Корпоративные хранилища данных. Интеграция систем. Проектная документация.
Архитектура корпоративного хранилища данных
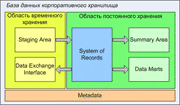
Основными компонентами корпоративного хранилища данных являются:
Архитектура области хранения данных базы данных корпоративного хранилища, как правило, состоит из следующих областей:
Обычно приведенные выше области хранения данных реализуются в виде отдельных схем одной или нескольких баз данных.
Ниже представлена общая схема организации областей хранения данных.
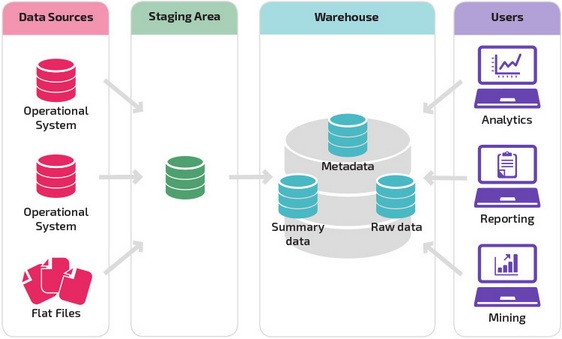
Область временного хранения данных (Staging Area)
Область временного хранения данных является промежуточным слоем между источниками данных и областью постоянного хранения. В данной области сохраняются извлеченные из операционных систем-источников (СУБД, csv, dbf, xml файлов, web-сервисов и т.д.) данные, производится их очистка, трансформация, обогащение, подготовка к загрузке в область постоянного хранения. Зачастую очередной цикл обработки и загрузки данных в хранилище не может быть начат пока не будут извлечены все необходимые данные из различных систем-источников, а в силу ряда причин (географической распределенности, разных циклов функционирования систем и т.п.) данные в источниках могут быть доступны в разные моменты по времени. Область временного хранения служит для сбора всех необходимых данных перед началом трансформации.
Одной из наиболее важных задач при построении хранилища данных является определение соответствия (mapping) сущностей систем-источников данных и сущностей модели хранилища данных. Обычно подобное соответствие представляет собой отношение десятков (а иногда и сотен) таблиц систем-источников к десяткам таблиц области постоянного хранения данных. Правильно организованная область временного хранения данных позволяет значительно упростить организацию процессов загрузки данных из области временного в область постоянного хранения.
Ниже представлены основные принципы формирования области временного хранения.
Детальные данные (System of records)
Данная область является основной хранилища данных. В этой области хранятся преобразованные и очищенные детальные данные, полученные из систем-источников, и основные классификаторы. Хорошо спроектированная модель данной области является залогом дальнейшего успешного функционирования базы данных и BI-приложения.
Данная область содержит следующие типы сущностей:
Справочники и классификаторы определяют:
Сущности, содержащие фактические значения, – транзакционные данные из систем источников. Например, информация о совершенных телефонных звонках, выставленных счетах, проводках, проданных товарах и т.п.
Сущности, содержащие связи, определяют взаимосвязи между остальными сущностями. Например, Клиент-Услуга.
Область детальных данных не содержит никаких агрегатов. Только детальные, очищенные и структурированные в соответствии с моделью данные.
Агрегаты (Summary area)
В данной области хранятся агрегаты данных, которые в основном строятся для сущностей, описывающих участников бизнес-процессов. Например, агрегаты строятся для данных по продажам товаров, оказанию услуг, клиентам и т.п. Данные агрегируются в разрезе времени – от часа, дня к неделе, месяцу. Для каждого агрегата может быть определена своя степень агрегации данных.
Витрины данных (Data Marts)
Витрины данных являются объектами хранения аналитической информации, нацеленными на поддержку конкретных бизнес-функций, конкретных подразделений компании. На уровне базы данных витрины обычно реализуются по схеме «звезда» или «снежинка» и содержат данные из области детальных данных (System of records). Также могут быть реализованы в виде многомерного OLAP-куба. Витрины данных являются основой, обеспечивающей возможность проведения многомерного анализа (OLAP) данных.
Ниже представлены основные принципы проектирования витрин данных.
Интерфейсы обмена данными (Data Exchange Interface)
Хранилище обычно строится с целью консолидации в нем данных компании, и поэтому оно зачастую является источником данных для других информационных систем. Для обмена данными создаются интерфейсы обмена (обычно это таблицы базы данных), в которых и хранятся специально подготовленные (возможно, перед передачей данных потребуется их предобработка) для передачи данные. Интерфейсы обмена желательно создавать как можно более универсальными.
Метаданные (Metadata)
Разработка и сопровождение системы с хорошо спроектированными и описанными метаданными является более простой задачей, нежели при отсутствии таковых. Метаданные хранилища включают:
Обычно управление метаданными осуществляется отдельными инструментами для каждого из компонентов хранилища. Например, для базы данных Oracle, метаданные которой хранятся в системных таблицах и настроечных файлах, это будет Oracle Enterprise Manager.
Архитектура хранилищ данных: традиционная и облачная
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!

Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
Звезда vs. Снежинка
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
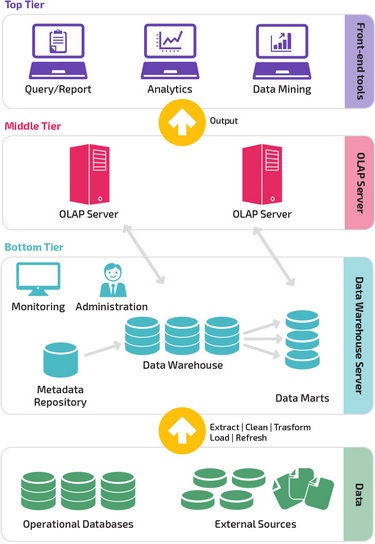
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.

ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
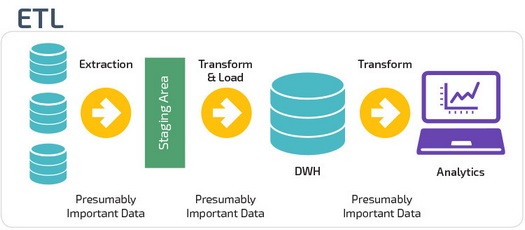
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.

Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.

Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.

Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.
Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
Что такое DWH и почему без них данные компании почти бесполезны
Тем, кто работает в крупном бизнесе, периодически приходится слышать три магические буквы — DWH. Узнав расшифровку этой аббревиатуры — data warehouse, можно догадаться, что это имеет отношение к данным. А вот чем DWH отличается от простых баз данных, почему вокруг них снуют рои бизнес-аналитиков и зачем вашей компании иметь такую штуку — это всё еще непонятно. Разбираемся в статье.
DWH — что это и в чем отличие от баз данных
Data warehouse — склад всех нужных и важных для принятия решений данных компании.
Но есть же всякие базы данных внутри фирмы, разве они не DWH? Например, СУБД с клиентами, складскими запасами или покупками. Где разница между обычной базой данных и DWH?
Короче говоря, DWH — это система данных, отдельная от оперативной системы обработки данных. В корпоративных хранилищах в удобном для анализа виде хранятся архивные данные из разных, иногда очень разнородных источников. Эти данные предварительно обрабатываются и загружаются в хранилище в ходе процессов извлечения, преобразования и загрузки, называемых ETL. Решения ETL и DWH — это (упрощенно) одна система для работы с корпоративной информацией и ее хранения.
Что дают DWH-решения для BI и принятия решений в компании
Понятное дело, что просто так тратить деньги и время на консервирование кучи разных записей, которые и так можно накопать в других базах данных, никто не станет. Ответ заключается в том, что DWH необходима для того, чтобы делать BI — business intelligence.
Что такое BI с DWH? Бизнес-аналитика (BI) — это процесс анализа данных и получения информации, помогающей компаниям принимать решения.
Если бы такого аналитического отчета не было — управленцам пришлось бы искать проблему наугад.
Логичный вопрос: казалось бы, зачем держать для этого всего DWH? Аналитики вполне могут ходить в базы данных разных систем и просто выдергивать оттуда то, что им надо.
Ответ: так, конечно, тоже можно делать. Но — не нужно. И вот почему:
Для работы с большими данными используют различные решения, обрабатывающие информацию из DWH. SAS, VK Cloud Solutions (бывш. MCS) и другие компании предлагают различные варианты коробочных и облачных решений под такие задачи.
Экспертиза GlobalCareer: подбор DWH-специалистов
Как мы подбираем разработчиков, специализирующихся по DWH.
Корпоративные хранилища данных (КХД, Data Warehouse, DWH) очень востребованы в финтех-компаниях, торговле и телекоме, а в последнее время ими стали пользоваться и производственные холдинги, активно внедряющие IT-технологии. Поэтому запрос на поиск DWH-разработчиков возникает всё чаще. Сегодня делимся опытом подбора кандидатов, специализирующихся по КХД.
В зависимости от особенностей деятельности компании требования к вакансиям, связанным с созданием корпоративных хранилищ данных, могут иметь свою специфику, но есть ряд компетенций, которыми обязательно должны обладать кандидаты на такие позиции.
Достаточно часто встречается несоответствие реального опыта соискателя с опытом, который необходим для работы. Так, в резюме могут быть указаны подходящие технологии, а на интервью становится понятно, что человек только начал их изучение. Поэтому при беседе с претендентом важно проговорить используемые методики работы и узнать уровень владения ими.
Вот на что обращают внимание профессиональные консультанты GlobalCareer, занимаясь рекрутингом на DWH-позиции:
Опыт работы с Oracle. Это главная система работы с базами данных. Она оптимизирована для больших нагрузок, обеспечивает высокую производительность системы (сбор данных и их анализ) и позволяет быстро создавать новые КХД и витрины данных. Поэтому специалист по DWH практически по умолчанию должен уметь работать с Oracle.
Владение OLAP. Эта технология используется при анализе больших объёмов данных, позволяет обрабатывать их очень быстро и считается ключевым компонентом баз данных. А т. к. одно из главных качеств DWH – скорость работы, то без знания технологий, позволяющих эту скорость обеспечить, создание эффективной КХД оказывается под вопросом.
Отличное знание SQL, PL/SQL. SQL стандартный язык баз данных, а PL/SQL в него интегрирован, поэтому без навыков работы с ними кандидат не сможет работать над проектами DWH.
Навыки работы с инструментами ETL (Informatica Power Center, IBM DataStage, Oracle Data Integrator, Oracle WareHouse Builder). Для управления данными в КХД – их обработки, преобразования и перемещения в хранилище – используются ETL-процессы. Поэтому без умения применять различные инструменты для их осуществления сложно представить работу с DWH. Желательно, чтобы кандидат мог подтвердить свои знания по продукту ETL сертификатом вендора. Это станет гарантией того, что он быстро адаптируется и включится в работу.
Опыт в построении Data Mart (витрин данных). Т.к. витрину данных можно назвать хранилищем данных для одного отдела — здесь собрана информация одного типа, её работу поддерживает, как правило, одно приложение и создаётся она для нужд определённого подразделения, то опыт участия в разработке Data Mart станет большим плюсом для кандидата на вакансии, связанные с КХД.
Отличное знание стека Hadoop (Apache Hadoop, Cloudera Manager, MapReduce, HDFS, Spark, Kafka, YARN). Эта основополагающая технология Big Data обеспечивает работу высоконагруженных систем, позволяет хранить, сортировать и быстро преобразовывать огромные объёмы информации. Поэтому специалист, разбирающийся в ней, сможет заниматься реализацией проектов DWH любой сложности.
Разработка корпоративной базы данных с нуля. Это, как правило, даёт кандидату большую фору, т.к. означает, что он отлично понимает принципы создания и поддержки работы КХД. А значит, сможет быстро включиться в решение задач по модернизации существующей базы, самостоятельно разобравшись с её недочётами, или сможет начать создание нового хранилища.
Знание одного из языков программирования. Поскольку для запуска процессов ETL используются языки программирования, то их знание необходимо кандидату для работы с DWH. Если в задачах специалиста будет поддержка и модернизация существующего корпоративного хранилища, на этапе интервью с соискателем следует уточнить его уровень владения тем языком программирования, с помощью которого ранее велась разработка.
Создание КХД – трудоёмкий процесс, сопровождаемый множеством организационных и технических сложностей, поэтому заказчики охотнее работают с соискателями, имеющими успешный опыт внедрения в крупных компаниях. На рынке сейчас достаточно разработчиков хранилищ данных, но кандидатов со знанием Hadoop среди них не так много. Именно они наиболее востребованы, при этом уровень их зарплат высок. Мы регулярно подбираем специалистов на проекты DWH уровня Senior и Architect, для которых опыт работы с Hadoop обязателен.
Высоким спросом пользуются DWH-специалисты с опытом работы в области Big Data: Hadoop, Oracle, Teradata, DB2, SQL. Даже опыт работы, например, от года, обеспечивает большую востребованность этих кандидатов. Поэтому, чтобы закрыть вакансию разработчиков хранилищ данных в Москве, по факту нужно предложить Regular-специалисту — от 150 тысяч рублей, Senior — от 230 тысяч рублей, тимлиду — от 285 тысяч рублей в месяц до вычета налогов.
Востребованность кандидатов на вакансии DWH будет только усиливаться, а требования к ним будут усложняться. Так, если раньше основной задачей разработчиков хранилищ данных был выбор правильных фреймворков и построение системы, то теперь они сталкиваются с другими вызовами: необходимостью использовать данные в real-time режиме, плюс в условиях высоконагруженной системы. Поэтому от рекрутёров требуется пристальное внимание к соискателям с подходящим стеком и максимально точное составление профилей необходимых для КХД-позиций кандидатов.
Если вашей компании нужна зарплатная аналитика IT-специалистов любого профиля или обзор общей ситуации на рынке – напишите нам, и команда GlobalCareer поможет с решением этих задач.
Архитектор dwh что это
В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data).
Где хранить корпоративные данные: краткий ликбез по Data Warehouse
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Частично этот вопрос Data Governance мы затрагивали в контексте управления НСИ. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины [1].
Принцип слоеного пирога или архитектура КХД
Вышеприведенное определение DWH показывает, что это средство хранения данных является реляционным. Однако, не стоит считать КХД просто большой базой данных с множеством взаимосвязанных таблиц. В отличие от традиционной SQL-СУБД, Data Warehouse имеет сложную многоуровневую (слоеную) архитектуру, которая называется LSA – Layered Scalable Architecture. По сути, LSA реализует логическое деление структур с данными на несколько функциональных уровней. Данные копируются с уровня на уровень и трансформируются при этом, чтобы в итоге предстать в виде согласованной информации, пригодной для анализа [2].
Классически LSA реализуется в виде следующих уровней [3]:
Все слои, кроме сервисного, состоят из области постоянного хранения данных и модуля загрузки и трансформации. Области хранения содержат технические (буферные) таблицы для трансформации данных и целевые таблицы, к которым обращается потребитель. Для обеспечения процессов загрузки и аудита ETL-процессов данные в целевых таблицах стейджинга, ядра и витринах маркируются техническими полями (мета-атрибутами) [3]. Еще выделяют слой виртуальных провайдеров данных и пользовательских отчетов для виртуального объединения (без хранения) данных из различных объектов. Каждый уровень может быть реализован с помощью разных технологий хранения и преобразования данных или универсальных продуктов, например, SAP NetWeaver Business Warehouse (SAP BW) [2].
Data Lake и корпоративное хранилище данных: как работать с Big Data
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД [4] не совсем корректно по следующим причинам:
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке [6]:
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum [6]. От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка [6].
 LSA-архитектура корпоративного Data Lake в Тинькоф-банке
LSA-архитектура корпоративного Data Lake в Тинькоф-банке
В следующей статье мы продолжим разговор про архитектурные особенности современных DWH с учетом потребности работы с Big Data и рассмотрим еще несколько примеров таких гибридных подходов. А технические подробности реализации КХД и другие актуальные вопросы управления бизнес-данными вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: