласованием оценочного плана с заказчиком на уровне Sales-, финансового- менеджера и прочего начальства (это и есть момент покупки сервиса) и официальным стартом разработки.
Architectural Iteration Artifact Flow
Первая итерация — архитектурная, во время которой строятся слои будущей системы, пишутся прототипы темных мест. Давайте посмотрим что творится с артефактами.
На входе у нас Vision & User Storiy titles. Этот артефакт выносится на первый большой митинг с командой. Задача митинга — выработать архитектуру ПО и план на архитектурную итерацию. Идет обсуждение, доска загромождается рисунками… Первый артефакт который рождается в споре — это драфт архитетктуры. Дальше оцениваются и распределяются задачи — инфраструктурные (что-то сконфигурировать и настроить), прототипы (проверить что архитектурная идея работает), архитектурные (подключить компонент архитектуры — например Веб-Сервисы). Оценки по времени поступают от самой команды. В результате появляется второй артефакт — план итерации.
План итерации и архитектурный драфт поступает в самый большой узел на нашей диаграмме — в разработку. Результатами разработки являются код, список багов и иженерные артефакты, такие как инструкции по инсталляции.
Интересно что на фоне артефакт-оборота разработки выполняется второй, не менее важный: сбор Требований. Это постоянный процесс в результате которого общий взгляд на систему скоординировано детализируется. Иногда в результате детализации меняется и сам изначальный общий взгляд. Сам процесс сбора требований может протекать по-разному, но его участниками всегда являются владелец проекта (наш аналитик) и заказчик (либо его технический консультант). Результатом этого процесса является постоянно развивающийся драфт Требований. Во второй части статьи я покажу как можно использовать сервисы Google Wave и Google Docs для работы над этим артефактом.
Также здесь важно отметить что у Владельца Проекта уже на этом этапе должен быть создан неформальный бэклог для накопления и приоритезации Историй Пользователя, которые попадают на следующую итерацию. Именно на них он должен сконцентрировать работу по сбору требований. Эта практика — сбор «наперед» — переходит от одной итерации к другой.
Functional Iteration Artifact Flow
Это самая важная составляющая проекта. Во время функциональных итераций продукт «растет». Как правило (у нас) разработка начинается с архитектурной итерации, а затем идут несколько функциональных итераций вплоть до релиза проекта.
Если в общих словах описывать потоки артефактов такой итерации, то кроме потока разработки и сбора требований добавляется поток спецификации: команда QA на основе коллекции Требований и списка наименований Историй Пользователя пишет короткие, но исчерпывающие Test Cases. Эти Test Cases вместе с итерационным планом являются главными движущими артефактами во время разработки.
Сбор сведений при помощи Google Wave и Google Docs
На артефакте коллекции требований хочу остановиться отдельно. Этот артефакт отвечает за синхронизацию картинки функционала системы между всеми участниками проекта. Наша группа набила тут много шишек и, если мне удастся убрать пару-тройку граблей с Вашей дороги, я буду счастлив).
Первый вопрос в Agile проекте возникает всегда: зачем писать Требования если можно просто поговорить по телефону или скайпу? Такой сценарий не исключается, но он ограничен случаем, когда домен хорошо понятен и программисту и заказчику, они говорят на одном языке примерно на одном уровне, они обладают одинаковым менталитетом (используют одинаковые принципы Здравого Смысла), части системы, которые обсуждаются легко укладываются в памяти (они компактны, а система как правило небольшая). На самом деле такой случай относится больше к исключениям, чем к правилам. Системы строятся большие и разветвленные, команды у нас сейчас распределенные, с разным менталитетом, с разной специализацией, мир многополярен, ИМХО, это хорошо.
На мой взгляд коллекцию требований нужно рассматривать как проект закона, а тест кейсы (в качестве спецификации) — как закон для данного проекта и его участников.
В данном подходе Google Волна используется для построения синхронного дерева обсуждений. Под синхронностью я понимаю то, что нету времени ожидания между отправкой данных и получения их Вашим собеседником. Вы можете видеть то, что он пишет и наоборот. Это свойство существенно активизирует скорость самого процесса накопления требований.
Волна состоит из текста и рисунков. Рисунки представляют макеты страниц пользовательского интерфейса системы. Текст — это описания к макетам и логическим потокам вокруг них. На первый взгляд все просто. Однако у Волны есть свои недостатки. Как ни странно самой серьезной проблемой является то, что волна имеет слишком много свободы для организации ветвления. Если начинать использовать Волну без продуманного набора правил она быстро превратится в бестолковое захламленное пространство. Эти правила мы обсудим через пару секунд.
Теперь о макетах. На данный момент наилучшим средством для их создания я считаю Google Document и его компонент Drawing. Он прост и надежен. В волну документ вставляется при помощи iFrame гаджета.
Теперь о правилах построения волн для сбора Требований:
1. Отдельные Истории пользователя являются отдельными волнами, собранными в «волновую» папку с названием проекта.
2. Макеты, относящиеся к определенной странице и ее состояниям собираются вместе в отдельной папке Google Docs с названием проекта. В названиях этих макетов присуствует название действия или эффекта, который они демонстрируют. Также следует отметить, что каждый Google документ имеет свою собственную систему версий — поэтому не следует дублировать версии макетов отдельными документами — это существенно упрощает всю схему.
3. Используйте один экземпляр точного макета на один шаг Истории Пользователя. Под точным макетом я подразумеваю Google документ. При этом набросков может быть много. Для набросков удобно использовать этот гаджет.
3. Внутри Волна имеет четкую структуру: в отдельных сообщениях находятся заголовок Волны, который описывает общий смысл данной Истории Пользователя, и далее в отдельных сообщениях следуют шаги этой истории.
Внутри шага истории идут в виде Replies три секции — макет (Google документ в iFrame), текст комментариев к макету и текст логических потоков на этом шаге истории. Эти части шага реализованы как Replies для того, чтобы их можно было быстро закрыть — это удобно для длинных и закрученных Волн.
Преимущества такого подхода к организации Волны следующие:
1. Сбор требований легко распараллеливается. Если проект объемный, в сбор требований легко включаются разработчики. Владелец проекта просто создает Волны с первым заголовочным сообщением и расшаривает их на разработчиков. Затем разработчики рисуют макеты и обсуждают их с заказчиком напрямую.
2. Упрощается и ускоряется общение по бизнес домену во время спринта. Если у программиста или QA-щика возникают вопросы — он их тут-же задает в Волну.
3. Заказчик может быстро инициировать разговор по любой точке Требований.
Пример сбора требований для простой Истории Пользователя
Рассмотри некий пример обсуждения и накопления требований по такой истории: посетитель веб-сайта знакомится с текстом домашней страницы и новостями.
Просмотрите экранный снимок волны, а дальше я добавлю пару комментариев.
Развитие этой волны происходило таким образом: владелец проекта создал волну под названием соответствующей истории пользователя. Затем он добавил сообщение — заголовок с общими словами по этой истории и адресами двух гаджетов (для удобства, чтобы они были всегда под рукой). Далее он пригласил в Волну заказчика. Создал сообщение для первого шага истории пользователя, создал Google документ с первым макетом страницы. Добавил несколько слов для описания макета и логического потока.
На этом этапе в работу включился заказчик и написал. что показ только трех последних новостей на домашней странице — плохая идея, нужен компонент для листания страниц (Pagination). Для наглядности заказчик вставил в реплику гаджет для рисования набросков и быстро изобразил вид такого компонента.
Владелец продукта согласился с предложением и дорисовал (не выходя из волны) нужный компонент на точном макете и обновил текстовку.